pandas在excel中的应用
1、pandas 中 一维数组,二维数组和exce,csv的简单应用。
import pandas as pd
# series 方法代表一维数组
# li_st = ["r", "t", "c", "d"]
# li_index = ["p", "k", "y", "o"]
# 指定索引,索引的长度要和一维数组的长度一样
# li_st_ser = pd.Series(li_st, li_index)
# print(li_st_ser)
# di_ct = {"a": "1", "v": 3, "r": 5}
# di_ct_dict = pd.Series(di_ct)
# 通过一维数组,拿到字典的key
# print(di_ct_dict.index)
# 通过一维数组,拿到字典的values
# print(di_ct_dict.values)
# li_st_indes2 = ["r", "t", "c", "d"]
# li_st_indes2_yu = pd.Series(li_st_indes2)
# 能拿到默认索引的值。
# print(li_st_indes2_yu.index.values)
# 输出一维数组的值
# print(li_st_indes2_yu.values)
# li_st = ["r", "t", "c", "d"]
# li_ser = pd.Series(li_st)
# 输出带索引的一维数组
# print(li_ser)
# li_st_sd = [[1, 4, 6], [3, [999, 99, 9]], [6, 2], [1, 9], [4, 1], [4, 9, 8]]
# li_dateFrame = pd.DataFrame(li_st_sd)
# 默认带行和列索引的二维数组输出
# print(li_dateFrame)
# li_st = {"小写": ["a", "b"], "大写": ["A", "B"]}
# index_num = ["一", "二"]
# data_zonghe = pd.DataFrame(li_st, index=index_num)
# 给字典指定行索引的值
# print(data_zonghe)
# df_r = pd.read_excel(r"C:\Users\Administrator\Desktop\456999\test.xlsx")
# ()括号里面带r的时候,要用\捺,去掉r要用/撇
# print(df_r)
# df = pd.read_csv("C:/Users/Administrator/Desktop/456999/t2.csv")
# csv 格式的输出
# print(df)
''''
dfr = pd.read_excel("C:/Users/Administrator/Desktop/456999/top9.xlsx")
# 输出excel里面的值,空格用NaN表示
print(dfr)
# 输出每列有多少个不是空格(数量+ ,non-null),及列的数据类型。
print(dfr.info())
# 判断excel中有那些空格,空格就输出True
print(dfr.isnull())
'''
2、mysql,pandas一起对数据库表的操作:
import pandas as pd
import pymysql
db = ""
def mysql_conn():
global db
try:
# 打开数据库连接
db = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="dong2025",
database="mysql8",
charset="utf8",
)
sql = "SELECT * FROM BOOK"
df_sql = pd.read_sql(sql, db)
# return df_sql # 展示所有结果
# return df_sql.head() # 默认展示前5行
# return df_sql.head(2) # 展示前2行
# return df_sql.shape # 统计行和列数。
# return df_sql.info() # info()方法可以查看数据表中的数据类型
# return df_sql.describe() # 对BOOK表的描述
except:
# Rollback in case there is any error
db.rollback()
finally:
db.close()
my_con = mysql_conn()
print(my_con)
3、用pymysql单独连接数据库
# -*- coding: UTF-8 -*-
# 查询数据库的某一张表
import pymysql
db = ""
def mysql_conn():
global db
try:
# 打开数据库连接
db = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="dong2025",
database="mysql8",
charset="utf8",
)
# 使用cursor()方法获取操作游标
# cursor = db.cursor()
cursor = db.cursor(cursor=pymysql.cursors.DictCursor) # 可以返回字典数据(包含字段名字)
# SQL 查询数据库中的某一张表
sql = "SELECT * FROM BOOK WHERE BOOK_ID > 3"
# 执行sql语句
cursor.execute(sql)
