力扣刷题之排序
力扣刷题之排序
-
-
- 147.对链表进行插入排序
- 148.排序链表
- 242.有效的字母异位词
- 274.H指数
- 347.前K个高频元素
- 349.两个数组的交集
- 350.两个数组的交集II
- 354.俄罗斯套娃信封问题
- 435.无重叠区间
- 378.有序矩阵中第K小的元素
- 389.找不同
- 406.根据身高重建队列
- 436.寻找右区间
- 451.根据字符出现频率排序
- 452.用最少数量的箭引爆气球
- 455.分发饼干
- 462.最少移动次数使数组元素相等II
- 475.供暖器
- 506.相对名次
- 522.最长特殊序列II
- 532.数组中的k-diff数对
-
147.对链表进行插入排序
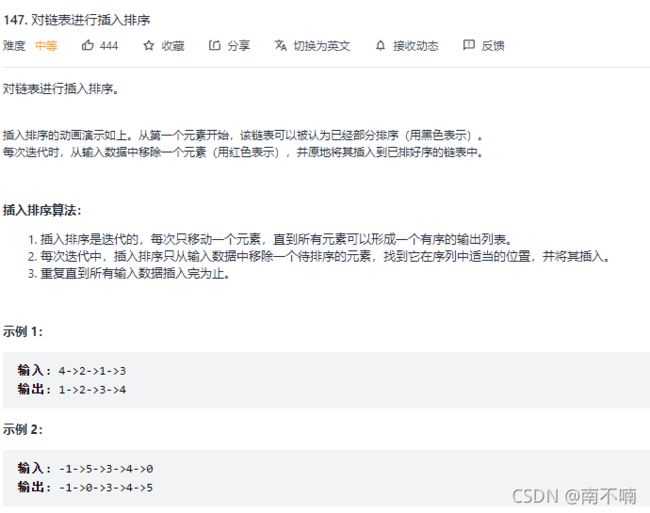

class Solution {
public:
ListNode* insertionSortList(ListNode* head) {
if (head == nullptr) {
return head;
}
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* lastSorted = head;
ListNode* curr = head->next;
while (curr != nullptr) {
if (lastSorted->val <= curr->val) {
lastSorted = lastSorted->next;
} else {
ListNode *prev = dummyHead;
while (prev->next->val <= curr->val) {
prev = prev->next;
}
lastSorted->next = curr->next;
curr->next = prev->next;
prev->next = curr;
}
curr = lastSorted->next;
}
return dummyHead->next;
}
};
148.排序链表


归并排序 自顶向下

class Solution {
public:
ListNode* sortList(ListNode* head) {
return sortList(head, nullptr);
}
ListNode* sortList(ListNode* head, ListNode* tail) {
if (head == nullptr) {
return head;
}
if (head->next == tail) {
head->next = nullptr;
return head;
}
ListNode* slow = head, *fast = head;
while (fast != tail) {
slow = slow->next;
fast = fast->next;
if (fast != tail) {
fast = fast->next;
}
}
ListNode* mid = slow;
return merge(sortList(head, mid), sortList(mid, tail));//空间复杂度:O(logn),其中 n 是链表的长度。空间复杂度主要取决于递归调用的栈空间。
}
ListNode* merge(ListNode* head1, ListNode* head2) {
ListNode* dummyHead = new ListNode(0);
ListNode* temp = dummyHead, *temp1 = head1, *temp2 = head2;
while (temp1 != nullptr && temp2 != nullptr) {
if (temp1->val <= temp2->val) {
temp->next = temp1;
temp1 = temp1->next;
} else {
temp->next = temp2;
temp2 = temp2->next;
}
temp = temp->next;
}
if (temp1 != nullptr) {
temp->next = temp1;
} else if (temp2 != nullptr) {
temp->next = temp2;
}
return dummyHead->next;
}
};
归并排序 自底向上

