法学领域的技术创新点
文章目录
- 一、中国法研杯-2019方案分享
-
- 1 相似案件检索——法律文书的相似判断
-
- 方案1 -冠军
- 方案2——三等奖
- 2 裁判文书论辩挖掘
- 二、中国法研杯2018总述
-
-
- Overview of CAIL2018: Legal Judgment Prediction Competition
-
- 三、中国法研杯2022-任务概述
-
-
- 事件检测
- 文书校对
- 类案检索
- 司法摘要
- 论辩理解
- 信息抽取
- 可解释类案匹配
-
- 四、法律相关文献
-
-
- 基于序列到序列模型的法律问题关键词抽取
- 融入罪名关键词的法律判决预测多任务学习模型
- Legal Judgment Prediction via Topological Learning
-
- 五、Legal NLP Introduction
一、中国法研杯-2019方案分享
1 相似案件检索——法律文书的相似判断
第一步是针对多篇法律文书进行相似度的计算和判断;然后对于每份文书提供文书的标题和事实描述,从两篇候选集文书中找到与询问文书更为相似的一篇。

挑战:
1.半结构化的法律文书
2.专业词汇多
3.案件文本长、案件复杂度高、案情灵活多变、案件分析数值繁多
方案1 -冠军
原文链接:
绝对假设:假定文书数据 A 和文书数据 B 之间是符合绝对的相似,同时文书数据 A 和文书数据 C 之间是符合绝对的不相似,即原先的三元组数据拆分成两两文书数据之间是否绝对相似的问题,这样就可以使用二分类模型来解决此类问题。
**问题:**在上述假设条件下,会出现数据标准冲突的问题。
将三元组之间的相对相似问题转化为 了两两文本间的相似距离计算,来评估文本之间的相似度。
细节:
- 文本特征选择:构建赛题案由相关的业务抽象特征。
因此,他们主要参考了合同法、担保法、婚姻法及相关司法解释,总结出了原告/被告属性、担保类型(一般、连带)、计息方式、约定借期利率、约定逾期利率、抵押物、借款合意凭据等七个特征。最终根据可行性以及数据表现,选用了原告被告特征、担保特征、利息特征等特征。
2. 模型tricks
(1) 模型融合:Bert 的多个layer的输出结果和Bert-Bi-LSTM和BI-GRU的融合。
方案2——三等奖
任务转化(任务表示形式):
我们将其转化为二元组相似任务。即假设sim(A,B)>sim(A,C),A与B相似度的标签为1,A与C相似度的标签为0
解决方案:
第一个模型:Siamese network
简单来说,Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的。如下图所示,通过两层的双向LSTM作为encoder,左右两边的encoder通过共享权值,然后通过余弦相似度衡量两个Sentence的相似情况。
第二个模型:InferSent
这里我们也使用BERT作为encoder,然后通过pooling,然后计算Sent A和Sent B的|u-v|以及u*v,得到两者的交互向量,线上分数可以达到64.5左右的acc。
第三个模型:原始的Bert
原始的BERT模型同样可以解决相似度匹配任务,同样地,我们在原始的BERT模型上也可以取得不错的成绩。
最终结果:以上模型结果的加权融合。


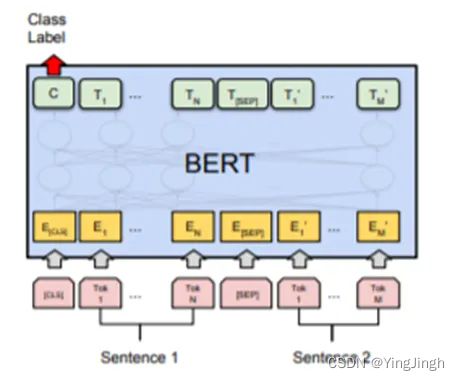
2 裁判文书论辩挖掘
在法院的庭审过程中,裁判文书起着记录辩、诉双方观点证据的重要作用,诉方与辩方由于立场观点的不同,或对于事实陈述的不一致,便形成了庭审过程中双方的争议焦点。
论辩挖掘任务,要求选手基于辩诉双方的陈述文本,输出存在逻辑交互关系的论点对(争议焦点)。本项任务以1000篇裁判文书以及4000对互动论点对为训练集、验证集和测试集,采用准确率进行评估。数之联的模型如下图所示,基于Bert的SiameseNetwork + triplet loss,诉称、辩称按照Bert经典的 sentencepair输入,确保诉称和辩称的相互attend。由于诉称和辩称之间的匹配关系并不是非黑即白,留有一定的匹配灰度,因此通过triplet loss 用来fightoverfitting。
原文链接:

