毕业设计-某干深度学习的无人机目标识别
目录
前言
课题背景和意义
实现技术思路
一、目标识别概述及深度学习网络
二、无人机数据采集与预处理
三、目标识别检测算法
实现效果图样例
最后
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
毕业设计-某干深度学习的无人机目标识别
课题背景和意义
随着多旋翼无人机技术的发展和无人机市场化率进一步提高,大量便民性、功能性 多旋翼无人机被用于日常生活中。由于使用者缺乏航空安全意识和相关部门的监督存在 漏洞,不少机场存在无人机的“黑飞”、“滥飞”现象,导致航班停飞、飞行事故频发。 机场安全是保证航空飞行的重要前提,在机场附近的低小慢目标中,无人机造成的影响 尤为严重。尽管有雷达等技术手段探测到异物,但无法准确、有效地识别并驱赶非法入 侵的无人机,如何对机场空域的无人机进行快速、有效的识别成为研究重点之一。 针对以上问题,采用当前目标识别领域主流算法,基于 Retinanet 的 3 种 Res 结构和 YOLOv5 的模型开发出对无人机样本进行识别与定位,通过训练、测试及推理对两种算法在无人机数据集上的检测效果进行比对,从而实现在实际项目中对无人机目 标的快速性和准确性识别、定位。对无人机目标定位与检测,做出反制措施,具有重要意义。
实现技术思路
一、目标识别概述及深度学习网络
目标识别概述
目标识别属于计算机图像识别领域和机器学习领域的分支,是深度学习和卷积神经 网络的重要组成部分。目标识别,即判断某副图像上是否存在目标物体,如果存在,则 通过算法给出感兴趣目标的类别与位置。
2、卷积神经网络
卷积神经网络的前身为全连接神经网络。全连接指从网络的输入层到输出层,所有 的上一层神经元皆与下一层神经元连接的网络结构。相比于传统的全连接神经网络,卷 积神经网络有以下几点优势: 首先,卷积神经网络应用场景更广泛。全连接神经网络由于网络的全连接,参数众 多,尽可用于简单的任务分类,如识别手写数字、简单二分类等。
在激活函数进一步优化情况下,神经网络结构往往不选择 Sigmoid 和 tanh 函数,而是选择 ReLU(Rectified Linear Unit)函数。其函数表达如式所示:
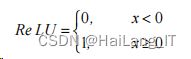
1 、输入层
输入层是神经网络的第一层,也是初始层。其作用是进行初次的信息采样,这种采 样方式通过卷积来完成。在计算机图像处理领域,对于彩色图像,一般以 RGB(Red, Green,Blue)三通道为输入,灰度图像模式则为单通道图像。
2、隐藏层
由于输入端和输出端是可视化图片,而中间层是具有黑匣子性质的网络结构,所以 又叫隐藏层。隐藏层主要包含卷积层、池化层和全连接层。这些隐藏层的主要作用是进 一步提取图像特征,通过卷积核池化等操作,学习到更全面的特征结构。
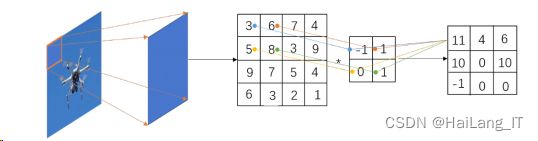
(1)卷积层。
卷积层的功能是对输入的图像进行特征提取。卷积层中有个重要的参 数,即卷积核。卷积的具体过程:
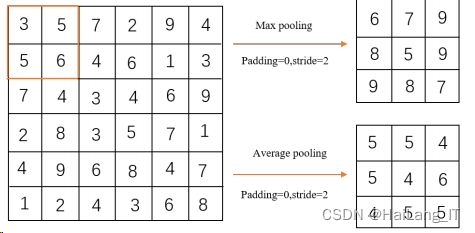
(2)池化层
池化层的主要作用是特征选择和信息过滤。池化的步骤跟卷积核几乎相同,由池化 大小、步长和填充控制。其池化方式主要分为 LP 池化、随机/混合池化、谱池化。最大池化与均值池化示例:
(3)全连接层
全连接层的功能是对提取的特征进行非线性组合以得到输出,即全连接层本身不被 期望具有特征提取能力,而是试图利用现有的高阶特征完成学习目标。
输出层
在图像分类中,输出层使用逻辑函数或归一化指数函数(softmax function)输出分 类标签,传统图像分类中常用全连接层以得到输出。
深度学习网络
1、深度学习网络的发展
深度学习的发展是以人工智能的蓬勃发展为前提,其中,人工智能发展主要分为专 家系统,规划管理、机器人、语音识别、自然语言处理、机器学习以及计算机视觉部分。
2、深度学习网络结构
前面已经介绍过神经网络的基本结构,深度学习的网络机构不是统一的,但都是基 于 CNN 的基本结构构造新的结构加以组合,以提取更多特征、减少更多参数、根据不 同任务进行设计与优化的结构。
二、无人机数据采集与预处理
视频的帧处理
视频的本质是由一张张图像组成的,视频的主要两大特征分别为流畅度和清晰度。 每一秒钟包含的图片数称之为帧数,由此可见,当帧数越高,视频就越流畅。当视频的 帧数不足时,呈现出来的视频则会给人的视觉产生不连续、不流畅的卡顿现象,这种现 象称之为掉帧。
1、OpenCV
OpenCV (Open Source Computer Vision Library) 是一个开源计算机视觉和机器学 习软件库,可在 Linux、windows、macOS 操作系统上运行,由一系列 C 和 C ++类构成, 提供了 python、Ruby、MATLAB 等语言的 API 接口。
2、视频帧的获取
通过光电拍摄设备进行场外无人机飞机飞行的视频拍摄,通过试飞不同 姿态、速度、距离等进行视频素材获取,视频分辨率为 1920×1080,拍摄视距多为 200m 开外,视频时长以 1~3Min 为主,另有部分视频以手机拍摄获得。
3、视频帧的分割
利用 OpenCV 中的 video_capture 模块对视频进行帧分割和抽帧处理。由于视频较 多,分别进行批处理。
无人机图像的预处理
获得无人机图片后,需要对目标图片进行一定的预处理。深度学习网络无法在一开 始对一张图片进行特征学习,需要人为告诉网络学习的目标是什么,也就是指定学习任 务。针对学习任务进行网络训练,从而达到识别的效果。
1、无人机数据筛选
前面已经提到,数据的获取主要是通过视频的帧切割和网络设置关键字“无人机”、 “旋翼无人机”、“drone”、“四旋翼飞行器”等关键词进行图片爬取,总共爬得四千多张。