class Solution {
public:
ListNode* sortList(ListNode* head) {
if (head == nullptr) {
return head;
}
int length = 0;
ListNode* node = head;
while (node != nullptr) {
length++;
node = node->next;
}
ListNode* dummyHead = new ListNode(0, head);//初始化一个空结点,初始赋值为0,并且list的下一个next指针指向head,指针指向为list
for (int subLength = 1; subLength < length; subLength <<= 1) {
ListNode* prev = dummyHead, *curr = dummyHead->next;
while (curr != nullptr) {
ListNode* head1 = curr;
for (int i = 1; i < subLength && curr->next != nullptr; i++) {
curr = curr->next;
}
ListNode* head2 = curr->next;
curr->next = nullptr;
curr = head2;
for (int i = 1; i < subLength && curr != nullptr && curr->next != nullptr; i++) {
curr = curr->next;
}
ListNode* next = nullptr;
if (curr != nullptr) {
next = curr->next;
curr->next = nullptr;
}
ListNode* merged = merge(head1, head2);
prev->next = merged;
while (prev->next != nullptr) {
prev = prev->next;
}
curr = next;
}
}
return dummyHead->next;
}
ListNode* merge(ListNode* head1, ListNode* head2) {
ListNode* dummyHead = new ListNode(0);
ListNode* temp = dummyHead, *temp1 = head1, *temp2 = head2;
while (temp1 != nullptr && temp2 != nullptr) {
if (temp1->val <= temp2->val) {
temp->next = temp1;
temp1 = temp1->next;
} else {
temp->next = temp2;
temp2 = temp2->next;
}
temp = temp->next;
}
if (temp1 != nullptr) {
temp->next = temp1;
} else if (temp2 != nullptr) {
temp->next = temp2;
}
return dummyHead->next;
}
};
242.有效的字母异位词
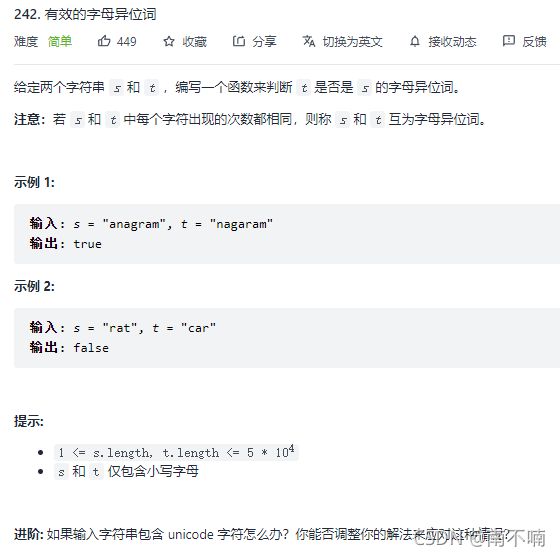
自己做的双哈希表
空间复杂度高
官方解法:
法一:排序
t 是 s 的异位词等价于「两个字符串排序后相等」。因此我们可以对字符串 s 和 t 分别排序,看排序后的字符串是否相等即可判断。此外,如果 s 和 tt的长度不同,t 必然不是 s的异位词。
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length() != t.length()) {
return false;
}
sort(s.begin(), s.end());
sort(t.begin(), t.end());
return s == t;
}
};
法二:哈希表
由于字符串只包含 26个小写字母,因此我们可以维护一个长度为 26的频次数组table,先遍历记录字符串 s中字符出现的频次,然后遍历字符串 t,减去table 中对应的频次,如果出现table[i]<0,则说明 t包含一个不在 s中的额外字符,返回 false 即可。
class Solution {
public:
bool isAnagram(string s, string t) {
unordered_map<char,int> map;
if (s.size() != t.size())
return false;
for(int i=0;i<s.size();i++){
++map[s[i]];
--map[t[i]];
}
for(unordered_map<char,int>::iterator it=map.begin();it!=map.end();it++){
if(it->second!=0)
return false;
}
return true;
}
};
274.H指数
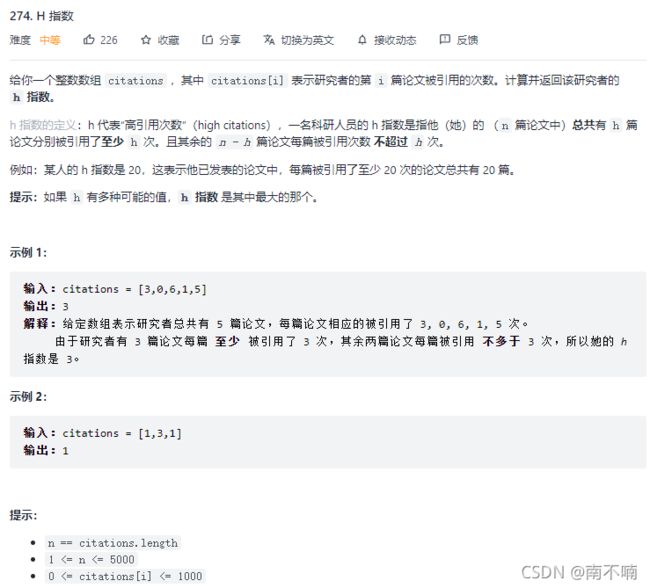
法一:排序

class Solution {
public:
int hIndex(vector<int>& citations) {
sort(citations.begin(), citations.end());
int h = 0, i = citations.size() - 1;
while (i >= 0 && citations[i] > h) {
h++;
i--;
}
return h;
}
};
法二:计数排序

