深入理解C语言关键字用法
本篇文章总结了各个关键字的用法、特殊用法。对C语言的关键字进行深入的理解。
一、C语言标准定义的关键字(共32个)及其意义
| 关键字 | 意义 |
|---|---|
| auto | 声明自动变量,缺省时编译器一般默认为auto |
| int | 声明整型变量 |
| long | 声明长整型变量 |
| double | 声明双精度变量 |
| char | 声明字符型变量 |
| float | 声明浮点型变量 |
| short | 声明短整型变量 |
| signed | 声明有符号型变量 |
| unsigned | 声明无符号变量 |
| struct | 声明结构体变量 |
| union | 声明联合数据类型 |
| enum | 声明枚举类型 |
| static | 声明静态类型 |
| switch | 用于开关语句 |
| case | 开关语句分支 |
| default | 开关语句中“其他”分支 |
| break | 跳出当前循环 |
| register | 声明寄存器变量 |
| const | 声明只读类型变量 |
| volatile | 说明变量在程序执行过程中可能被隐含的改变 |
| typedef | 用于给数据类型取别名 |
| extern | 声明变量是在其他文件正声明 |
| return | 子程序返回 |
| void | 声明函数无返回值或无参数,声明空类型指针 |
| continue | 结束当前循环,开始下一循环 |
| do | 循环语句的循环体 |
| while | 循环语句的循环条件 |
| if | 条件语句 |
| else | 条件语句的否定分支 |
| for | 一种循环语句‘ |
| goto | 无条件跳转 |
| sizeof | 计算对象所占内存空间大小’ |
二、用法
下面就一一讲解这些关键字,但讲解之前要先明确两个概念:
什么是定义?什么是声明?
举个例子:
a)int i;
b) extern int i;
哪个是定义,哪个是声明?或者都是定义还是都是声明?这个概念十分重要。
什么是定义:定义就是(编译器)创建一个对象,为这个对象分配一块内存并给它去一个名字,这个人名字就是变量名。但注意,这个名字一旦和这块内存匹配起来,他们就共同生死,终生不离不弃。并且这块内存的位置也不能被改变。一个变量或对象在一定的区域内只能被定义一次,如果多次定义,编译器会提示你重复定义。
什么是声明:有两重含义,如下:
第一重含义:告诉编译器,这个名字已经匹配到一块内存上了,下面的代码用到变量或对象是在别的地方定义的。声明可以出现多次。
第二重含义:告诉编译器,我这个名字我先预定了,别的地方再也不能用它来作为变量名或对象名。比如你在图书馆自习室的某个座位上放了一本书,表明这个座位已经有人预订,别人再也不允许使用这个座位。其实这个时候你本人并没有坐在这个座位上。这种声明最典型的例子就是函数参数的声明,例如:
void fun(int i, char c);
好,这样一解释,我们可以很清楚的判断:A)是定义;B)是声明。
那他们的区别也很清晰了。记住,定义声明最重要的区别:定义创建了对象并为这个
对象分配了内存,声明没有分配内存。
2.1auto
auto:编译器在默认的缺省情况下,所有变量都是 auto 的。
2.2 register
register:这个关键字请求编译器尽可能的将变量存在 CPU 内部寄存器中而不是通过内存寻址访问以提高效率。注意是尽可能,不是绝对。你想想,一个 CPU 的寄存器也就那么几个或几十个,你要是定义了很多很多 register 变量,它累死也可能不能全部把这些变量放入寄存器吧,轮也可能轮不到你。
不知道什么是寄存器?那见过太监没有?没有?其实我也没有。没见过不要紧,见过就麻烦大了。_,大家都看过古装戏,那些皇帝们要阅读奏章的时候,大臣总是先将奏章交给皇帝旁边的小太监,小太监呢再交给皇帝同志处理。这个小太监只是个中转站,并无别的功能。
好,那我们再联想到我们的 CPU。CPU 不就是我们的皇帝同志么?大臣就相当于我们的内存,数据从他这拿出来。那小太监就是我们的寄存器了(这里先不考虑 CPU 的高速缓存区)。数据从内存里拿出来先放到寄存器,然后 CPU 再从寄存器里读取数据来处理,处理完后同样把数据通过寄存器存放到内存里,CPU 不直接和内存打交道。这里要说明的一点是:小太监是主动的从大臣手里接过奏章,然后主动的交给皇帝同志,但寄存器没这么自觉, 它从不主动干什么事。一个皇帝可能有好些小太监,那么一个 CPU 也可以有很多寄存器, 不同型号的 CPU 拥有寄存器的数量不一样。
为啥要这么麻烦啊?速度!就是因为速度。寄存器其实就是一块一块小的存储空间,只不过其存取速度要比内存快得多。进水楼台先得月嘛,它离 CPU 很近,CPU 一伸手就拿到数据了,比在那么大的一块内存里去寻找某个地址上的数据是不是快多了?那有人问既然它速度那么快,那我们的内存硬盘都改成寄存器得了呗。我要说的是:你真有钱!
