stable-diffusion的模型简介和下载使用
前言
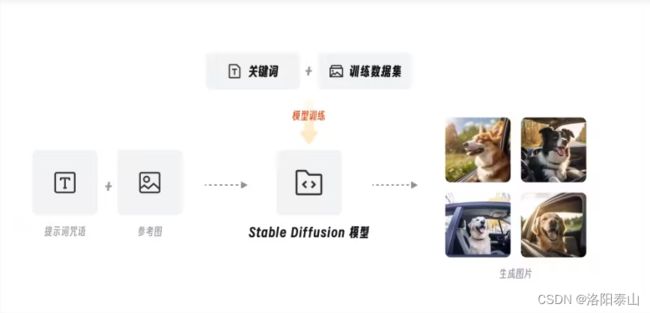
我们下载完stable-diffusion-ui后还需要下载需要的大模型,才能进行AI绘画的操作。秋叶的stable-diffusion-ui整合包内,包含了anything-v5-PrtRE.safetensors和Stable Diffusion-V1.5-final-prune_v1.0.ckpt两个模型。
-
anything-v5-PrtRE.safetensors模型可以用于生成多种类型的图像,包括肖像、风景、动物、卡通、科幻等,它具有较强的适应性和泛用性,效果表现出较强的真实感和细节还原能力。
-
Stable Diffusion-V1.5-final-prune_v1.0.ckpt模型是Stable Diffusion的一个版本,也具有生成多种图像的能力,同时它还具有较快的生成速度和较高的图像质量。这个模型在细节表现和风格化方面表现得更好,适合于需要快速生成高质量图像的应用场景。
因此,选择哪个模型取决于具体的应用场景和需求。如果需要生成多种类型的图像并且要求细节表现和泛用性较好,可以选择anything-v5-PrtRE.safetensors模型;如果需要快速生成高质量的图像,可以选择Stable Diffusion-V1.5-final-prune_v1.0.ckpt模型。
模型概念
先来看看模型在 Stable Diffusion 中到底是什么概念?在维基百科中对模型的定义非常简单:用一个较为简单的东西来代表另一个东西。换句话说,模型代表的是对某一种事物的抽象表达。
在 AIGC 领域,研发人员为了让机器表现出智能,使用机器学习的方式让计算机从数据中汲取知识,并按照人类所期望的方向执行各种任务。对于 AI 绘画而言,我们通过对算法程序进行训练,让机器来学习各类图片的信息特征,而在训练后沉淀下来的文件包,我们就将它称之为模型。用一句话来总结,模型就是经过训练学习后得到的程序文件。
常见的 AI绘画 用模型后缀名有如下几种:
.ckpt格式 ,.pt 格式,.pth格式,.safetensors格式
-
.ckpt格式 ,.pt 格式,.pth格式,这三种是 pytorch[2] 的标准模型保存格式,由于使用了 Pickle,会有一定的安全风险(自行百度:pickle反序列化攻击)。
-
.safetensors格式为一种新型的模型格式,正如同它的名字一样safe(安全)。为了解决前面的这几种模型的安全风险而出现的。.safetensors 格式与 pytorch 的模型可以通过工具进行任意转换,只是保存数据的方式不同,内容数据没有任何区别。
官方模型
如今市面上有如此多丰富的绘图模型,为什么 Stable Diffusion 官方模型还会被大家津津乐道?当然除了它本身能力强大外,更重要的是从零训练出这样一款完整架构模型的成本非常高。根据官方统计,Stable Diffusion v1-5 版本模型的训练使用了 256 个 40G 的 A100 GPU(专用于深度学习的显卡,对标 3090 以上算力),合计耗时 15 万个 GPU 小时(约 17 年),总成本达到了 60 万美元。
除此之外,为了验证模型的出图效果,伴随着上万名测试人员每天 170 万张的出图测试,没有海量的资源投入就不可能得到如今的 Stable Diffusion。这样一款模型能被免费开源,不得不说极大地推进了 AI 绘画技术的发展。
按理说这么大成本训练出来的模型,绘图效果应该非常强大吧?但实际体验过的朋友都知道,对比开源社区里百花齐放的绘图模型,官方模型的出图效果绝对算不上出众,甚至可以说有点拉垮,这是为什么呢?

