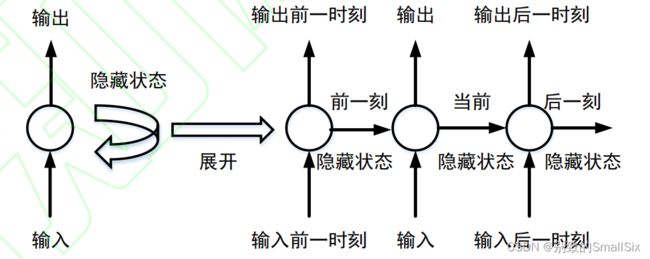
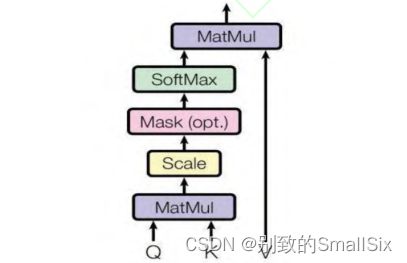
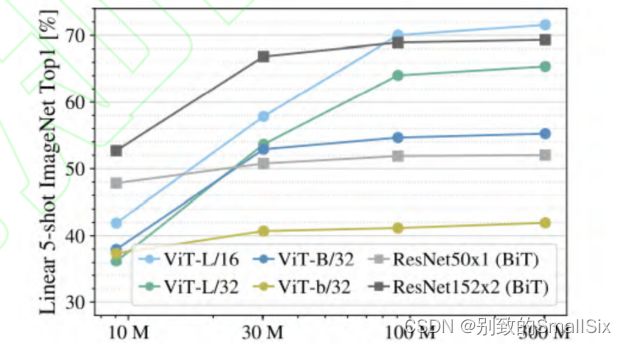
[5] Parmar N, Vaswani A, Uszkoreit J, et al. Image transformer[C]//International Conference on Machine Learning. PMLR, 2018: 4055-4064.
[6] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European Conference on Computer Vision. Springer, Cham, 2020: 213-229.
[7] Chen M, Radford A, Child R, et al. Generative pretraining from pixels[C]//International Conference on Machine Learning. PMLR, 2020: 1691-1703.
[8] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[9] Esser P, Rombach R, Ommer B. Taming transformers for high-resolution image synthesis[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 12873-12883.
[10] Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
[11] Tsai Y H, Bai S, Liang P. Multimodal transformer for unaligned multimodal language sequences[C]//Proceedings of the conference. Association for Computational Linguistics.
Meeting. NIH Public Access, 2019, 2019: 6558.
[12] 杨丽 , 吴雨茜 , 王俊丽 . 循环神经网络研究综述 [J]. 计算机应用, 2018,38(S2):1-6.
Yang L, Wu Y Q, Wang J L. Research review of cyclic neural networks[J]. Journal of Computer Applications, 2018, 38(S2): 1-6.
[13] 任欢 , 王旭光 . 注意力机制综述 [J]. 计算机应用 , 2021, 41(S1): 16.
Ren H, Wang X G. Summary of Attention Mechanism[J]. Computer Applications, 2021, 41(S1):16.
[14] 刘金花 . 基于主动半监督极限学习机多类图像分类方法研 究[D]. 东南大学 ,2016.
Liu J H. Research on multi-class image classification method based on active semi-supervised extreme learning machine [D]. Southeast University, 2016.
[15] 王红 , 史金钏 , 张志伟 . 基于注意力机制的 LSTM 的语义关系抽取[J]. 计算机应用研究 ,2018,35(05):1417-1420+1440.
Wang H, Shi J C, Zhang Z W. Semantic relation extraction of LSTM based on attention mechanism[J]. Application Research of Computers, 2018, 35(05): 1417-1420+1440.
[16] 唐海桃 , 薛嘉宾 , 韩纪庆 . 一种多尺度前向注意力模型的语音 识别方法[J]. 电子学报 ,2020,48(07):1255-1260.
Tang H T, Xue J B, Han J Q. A multi-scale forward attention model speech recognition method[J]. Chinese Journal of Electronics, 2020, 48(07): 1255-1260.