# fetchone(): 该方法获取下一个查询结果集。结果集是一个对象
# onedate = cursor.fetchone()
# return onedate
# fetchall():接收全部的返回结果行.
# alldata = cursor.fetchall()
# return alldata
# fetchmany():接收指定条数,返回结果行条数.
alldata = cursor.fetchmany(2)
return alldata
except:
# Rollback in case there is any error
db.rollback()
finally:
db.close()
my_con = mysql_conn()
print(my_con)
4、删除空格,对空格赋值:
import pandas as pd
dfr = pd.read_excel("C:/Users/Administrator/Desktop/456999/top9.xlsx")
# 输出excel里面的值,空格用NaN表示
print(dfr)
# 删除包含空格的行
# print(dfr.dropna())
# 只删除空白行
# print(dfr.dropna(how="all"))
# fillna()方法给空格填充值
# print(dfr.fillna(55))
# fillna()方法性别赋值,男
# print(dfr.fillna({"性别": "男"}))
# print(dfr.fillna({"编号": "A4"}))
5、用pandas删除excel中的重复数据
import pandas as pd
dfr = pd.read_excel("C:/Users/Administrator/Desktop/456999/top9.xlsx")
# 输出excel里面的值,空格用NaN表示
print(dfr)
# drop_duplicates()删除excel数据中重复的数据
# print(dfr.drop_duplicates())
# drop_duplicates("年龄")删除指定那一列重复的数据,并且可以根据keep知道保留那一行
# print(dfr.drop_duplicates(subset="年龄", keep="last"))
# 根据列删除所有,行的数据。可以通过keep=False的设置一条也不保留
print(dfr.drop_duplicates(subset="年龄", keep=False))
6、pandas查询EXCEL信息,指定行和列。
import pandas as pd
dfr = pd.read_excel("C:/Users/Administrator/Desktop/456999/top9.xlsx")
# 输出excel里面的值,空格用NaN表示
print(dfr)
# 给excel指定行
dfr.index = [6, 7, 8]
print(dfr)
# 给excel指定列
dfr.columns = ["一", "二", "三", "四"]
print(dfr)
7、pandas 操作excel 取某一或几列列的值
import pandas as pd
dfr = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
# 输出excel里面的值,空格用NaN表示
print(dfr)
# 指定取那一列数据
print(dfr[["订单编号"]])
print(dfr[["序号", "订单编号"]])
8、pandas 操作excel 取某一列或几列(某一行或几行的值)
import pandas as pd
dfr = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
# 输出excel里面的值,空格用NaN表示
print(dfr)
# 指定取那一列的数据
print(dfr[["订单编号"]])
print(dfr[["序号", "订单编号"]])
# 指定取那一列或几列的数据
pdp = pd.DataFrame(dfr)
pdp1 = pdp.iloc[:, [0, 1, 2]]
print(pdp1)
pdp2 = pdp.iloc[:, 1: 2]
print(pdp2)
print("*****************************************************")
# 下面是行的取值
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdd)
# 指定取那行数据
pindex1 = pdd.loc[1]
print(pindex1)
# 指定取的行数共3行
pindex2 = pdd.loc[0: 2]
print(pindex2)
# 指定取的行数共2行
pindex3 = pdd.iloc[0: 2]
print(pindex3)
pindex4 = pdd.iloc[[0, 1, 2]]
print(pindex4)
9、对行添加选择条件,取excel中的值
import pandas as pd
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdd)
# 通过判断,取excel中的值【这种方式也叫做布尔索引】。
pdex = pdIndex[pdIndex["唯一识别码"] > 103]
print(pdex)
# 多条件判断,取excel中的值
pdmore = pdIndex[(pdIndex["唯一识别码"] > 102) & (pdIndex["序号"] > 4)]
print(pdmore)
10、
同时选择行和列,取excel中的值,第一个方括号指行,第二个方括号指列。
import pandas as pd
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdd)
# 同时选择行和列,取excel中的值,第一个方括号指行,第二个方括号指列。
pdex = pdd.loc[[0, 1, 2], ["唯一识别码", "客户姓名"]]
