C/C++ 中的指针[非常全面]
写在最前面
这篇博客很长,基本包含了所有指针及指针相关的知识以及一些细节;相应的可能会有一些罗嗦;认真看完一定会有所收获(大佬除外)!
指针
变量被解释为计算机内存中的位置,可以通过它们的标识符(它们的名字)访问。这样,程序就不需要关心内存中数据的物理地址; 它只是在需要引用变量时使用标识符。
对于 C + + 程序来说,计算机的内存就像一连串的内存单元,每个单元的大小都是一个字节,每个单元的地址都是唯一的。这些单字节内存单元的排序方式允许大于一个字节的数据表示占用具有连续地址的内存单元。
这样,每个单元就可以通过其唯一地址很容易地定位在内存中。例如,地址为1776的内存单元总是紧跟在地址为1775的单元之后,在地址为1777的单元之前,正好是776之后的1000个单元,正好是2776之前的1000个单元。
当声明一个变量时,需要存储它的值被分配到内存中的一个特定位置(它的内存地址)。一般来说,C + + 程序不会主动确定其变量存储在确切内存地址。这个任务留给了运行程序的环境——通常是一个操作系统,它决定运行时的特定内存位置。然而,程序能够在运行时获取变量的地址,以便访问相对于变量处于某个位置的数据单元,这是有用的。
取地址运算符(&)
变量的地址可以通过在变量名前面加上与号(&)(称为取地址运算符操作符)来获得。例如:
|
|
这会将变量 myvar 的地址分配给 foo; 通过在变量 myvar 的名称前面加上 运算符 & ,我们不再将变量本身的内容分配给 foo,而是将其地址分配给 foo。
内存中变量的实际地址在运行时之前无法知道,但是为了帮助澄清一些概念,我们假设 myvar 在运行时放置在内存地址1776中。
在这种情况下,考虑以下代码片段:
|
每个变量执行后所包含的值如下图所示:
![C/C++ 中的指针[非常全面]_第1张图片](http://img.e-com-net.com/image/info8/ff20e728327c4c23a978965775720fa5.png)
首先,我们将值25赋给 myvar (一个变量,我们假设它在内存中的地址为1776)。
第二个语句指定 myvar 的地址,我们假设它是1776。
最后,第三个语句将 myvar 中包含的值赋给 bar。这是一个标准的分配操作。
第二个语句和第三个语句之间的主要区别是操作符(&)的出现。
存储另一个变量地址的变量(如前面示例中的 foo)在 C + + 中称为指针。指针是该语言的一个非常强大的特性,在低级编程中有许多用途。稍后,我们将看到如何声明和使用指针。
解引用运算符 (*)
如前所述,存储另一个变量地址的变量称为指针。指针被称为“指向”它们所存储的地址的变量。
指针的一个有趣的属性是,它们可以用来直接访问它们指向的变量。这是通过在指针名称前面加上解引用运算符(*)来完成的。操作符本身可以被读作“指向的值”。
因此,根据上一个示例的值,下面的语句:
baz = *foo;
这可以理解为: “ baz 等于 foo 指向的值”,这个语句实际上将值25赋给 baz,因为 foo 是1776,而1776指向的值(遵循上面的例子)是25。
![C/C++ 中的指针[非常全面]_第2张图片](http://img.e-com-net.com/image/info8/ab6754f33a8c4d479cbf2f8aa14d20e5.png)
清楚地区分 foo 指的是1776,而 * foo (标识符前面带有星号 *)指的是存储在地址1776的值,在本例中为25,这一点很重要。注意包含或不包含解引用运算符的区别(我已经添加了如何解读这两个表达的解释性注释) :
baz = foo; // baz equal to foo (1776)
baz = *foo; // baz equal to value pointed to by foo (25)
因此,引用运算符和解引用运算符是相辅相成的:
&是地址操作符,可以简单地理解为“某某的地址”*是解引用运算符,可以理解为“指向的值”
因此,它们有相反的含义: 用 & 获得的地址可以用 * 解引用。
前面,我们执行了以下两个赋值操作:
|
执行上述两个语句之后,下列所有表达式的结果都是 true:
|
声明指针
由于指针能够直接引用它所指向的值,所以当指向 char 时,指针与指向 int 或 float 时具有不同的属性。一旦解引用,就需要知道类型。为此,指针的声明需要包含指针要指向的数据类型。
指针的声明遵循以下语法:type * name;
其中 type 是指针指向的数据类型。此类型不是指针本身的类型,而是指针指向的数据的类型。例如:
int * number; char * character; double * decimals;
这是指针的三个声明。每个指针都指向一种不同的数据类型,但实际上,它们都是指针,并且所有指针都可能占用相同的内存空间(指针的内存大小取决于程序运行的平台)。然而,它们所指向的数据不占用相同的空间,也不属于相同的类型: 第一个指向 int,第二个指向 char,最后一个指向 double。因此,尽管这三个示例变量都是指针,但它们实际上有不同的类型: int * 、 char * 和 double * ,这取决于它们指向的类型。