class Solution {
public:
int hIndex(vector<int>& citations) {
int n = citations.size(), tot = 0;
vector<int> counter(n + 1);
for (int i = 0; i < n; i++) {
if (citations[i] >= n) {
counter[n]++;
} else {
counter[citations[i]]++;
}
}
for (int i = n; i >= 0; i--) {
tot += counter[i];
if (tot >= i) {
return i;
}
}
return 0;
}
};
347.前K个高频元素
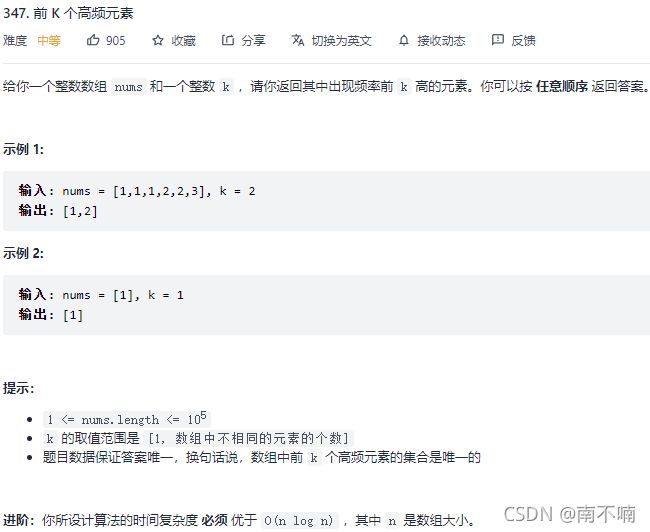
法一:堆

为什么是小顶堆而不是大顶堆?
只要能比堆里面最小的那个大,就行了,没必要当最大的那一个。你这么想,名额就k个,最差的情况就是我把第k名打败了,我就能进去,那么只要和k个里面最小的比就行
小顶堆的话,不需要把所有的节点都加入,堆的数据少,每次pop后维护更快。大顶堆的话,写起来方便,但是就要把所有的节点都加入堆中,每次pop后需要维护的工作可能更多。个人理解哈。
小顶堆是nlogk,大顶堆是nlogn
class Solution {
public:
static bool cmp(pair<int, int>& m, pair<int, int>& n) {
return m.second > n.second;
}
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int> occurrences;
for (auto& v : nums) {
occurrences[v]++;
}
// pair 的第一个元素代表数组的值,第二个元素代表了该值出现的次数
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(&cmp)> q(cmp);//q()不写cmp会报错,因为pair标准库没有写他的运算符排序,需要手写一个函数来确定他的优先级,cmp就相当于把这个函数作为参数进行传值
for (auto& [num, count] : occurrences) {
if (q.size() == k) {
if (q.top().second < count) {
q.pop();
q.emplace(num, count);
}
} else {
q.emplace(num, count);
}
}
vector<int> ret;
while (!q.empty()) {
ret.emplace_back(q.top().first);
q.pop();
}
return ret;
}
};
法二:快速排序

class Solution {
public:
void qsort(vector<pair<int, int>>& v, int start, int end, vector<int>& ret, int k) {
int picked = rand() % (end - start + 1) + start;
swap(v[picked], v[start]);
int pivot = v[start].second;
int index = start;
for (int i = start + 1; i <= end; i++) {
if (v[i].second >= pivot) {
swap(v[index + 1], v[i]);
index++;
}
}
swap(v[start], v[index]);
if (k <= index - start) {
qsort(v, start, index - 1, ret, k);
} else {
for (int i = start; i <= index; i++) {
ret.push_back(v[i].first);
}
if (k > index - start + 1) {
qsort(v, index + 1, end, ret, k - (index - start + 1));
}
}
}
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int> occurrences;
for (auto& v: nums) {
occurrences[v]++;
}
vector<pair<int, int>> values;
for (auto& kv: occurrences) {
values.push_back(kv);
}
vector<int> ret;
qsort(values, 0, values.size() - 1, ret, k);
return ret;
}
};
349.两个数组的交集
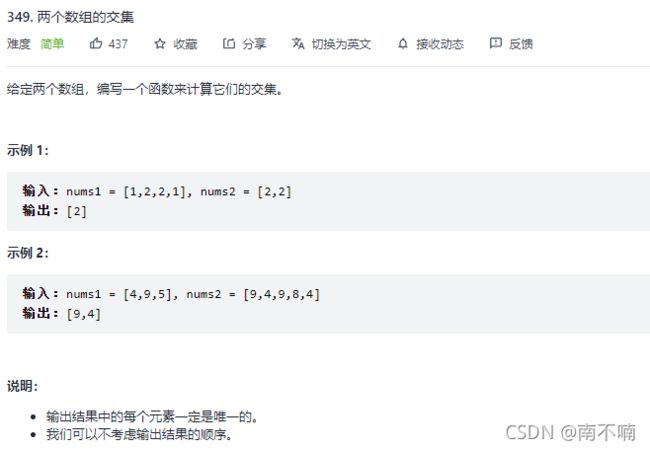