2、无人机数据标注
网络通过标注好的目标进行特征学习训练,以生成相应的权重和网络结构。而目标样本标注的质量与识别效果紧密相关,所以在人工标注样本的时候对目标的框定显得尤 为重要。

3、数据格式转换与预处理
在进行数据标注的同时,标注的图像以 Pascal VOC 或 YOLO 格式生成相应的数据 文件。Pascal VOC 格式生成的数据集是以 VOC2007 比赛时的数据标准,生成的 xml 后 缀名文件。利用 Subline 打开,可以看到标注的图片信息。如图所示,该文件中包含 了所有图像标注的信息。

另一种格式是以 YOLO 格式为主。与 VOC 格式不同的是,YOLO 的标注格式生成 的 txt 文本文件,主要包含所标注目标的类别、归一化后的中心点坐标 x,归一化后的中 心点坐标 y,归一化后的目标框宽度 w,归一化后的目标高度 h。
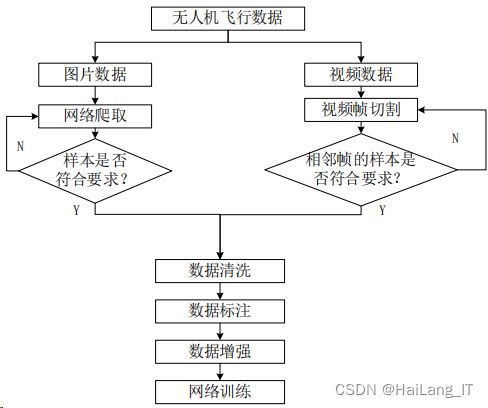
数据完成标注与格式转换后,下一步则进行数据处理。由于数据的有限性,为丰富 数据量和数据特征,主要有数据增广、三通道处理等方式。摄距离、目标占比等因素的影响,同一目标在成像图片中会呈现不同像素级别的大小。 在目标识别领域中,识别目标被分为大中小三种,在文献[52]中做出了对三种规模大小的 识别目标做了以下定义,如表所示。