注意,在声明一个指针时使用的星号(*)仅表示它是一个指针(它是它的类型复合说明符的一部分) ,不应该与之前看到的解引用运算符混淆,但它也是用星号(*)写的。它们只是用同一个符号表示的两个不同的东西。
让我们看一个关于指针的例子:
// my first pointer
#include
using namespace std;
int main ()
{
int firstvalue, secondvalue;
int * mypointer;
mypointer = &firstvalue;
*mypointer = 10;
mypointer = &secondvalue;
*mypointer = 20;
cout << "firstvalue is " << firstvalue << '\n';
cout << "secondvalue is " << secondvalue << '\n';
return 0;
} 输出: firstvalue is 10 secondvalue is 20
在 cpp.sh 中编辑和运行
注意,即使第一个值和第二个值都没有在程序中直接设置任何值,最终都会通过使用 mypoint 间接设置一个值。
为了证明一个指针在程序的生命周期内可以指向不同的变量,这个示例使用第二个值和同一个指针 mypoint 重复这个过程。
这里有一个更详细的例子:
// more pointers
#include
using namespace std;
int main ()
{
int firstvalue = 5, secondvalue = 15;
int * p1, * p2;
p1 = &firstvalue; // p1 = address of firstvalue
p2 = &secondvalue; // p2 = address of secondvalue
*p1 = 10; // value pointed to by p1 = 10
*p2 = *p1; // value pointed to by p2 = value pointed to by p1
p1 = p2; // p1 = p2 (value of pointer is copied)
*p1 = 20; // value pointed to by p1 = 20
cout << "firstvalue is " << firstvalue << '\n';
cout << "secondvalue is " << secondvalue << '\n';
return 0;
} 输出: firstvalue is 10 secondvalue is 20
Edit & run on cpp.sh
另一件事提醒注意的是
int * p1, * p2;
这声明了前面示例中使用的两个指针。但是请注意,每个指针都有一个星号(*) ,以便两者都有 int * (指向 int 的指针)类型。由于优先级规则,这是必需的。注意,如果代码是:
int * p1, p2;
P1的确是 int * 类型,但是 p2的类型是 int。对于这个目的,空间一点也不重要。但是无论如何,对于大多数对每条语句声明多个指针感兴趣的指针用户来说,只要记住在每个指针上加一个星号就足够了。或者更好: 对每个变量使用不同的语句。
指针和数组
数组的概念与指针的概念有关。实际上,数组的工作方式非常类似于指向它们的第一个元素的指针,而且,实际上,数组总是可以隐式地转换为适当类型的指针。例如,考虑以下两个声明:
int myarray [20]; int * mypointer;
下面的赋值操作是有效的:
mypointer = myarray;
之后,mypoint 和 myarray 将是等价的,并且具有非常相似的属性。主要的区别在于,我的指针可以被赋予一个不同的地址,而 myarray 永远不能被赋予任何东西,并且总是表示同一块20个 int 类型的元素。因此,下列转让无效:
myarray = mypointer;
让我们看一个混合数组和指针的例子:
// more pointers
#include
using namespace std;
int main ()
{
int numbers[5];
int * p;
p = numbers; *p = 10;
p++; *p = 20;
p = &numbers[2]; *p = 30;
p = numbers + 3; *p = 40;
p = numbers; *(p+4) = 50;
for (int n=0; n<5; n++)
cout << numbers[n] << ", ";
return 0;
} 输出:
10, 20, 30, 40, 50,
Edit & run on cpp.sh
指针和数组支持相同的操作集,两者的含义相同。主要区别在于,指针可以分配新的地址,而数组不能。
在关于数组的章节中,方括号([])被解释为指定数组元素的索引。实际上,这些括号是一个解引用运算符,称为偏移运算符。它们像 * 一样解引用它们所跟随的变量,但是它们也将括号之间的数字添加到被解引用的地址。例如:
a[5] = 0; // a [offset of 5] = 0 *(a+5) = 0; // pointed to by (a+5) = 0
这两个表达式是等价和有效的,a不仅 是一个指针,而且 是一个数组。请记住,数组,它的名称可以像指向其第一个元素的指针一样使用。