class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> set1, set2;
for (auto& num : nums1) {
set1.insert(num);
}
for (auto& num : nums2) {
set2.insert(num);
}
return getIntersection(set1, set2);
}
vector<int> getIntersection(unordered_set<int>& set1, unordered_set<int>& set2) {
if (set1.size() > set2.size()) {
return getIntersection(set2, set1);
}
vector<int> intersection;
for (auto& num : set1) {
if (set2.count(num)) {
intersection.push_back(num);
}
}
return intersection;
}
};
法二:排序+双指针

class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
sort(nums1.begin(), nums1.end());
sort(nums2.begin(), nums2.end());
int length1 = nums1.size(), length2 = nums2.size();
int index1 = 0, index2 = 0;
vector<int> intersection;
while (index1 < length1 && index2 < length2) {
int num1 = nums1[index1], num2 = nums2[index2];
if (num1 == num2) {
// 保证加入元素的唯一性
if (!intersection.size() || num1 != intersection.back()) {
intersection.push_back(num1);
}
index1++;
index2++;
} else if (num1 < num2) {
index1++;
} else {
index2++;
}
}
return intersection;
}
};
350.两个数组的交集II
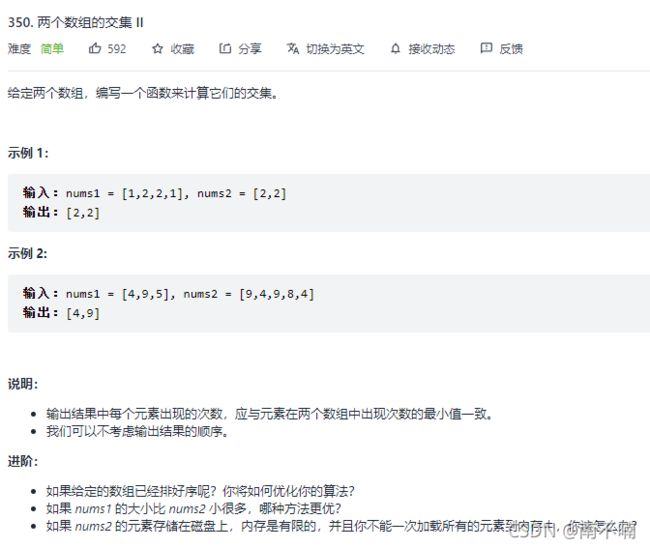
法一:哈希表

class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
if (nums1.size() > nums2.size()) {
return intersect(nums2, nums1);
}
unordered_map <int, int> m;
for (int num : nums1) {
++m[num];
}
vector<int> intersection;
for (int num : nums2) {
if (m.count(num)) {
intersection.push_back(num);
--m[num];
if (m[num] == 0) {
m.erase(num);
}
}
}
return intersection;
}
};
法二:排序+双指针

class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
sort(nums1.begin(), nums1.end());
sort(nums2.begin(), nums2.end());
int length1 = nums1.size(), length2 = nums2.size();
vector<int> intersection;
int index1 = 0, index2 = 0;
while (index1 < length1 && index2 < length2) {
if (nums1[index1] < nums2[index2]) {
index1++;
} else if (nums1[index1] > nums2[index2]) {
index2++;
} else {
intersection.push_back(nums1[index1]);
index1++;
index2++;
}
}
return intersection;
}
};

