2023-arxiv-LLaMA-Adapter Efficient Fine-tuning of Language Models with Zero-init Attention
2023-arxiv-LLaMA-Adapter Efficient Fine-tuning of Language Models with Zero-init Attention

Paper: https://arxiv.org/pdf/2303.16199.pdf
Code:https://github.com/OpenGVLab/LLaMA-Adapter/tree/v.1.0.0
LLaMA-Adapter:使用零初始化注意力对语言模型进行高效微调
作者提出了LLaMA-Adapter,这是一种轻量级的适应方法,可以有效地将LLaMA微调为指令遵循模型。LLaMA-Adapter 使用 52K数据,在冻结的 LLaMA 7B 模型上仅引入 1.2M 可学习参数,在 8 个 A100 GPU 上微调的成本不到 1 小时。说明采用了一组可学习的适应提示,并将它们预置在更高变压器层的单词标记中。然后,提出了一种零门控的零初始化注意力机制,该机制自适应地将新的教学线索注入LLaMA,同时有效保留了LLaMA的预训练知识。通过我们高效的训练,LLaMA-Adapter 可以产生高质量的响应,可与具有完全微调的 7B 参数的 Alpaca 相媲美。除了语言命令,该方法还可以简单地扩展到多模态指令,用于学习图像条件的LLaMA模型,从而在ScienceQA和COCO Caption基准测试中实现卓越的推理性能。
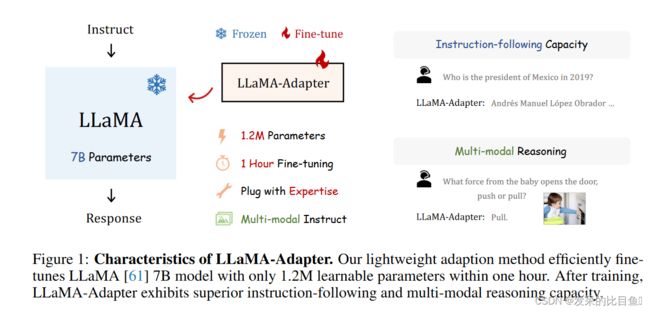
LLaMA-Adapter 具有四个主要特性,如图 1 所示。
-
1.2M的参数达到了与Alpaca完全微调类似的能力。
-
1小时的微调时间。
-
灵活的的切换下游任务。
-
支持多模态。
结构
Learnable Adaption Prompts
给定 52K instruction-to-output 数据和一个预先训练好的 LLaMA 模型(一个N层 transformer 模型),采用了一套可学习的适应提示(adaption prompts)来指导后续的微调
将 L 层 transformer 的提示符记为 { P l } l = 1 L \left\{P_l\right\}_{l=1}^L {Pl}l=1L,其中 P l ∈ R K × C P_l \in \mathbb{R}^{K \times C} Pl∈RK×C , K K K 表示每一层的提示长度,C 等于 LLaMA transformer 层的特征维数
只对于深层的 L L L 层插入 adapter,这可以更好地调整具有高级语义的语言表示
以第 l l l 个插入层为例,将长度为 M M M 的词 token 表示为 T l ∈ R M × C T_l \in \mathbb{R}^{M \times C} Tl∈RM×C。然后,将自适应提示符按照 token 维度作为前缀与 T l T_l Tl连接,表达式为:
[ P l ; T l ] ∈ R ( K + M ) × C \left[P_l ; T_l\right] \in \mathbb{R}^{(K+M) \times C} [Pl;Tl]∈R(K+M)×C
这样 P l P_l Pl 内部学习到的指令知识可以有效地引导 T l T_l Tl 生成上下文响应
Zero-init Attention

如果适应提示是随机初始化的,可能会在训练开始时对词 token 带来干扰,不利于调优的稳定性和有效性。考虑到这一点,修改了最后 L 个 transformer 层的传统注意机制为零初始注意
假设模型基于 P l ; T l P_l;T_l Pl;Tl信息,在生成第 (M + 1)-th 个单词,将对应的 (M + 1)-th 个词表示为 t l ∈ R 1 × C t_l \in \mathbb{R}^{1 \times C} tl∈R1×C , attention 首先基于如下 linear 层对 qkv 进行计算