指针初始化
指针可以初始化为在定义时指向特定位置的指针
int myvar; int * myptr = &myvar;
等同于:
int myvar; int * myptr; myptr = &myvar;
初始化指针时,初始化的是指向的地址(即 myptr) ,而不是指向的值(即 * myptr)。因此,上述守则不得与以下面混淆:
int myvar; int * myptr; *myptr = &myvar;无论如何,这都没有多大意义(而且也不是有效的代码)。
可以将指针初始化为变量的地址(如上例所示) ,也可以初始化为另一个指针(或数组)的值:
int myvar; int *foo = &myvar; int *bar = foo;
指针算术
对指针进行算术运算与对正则整数类型进行算术运算略有不同。首先,只允许执行加法和减法操作; 其他操作在指针世界中毫无意义。但是,根据指针所指向的数据类型的大小,加法和减法在使用指针时的行为略有不同。
当引入基本数据类型时,我们看到类型具有不同的大小。例如: char 的大小总是1字节,short 通常比这个大,int 和 long 甚至更大; 它们的确切大小取决于系统。例如,假设在给定的系统中,char 占用1个字节,short 占用2个字节,long 占用4个字节。
假设现在我们在这个编译器中定义了三个指针:
char *mychar; short *myshort; long *mylong;
假设我们知道它们分别指向内存位置1000,2000和3000。
因此,如果我们写:
++mychar; ++myshort; ++mylong;
正如预期的那样,mychar 将包含值1001。但是不那么明显,myshort 将包含值2002,mylong 将包含3004,尽管它们每个只增加了一次。原因是,当向指针加1时,指针会指向下面同一类型的元素,因此,它所指向的类型的字节大小被添加到指针中。
![C/C++ 中的指针[非常全面]_第3张图片](http://img.e-com-net.com/image/info8/31e68c018792419db1233064e004eab8.png)
这适用于对指针进行任意数字的加减运算。如果我们写下:
|
关于递增(+ +)和递减(--)操作符,它们都可以用作表达式的前缀或后缀,但行为略有不同: 作为前缀,递增发生在计算表达式之前,作为后缀,递增发生在计算表达式之后。这也适用于递增和递减指针的表达式,这些指针可以成为更复杂的表达式的一部分,这些表达式还包括解引用操作符(*)。记住运算符优先级规则,我们可以回想起后缀运算符,如递增和递减,比前缀运算符,如解引用运算符(*)具有更高的优先级。因此,下面的表达:
*p++
等效于 * (p + +)。它所做的是增加 p 的值(所以它现在指向下一个元素) ,但是因为 + + 被用作后缀,所以整个表达式被计算为指针最初指向的值( 指向它在增加之前的地址)。
关于运算符优先级:c++ 运算符优先级表格
本质上,这些是解引用运算符与递增运算符的前缀和后缀版本的四种可能的组合(同样适用于递减运算符) :
*p++ // same as *(p++): increment pointer, and dereference unincremented address
*++p // same as *(++p): increment pointer, and dereference incremented address
++*p // same as ++(*p): dereference pointer, and increment the value it points to
(*p)++ // dereference pointer, and post-increment the value it points to
涉及这些运算符的一个典型但不那么简单的语句是:
*p++ = *q++;因为 + + 的优先级高于 * ,所以 p 和 q 都是递增的,但是因为两个递增运算符(+ +)都用作后缀而不是前缀,所以赋给 * p, * q 的值都是在递增之前 p 和 q。然后两者再递增的。这大致相当于:
*p = *q;
++p;
++q;
|
- tips:通过添加括号(),增加表达式的易读性来减少混淆。
指针与常量
指针可用于根据地址访问变量,这种访问可能包括修改指向的值。但也可以声明指针,这些指针可以访问指向的值来读取它,但不能修改它。对于这一点,将指针指向的类型限定为 const 就足够了。例如:
int x;
int y = 10;
const int * p = &y;
x = *p; // ok: reading p
*p = x; // error: modifying p, which is const-qualified
这里 p 指向一个变量,但是以一种常量限定的方式指向它,这意味着它可以读取指向的值,但是不能修改它。还要注意,表达式 & y 的类型为 int * ,但是它被赋值给类型为 const int * 的指针。这是允许的: 指向非常数的指针可以隐式转换为指向常数的指针。但不是反过来!作为一个安全特性,常量指针不能隐式转换为非常量指针。