354.俄罗斯套娃信封问题
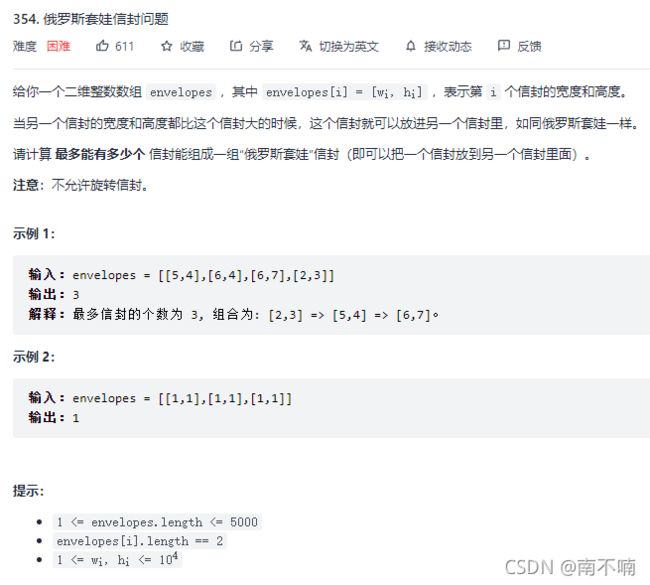
法一:动态规划

class Solution {
public:
int maxEnvelopes(vector<vector<int>>& envelopes) {
if (envelopes.empty()) {
return 0;
}
int n = envelopes.size();
sort(envelopes.begin(), envelopes.end(), [](const auto& e1, const auto& e2) {
return e1[0] < e2[0] || (e1[0] == e2[0] && e1[1] > e2[1]);
});
vector<int> f(n, 1);
for (int i = 1; i < n; ++i) {
for (int j = 0; j < i; ++j) {
if (envelopes[j][1] < envelopes[i][1]) {
f[i] = max(f[i], f[j] + 1);
}
}
}
return *max_element(f.begin(), f.end());
}
};
435.无重叠区间
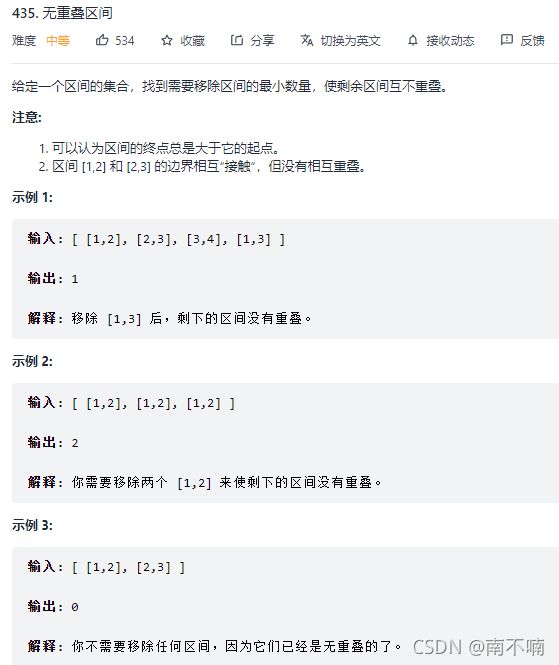

超时n^2
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
if (intervals.empty()) {
return 0;
}
sort(intervals.begin(), intervals.end(), [](const auto& u, const auto& v) {
return u[0] < v[0];
});
int n = intervals.size();
vector<int> f(n, 1);
for (int i = 1; i < n; ++i) {
for (int j = 0; j < i; ++j) {
if (intervals[j][1] <= intervals[i][0]) {
f[i] = max(f[i], f[j] + 1);
}
}
}
return n - *max_element(f.begin(), f.end());
}
};
法二:贪心nlogn

class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
if (intervals.empty()) {
return 0;
}
sort(intervals.begin(), intervals.end(), [](const auto& u, const auto& v) {
return u[1] < v[1];
});
int n = intervals.size();
int right = intervals[0][1];
int ans = 1;
for (int i = 1; i < n; ++i) {
if (intervals[i][0] >= right) {
++ans;
right = intervals[i][1];
}
}
return n - ans;
}
};
378.有序矩阵中第K小的元素
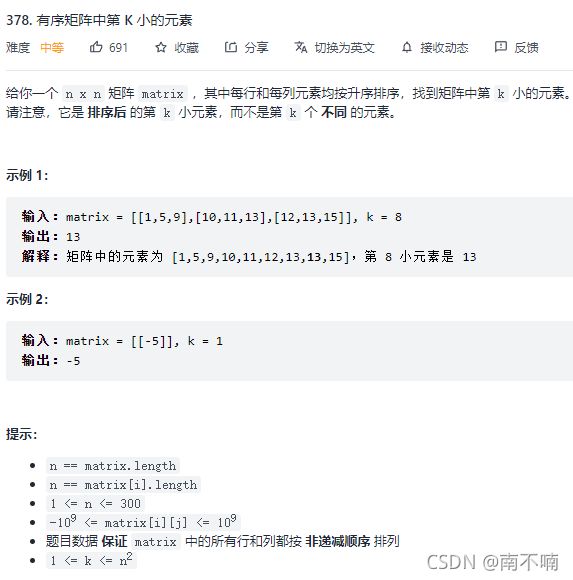
法一:直接排序
二维数组转化为一维数组
class Solution {
public:
int kthSmallest(vector<vector<int>>& matrix, int k) {
vector<int> rec;
for (auto& row : matrix) {
for (int it : row) {
rec.push_back(it);
}
}
sort(rec.begin(), rec.end());
return rec[k - 1];
}
};
法二:归并排序

暂时没看懂这个怎么归并排序的,还要用小根堆来维护???
class Solution {
public:
int kthSmallest(vector<vector<int>>& matrix, int k) {
struct point {
int val, x, y;
point(int val, int x, int y) : val(val), x(x), y(y) {}
bool operator> (const point& a) const { return this->val > a.val; }
};
priority_queue<point, vector<point>, greater<point>> que;
int n = matrix.size();
for (int i = 0; i < n; i++) {
que.emplace(matrix[i][0], i, 0);
}
for (int i = 0; i < k - 1; i++) {
point now = que.top();
que.pop();
if (now.y != n - 1) {
que.emplace(matrix[now.x][now.y + 1], now.x, now.y + 1);
}
}
return que.top().val;
}
};
法三:二分查找