在采集到的无人机数据集中,大部分数据样本的大小为 1960×1280pixel,其中的无 人机目标在 32×32 像素之内,属于小目标。也有部分属于中等大小目标和大型目标。 图是对无人机样本数据进行放大、旋转、翻转的增广效果,从左到右从上到下分别 为原图、裁剪、翻转、旋转:

无人机的数据三通道处理主要是通过改变图像的颜色空间,来获得不同色差下的目 中国民用航空飞行学院硕士学位论文 23 标特征。常用的有 RGB(Red、Green、Blue)三通道和 HSV(Hue、Saturation、Value)。 下图是 HSV 的处理过程:

三、目标识别检测算法
Retinanet 识别算
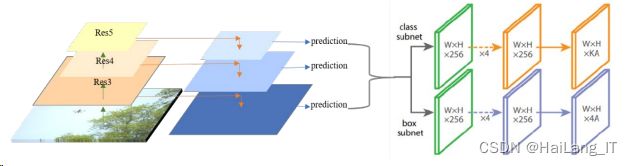
Retinanet 算法的网络构建
(1)ResNet
ResNet(Residual Network,残差网络)的提出解决了之前 8 层 AlexNet、19 层 VGG、 22 层 GoogleNet 带来的训练参数过多、梯度爆炸等问题。为解决神经网络的退化问题,即训练网络时出现梯度消失,导致网络无法找到最优 值,ResNet 采用了一种有别于传统神经网络结构。传统神经网络通过对输入做卷积运算 得到输出,而 ResNet 的基本单元如图所示:
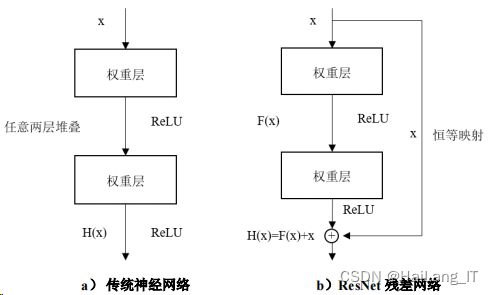
ResNet 网络增加了从输入到输出的直连(shortcut connection),其卷积拟合的是输 出与输入的差 F(x)。传统神经网络是通过逐层卷积、池化,然后经过 ReLU 函数输出作为下一层的输入 x,经过多次模块的组合,从而得到输出 y。同样,ResNet 模块的输入 x 经过一个卷积 层和 ReLU
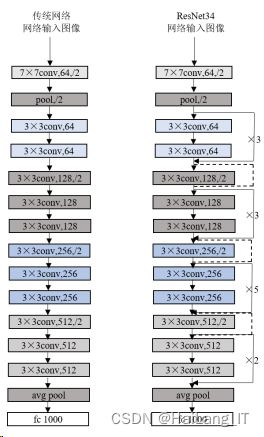
利用浅层或前层的特征传入更深层,可得到更丰富的数据,使得网络对数据波 动更灵敏,更易求得最优解,因此能改善更深层网络的训练。以 ResNet34 网络结构为 例,如图所示:
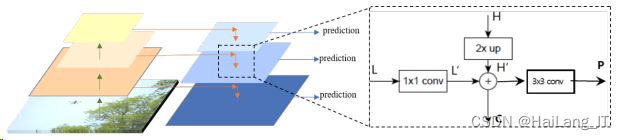
(2)FPN
在此之前,绝大多数 Object Detection 都是只采用网络的顶层特征做预测,这是由于顶层的特征经过多层卷积后,特 征语义信息更加丰富,但是经过多次的卷积与池化,会导致目标的位置比较粗略,而底 层特征尽管语义信息较少,但位置信息却相对更明确。
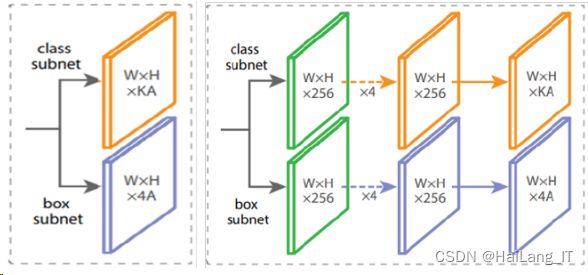
(3)分类与回归
预测部分主要分为了分类和回归两类,且这两类同步进行。在 FPN 阶段,输出的具 有不同特征大小的 P3~P7,送入这两个网络。分类子网络进行目标的分类,一方面是区 别前景与背景,另一方面是识别出目标物体的类别;回归子网络是对锚框的误差修正, 以更小的误差靠近原真实标注框,以此达到框得准的目标,如图所示