使用register 修饰符的注意点
虽然寄存器的速度非常快,但是使用 register 修饰符也有些限制的:register 变量必须是能被 CPU 寄存器所接受的类型。意味着 register 变量必须是一个单个的值,并且其长度应小于或等于整型的长度。 而且 register 变量可能不存放在内存中,所以不能用取址运算符“&” 来获取 register 变量的地址。
2.3static
static 在C语言里主要有两个作用,C++对他进行了扩展
第一个作用:修饰变量。变量又分为局部和全局变量,但它们都存在内存的静态区。静态全局变量,作用域仅限于变量被定义的文件中,其他文件即使用 extern 声明也没法
使用他。准确地说作用域是从定义之处开始,到文件结尾处结束,在定义之处前面的那些代码行也不能使用它。想要使用就得在前面再加 extern ***。恶心吧?要想不恶心,很简单,直接在文件顶端定义不就得了。
静态局部变量,在函数体里面定义的,就只能在这个函数里用了,同一个文档中的其他函数也用不了。由于被 static 修饰的变量总是存在内存的静态区,所以即使这个函数运行结束,这个静态变量的值还是不会被销毁,函数下次使用时仍然能用到这个值。
第二个作用:修饰函数
函数前加 static 使得函数成为静态函数。但此处“static”的含义不是指存储方式,而是指对函数的作用域仅局限于本文件(所以又称内部函数)。使用内部函数的好处是:不同的人编写不同的函数时,不用担心自己定义的函数,是否会与其它文件中的函数同名。
关键字 static 有着不寻常的历史。起初,在 C 中引入关键字 static 是为了表示退出一个块后仍然存在的局部变量。随后,static 在 C 中有了第二种含义:用来表示不能被其它文件访问的全局变量和函数。为了避免引入新的关键字,所以仍使用 static 关键字来表示这第二种含义。
2.4基本数据类型
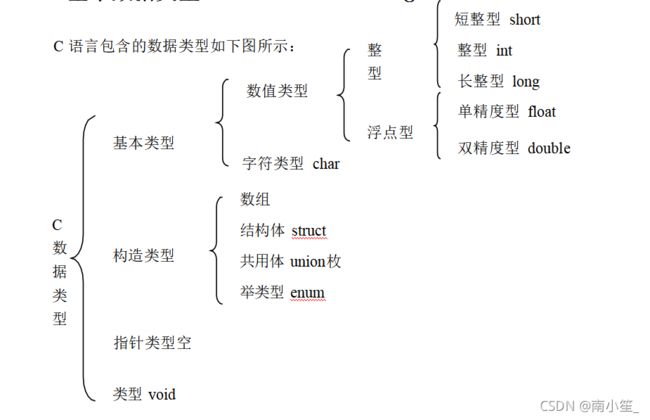 short、int、long、char、float、double 这六个关键字代表 C 语言里的六种基本数据类型。
short、int、long、char、float、double 这六个关键字代表 C 语言里的六种基本数据类型。
怎么去理解它们呢? 举个例子:见过藕煤球的那个东西吧?(没见过?煤球总见过吧)。那个东西叫藕煤器,拿着它在和好的煤堆里这么一咔,一个煤球出来了。半径 12cm,12 个孔。不同型号的藕煤器咔出来的煤球大小不一样,孔数也不一样。这个藕煤器其实就是个模子。
