Hive On Spark 概述、安装配置、计算引擎更换、应用、异常解决
文章目录
-
- Hadoop 安装
- Hive 安装
- Hive On Spark 与 Spark On Hive 区别
-
- Hive On Spark
- Spark On Hive
- 部署 Hive On Spark
-
- 查询 Hive 对应的 Spark 版本号
- 下载 Spark
- 解压 Spark
- 配置环境变量
- 指定 Hadoop 路径
- 在 Hive 配置 Spark 参数
- 上传 Jar 包并更换引擎
- 测试 Hive On Spark
- 解决依赖冲突问题
前言: 本篇文章在已经安装 Hadoop 3.3.4 与 Hive 3.1.3 版本的基础上进行,与笔者版本不一致也没有关系,按照步骤来就行了。
Hadoop 安装
详情查看我的这篇博客:Hadoop 完全分布式搭建(超详细)
Hive 安装
详情查看我的这篇博客:Hive 搭建(将 MySQL 作为元数据库)
Hive On Spark 与 Spark On Hive 区别
Hive On Spark
在 Hive 中集成 Spark,Hive 既作为元数据存储,又负责解析 HQL 语句,只是将 Hive 的运行引擎更换为 Spark,由 Spark 负责运算工作,而不再是默认的 MR 引擎,但部署较为复杂。
Spark On Hive
Hive 只负责元数据存储,由 Spark 来解析与执行 SQL 语句,其中的 SQL 语法为 Spark SQL,且部署简单。
Spark on Hive 的优点在于它提供了更灵活的编程接口,适用于各种数据处理需求,但性能可能不如 Hive on Spark,特别是在处理复杂查询时。
部署 Hive On Spark
查询 Hive 对应的 Spark 版本号
每个 Hive 版本适配的 Spark 都不相同,使用的 Spark 版本必须与 Hive 源码中指定的版本一致,或者重新编译源码,更换成需要的版本。
我这里使用的 Hive 版本为 3.1.3,现在通过官方网站 —— Index of /hive
获取对应版本的 Hive 源码。

下载完成后,解压缩,在主目录下找到 pom.xml 文件:
直接通过浏览器打开该文件,搜索 spark.version 即可查询到对应的 Spark 版本。

可以看到 Hive 3.1.3 对应的 Spark 版本为 2.3.0,如果你不想使用该版本,那么使用 IDEA 打开该项目,在该 pom.xml 文件中修改你需要的 Spark 版本,然后使用 maven 重新打包,重新安装 Hive 即可。
我这里就不在重新编译了,该 Spark 版本已经可以满足我的使用需求。
下载 Spark
在 Spark 官方网站直接下载 —— Index of /dist/spark
找到对应版本进行下载,这里需要注意选择纯净版的包下载,如下所示:
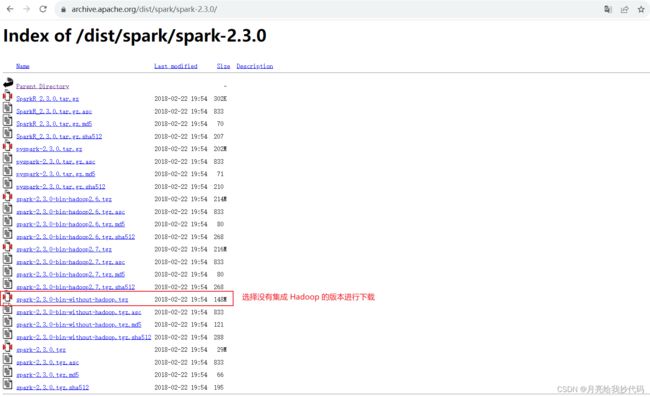
选择 without-hadoop 没有集成 Hadoop 的 Spark 版本进行下载,这样 Spark 就会使用集群系统中安装的 Hadoop。
将下载好的包上传到集群中,下面开始安装部署 Spark。
注意,请将下列提到的路径替换为你自己实际的存储路径!!!不一定需要和我一样。
解压 Spark
tar -xvf spark-2.3.0-bin-without-hadoop.tgz -C /opt/module/
顺手改个名字
cd /opt/module
mv spark-2.3.0-bin-without-hadoop/ spark-2.3.0
配置环境变量
vim /etc/profile
文件末尾添加:
#SPAKR_HOME
export SPARK_HOME=/opt/module/spark-2.3.0
export PATH=$PATH:$SPARK_HOME/bin
刷新环境变量:source /etc/profile
指定 Hadoop 路径
因为我们的版本选择的纯净版,所以需要在 Spark 环境文件中指定已经安装的 Hadoop 路径。
cd $SPARK_HOME/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
在该文件末尾添加,指定 Hadoop 路径:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
添加完成之后,保存并退出。
其中 $(hadoop classpath) 的作用是获取 Hadoop 类路径的值 (需要提前配置 Hadoop 的环境变量,否则获取不到) ,我们可以直接打印看看它存储的内容:

在 Hive 配置 Spark 参数
进入 Hive 的 conf 目录中,创建 Spark 配置文件,指定相关参数。
cd $HIVE_HOME/conf
vim spark-default.conf
添加如下配置内容:
# 指定提交到 yarn 运行
spark.master yarn
# 开启日志并存储到 HDFS 上
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop120:8020/spark-logDir
# 指定每个执行器的内存
spark.executor.memory 1g
# 指定每个调度器的内存
spark.driver.memory 1g
配置文件创建完成后,在 HDFS 上创建 Spark 的日志存储目录。
hadoop fs -mkdir /spark-logDir
上传 Jar 包并更换引擎
因为只在一台机器上安装了 Hive 和 Spark,所以当我们将任务提交到 Yarn 上进行调度时,可能会将该任务分配到其它节点,这就会导致任务无法正常运行,所以我们需要将 Spark 中的所有 Jar 包到 HDFS 上,并告知 Hive 其存储的位置。
上传文件
hadoop fs -mkdir /spark-jars
cd $SPARK_HOME
hadoop fs -put ./jars/* /spark-jars
在 Hive 的配置文件中指定 Spark jar 包的存放位置:
cd $HIVE_HOME/conf
vim hive-site.xml
在其中添加下列三项配置:
<property>
<name>spark.yarn.jarsname>
<value>hdfs://hadoop120:8020/spark-jars/*value>
property>
<property>
<name>hive.execution.enginename>
<value>sparkvalue>
property>
<property>
<name>hive.spark.client.connect.timeoutname>
<value>5000value>
property>
配置项添加完成后,我们就配置好了 Hive On Spark,下面对其进行测试。
测试 Hive On Spark
进入 Hive 中创建测试表:
drop table if exists books;
create table books(id int,book_name string);
写入测试数据:
insert into books values (1,'bigdata');
insert into books values (2,'hive');
insert into books values (3,'spark');

注意,每次打开终端的首次 MR 操作会消耗比较多的时间,要去与 Yarn 建立连接、分配资源等,大概
30s至1m左右。
程序运行时,可以访问其给出的 WEB URL 地址(http://hadoop120:45582 不固定),访问后如下所示:

可以看到运行速度还是嘎嘎快的(真是受够了 MR!):

查询结果:
select * from books;

数据插入完成,测试成功。
解决依赖冲突问题
当我们在使用 Hive On Spark 时,可能会发生如下依赖冲突问题:
Job failed with java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.<init>()V from class org.apache.hadoop.mapreduce.lib.input.FileInputFormat
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:262)
at org.apache.hadoop.hive.shims.Hadoop23Shims$1.listStatus(Hadoop23Shims.java:134)
at org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:217)
at org.apache.hadoop.mapred.lib.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:75)
at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileInputFormatShim.getSplits(HadoopShimsSecure.java:321)
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getCombineSplits(CombineHiveInputFormat.java:444)
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getSplits(CombineHiveInputFormat.java:564)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:200)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:253)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:251)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:251)
at org.apache.spark.rdd.RDD.getNumPartitions(RDD.scala:267)
at org.apache.spark.api.java.JavaRDDLike$class.getNumPartitions(JavaRDDLike.scala:65)
at org.apache.spark.api.java.AbstractJavaRDDLike.getNumPartitions(JavaRDDLike.scala:45)
at org.apache.hadoop.hive.ql.exec.spark.SparkPlanGenerator.generateMapInput(SparkPlanGenerator.java:215)
at org.apache.hadoop.hive.ql.exec.spark.SparkPlanGenerator.generateParentTran(SparkPlanGenerator.java:142)
at org.apache.hadoop.hive.ql.exec.spark.SparkPlanGenerator.generate(SparkPlanGenerator.java:114)
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient$JobStatusJob.call(RemoteHiveSparkClient.java:359)
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:378)
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:343)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime. Please check stacktrace for the root cause.
这是由于 Hive 中的 guava 包版本比较高,与 Spark 不太兼容,所以我们需要更换为低一点的版本,建议使用 guava-13.0.jar 版本。
Jar 包获取地址:Maven 仓库
# 备份 Hive 的高版本
cd $HIVE_HOME/lib
mv guava-19.0.jar guava-19.0.jar.bak
# 将低版本放入 Hive 与 Spark 中
cp guava-13.0.jar $HIVE_HOME/lib
cp guava-13.0.jar $SPARK_HOME/jars
# 还需上传到 HDFS 中存储 Spark Jars 的目录下
hadoop fs -put guava-13.0.jar /spark-jars
重新启动 Hive 终端就可以生效啦。