C语言— —基本数据类型
本文主要介绍C语言中的基本数据类型(带*的章节内容为进阶知识,对于初学者可以暂时跳过)。
文章目录
-
- 1. 什么是数据类型
- 2. 基本数据类型
- 3. 有符号与无符号的区别和最值
- 4. 浮点数的存储方式*
-
- 4.1 二进制小数
- 4.2 科学计数法
- 4.3 浮点数的存储
- 5. 变量与标识符
- 6. 字符型与ASCII表
- 参考资料
1. 什么是数据类型
数据类型,重点是类型。何谓类型,就是一组元素,具有某些相同的性质,我们可以把这些性质高度归纳概括为一个词语,那么这个词语就代表了一个类型。例如,狗就是一种动物类型。
在数学中,数的分类如下:
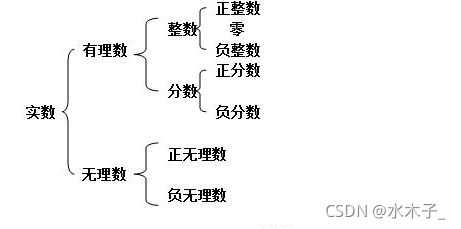
例如,数字 1 的最小类型就是正整数,最大类型就是实数。
在C语言中,我们需要有一个机制来表示数字,这就是用二进制数来表示十进制数。但是,我们知道,数的范围是 [ − ∞ , + ∞ ] [-\infty, +\infty] [−∞,+∞],正如我们不可能在一张纸上写下所有的数字,计算机也不可能表示所有的数字。所以计算机表示的数字是有一定范围的,这个范围由二进制位的数量和如何解释二进制表示来确定的。
2. 基本数据类型
在C语言中,基本数据类型包括整型、布尔型、字符型和浮点型。
- 整型:只能表示整数,对应于一部分有理数中的整数;
- 浮点型:能表示小数,对应于一部分的分数;
- 布尔型:特殊类型,该类型的数据只有两个:true或者false,也可以是1或0;
- 字符型:属于整型的一种,表示一个字符;
完整列表如下:
| 数据类型 | 含义 | 字节大小 | 范围 |
|---|---|---|---|
| bool | 布尔型 | 1 | true、false(1、0) |
| [signed] char | 有符号字符型 | 1 | [-128, 127] |
| unsigned char | 无符号字符型 | 1 | [0, 255] |
| [signed] short | 有符号短整型 | 2 | [-32768, 32767] |
| unsigned short | 无符号短整型 | 2 | [0, 65535] |
| [signed] int | 有符号整型 | 4 | [-2147483648, 2147483647] |
| unsigned int | 无符号整型 | 4 | [0, 4294967295] |
| [signed] long | 有符号长整型 | 4 | [-2147483648, 2147483647] |
| unsigned long | 无符号长整型 | 4 | [0, 4294967295] |
| [signed] long long | 有符号超长整型 | 8 | [ − 2 63 , 2 63 − 1 ] [-2^{63},2^{63}-1] [−263,263−1] |
| unsigned long long | 无符号超长整型 | 8 | [ 0 , 2 64 − 1 ] [0, 2^{64}-1] [0,264−1] |
| float | 单精度夫浮点数 | 4 | 略 |
| double | 双精度浮点数 | 8 | 略 |
在不同的电脑上,数据类型所占有的字节大小可能不同。以我的电脑为例:
# include 
3. 有符号与无符号的区别和最值
我们以字符数据类型char为例,来解释有符号和无符号的区别以及最值是如何得来的。首先明确有符号数和无符号数:
- 有符号数:可以表示正数、0和负数;
- 无符号数:只能表示正数和0,不能表示负数;
字符数据类型char所占字节大小为1,表示用8位二进制位来存储字符数据。8位二进制位可以表示256个数,从0000 0000到1111 1111。
如果是有符号字符数据类型,那么理解二进制的方式就是按照补码的形式进行理解:
0 000 0000 - 0 111 1111 : 表示0和正数,范围是 [0,127]
1 000 0000 - 1 111 1111 : 表示负数,范围是[-128,-1]
如果是无符号字符数据类型,那么理解二进制的方式就按照普通的二进制理解:
0000 0000 - 1111 1111 : 表示0和正数,范围是[0,255]
这就是有符号和无符号的区别,以及最值是如何得到的。
之后,如果一个数据类型没有明确指明其为无符号,则默认为有符号。
4. 浮点数的存储方式*
本部分内容为进阶知识,对于入门同学来说,可以暂时跳过。
前面我们讲解了有符号整数和无符号整数是如何在二进制中进行存储的,现在我们讲解浮点数是如何在二进制中存储的。首先需要了解二进制小数时如何表示的。
4.1 二进制小数
有如下图片,表示二进制序列:

图源:参考资料[2]
上图表示的二进制值转换为十进制公式为:
b = ∑ i = − n m 2 i × b i b = \sum_{i = -n}^{m}2^i\times b_i b=i=−n∑m2i×bi
例如, 101.1 1 2 101.11_2 101.112表示的十进制数为:
1 × 2 2 + 0 × 2 1 + 1 × 2 0 + 1 × 2 − 1 + 1 × 2 − 2 = 4 + 0 + 1 + 1 2 + 1 4 = 5 3 4 1 × 2^2 + 0 × 2^1 + 1 ×2^0 + 1 × 2^{−1} + 1 × 2^{−2} = 4 + 0 + 1 + \frac{1}{2} + \frac{1}{4} = 5\frac{3}{4} 1×22+0×21+1×20+1×2−1+1×2−2=4+0+1+21+41=543
4.2 科学计数法
在十进制中,所谓科学计数法,就是一个数d被写成一个实数a,与一个 10 的n次幂的积:
d = a × 1 0 n d = a \times 10^n d=a×10n
其中:
- n必须是一个整数
- 1 ≤ ∣ a ∣ < 10 1\leq|a|<10 1≤∣a∣<10(如果 |a|是一个小于1的小数,或 |a| 大于等于10,皆可通过改变 n 来表示)
- a是一个实数,可称为有效数或尾数
在C语言中,也可以使用科学计数法,例如,使用科学计数法表示111,则结果为1.11e2,即省略掉底数10,并且用e连接有效数和指数。
按照十进制中的科学计数法,二进制也可以使用科学计数法:
b = a × 2 n b = a \times 2^n b=a×2n
例如,使用二进制的科学计数法表示数 101.1 1 2 101.11_2 101.112,那么结果为1.0111e2,此时默认的底数应该为2。
4.3 浮点数的存储
经过二进制小数和科学计数法的铺垫,我们可以继续学习浮点数的存储了,该存储方式是IEEE提出的,即根据二进制的科学计数法,存储有效数和指数,而不是直接存储二进制数。因此在浮点数存储中,将存储区域分为三部分:符号位、有效数部分和指数部分。单精度和双精度浮点数的存储分布如下:

图源:参考资料[2]
- 在上图中,s表示符号为,exp区域部分指数,frac表示有效数部分
- 在单精度浮点数中,s占据1个比特位,exp占据8个比特位,frac占据23个比特位
- 在双精度浮点数中,s占据1个比特位,exp占据11个比特位,frac占据52个比特位
我们以单精度浮点数为例,来解释浮点数存储的三种情况。根据exp取值的不同,分为如下三种情况:
情况一:规格化的值
在这种情况下,exp的值不等于0,也不等于255,即比特位不全为0也不全为1。
![]()
在这种情况下,指数被解释为以偏置形式表示的有符号整数,也就是说,指数的值 n = e − B i a s n=e-Bias n=e−Bias,其中e是exp表示的无符号整数,Bias是一个等于 2 k − 1 − 1 2^{k-1}-1 2k−1−1的偏置值(单精度为127,双精度是1023)。由此,对于单精度来说,指数的取值范围是[-126,127];对于双精度来说,指数的取值范围是[-1022,1023]。
frac部分被解释为小数值f,其中 0 ≤ f < 1 0\leq f < 1 0≤f<1,其二进制表示是 0. f n − 1 . . . f 1 f 0 0.f_{n-1}...f_1f_0 0.fn−1...f1f0,也就是二进制小数点在最高有效位的左边。有效数定义为M = 1 + f,这种方式叫做隐含的以1开头的表示,因此我们可以把M看作 1. f n − 1 . . . f 1 f 0 1.f_{n-1}...f_1f_0 1.fn−1...f1f0。
例如,现有如下的单精度浮点数的存储表示:
0 00111100 100000000000000000000000
符号位为0,代表正数;exp部分的值为60,则减去偏置值后,指数值为-67;frac部分的小数部分为0.1,加上隐含的二进制整数部分1,则有效数为1.1。最后,该单精度浮点数为 1. 1 ( 2 ) × 2 − 67 1.1_{(2)}\times 2^{-67} 1.1(2)×2−67。
情况二:非规格化的值
在这种情况下,exp全为0。