现在我们联想一下,short、int、long、char、float、double 这六个东东是不是很像不同类型的藕煤器啊?拿着它们在内存上咔咔咔,不同大小的内存就分配好了,当然别忘了给 它们取个好听的名字。在 32 位的系统上 short 咔出来的内存大小是 2 个byte;int 咔出来的内存大小是4 个byte;long 咔出来的内存大小是4 个byte;float 咔出来的内存大小是4 个byte;
double 咔出来的内存大小是 8 个byte;char 咔出来的内存大小是 1 个 byte。(注意这里指一般情况,可能不同的平台还会有所不同,具体平台可以用 sizeof 关键字测试一下)
很简单吧?咔咔咔很爽吧?是很简单,也确实很爽,但问题就是你咔出来这么多内存块, 你总不能给他取名字叫做x1,x2,x3,x4,x5…或者长江 1 号,长江 2 号…吧。它们长得这么像(不是你家的老大,老二,老三…),过一阵子你就会忘了到底哪个名字和哪个内存块匹配了(到底谁嫁给谁了啊?_)。所以呢,给他们取一个好的名字绝对重要。下面我们就来研究研究取什么样的名字好。
2.5sizeof
sizeof 是关键字不是函数,其实就算不知道它是否为 32 个关键字之一时,我们也可以借助编译器确定它的身份。看下面的例子:
int i=0;
A),sizeof(int); B),sizeof(i); C),sizeof int; D),sizeof i; 毫无疑问,32 位系统下 A),B)的值为 4。那C)的呢?D)的呢?
在 32 位系统下,通过 Visual C++6.0 或任意一编译器调试,我们发现 D)的结果也为 4。咦?sizeof 后面的括号呢?没有括号居然也行,那想想,函数名后面没有括号行吗?由此轻易得出 sizeof 绝非函数。
好,再看 C)。编译器怎么怎么提示出错呢?不是说 sizeof 是个关键字,其后面的括号可以没有么?那你想想 sizeof int 表示什么啊?int 前面加一个关键字?类型扩展?明显不正确,我们可以在 int 前加 unsigned,const 等关键字但不能加 sizeof。好,记住:sizeof 在计算变量所占空间大小时,括号可以省略,而计算类型(模子)大小时不能省略。一般情况下, 咱也别偷这个懒,乖乖的写上括号,继续装作一个“函数”,做一个“披着函数皮的关键字”。做我的关键字,让人家认为是函数去吧。
sizeof(int)*p 表示什么意思?
sizeof(int)*p 表示什么意思?
留几个问题(讲解指针与数组时会详细讲解),32 位系统下:
int *p = NULL;
sizeof§的值是多少?
sizeof(*p)呢?
int a[100];
sizeof (a) 的值是多少?
sizeof(a[100])呢?//请尤其注意本例。
sizeof(&a)呢?
sizeof(&a[0])呢?
int b[100];
void fun(int b[100])
{
sizeof(b);// sizeof (b) 的值是多少?