指向 const 的元素的指针的用例之一是作为函数参数: 将非 const 指针作为参数的函数可以修改作为参数传递的值,而将 const 指针作为参数的函数则不能。
// pointers as arguments:
#include
using namespace std;
void increment_all (int* start, int* stop)
{
int * current = start;
while (current != stop) {
++(*current); // increment value pointed
++current; // increment pointer
}
}
void print_all (const int* start, const int* stop)
{
const int * current = start;
while (current != stop) {
cout << *current << '\n';
++current; // increment pointer
}
}
int main ()
{
int numbers[] = {10,20,30};
increment_all (numbers,numbers+3);
print_all (numbers,numbers+3);
return 0;
} 输出:
11 21 31
注意 print _ all 使用指向常量元素的指针。这些指针指向它们无法修改的常量内容,但它们本身不是常量: 也就是说,指针仍然可以递增或分配不同的地址,尽管它们无法修改它们指向的内容。
这就是将常量的第二个维度添加到指针的地方: 指针本身也可以是常量。这是通过将 const 附加到指定类型(在星号之后)来指定的:
int x;
int * p1 = &x; // non-const pointer to non-const int
const int * p2 = &x; // non-const pointer to const int
int * const p3 = &x; // const pointer to non-const int
const int * const p4 = &x; // const pointer to const int
使用 const 和指针的语法肯定是有难度的,并且识别最适合每种用法的情况往往需要一些经验。在任何情况下,尽早正确使用指针(和引用)获得常量都是很重要的,但是如果您第一次接触到常量和指针的混合,那么您不应该过于担心现在还没熟练掌握,慢慢熟悉它。
const 限定符可以在指针类型之前或之后,具有完全相同的含义:
const int * p2a = &x; // non-const pointer to const int
int const * p2b = &x; // also non-const pointer to const int
与星号周围的空格一样,本例中 const 的顺序只是一个样式问题。本章使用前缀 const,由于历史原因,这似乎更加扩展,但两者完全等价。每种风格的优点仍在互联网上激烈争论。
指针和字符串文字
字符串文字是包含以空结尾的字符序列的数组。但也可以直接访问。字符串文字是适当数组类型的数组,它包含所有字符和结束的 空字符('\0'),每个元素都是 const char 类型(作为文字,它们永远不能被修改)。例如:
const char * foo = "hello";
这将声明一个数组,其文字表示为“ hello”,然后将指向其第一个元素的指针分配给 foo。如果我们假设“ hello”存储在从地址1702开始的内存位置,我们可以将前面的声明表示为:
![C/C++ 中的指针[非常全面]_第4张图片](http://img.e-com-net.com/image/info8/cf5b7f84a2334de9a4d9f80c9b7eb1bd.png)
注意,这里 foo 是一个指针,包含值1702,而不是“ h”或“ hello”,尽管1702确实是这两个值的地址。
指针 foo 指向一个字符序列。由于指针和数组在表达式中的行为方式基本相同,foo 可以用来访问字符,其方式与以空结尾的字符序列的数组相同。例如:
*(foo+4)
foo[4]
两个表达式的值都为‘ o’(数组的第五个元素)。
指针指向指针
C + + 允许使用指向指针的指针,这些指针依次指向数据(甚至指向其他指针)。语法只需要在指针的声明中为每个间接级别加一个星号(*) :
|
假设为每个变量随机选择内存位置为7230、8092和10502,这可以表示为:
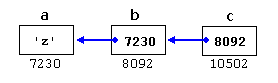
每个变量的值在对应的单元格中表示,它们各自在内存中的地址由它们下面的值表示。
例如新变量 c,它是一个指向指针的指针,可以在三个不同的间接级别中使用,每个级别对应一个不同的值:
- c的类型为 char * * ,值为8092
- * c 是 char * 类型,值为7230
- * * c 的类型为 char,值为‘ z’
空指针
指针的 void 类型是一种特殊类型的指针。在 C + + 中,void 表示没有类型。因此,void 指针是指向没有类型的值的指针(因此也是一个未确定的长度和未确定的解引用属性)。