在这种情况下,指数值为n = 1 - Bias = -126,有效数的值M = f(即没有隐含的整数1了)。
例如,现有如下的单精度浮点数二进制表示:
0 00000000 00000000000000000000000
1 00000000 00000000000000000000000
第一行的值为 0 × 2 − 126 = + 0 0 \times 2^{-126} = +0 0×2−126=+0;第二行的值为 − 0 × 2 − 126 = − 0 -0 \times 2^{-126} = -0 −0×2−126=−0。所以在浮点数表示中,0有两种表示方法,分正负。
情况三:特殊值
在这种情况下,exp部分全为1。根据frac的值,又分为以下两种情况:
- frac为全0

在这种情况下,单精度浮点数值为无穷大 ∞ \infty ∞,根据符号位区分正负。
- frac不为0

在这种情况下,结果为NaN,表示非数字(Not a Number)。例如,当计算 ∞ − ∞ \infty - \infty ∞−∞时,结果就是NaN。
5. 变量与标识符
我们已经介绍了基本数据类型,并且用程序验证了各种数据类型所占字节的大小,那么现在就来讲解一下如何在程序中使用数据类型。我们看下面一段程序:
int a ;
这段程序的作用是:声明一个名为a的整型变量。
通过这段程序,我们接触到一个新的概念——变量。所谓变量,可以认为是内存中的一块存储区域,在该区域中存储某种数据类型的值,这个值是可以改变的,并且该块存储区域由变量名标识,我们可以通过变量名来取得存储的值,也可以通过变量名来改变存储的值。最后,变量名也称为标识符,关于标识符的规则,如下:
-
标识符由字母(A-Z,a-z)、数字(0-9)、下划线“_”组成,并且首字符不能是数字,但可以是字母或者下划线。例如,正确的标识符:abc,a1,prog_to。
-
不能把C语言关键字作为用户标识符,例如if,for,while等。
-
标识符长度是由机器上的编译系统决定的,一般的限制为8字符(注:8字符长度限制是C89标准,C99标准已经扩充长度,其实大部分工业标准都更长)。
-
标识符对大小写敏感,即严格区分大小写。一般对变量名用小写,符号常量命名用大写。例如,标识符
A和a是不同的。 -
标识符命名应做到**“见名知意”**,例如,长度(length),求和、总计(sum),圆周率(pi)。
前四条规则是必须遵守的,第五条规则是建议规则,关于变量命名,有如下命名规则:
- 驼峰命名法:对于变量名,如果包含多个单词,那么首单词的首字母小写,后面的单词首字母大写,其余字母都是小写。
- 下划线命名法:对于变量名,如果包含多个单词,那么每个单词之间用下划线
_分割。
例如,我们以一个变量来表示书的数量,那么驼峰命名法命名该变量可能为:numberOfBooks,下划线命名法可能为number_of_books。
MORE
关于标识符命名,如果想要深入了解,请搜索编程规范之命名。
6. 字符型与ASCII表
字符型数据类型占据一个字节的大小,总共有256个数字,如果将一个数字与一个字符对应起来,那么就可以表示256个字符了。
那么什么是字符呢?字符就是类字形单位或符号,包括字母、数字、运算符号、标点符号和其他符号,以及一些功能性符号。例如,字母A就是一个字符,汉字大也是一个字符。世界上的字符肯定远远超过256个,至少我们汉字就远不止256个吧,那么有符号字符型数据类型所表示的字符是哪些呢?这就是我们要说的ASCII码表。完整的ASCII码表请查看参考资料[1]。
我们以下面的两个例子做说明:
| Bin(二进制) | Dec(十进制) | 缩写/字符 | 解释 |
|---|---|---|---|
| 0010 0010 | 34 | " | 双引号 |
| 0100 0001 | 65 | A | 大写字母A |
对于字符"来说,这是一个双引号字符,它的数字对应着34,也就是说,如果一个字符型存储的值是34,那么它表示的字符是双引号。
从完整的ASCII码表中,我们也可以看出,字符型数据类型只使用了128个数字,只表示了128个字符,[-128,-1]是不代表任何字符的,所以在一个字符型数据类型的变量所标识的存储区域中,存储一个负数是无意义的。
由于在C语言中,字符与数字对应,所以字符型是一个特殊的整型数据类型。
MORE
在C语言中,一个字符型只代表ASCII码表中的字符,ASCII码表对于英语世界的字符是足够使用的,但是并不能表示汉字、日文、韩文等其他字符,所以这就是字符集与编码要解决的问题。(大家可以自行了解字符集与编码,有机会再介绍)
参考资料
[1] ASCII码表:https://baike.baidu.com/item/ASCII/309296
[2] Computer System: A Programmer’s Perspective.