少走十八年弯路,一文速通机器学习入门
少走十八年弯路,一文速通机器学习入门
一篇更适合新手宝宝的AI入门攻略
前言
从理论课到自己找代码实践和复现论文,摸索了大概一年的时间,最大的感触是理论对接不上代码。网上的教程总是长篇大论地一个一个算法地拆解,又或者是扔一堆很难读的代码,b站上的无数个不同的账号发着不同的学习视频,但来来去去都是同一个人的声音,并且想要拿源码最后都会把你指向同一个公众号。。。。
想了想我的入门之路真的很崎岖,因为我是大一上的算法课,是把一些入门级的算法弄懂了,但是怎么对接回代码层面一窍不通。其实很多时候AI充当的是一个工具的作用,你不用很细地去手撕某一个算法,你只要知道这个算法是干嘛的,怎么拿来用就够了,又或者是,更多的时候,我想直接拿一个现有的模型来跑来练。面向有这部分需求的小白,他们根本不需要花这么长的周期去上手实现这一个简单的东西。也许是真的太基础了,目前我也没有看到一些好的文章对这方面做一个系统的总结。无所谓,我是菜鸡,所以我知道菜鸡需要什么保姆式的引导。那就开始吧。
(由于笔者也是入门不久的小白,可能本文会有描述不当的地方,欢迎指正和建议)
我需要什么准备知识?
1.会用python
2.线性代数
3.(前期)少量高数–》(后期)大量高数
4.(后期)数学思维
5.学习热情
何为机器学习?
什么是机器学习?只看这一个图就够了

简单来说就是,把输入给模型,模型给你一个输出
何为模型?
现在我们来把每一部分展开看看,先看我们最关心的核心部分——模型

所谓模型,其本质就是一个函数f(x),由用户提供输入,计算机计算输出。我们的目的是找到一个好的f(x),使它能贴合我们的任务,给到一个准确度较高的输出。
下面我们再来拆分一下模型,核心可以分成三部分来看,分别是模型的架构、损失函数和权重。
什么是模型架构?
简单来说是实现这个任务的模型框架,其核心是算法,举几个栗子:DNN、CNN、RNN,由于这里面向的是想快速上手的小白,就不多铺述了。不同算法有不同的特点和作用,入了门之后,我们要重点学习的也是这一部分的内容。算法是整个机器学习的核心,决定了一个模型的精度上限。
什么是损失函数?
既然是函数,那么肯定是一个求解问题。我们可以将模型看成是对任务的一种数学映射。只要我们把输入放进这个函数,计算机计算完之后就会得到一个正确的结果。而损失函数,就是衡量模型的计算结果到正确结果的距离的一个函数。
什么是权重?
类似加权平均数的计算,假设我们的模型是一个计算20个人的平均工资的模型。那么我们的输入肯定就是20个人的工资,也就是一个20列的向量。我们的f就应该对x中的每一列*20分之一求和。这个时候,每一个1/20就是一个权重,所有的1/20就构成了整个模型的权重。换言之,权重其实就是模型中的参数。f(x)=ax+b,这里的a,和b就是权重。
有点抽象,举个栗子,假设我们要对一堆猫和狗的图片做二分类,模型要输出这张图是猫的概率和是狗的概率(为什么要输出概率?涉及到建模和算法的知识,这里留给大家去思考,本文不讲算法),然后再处理一下,如果猫的概率大,就输出1,否则就输出0。
好,假设我们初始的权重全是0,无论输入什么图片,计算出来的结果都是,猫的概率是0,狗的概率是1。那么我们就对模型进行训练,这个时候就要用上我们的损失函数。
我们也说了损失函数其实就是用来量度输出结果跟真实结果的偏差的,我们要把这个偏差降到最小。

举个不好的栗子,假设我们的损失函数长这样(只是为了便于理解),假设我们的模型和参数在接收输入后对应损失函数落在"初始点"这个位置,我们可以通过计算梯度(重要知识点,什么是梯度?),反向更新权重,一步一步走,使模型走到loss最低点(理想状况)很多时候都是走到一个比较低的点,甚至是局部最优解,这里只是做一个介绍,就不展开说优化了。
好,模型的部分到这里就结束了,下面我们来看input。
输入? 
我们要把输入转成计算机可以理解的东西,也是模型能接收的输入。要把数据统一成一个固定的格式,并且对数据做归一化。这个过程叫做数据预处理。
那么什么是张量?一图速通(56秒的视频,非常形象好理解):https://www.bilibili.com/video/BV1p54y1Y7AP
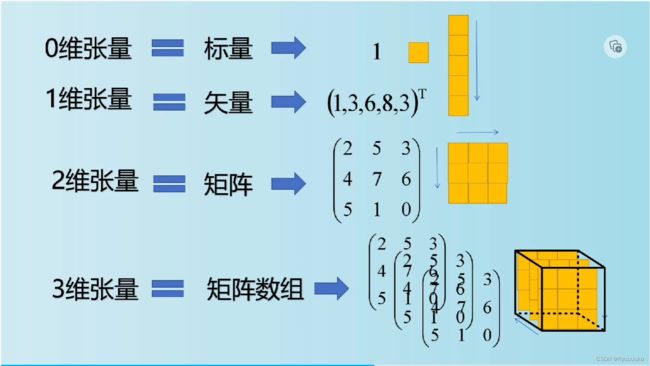
张量:张量概念是矢量概念的推广,矢量是一阶张量。张量是一个可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数。用大白话来说,就是很多个矩阵的嵌套。
一文速通:什么是张量 (tensor)? - 知乎 (zhihu.com)[1]
什么是特征?
一文速通:机器学习中的“特征”到底是什么? - 知乎 (zhihu.com)[2]
数据预处理:
数据处理常用的库:panda、numpy
归一化:就是把输入数据全都控制到0-1之间或某个范围之间(如-1到1)
几种常见的归一化方式:如何理解归一化(normalization)? - 知乎 (zhihu.com)[3]
为什么要归一化:最直观的效果就是能加快计算速度,以及可以减少内存的占用。
一文速通:机器学习笔记:为什么要对数据进行归一化处理? - 不说话的汤姆猫 - 博客园 (cnblogs.com)[4]
具体问题具体分析,建议多复现实验去体会数据预处理~
输出?
这个没什么好说的,采用不同的算法输出也不一样,最后的结果再加处理就能转成跟标签一致的形式了。
End
最近比较忙,今天先写这么多,后续应该会上代码实例来细细分析一遍,以及介绍一下搭建一个模型的思路。
参考链接:
1.https://www.zhihu.com/question/20695804/answer/2798849378
2.https://zhuanlan.zhihu.com/p/261296625
3.https://zhuanlan.zhihu.com/p/424518359
4.https://www.cnblogs.com/silence-tommy/p/7113498.html