这使 void 指针具有很大的灵活性,可以指向任何数据类型,从整数值或浮点数到字符串。作为代价,它们有一个很大的局限性: 它们指向的数据不能被直接解引用(这是合乎逻辑的,因为我们没有要解引用的类型) ,出于这个原因,void 指针中的任何地址都需要转换成具体数据类型的指针类型,然后才能被解引用。
它的一个可能用途是将泛型参数传递给函数,例如:
// increaser
#include
using namespace std;
void increase (void* data, int psize)
{
if ( psize == sizeof(char) )
{ char* pchar; pchar=(char*)data; ++(*pchar); }
else if (psize == sizeof(int) )
{ int* pint; pint=(int*)data; ++(*pint); }
}
int main ()
{
char a = 'x';
int b = 1602;
increase (&a,sizeof(a));
increase (&b,sizeof(b));
cout << a << ", " << b << '\n';
return 0;
} |
y, 1603 |
Sizeof 是一个集成在 C + + 语言中的运算符,它返回参数的大小(以字节为单位)。对于非动态数据类型,此值为常数。因此,例如,sizeof (char)为1,因为 char 的大小总是为一个字节。
无效指针和空指针
原则上,指针指向有效的地址,如变量的地址或数组中元素的地址。但是指针实际上可以指向任何地址,包括不引用任何有效元素的地址。典型的例子是指向数组中不存在元素的指针和未初始化的指针:
int * p; // 未初始化的指针(局部变量)uninitialized pointer (local variable)
// 为什么强调是局部变量,因为全局变量会有默认初始化
int myarray[10];
int * q = myarray+20; // 出界元素 || element out of bounds
P 和 q 都不指向已知包含值的地址,但是上面的语句都不会导致错误。在 C + + 中,指针可以获取任何地址值,不管这个地址上是否真的有什么东西。可能导致错误的是解引用这类指针(即,实际访问它们指向的值)。访问这类指针会导致未定义行为,从运行时的错误到访问一些随机值。
但是,有时候,指针确实需要显式地指向不存在的地方(nowhere:不知道如何翻译恰当,就翻译为不存在的地方,以下同),而不仅仅是一个无效的地址。对于这种情况,存在一个任何指针类型都可以使用的特殊值: 空指针值。这个值可以用两种方式在 C + + 中表示: 或者使用一个整数值为零,或者使用 nullptr 关键字:
int * p = 0; int * q = nullptr; // 一般使用第二种,见名知意
在这里,p 和 q 都是空指针,这意味着它们显式地指向不存在的地方,并且它们实际上相等: 所有空指针比较等于其他空指针。在旧代码中,定义的常量 NULL 用于引用空指针值也很常见:
int * r = NULL; // 一般是c语言的写法,c++ 写nullptr 更规范
NULL 在标准库的一些头文件中定义,被定义为某个空指针常量值(如0或 nullptr)的别名。
不要将空指针(null pointers)与空指针(void pointers)混淆!null指针是一个值,任何指针都可以用来表示它指向“不存在的地方”,而void指针是一种指向某处的指针,没有特定的类型。一个引用存储在指针中的值,另一个引用它所指向的数据类型。
函数指针
C + + 允许使用指向函数的指针进行操作。这种方法的典型用途是将函数作为参数传递给另一个函数。函数指针的声明语法与常规函数声明语法相同,只不过函数的名称被括在括号()之间,并在名称前插入星号(*) :
// pointer to functions
#include
using namespace std;
int addition (int a, int b)
{ return (a+b); }
int subtraction (int a, int b)
{ return (a-b); }
int operation (int x, int y, int (*functocall)(int,int))
{
int g;
g = (*functocall)(x,y);
return (g);
}
int main ()
{
int m,n;
int (*minus)(int,int) = subtraction;
m = operation (7, 5, addition);
n = operation (20, m, minus);
cout <
在上面的示例中,minus是指向具有两个 int 类型参数的函数的指针。它被直接初始化为指向函数subtraction:
int (* minus)(int,int) = subtraction;
函数指针在实际的主要的应用是回调函数,关于函数指针与回调函数的细节可以看下面的博客:
函数指针与回调函数
参考网址:https://cplusplus.com/doc/tutorial/pointers/
一个在线c++运行的网站(没有科学上网,可能有时打不开):C++ Shell