class Solution {
public:
bool check(vector<vector<int>>& matrix, int mid, int k, int n) {
int i = n - 1;
int j = 0;
int num = 0;
while (i >= 0 && j < n) {
if (matrix[i][j] <= mid) {
num += i + 1;
j++;
} else {
i--;
}
}
return num >= k;
}
int kthSmallest(vector<vector<int>>& matrix, int k) {
int n = matrix.size();
int left = matrix[0][0];
int right = matrix[n - 1][n - 1];
while (left < right) {
int mid = left + ((right - left) >> 1);
if (check(matrix, mid, k, n)) {
right = mid;
} else {
left = mid + 1;
}
}
return left;
}
};
389.找不同
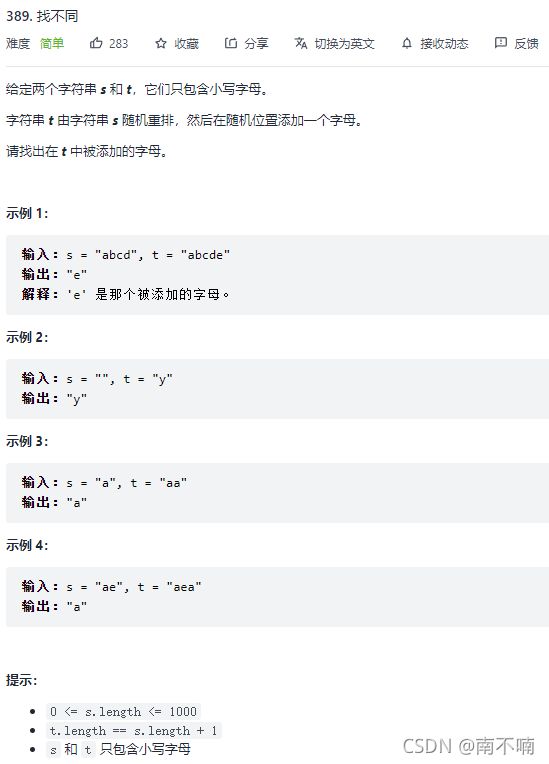
法一:计数

class Solution {
public:
char findTheDifference(string s, string t) {
vector<int> cnt(26, 0);
for (char ch: s) {
cnt[ch - 'a']++;
}
for (char ch: t) {
cnt[ch - 'a']--;
if (cnt[ch - 'a'] < 0) {
return ch;
}
}
return ' ';
}
};
法二:求和

class Solution {
public:
char findTheDifference(string s, string t) {
int as = 0, at = 0;
for (char ch: s) {
as += ch;
}
for (char ch: t) {
at += ch;
}
return at - as;
}
};
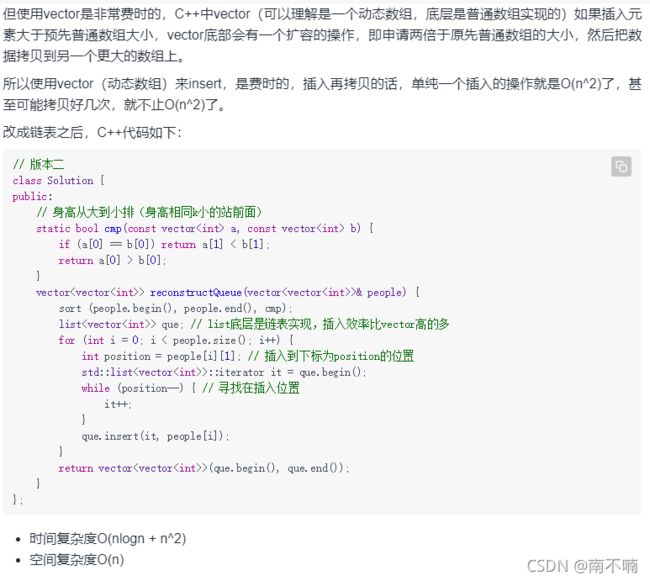
406.根据身高重建队列
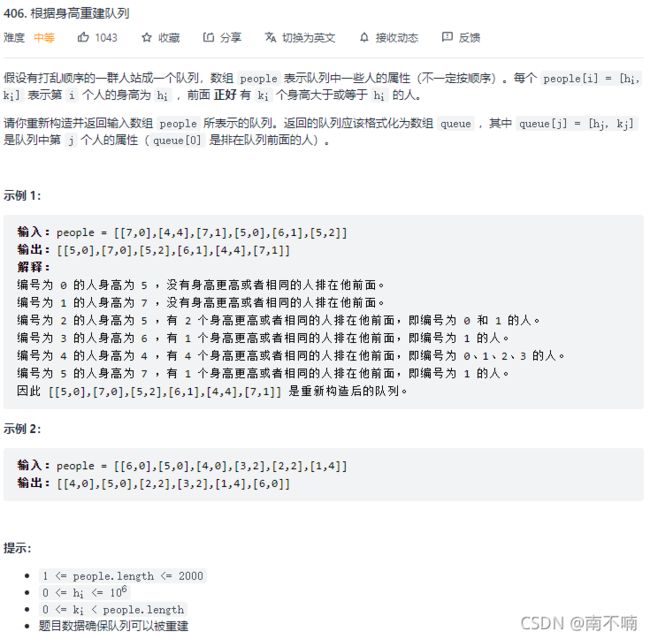