[17] Wang W, Shen J, Yu Y, et al. Stereoscopic thumbnail creation via efficient stereo saliency detection[J]. IEEE transactions on visualization and computer graphics, 2016, 23(8): 2014- 2027.
[18] Lin Z, Feng M, Santos C N, et al. A structured self-attentive sentence embedding[C]//Proceedings of the International Conference on Learning Representations, Toulon, France. 2017.
[19] Han K, Wang Y, Chen H, et al. A Survey on Visual Transformer[J]. arXiv preprint arXiv:2012.12556, 2020.
[20] Khan S, Naseer M, Hayat M, et al. Transformers in Vision: A Survey[J]. arXiv preprint arXiv:2101.01169, 2021.
[21] Han K, Xiao A, Wu E, et al. Transformer in transformer[J]. arXiv preprint arXiv:2103.00112, 2021.
[22] Yuan L, Chen Y, Wang T, et al. Tokens-to-token vit: Training vision transformers from scratch on imagenet[J]. arXiv preprint arXiv:2101.11986, 2021.
[23] Jiang Z, Hou Q, Yuan L, et al. Token labeling: Training a 85.5% top-1 accuracy vision transformer with 56m parameters on imagenet[J]. arXiv preprint arXiv:2104.10858, 2021.
[24] Zhou D, Kang B, Jin X, et al. Deepvit: Towards deeper vision transformer[J]. arXiv preprint arXiv:2103.11886, 2021.
[25] Zhu X, Su W, Lu L, et al. Deformable DETR: Deformable Transformers for End-to-End Object Detection[J]. arXiv preprint arXiv:2010.04159, 2020.
[26] Sun Z, Cao S, Yang Y. Rethinking Transformer-based Set Prediction for Object Detection[J]. arXiv preprint arXiv:2011.10881, 2020.
[27] Dai Z, Cai B, Lin Y, et al. UP-DETR: Unsupervised Pretraining for Object Detection with Transformers[J]. arXiv preprint arXiv:2011.09094, 2020.
[28] Zheng M, Gao P, Wang X, et al. End-to-End Object Detection with Adaptive Clustering Transformer[J]. arXiv preprint arXiv:2011.09315, 2020.
[29] Zheng S, Lu J, Zhao H, et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers[J]. arXiv preprint arXiv:2012.15840, 2020.
[30] Strudel R, Garcia R, Laptev I, et al. Segmenter: Transf-ormer for Semantic Segmentation[J]. arXivpreprint arXiv:2105.056 33, 2021.
[31] Xie E, Wang W, Yu Z, et al. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers[J]. arXiv preprint arXiv:2105.15203, 2021.
[32] Wang H, Zhu Y, Adam H, et al. MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers[J]. arXiv preprint arXiv:2012.00759, 2020.
[33] Wang Y, Xu Z, Wang X, et al. End-to-End Video Instance Segmentation with Transformers[J]. arXiv preprint arXiv:2011.14503, 2020.
[34] Ma F, Sun B, Li S. Robust Facial Expression Recognition with Convolutional Visual Transformers[J]. arXiv preprint arXiv:2103.16854, 2021.
[35] Zheng C, Zhu S, Mendieta M, et al. 3d human pose estimation with spatial and temporal transformers[J]. arXiv preprint arXiv:2103.10455, 2021.
[36] He S, Luo H, Wang P, et al. TransReID: Transformer-based Object Re-Identification [J]. arXiv preprint arXiv:2102.04378, 2021.
[37] Liu R, Yuan Z, Liu T, et al. End-to-end lane shape prediction with transformers[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2021: 3694-3702.
[38] Chen H, Wang Y, Guo T, et al. Pre-trained image processing transformer[J]. arXiv preprint arXiv:2012.00364, 2020.
[39] Yang F, Yang H, Fu J, et al. Learning texture transformer network for image super-resolution[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 5791-5800.
[40] Jiang Y, Chang S, Wang Z. Transgan: Two transformers can make one strong gan[J]. arXiv preprint arXiv:2102.07074, 2021.
[41] Chen Y, Cao Y, Hu H, et al. Memory enhanced global-local aggregation for video object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10337-10346.