前两个是Stable Diffusion官方的基础模型,后一个是别人用官方基础模型为底模训练的特定画风的模型。
这里我们用 ChatGPT 来对比就很好理解了。ChatGPT 的底层大模型是 GPT 模型,GPT 模型虽然包含了海量的基础知识,但并不能直接拿来使用,还需要经过人工微调和指导才能应用在实际生活中,而 ChatGPT 就是在聊天领域的应用程序。同理,Stable Diffusion 作为专注于图像生成领域的大模型,它的目的并不是直接进行绘图,而是通过学习海量的图像数据来做预训练,提升模型整体的基础知识水平,这样就能以强大的通用性和实用性状态完成后续下游任务的应用。
用更通俗的话来说,官方大模型像是一本包罗万象的百科全书,虽然集合了 AI 绘图所需的基础信息,但是无法满足对细节和特定内容的绘图需求,所以想由此直接晋升为专业的绘图工具还是有些困难。
常见模型解析
根据模型训练方法和难度的差异,我们可以将这些模型简单划分为 2 类:
一种是主模型(Checkpoint),另一种则是用于微调主模型的扩展模型(Embedding、Lora、Hyperbetwork)。
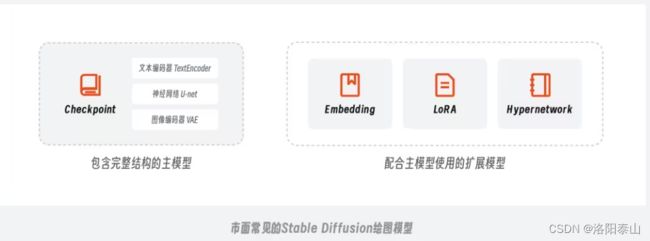
- 主模型指的是包含了 TextEncoder(文本编码器)、U-net(神经网络)和 VAE(图像编码器)的标准模型 Checkpoint,它是在官方模型的基础上通过全面微调得到的。但这样全面微调的训练方式对普通用户来说还是比较困难,不仅耗时耗力,对硬件要求也很高.
- 因此大家开始将目光逐渐转向训练一些扩展模型,比如 Embedding、LoRA 和 Hypernetwork扩展模型,通过它们搭配合适的主模型同样可以实现不错的控图效果。
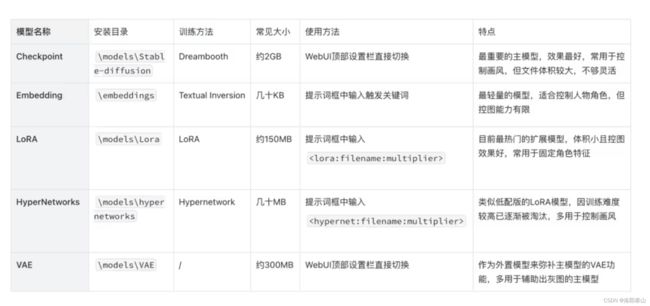
Checkpoint
- Checkpoint 模型,又称 Ckpt 模型或大模型、主模型、底模等。Checkpoint 翻译为中文叫检查点、关卡,之所以叫这个名字,是因为模型训练到关键位置时会进行存档,有点类似我们玩游戏时的保存进度,方便后面进行调用和回滚,比如官方的 v1.5 模型就是从 v1.2 的基础上调整得到的。
- Checkpoint 模型常见的文件格式有两种 .ckpt格式 ,.safetensors格式,需要放在sd-webui-aki(秋叶)或者stable-diffusion-ui根目录下的models\Stable-diffusion文件夹下,stable-diffusion-ui才能加载出来使用。
- Checkpoint模型是一种训练过程中保存模型参数的方法,它可以在训练过程中定期保存模型的参数,并在需要时恢复训练过程。这种方法通常用于训练时间较长的模型,以防止训练过程中的意外中断导致之前训练的结果丢失。
Embeddings
Embeddings(Textual Inversion)又被称作嵌入式向量,在之前初识篇的文章里我给大家介绍了 Stable Diffusion 模型包含文本编码器、扩散模型和图像编码器 3 个部分,其中文本编码器 TextEncoder 的作用是将提示词转换成电脑可以识别的文本向量,而 Embedding 模型的原理就是通过训练将包含特定风格特征的信息映射在其中,这样后续在输入对应关键词时,模型就会自动启用这部分文本向量来进行绘制。
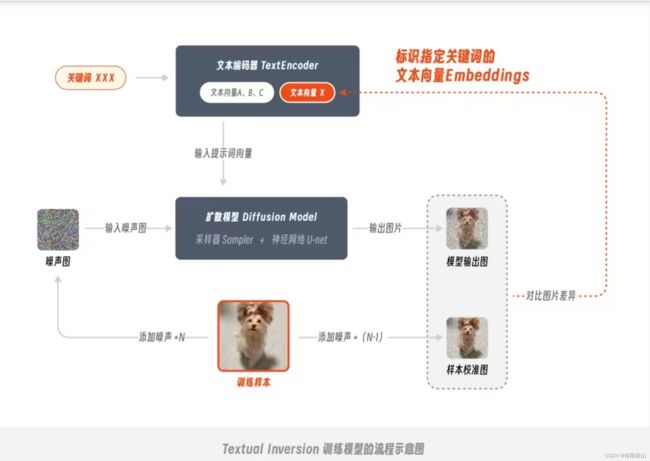
训练 Embeddings 模型的过程,由于是针对提示文本部分进行操作,所以该训练方法叫做 Textual Inversion 文本倒置,平时在社区中提到 Embeddings 和 Textual Inversion 时,指的都是同一种模型。