print(pdex)
11、pandas对excel的行,列取值的最后总结:

import pandas as pd
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdd)
# 同时选择行和列,取excel中的值,第一个方括号指行,第二个方括号指列。
# 普通索引 + 普通索引
pdex = pdd.loc[[0, 1, 2], ["唯一识别码", "客户姓名"]]
print(pdex)
# 位置索引+位置索引,要用iIoc方法
indexpd = pdd.iloc[[0, 1, 2], [3, 4]]
print(indexpd)
print("*******************************************")
# 多条件判断,取excel中的值
# 布尔索引+普通索引一起来取excel的值
pdmore = pdIndex[(pdIndex["唯一识别码"] > 102) & (pdIndex["序号"] > 1)][["订单编号", "成交时间"]]
print(pdmore)
print("************************************")
# 切片索引+切片索引
qpsy = pdd.iloc[1:4, 0:2]
print(qpsy)
12、pandas对excel的数值替换 总结:

import pandas as pd
import numpy as np
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
# 下面两种方法都可以通过列字段,拿到列的值。
print(pdd["唯一识别码"])
print(pdIndex["唯一识别码"])
# 只能整体替换,不能局部替换,没有excel操作方便
print(pdd["唯一识别码"].replace(101, 6))
print(pdIndex["唯一识别码"].replace(101, 6))
# 把所有的空置全部替换成ok
print(pdIndex.replace(np.NaN, "ok"))
print(pdd.replace(np.NaN, "ok"))
# 对excel多个值进行替换(也叫多对一替换)
print(pdIndex.replace([192, 193, 195], "ok"))
print(pdd.replace([192, 193, 195], "ok"))
# 对excel多个值进行替换(也叫多对多替换)
print(pdIndex.replace({192: 22, 193: 23, 196: 26}))
print(pdd.replace({192: 22, 193: 23, 196: 26}))
13、pandas 对指定excel列进行排序

import pandas as pd
import numpy as np
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
# 下面两种方法都可以通过列字段,拿到列的值。
print(pdIndex)
# 指定某列排序(升序或降序)
pddvalues = pdd.sort_values(by=["销售ID"], ascending=False)
print(pddvalues)
pddvaluesed = pdIndex.sort_values(by=["销售ID"], ascending=True)
print(pddvaluesed)
14、na_position的作用是把空置放在前面还是后面,的默认值是last

import pandas as pd
import numpy as np
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
# 下面两种方法都可以通过列字段,拿到列的值。
print(pdIndex)
# 指定某列排序(升序或降序),但是,缺失值永远在最下面。
pddvalues = pdd.sort_values(by=["销售ID"], ascending=False)
print(pddvalues)
pddvaluesed = pdIndex.sort_values(by=["销售ID"], ascending=True)
print(pddvaluesed)
# na_position的作用是把空置放在前面还是后面,的默认值是last,
pddvalues2 = pdd.sort_values(by=["销售ID"], na_position="first")
print(pddvalues2)
pddvaluesed2 = pdIndex.sort_values(by=["销售ID"])
print(pddvaluesed2)
15、指定多列排序(升序或降序),当前列值相同时,比较下一列,以此类推。
import pandas as pd
import numpy as np
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
# 下面两种方法都可以通过列字段,拿到列的值。
print(pdIndex)
# 指定多列排序(升序或降序),当前列值相同时,比较下一列,以此类推。
pddvalues = pdd.sort_values(by=["销售ID", "成交时间"], ascending=[True, False])
print(pddvalues)
pddvaluesed = pdIndex.sort_values(by=["销售ID", "成交时间"], ascending=[True, False])
print(pddvaluesed)
16、 pandas 操作excel数值排名
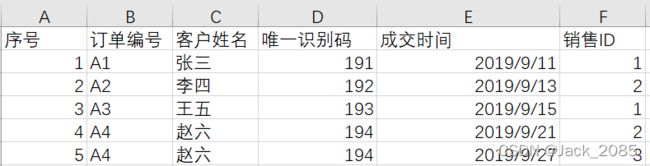
import pandas as pd
import numpy as np
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
# 下面两种方法都可以通过列字段,拿到列的值。
print(pdIndex)