Q l = Linear q ( t l ) K l = Linear k ( [ P l ; T l ; t l ] ) V l = Linear v ( [ P l ; T l ; t l ] ) \begin{aligned} Q_l & =\operatorname{Linear}_{\mathrm{q}}\left(t_l\right) \\ K_l & =\operatorname{Linear}_{\mathrm{k}}\left(\left[P_l ; T_l ; t_l\right]\right) \\ V_l & =\operatorname{Linear}_{\mathrm{v}}\left(\left[P_l ; T_l ; t_l\right]\right) \end{aligned} QlKlVl=Linearq(tl)=Lineark([Pl;Tl;tl])=Linearv([Pl;Tl;tl])
然后,计算softmax函数前的注意得分为
S l = Q l K l T / C ∈ R 1 × ( K + M + 1 ) S_l=Q_l K_l^T / \sqrt{C} \in \mathbb{R}^{1 \times(K+M+1)} Sl=QlKlT/C∈R1×(K+M+1)
记录了 t l t_l tl和所有 K+M+1 token 之间的特征相似性。同时, s l s_l sl可以由两个组分重新计算为
S l = [ S l K ; S l M + 1 ] T S_l=\left[S_l^K ; S_l^{M+1}\right]^T Sl=[SlK;SlM+1]T
其中 S l K ∈ R K × 1 S_l^K \in \mathbb{R}^{K \times 1} SlK∈RK×1 和 S l M + 1 ∈ R ( M + 1 ) × 1 S_l^{M+1} \in \mathbb{R}^{(M+1) \times 1} SlM+1∈R(M+1)×1 分别为 K \mathrm{K} K 个适应提示和 M + 1 \mathrm{M}+1 M+1 个词 token 的注意得分。前者 S l K S_l^K SlK 表示可学习提示符对 t l t_l tl 的贡献,这可能会在训练早期造成干扰
为此,采用一种可学习的门控因子 g l g_l gl ,自适应控制关注中 S l K S_l^K SlK 的重要性
S l g = [ Softmax ( S l K ) ⋅ g l ; Softmax ( S l M + 1 ) ] T S_l^g=\left[\operatorname{Softmax}\left(S_l^K\right) \cdot g_l ; \operatorname{Softmax}\left(S_l^{M+1}\right)\right]^T Slg=[Softmax(SlK)⋅gl;Softmax(SlM+1)]T
单独的 softmax 函数确保第二项与添加的适应提示无关, g l g_l gl训练开始会初始化为 0,然后再逐渐增大。注意力的每个头会采用不同的 g l g_l gl进行独立学习。最后,计算带有线性投影层的注意层的输出为
t l o = Linear o ( S l g V l ) ∈ R 1 × C t_l^o=\text { Linear }_{\mathrm{o}}\left(S_l^g V_l\right) \in \mathbb{R}^{1 \times C} tlo= Linear o(SlgVl)∈R1×C
Multi-modal Reasoning
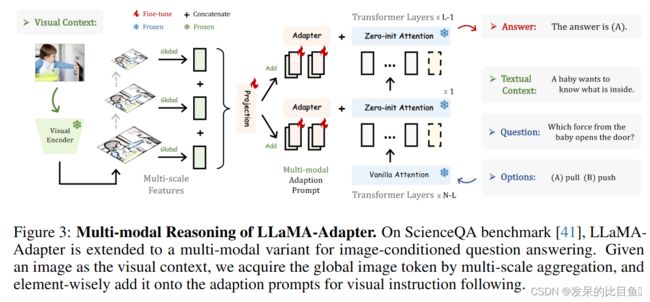
LLaMA-Adapter 不局限于文本指令,能够根据其他模态输入来回答问题,为语言模型增加了丰富的跨模态信息
对于图片输入,使用 CLIP 提取多尺度的全局特征,然后将这些多尺度特征 concat 起来,经过一个投影层得到全局的信息表征
I p = Projection ( Concat ( { I m } m = 1 M ) ) I_p=\operatorname{Projection}\left(\operatorname{Concat}\left(\left\{I_m\right\}_{m=1}^M\right)\right) Ip=Projection(Concat({Im}m=1M))
I p ∈ R 1 × C I_p \in \mathbb{R}^{1 \times C} Ip∈R1×C 是和 adapter prompt 维度一样的全局图片特征表示,然后将该特征 repeat 后与 adapter prompt 相加得到多模态特征
P l v = P l + Repeat ( I p ) ∈ R K × C P_l^v=P_l+\operatorname{Repeat}\left(I_p\right) \in \mathbb{R}^{K \times C} Plv=Pl+Repeat(Ip)∈RK×C