遇到两个维度权衡的时候,一定要先确定一个维度,再确定另一个维度。
如果两个维度一起考虑一定会顾此失彼



// 版本一
class Solution {
public:
static bool cmp(const vector<int> a, const vector<int> b) {
if (a[0] == b[0]) return a[1] < b[1];
return a[0] > b[0];
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort (people.begin(), people.end(), cmp);
vector<vector<int>> que;
for (int i = 0; i < people.size(); i++) {
int position = people[i][1];
que.insert(que.begin() + position, people[i]);
}
return que;
}
};
// 版本二
class Solution {
public:
// 身高从大到小排(身高相同k小的站前面)
static bool cmp(const vector<int> a, const vector<int> b) {
if (a[0] == b[0]) return a[1] < b[1];
return a[0] > b[0];
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort (people.begin(), people.end(), cmp);
list<vector<int>> que; // list底层是链表实现,插入效率比vector高的多
for (int i = 0; i < people.size(); i++) {
int position = people[i][1]; // 插入到下标为position的位置
std::list<vector<int>>::iterator it = que.begin();
while (position--) { // 寻找在插入位置
it++;
}
que.insert(it, people[i]);
}
return vector<vector<int>>(que.begin(), que.end());
}
};
436.寻找右区间
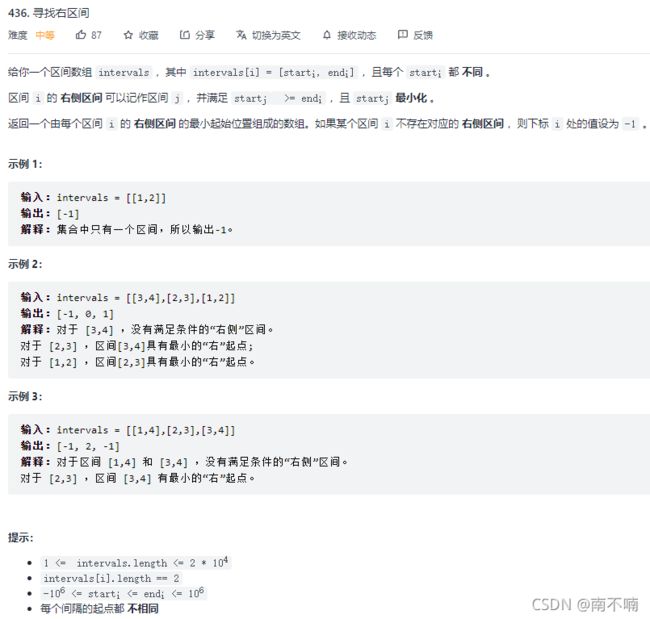
map+lower_bound(二分)
class Solution {
public:
vector<int> findRightInterval(vector<vector<int>>& intervals) {
map<int,int>left2index;
for(int i=0;i<intervals.size();i++){
left2index[intervals[i][0]]=i;
}
vector<int>ans;
for(auto vec:intervals){
auto it=left2index.lower_bound(vec[1]);
if(it==left2index.end())ans.push_back(-1);
else ans.push_back((*it).second);
}
return ans;
}
};

class Solution {
public:
vector<int> findRightInterval(vector<vector<int>>& intervals) {
// 左边界到序号的映射
unordered_map<int, int> left2index;
int n = intervals.size();
for (int i = 0; i < n; ++i)
{
left2index[intervals[i][0]] = i;
}
// 按照左边界从小到大排序
sort(intervals.begin(), intervals.end(), [](const vector<int>& a, const vector<int>& b) {
return a[0] < b[0];
});
// 遍历二分去找每个的满足条件的最小区间
vector<int> res(n, -1);
for (int i = 0; i < n; ++i)
{
// 当前的右边界
int right = intervals[i][1];
int l = 0;
int r = n-1;
while (l <= r)
{
int m = (l+r) >> 1;
if (intervals[m][0] >= right)
{
// 这个结果记得去按照左边界找回自己真实的序号
res[left2index[intervals[i][0]]] = left2index[intervals[m][0]];
r = m-1;
}
else
{
l = m+1;
}
}
}
return res;
}
};
451.根据字符出现频率排序
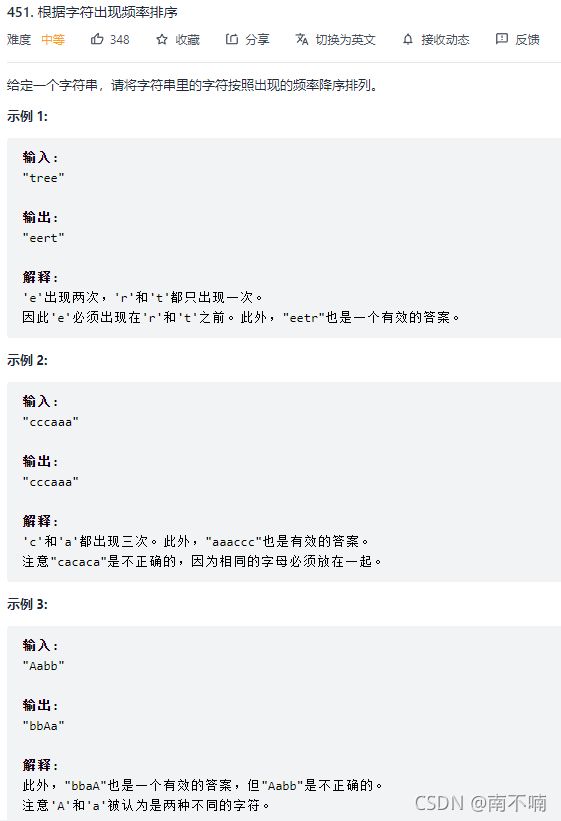
按照出现频率排序(哈希表)