# rank(method="average"),对列中相同的值,求平均值,排序不变。
print(pdd["销售ID"].rank(method="average"))
print(pdIndex["销售ID"].rank(method="average"))
# rank(method="first"),对列中的值排序,值相同的放在后面,以此类推。
print(pdd["销售ID"].rank(method="first"))
print(pdIndex["销售ID"].rank(method="first"))
# rank(method="min"),对列中中的值排序,相同的值,按小的值,显示,
# 相当于数据库中的rank()方法,次序不连续。
print(pdd["销售ID"].rank(method="min"))
print(pdIndex["销售ID"].rank(method="min"))
# rank(method="max"),对列中中的值排序,相同的值,按大的值,显示,
# 相当于数据库中的rank()方法,次序不连续。
print(pdd["销售ID"].rank(method="max"))
print(pdIndex["销售ID"].rank(method="max"))
17、pandas,删除列,axis函数与columns函数的应用
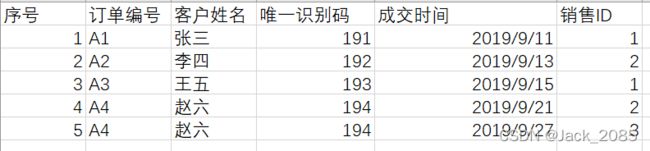
import pandas as pd
import numpy as np
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 删除指定列,axis=1才行
pdddrop = pdd.drop(["销售ID", "成交时间"], axis=1)
print(pdddrop)
pdddroped = pdIndex.drop(["销售ID", "成交时间"], axis=1)
print(pdddroped)
# 删除指定列,用columns函数,就不用axis=1了
pdddrop5 = pdd.drop(columns=["销售ID", "成交时间", "唯一识别码"])
print(pdddrop5)
pdddrop5ed = pdIndex.drop(columns=["销售ID", "成交时间", "唯一识别码"])
print(pdddrop5ed)
18、pandas 直接生产二维数组,保存在excel中
import pandas as pd
import numpy as np
data = np.arange(1, 101).reshape((10, 10))
data_df = pd.DataFrame(data)
data_df.columns = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
data_df.index = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
writer = pd.ExcelWriter('C:/Users/Administrator/Desktop/456999/top100.xlsx')
data_df.to_excel(writer, float_format='%.5f')
writer.save()
19、pandas 先读取excel再生产新的excel。
import pandas as pd
import numpy as np
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
writer = pd.ExcelWriter('C:/Users/Administrator/Desktop/456999/top99.xlsx')
pdd.to_excel(writer, float_format='%.5f')
writer.save()
20、pandas删除excel中的行的操作

import pandas as pd
import numpy as np
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# # 删除指定行,要是字符串要加上双引号,axis=0才行
pdddrop = pdd.drop([0, 1], axis=0)
print(pdddrop)
pdddroped = pdIndex.drop([0, 1, 2], axis=0)
print(pdddroped)
# 删除指定行,也可调用index方法输入(索引值),axis也要等于0
pdddrop5 = pdd.drop(pdd.index[[1, 2, 3]], axis=0)
print(pdddrop5)
pdddrop5ed = pdIndex.drop(pdIndex.index[[2, 3, 4]], axis=0)
print(pdddrop5ed)
# 也可以直接用index函数,如果是字符串,需要用双引号
pdddrop6 = pdd.drop(index=[1, 2, 3, 4])
print(pdddrop6)
pdddrop6ed = pdIndex.drop(index=[2, 3, 4])
print(pdddrop6ed)
# 删除特定行,可以逆向操作,把自己想要的数据取出来。
pd5 = pdIndex[pdIndex["唯一识别码"] > 192]
print(pd5)
pd6 = pdd[pdd["唯一识别码"] > 193]
print(pd6)
21、数值计算功能(统计列表中每个值出现的次数和每个值占比)
import pandas as pd
import numpy as np
# 数值计算功能(统计列表中每个值出现的次数和每个值占比)
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 统计指定列中,每个值出现的次数。
pd5 = pdIndex["销售ID"].value_counts()
print(pd5)