二、中国法研杯2018总述
Overview of CAIL2018: Legal Judgment Prediction Competition
**目标:**根据给定事实预测判断结果
竞赛者常见技巧:
- 词嵌入。参与者已经证明,一个更好的词嵌入模型,如 ELMO(Peters 等人,2018 年),可以取得比 Skip-Gram(Mikolov 等人,2013 年)更好的性能。此外,在更大的法律语料库上训练词嵌入也能提高 LJP 模型的性能。
- 数据平衡。下采样和超采样方法是本次竞赛中解决类别不平衡问题的最常用方法。
- 联合学习。由于这些子任务之间存在依赖关系,一些参赛者会采用多任务学习模型来共同解决这些问题。
- 附加属性。受 Hu 等人(2018)的启发,参赛者通过预测类别对的法律属性来提高他们在少拍和易混类别对上的表现。
- 附加特征。许多参与者尝试手动提取特征,如涉及金额、命名实体、年龄等。这些手动定义的特征可以大大提高任务 3 的性能。
- 损失函数。大多数模型使用交叉熵作为损失函数。不过,有些模型采用了更有前途的损失函数,如焦点损失(Lin 等人,2018 年),以提高低频类别的性能。此外,不同类别的损失权重和输出层的激活函数对最终性能也有很大影响。
- 集合。大多数参与者会训练多个不同的分类模型,并通过简单的投票或权重将它们组合在一起。
三、中国法研杯2022-任务概述
事件检测
2022年的新任务。词级别分类,有点像序列标注,但不需要在所有词上面做预测。一共108种事件类型。训练集、验证集1来自于论文 LEVEN(ACL 2022 Findings), 包含8000+份文书,60000+个句子。验证集2和最终测试集将以混淆数据的形式向选手开放。
作者:Erutan Lai
链接:https://zhuanlan.zhihu.com/p/550558067
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
文书校对
2022年的新任务。
共13K语料,来源于裁判文书、检察文书等。针对拼写、冗余、缺失、乱序四种类型错误。
模型需要找出文中有问题的片段,并对该片段给出修改建议。
评价指标:综合F1值=0.8检出错误F1+0.2纠正错误F1
类案检索
任务同CAIL 2021类案检索任务相同。
采用LeCaRD数据集。给定若干查询案例,每案例对应大小为100的候选案例池,要筛选出与查询案例相关的类案(排序)。类案相似程度划分为四级。复赛和封闭测试阶段采用不公开的数据集。
包含107个查询案例和总数为10700的候选案例池。
评价标注采用NDCG@30(Normalized Discounted Cumulative Gain)
司法摘要
任务好像同CAIL 2021司法摘要任务略有不同。第一阶段使用的训练集、验证集、测试集来自互联网,包含大约9575条数据。评价指标采用ROUGE,具体加权方式为:0.2f-score(R1)+0.3f-score(R2)+0.5*f-score(RL)
论辩理解
同CAIL 2021论辩理解任务有差异,专注于 “争议观点对抽取”子任务。还是挺有意思的。训练数据集包含 约4000条裁判经标注的裁判文书。给定一个诉方观点和五个候选观点,模型需要自动识别出候选观点中哪一个是能形成争议的辩方观点。任务定义形式客观可行。以准确率(P@1)作为评价指标。
信息抽取
同 CAIL 2021 信息抽取任务不同,去年关注于实体抽取,而这次关注抽取文本中的实体关系三元组。数据涉及若干涉毒类罪名法律文书,总计1750条数据。关注三种罪名:贩卖毒品罪、非法持有毒品罪和容留他人吸毒罪。抽取4种关系类型:贩卖(给人)( sell_drug_to ),贩卖(毒品)( traffic_in ),持有( possess ),非法容留( provide_shelter_for )。采用微平均F1值(Micro-F1-measure)作为评价指标
可解释类案匹配
2022年的新任务。训练集和测试集来源于人工标注的5000对案例(案由均为“妨碍社会管理秩序罪”)。匹配结果为:“匹配”/“部分匹配”/“不匹配”。且标注了匹配解释:与类案匹配相关的司法特征句、并对匹配的两种类型标注了特征句之间的对齐关系。以宏F1(Macro-F1)作为评价指标,匹配结果得分与解释结果得分取均值作为最终的分数。
四、法律相关文献
2020前相关文献:
基于序列到序列模型的法律问题关键词抽取
用的是生成模型,为了保证关键词生成的质量,使用了强化学习,来做质量的把控。
方法:一种基于强化学习的序列到序列模型来对法律问题自动生成关键词
问题现状: 普通用户提交的问题文本口语化程度比较高。本文提出一种根据问题的语义信息来抽取关键词的方法,将关键词抽取看作生成问题而非简单的抽取问题.
融入罪名关键词的法律判决预测多任务学习模型
罪名预测和法条推荐是法律判决预测的2个重要子任务。主要目标为:通过给定的刑事法律文书中的案情描述部分,自动预测被告人的罪名以及本案涉及的相关法条.
模型结构: 编 码 端 采 用 层 次 化 注 意 力 机 制(hierarchicalattentionnetworks,HAN)[29]对案情描述进行编码,解码端采用多个二元分类进行建模同时预测罪名和法条. (关键词获取是结巴。用 TF-IDF、TextRank对关
键词候选词的得分进行排序)

Legal Judgment Prediction via Topological Learning
法律判决通常由多个子任务组成,如适用法律条款的决定、指控、罚款和处罚期限等。这些子任务之间可能是存在依存关系 的。
判决流程:

在设计模型解决案件问题上,是先根据人的判决过程设置的。一般而言,大陆法系的法官首先决定哪些法律条文与该场景相关,然后根据相关法律条文的指示确定罪名。
子任务如果没有任何关联,子任务是可以并行的。如果存在依存关系,则串行。

模型结构:

五、Legal NLP Introduction
法律技术有广泛的应用领域,可帮助律师事务所和机构开展与文件支持(创建、修订、存储和检索)、法律程序(在诉讼和政府调查过程中提供电子文件、对(非)法律来源进行法律研究以支持决策)相关的日常活动,以及更广泛地说,与法律服务从文本和纸张到数字形式的非物质化相关的所有方面。其中一些领域以文件和语言为中心(文件存储和检索、电子发现、法律研究和文件自动化/组装),与法律 NLP 高度相关。
NLP 技术最初用于协助起草法律文件。一种常见的自动支持方法依赖于起草的决策树模型,在这种模型中,文件模板(如合同)会根据起草者的本地决定自动完善和实例化。
信息检索:检索相关文本,并提取与特定案件相关的具体法律和法定规则。
起草、出版、查询、链接和推理法律资料来源
文本特点:
1.独特的法律表述
2.标准化或法典化的法律语言词典
3.不同术语
4.句法结构(文本长且高度结构化)
5.语料结构复杂,相互联系密切。