为了方便理解,你可以吧Embeddings 嵌入式模型,理解成一堆特定图片特征信息的的提示词。Embeddings/Textual Inversion需要搭配Checkpoint模型使用,常作用AI绘画中的反向提示词。
LoRA
LoRA 是 Low-Rank Adaptation Models 的缩写,意思是低秩适应模型。LoRA 原本并非用于 AI 绘画领域,它是微软的研究人员为了解决大语言模型微调而开发的一项技术,因此像 GPT3.5 包含了 1750 亿量级的参数,如果每次训练都全部微调一遍体量太大,而有了 lora 就可以将训练参数插入到模型的神经网络中去,而不用全面微调。通过这样即插即用又不破坏原有模型的方法,可以极大的降低模型的训练参数,模型的训练效率也会被显著提升。
相较于Checkpoint模型训练的方法,LoRA 的训练参数可以减少上千倍,对硬件性能的要求也会急剧下降,如果说 Embeddings 像一张标注的便利贴,那 LoRA 就像是额外收录的夹页,在这个夹页中记录了更全面图片特征信息。
由于需要微调的参数量大大降低,LoRA 模型的文件大小通常在几百 MB,比 Embeddings 丰富了许多,但又没有 Ckpt 那么臃肿。模型体积小、训练难度低、控图效果好,多方优点加持下 LoRA 收揽了大批创作者的芳心,在开源社区中有大量专门针对 LoRA 模型设计的插件,可以说是目前最热门的模型之一。
那 LoRA 模型具体有哪些应用场景呢?总结成一句话就是固定目标的特征形象,这里的目标既可以是人也可以是物,可固定的特征信息就更加保罗万象了,从动作、年龄、表情、着装,到材质、视角、画风等都能复刻。因此 LoRA 模型在动漫角色还原、画风渲染、场景设计等方面都有广泛应用。比如你训练了一个固定动漫角色人物的loRA,搭配写实的Checkpoint模型,就会生成逼真的人物,搭配二次元就会生成二次元风格的人物等等。
安装 LoRA 模型的方法和前面大同小异,将模型保存在\models\Lora 文件夹即可,在实际使用时,我们只需选中希望使用的 LoRA 模型,在提示词中就会自动加上对应的提示词组。
Hypernetwork
Hypernetwork 中文意思是超级网络,是一个神经网络模型,用于调整扩散模型(Diffusion model)的参数。它通过训练产生一个新的神经网络模型,这个模型能向原始Diffusion模型中插入合适的中间层及对应的参数,以使输出图像与输入指令之间产生特定的关联关系。虽然Hypernetwork的训练过程没有对原模型进行全面微调,但它的模型尺寸通常在几十到几百MB之间。相比之下,Hypernetwork比LoRA模型的训练难度更大且应用范围较窄,目前主要被用于控制图像画风。在国内,LoRA模型因其更好的效果和更广泛的应用范围,逐渐取代了Hypernetwork。
Hypernetwork 的安装地址,使用流程与 LoRA 基本相同,将模型保存在\models\hypernetworks 文件夹即可。
VAE
Stable Diffusion中使用的VAE模型的全称是Variational AutoEncoder(变分自编码器)。这是一种神经网络模型,能够对图像进行编码和解码,将图像转换到更小的潜在空间,以便计算可以更快。
VAE模型通过编码和解码图像来实现在更小的潜在空间中的图像表示,这可以加速计算过程。在生成AI绘画时,VAE会对输出的颜色和线条产生影响。
当人们提到下载和使用VAE时,他们指的是使用VAE的改进版本。这发生在模型训练者用额外的数据进一步微调了模型的VAE部分。为了避免发布一个很大的完整新模型,他们只发布了经过更新的小部分。