pd6 = pdd["销售ID"].value_counts()
print(pd6)
# 统计指定列中,每个值出现的占比。
pd7 = pdIndex["销售ID"].value_counts(normalize=True)
print(pd7)
pd8 = pdd["销售ID"].value_counts(normalize=True)
print(pd8)
22、统计指定列中,不重复的值及个数。
import pandas as pd
# 数值计算功能(统计列表中每个值出现的次数和每个值占比)
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 统计指定列中,不重复的值及个数。
pd5 = pdIndex["销售ID"].unique()
print(pd5)
pd6 = pdd["销售ID"].unique().__len__()
print(pd6)
23、统计指定列中(或整个excel)中,是否包含某个值。
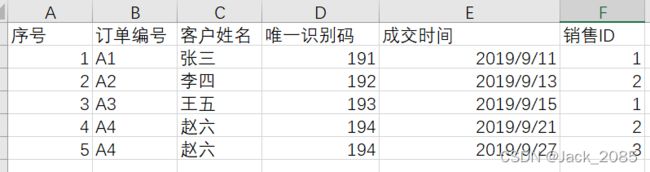
import pandas as pd
# 数值计算功能(统计列表中每个值出现的次数和每个值占比)
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 统计指定列中,是否包含某个值。
pd1 = pdIndex["销售ID"].isin([2, 3])
print(pd1)
pd2 = pdd["销售ID"].isin([2, 3])
print(pd2)
# 统计整个excel列中,是否包含某个值。
pd3 = pdIndex.isin([2, 3])
print(pd3)
pd4 = pdd.isin([2, 3])
print(pd4)
24、区间切分,当方差比较大的时候:cut与qcut有区别。

import pandas as pd
# 数值计算功能(统计列表中每个值出现的次数和每个值占比)
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 区间切分,当方差比较大的时候:cut与qcut有区别。
p1 = pd.cut(pdIndex["序号"], 6)
print(p1)
p2 = pd.cut(pdd["序号"], 6)
print(p2)
p3 = pd.qcut(pdIndex["序号"], 2)
print(p3)
p4 = pd.qcut(pdd["序号"], 2)
print(p4)
25、插入指定列的位置,列的名称和列的数据(下面两种方法都可以)
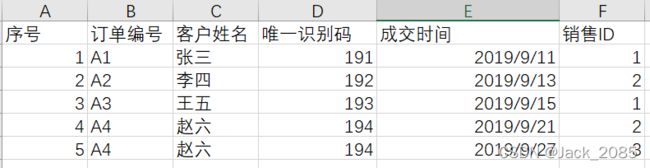
import pandas as pd
# 数值计算功能(统计列表中每个值出现的次数和每个值占比)
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 插入指定列的位置,列的名称和列的数据(下面两种方法都可以)
# pdd.insert(2, "商品类别", ["cat001", "cat002", "cat003", "cat004", "cat005"])
# print(pdd)
pdIndex.insert(2, "商品类别", ["cat001", "cat002", "cat003", "cat004", "cat005"])
print(pdIndex)
26、行列互换
import pandas as pd
# 数值计算功能(统计列表中每个值出现的次数和每个值占比)
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 行列互换
pT = pdd.T
print(pT)
pdIndexT = pdIndex.T
print(pdIndexT)
# 两次行列互换,就会回复原型。
pTT = pdd.T.T
print(pTT)
pdIndexTT = pdIndex.T.T
print(pdIndexTT)
27、索引重塑

import pandas as pd
# 数值计算功能(统计列表中每个值出现的次数和每个值占比)
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet2")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 索引重塑
pddstack = pdd.stack()
print(pddstack)
print("*****************************")
print(pdIndex.stack())
28、函数apply与applymap 的应用

import pandas as pd
# 函数apply与applymap 的应用
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet3")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# apply 函数对指定列数值通过匿名函数来操作控制结果。
print(pdIndex["C2"].apply(lambda x: x+3))
print(pdd["C2"].apply(lambda x: x+3))
# applymap 函数是对所有值通过匿名函数,来操作。
print(pdIndex.applymap(lambda x: x+3))
print(pdd.applymap(lambda x: x+3))
29、pandas操作excel的算术运算
import pandas as pd
# 函数apply与applymap 的应用
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet3")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 两列相加。
print(pdIndex["C2"]+pdIndex["C3"])
print(pdd["C2"]+pdd["C3"])