(4)RPN
RPN(Region Proposal Network),叫做区域建议网络。无人机图像作为 input image, 进过 CNN 特征提取后进入第一阶段,即 region proposal。RPN 网络的输出 classification, 并不是判定哪一类,而是输出一个二值 p∈[0,1],这个值是人工设定一个门限值 threshold ∈[0,1],以判定图像中的物体是否属于自定义数据集中的类。
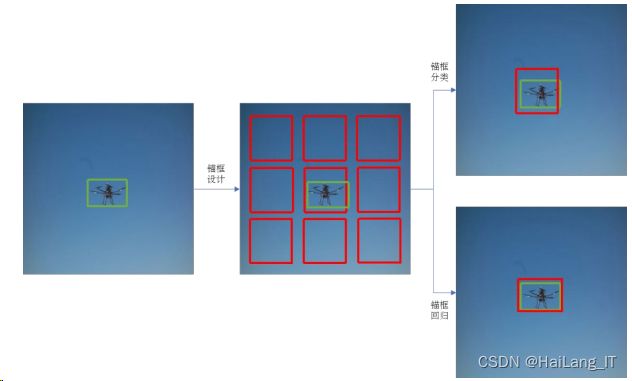
3、Anchor Box 的设计机制
Anchor 在英文中意为锚,用于固定船只。在目标识别中,网络需要处理两个任务, 即目标位置和目标大小。Anchor box 又叫锚框,用于锚定识别目标并框出大小。
YOLOv5 识别算法
YOLOv1[54]的核心思想是将整张图片作为输入,分割为 S×S 格网格,通过中心对落在某个网格上的识别目标进行位置预测和置信度预测,得到最终结果。
1、YOLOv5 算法的网络构建
YOLOv5 的网络结构如图所示:
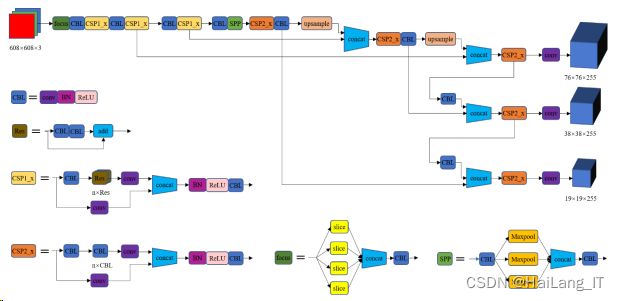
下图是 Focus 模块结构图,以 608×608×3 的图片作为网络输入,通过 mosaic 数据增强、自适应锚框计算和自适应缩放对输入样本进行数据增广操作,然后进入网络 的第二部分 backbone,又称主干网路。
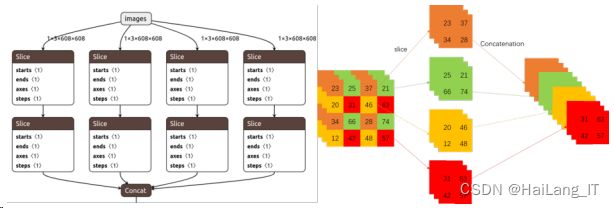
2、YOLOv5 的权重文件
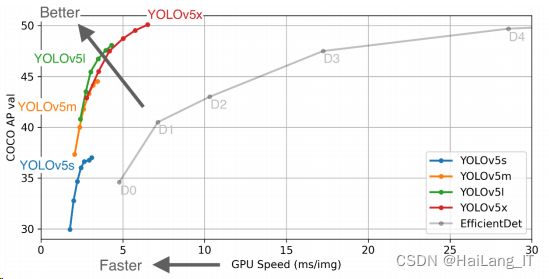
根据 YOLOv5 官网给出的权重文件测试图,由图可见,YOLOv5 有 4 个版本, 这 4 个版本则是根据其 depth_mutiple 和 width_multiple 两个参数来控制网络的深度和宽 第 4 章 目标识别检测算法 40 度来命名。作者将 YOLOv5 的四个版本同 EfficientDet 在 COCO 公共数据集上做了 AP (Average Precision)值的对比。
显而易见,YOLOv5 算法在 GPU 上的推理速度均值分 布在 2~7ms/img,整体上要超过 EfficientDet 的推理速度。这种推理速度尤其体现在落地 项目的实际情况中。下面将对 YOLOv5 的四种网络结构进行逐次解析。
实现效果图样例
无人机目标识别:

是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!