有些VAE模型可能会内置制作者推荐的VAE,但大多数情况下应该认为没有内置。此外,如果您想要更改色调等内容,也可以通过更改VAE来实现,因此最好尽可能自己准备。
VAE模型主要用于搭配Checkpoint大模型使用,用来改善照片的光照、颜色、亮度和对比度,以及产生特定的视觉效果,相当于生成的图片加上滤镜的效果。
VAE 模型的放置位置是在\models\VAE,因为是辅助 Checkpoint 大模型来使用,所以可以将大模型对应的 VAE 修改为同样的名字,然后在选项里勾选自动,这样在切换 Checkpoint 模型时 VAE 就会自动跟随变换了。
ControlNet模型
ControlNet是一个用于控制AI图像生成的插件,它使用了一种称为"Conditional Generative Adversarial Networks"(条件生成对抗网络)的技术来生成图像。与传统的生成对抗网络不同,ControlNet允许用户对生成的图像进行精细的控制。
在Stable Diffusion中,ControlNet模型用于对生成的图像进行更精确的控制。通过使用ControlNet,用户可以上传线稿让AI帮我们填色渲染,控制人物的姿态、图片生成线稿等等。
模型的下载
国外最大的两个下载网站
- 一个是C站(Civitai) Civitai 有许多定制好的模型,而且可以免费下载,https://civitai.com
Civitai 是一个AI绘画模型分享平台。用户可以在这个平台上浏览并发现由不同创作者创建的AI艺术创作资源,同时也可以轻松地分享他们自己的艺术作品。该平台旨在为AI艺术创作爱好者提供一个分享和发现资源的场所,以促进艺术创作和交流
- 一个是抱脸(huggingface) huggingface 有许多定制好的模型,而且可以免费下载,https://huggingface.co/runwayml/
HuggingFace是一个致力于开发先进自然语言处理技术和工具的公司。他们因开源的Transformers库在机器学习社区中崭露头角,尽管初衷是创建聊天机器人,但这个库在机器学习领域得到了广泛应用。HuggingFace开发了许多流行的自然语言处理工具和框架,包括用于PyTorch、TensorFlow和JAX的最先进机器学习tokenizers,快速先进的Rust标记器,以及最大的即用型数据集中心datasets,这些可以帮助开发人员快速构建和训练模型并完成任务。HuggingFace已经共享了超过10万个预训练模型和1万个数据集,为机器学习界提供了巨大价值。其官网为https://huggingface.co/,而其Github仓库则可以通过https://github.com/huggingface进行访问。
Civitai 适合普通用户使用,上面有大神分享得模型和图片示例,HuggingFace适合大神使用,没有图片示例,但是资源多,有最新科研得模型。访问这两个网站,需要科学上网,所以推荐普通用户到国内得模型网站上下载。国内模型网站得模型,大部分都是从国外搬用过来得,还有一谢国内得大佬贡献的!
国内推荐的三个模型网站
-
LiblibAI·哩布哩布AI-中国领先的AI创作平台 https://www.liblib.ai/
原创AI模型分享社区,这里有最新、最热门的模型素材,10万+模型免费下载。欢迎每一位创作者加入,分享你的作品。与中国原创模型作者交流,共同探索AI绘画。
-
吐司 TusiArt.com https://tusiart.com/
由秋叶启动器的大佬,创建的网站,可在线生图的 AI 模型分享社区,还是免费的!
-
eSheep 一站式的AIGC社区 https://www.esheep.com/
eSheep.com 是国内知名的AIGC在线画图网站,提供海量模型,并支持在线AI画图。