# 两列相减
print(pdIndex["C3"] - pdIndex["C2"])
print(pdd["C3"] - pdd["C2"])
# 两列相乘
print(pdIndex["C3"] * pdIndex["C2"])
print(pdd["C3"] * pdd["C2"])
# 两列相除
print(pdIndex["C3"] / pdIndex["C2"])
print(pdd["C3"] / pdd["C2"])
# 列乘以自然数
print(pdIndex["C3"] * 80)
print(pdd["C3"] * 80)
30、pandas列之间的比较,列求和,行求和。
import pandas as pd
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet3")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 两列比较,返回布尔值。
print(pdIndex["C2"] < pdIndex["C3"])
print(pdd["C2"] > pdd["C3"])
# 两列不相等,返回布尔值
print(pdIndex["C3"] != pdIndex["C2"])
print(pdd["C3"] != pdd["C2"])
# 统计每列非空值的个数
pddcount = pdd.count()
print(pddcount)
pdIndexcount = pdIndex.count()
print(pdIndexcount)
# 统计每行非空值的个数
pddcount1 = pdd.count(axis=1)
print(pddcount1)
pdIndexcount1 = pdIndex.count(axis=1)
print(pdIndexcount1)
# 指定列,统计非空值个数
pc1count = pdIndex["C1"].count()
print(pc1count)
# 统计每一列的值相加总和
pdIndexSum = pdIndex.sum()
print(pdIndexSum)
# 统计每一行的值相加总和
pdIndexSumhang = pdIndex.sum(axis=1)
print(pdIndexSumhang)
# C1列相加总和
pc1sum = pdIndex["C1"].sum()
print(pc1sum)
# 取指定行的值的总和
pindexsum2 = pdd.loc[1].sum()
print(pindexsum2)
31、pandas对excel求平均值,最大值,最小值。
import pandas as pd
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet3")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 求每一列的均值。
print(pdIndex.mean())
print(pdd.mean())
# 求每一行的均值。
print(pdIndex.mean(axis=1))
print(pdd.mean(axis=1))
# 某一列的均值
print(pdIndex["C2"].mean())
# 某一行的均值(Ioc与iIoc函数都可以)
print(pdIndex.loc[1].mean())
print(pdIndex.iloc[2].mean())
# 下面是求最大值
print(pdIndex.max())
print(pdd.max())
# 求指定列的最大值
print(pdIndex["C2"].max())
print(pdd["C3"].max())
# 求某一行的最大值
print(pdIndex.loc[1].max())
print(pdd.iloc[2].max())
# 求最小值的函数时 min()与求最大值,是同理的。
# 这里方法就不在重复了,参考求最大值的逻辑就ok。
32、pandas求excel的中位数与众数
import pandas as pd
pdIndex = pd.read_excel("C:/Users/Administrator/Desktop/456999/top10.xlsx", sheet_name="Sheet3")
pdd = pd.DataFrame(pdIndex)
print(pdIndex)
# 求每一列的中位数。
print(pdIndex.median())
print(pdd.median())
# 求每一行的中位数。
print(pdIndex.median(axis=1))
print(pdd.median(axis=1))
# 某一列的中位数
print(pdIndex["C2"].median())
# 某一行的均值(Ioc与iIoc函数都可以)
print(pdIndex.loc[1].median())
print(pdIndex.iloc[2].median())
# 上面是求中位数(median)
# 下面是求众数(mode)
print("*****************************")
# 某一列的中的众数
print(pdIndex["C2"].mode())
33、
33.1、方差(var)excel与python方法一致。
33.2、标准差,excel用stdevp();python用std()方法。
33.3、分位数,excel用percentile();python用quantile()方法
33.4、相关性运算,excel用correl();python用corr()方法
34、
pandas在excel中的应用2_Jack_2085-CSDN博客 https://blog.csdn.net/weixin_54217632/article/details/122070761
https://blog.csdn.net/weixin_54217632/article/details/122070761
35、
36、
37、
38、
39、
40、
41、
42、
43、
44、
45、
46、
47、
48、
49、
50