}
2.6 singed 、unsigned 关键字
我们知道计算机底层只认识 0、1.任何数据到了底层都会变计算转换成 0、1.那负数怎么存储呢?肯定这个“-”号是无法存入内存的,怎么办?很好办,做个标记。把基本数据类型的最高位腾出来,用来存符号,同时约定如下:最高位如果是 1,表明这个数是负数,其值为除最高位以外的剩余位的值添上这个“-”号;如果最高位是 0,表明这个数是正数, 其值为除最高位以外的剩余位的值。
这样的话,一个 32 位的 signed int 类型整数其值表示法范围为:- 231 ~ 231 -1;8 位的
char 类型数其值表示的范围为- 27 ~ 27 -1。一个 32 位的 unsigned int 类型整数其值表示法
范围为:0~
232 -1;8 位的 char 类型数其值表示的范围为 0~ 28 -1。同样我们的 signed 关
键字也很宽恒大量,你也可以完全当它不存在,编译器缺省默认情况下数据为 signed 类型的。
上面的解释很容易理解,下面就考虑一下这个问题:
int main()
{
char a[1000]; int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a)); return 0;
}
此题看上去真的很简单,但是却鲜有人答对。答案是 255。别惊讶,我们先分析分析。
for 循环内,当 i 的值为 0 时,a[0]的值为-1。关键就是-1 在内存里面如何存储。
我们知道在计算机系统中,数值一律用补码来表示(存储)。主要原因是使用补码,可以将符号位和其它位统一处理;同时,减法也可按加法来处理。另外,两个用补码表示的数相加时,如果最高位(符号位)有进位,则进位被舍弃。正数的补码与其原码一致;负数的补码:符号位为 1,其余位为该数绝对值的原码按位取反,然后整个数加 1。
按照负数补码的规则,可以知道-1 的补码为 0xff,-2 的补码为 0xfe……当 i 的值为 127 时,a[127]的值为-128,而-128 是char 类型数据能表示的最小的负数。当 i 继续增加,a[128] 的值肯定不能是-129。因为这时候发生了溢出,-129 需要 9 位才能存储下来,而 char 类型数据只有 8 位,所以最高位被丢弃。剩下的 8 位是原来 9 位补码的低 8 位的值,即 0x7f。当 i 继续增加到 255 的时候,-256 的补码的低 8 位为 0。然后当i 增加到 256 时,-257 的补码的低 8 位全为 1,即低八位的补码为 0xff,如此又开始一轮新的循环……
按照上面的分析,a[0]到 a[254]里面的值都不为 0,而 a[255]的值为 0。strlen 函数是计算字符串长度的,并不包含字符串最后的‘\0’。而判断一个字符串是否结束的标志就是看是否遇到‘\0’。如果遇到‘\0’,则认为本字符串结束。
分析到这里,strlen(a)的值为 255 应该完全能理解了。这个问题的关键就是要明白 char 类型默认情况下是有符号的,其表示的值的范围为[-128,127],超出这个范围的值会产生溢出。另外还要清楚的就是负数的补码怎么表示。弄明白了这两点,这个问题其实就很简单了。
留三个问题:
1),按照我们上面的解释,那-0 和+0 在内存里面分别怎么存储?
2),int i = -20;
unsigned j = 10;
i+j 的值为多少?为什么?
3), 下面的代码有什么问题?
unsigned i ;
for (i=9;i>=0;i–)
{
printf("%u\n",i);
}
2.7 if 、else
•float 变量与“零值”进行比较
float 变量与“零值”进行比较的 if 语句怎么写?
float fTestVal = 0.0;
A), if(fTestVal == 0.0); if(fTestVal != 0.0);
B), if((fTestVal >= -EPSINON) && (fTestVal <= EPSINON)); //EPSINON 为定义好的精度。
哪一组或是那些组正确呢?我们来分析分析:
float 和 double 类型的数据都是有精度限制的,这样直接拿来与 0.0 比,能正确吗?明显
不能,看例子:
的值四舍五入精确到小数点后 10 位为:3.1415926536,你拿它减去
0.00000000001 然后再四舍五入得到的结果是多少?你能说前后两个值一样吗?
EPSINON 为定义好的精度,如果一个数落在[0.0-EPSINON,0.0+EPSINON] 这个闭区间内,我们认为在某个精度内它的值与零值相等;否则不相等。扩展一下,把 0.0 替换为你想比较的任何一个浮点数,那我们就可以比较任意两个浮点数的大小了,当然是在某个精度内。
同样的也不要在很大的浮点数和很小的浮点数之间进行运算,比如:
10000000000.00 + 0.00000000001
这样计算后的结果可能会让你大吃一惊。
2.8 switch case
case 关键字后面的值有什么要求吗?
case 后面只能是整型或字符型的常量或常量表达式