[42] Zeng Y, Fu J, Chao H. Learning joint spatial-temporal transformations for video inpainting[C]//European Conference on Computer Vision. Springer, Cham, 2020: 528-543.
[43] Bertasius G, Wang H, Torresani L. Is Space-Time Attention All You Need for Video Understanding?[J]. arXiv preprint arXiv:2102.05095, 2021.
[44] Liu Z, Luo S, Li W, et al. ConvTransformer: A Convolutional Transformer Network for Video Frame Synthesis[J]. arXiv preprint arXiv:2011.10185, 2020.
[45] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[46] Zagoruyko S, Komodakis N. Wide Residual Networks[J]. British Machine Vision Conference 2016, 2016.
[47] Tan M, Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks[C]//International Conference on Machine Learning. PMLR, 2019: 6105-6114.
[48] Kolesnikov A, Beyer L, Zhai X, et al. Big transfer (bit): General visual representation learning[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August
23–28, 2020, Proceedings, Part V 16. Springer International
Publishing, 2020: 491-507.
[49] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[50] Howard A G, Zhu M, Chen B. Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv:1704.04861, 2017.
[51] Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4510-4520.
[52] Yun S, Oh S J, Heo B. Re-labeling imagenet: from single to multi-labels, from global to localized labels[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 2340-2350.
[53] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[54] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[55] 李彦冬 . 基于卷积神经网络的计算机视觉关键技术研究 [D].电子科技大学 ,2017.
Li Y D. Research on key technologies of computer vision based on convolutional neural networks [D]. University of Electronic Science and Technology of China, 2017
[56] Dai J, Qi H, Xiong Y, et al. Deformable convolutional networks[C]//Proceedings of the IEEE international conf-erence on computer vision. 2017: 764-773
[57] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2117-2125.
[58] Tian Z, Shen C, Chen H, et al. Fcos: Fully convolutional onestage object detection[C]//Proceedings of the IEEE/CVF Int-ernational Conference on Computer Vision. 2019: 9627- 9636
[59] Chen Y, Wang Z, Peng Y, et al. Cascaded pyramid network for multi-person pose estimation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.
2018: 7103-7112.
[60] Ding X, Guo Y, Ding G, et al. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 1911-1920.
[61] Yang L, Fan Y, Xu N. Video instance segmentation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 5188-5197.
[62] Wang K, Peng X, Yang J, et al. Suppressing uncertainties for large-scale facial expression recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 6897-6906.
[63] Lin K, Wang L, Liu Z. End-to-end human pose and mesh reconstruction with transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1954-1963.
[64] Hao L .Bags of Tricks and A Strong Baseline for Deep Person Re-identification[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2019.
[65] Chen T, Ding S, Xie J, et al. Abd-net: Attentive but diverse person re-identification[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 8351- 8361.
[66] Miao J, Wu Y, Liu P, et al. Pose-guided feature alignment for occluded person re-identification[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 542-551.
[67] Khorramshahi P, Peri N, Chen J, et al. The devil is in the details: Self-supervised attention for vehicle re-identification[C]//European Conference on Computer Vision. Springer, Cham, 2020: 369-386.
[68] Tabelini L, Berriel R, Paixao T M, et al. Polylanenet: Lane estimation via deep polynomial regression[C]//2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021: 6150-6156.
[69] Li X, Li J, Hu X, et al. Line-cnn: End-to-end traffic line detection with line proposal unit[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21(1): 248-258.
[70] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative Adversarial Networks[J]. Advances in Neural Information Processing Systems, 2014, 3:2672-2680.
[71] Karras T, Laine S, Aittala M, et al. Analyzing and improving the image quality of stylegan[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 8110-8119.
[72] Feichtenhofer C, Fan H, Malik J, et al. Slowfast networks for video recognition[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 6202-6211
[73] Liu Z, Yeh R A, Tang X, et al. Video frame synthesis using deep voxel flow[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 4463-4471.
[74] Villegas R, Yang J, Hong S, et al. Decomposing motion and content for natural video sequence prediction[J]. arXiv preprint arXiv:1706.08033, 2017.