class Solution {
public:
string frequencySort(string s) {
unordered_map<char, int> mp;
int length = s.length();
for (auto &ch : s) {
mp[ch]++;
}
vector<pair<char, int>> vec;
for (auto &it : mp) {
vec.emplace_back(it);
}
sort(vec.begin(), vec.end(), [](const pair<char, int> &a, const pair<char, int> &b) {
return a.second > b.second;
});
string ret;
for (auto &[ch, num] : vec) {
for (int i = 0; i < num; i++) {
ret.push_back(ch);
}
}
return ret;
}
};
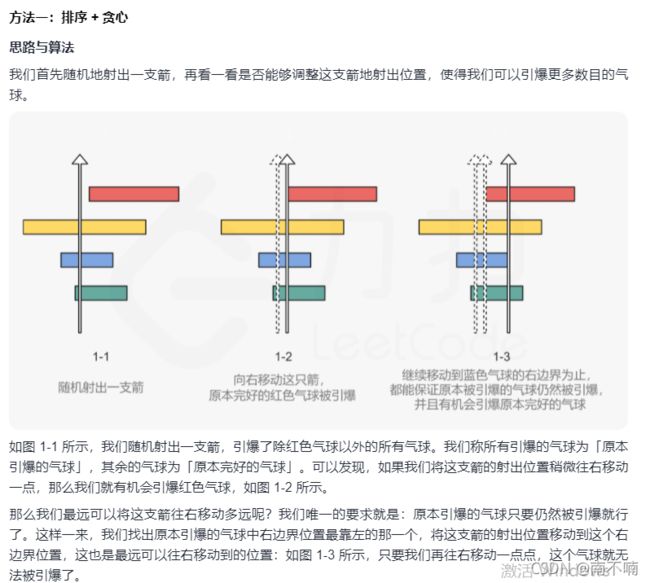
452.用最少数量的箭引爆气球
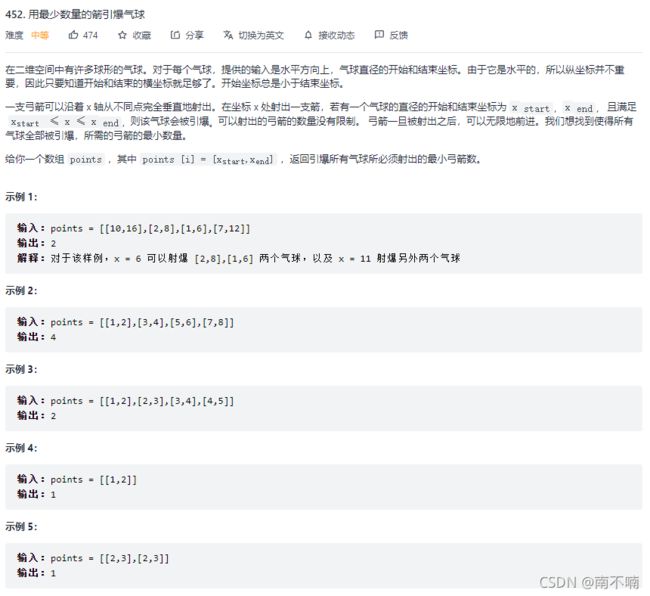
排序+贪心

class Solution {
public:
int findMinArrowShots(vector<vector<int>>& points) {
if (points.empty()) {
return 0;
}
sort(points.begin(), points.end(), [](const vector<int>& u, const vector<int>& v) {
return u[1] < v[1];
});
int pos = points[0][1];
int ans = 1;
for (const vector<int>& balloon: points) {
if (balloon[0] > pos) {
pos = balloon[1];
++ans;
}
}
return ans;
}
};
455.分发饼干

class Solution {
public:
int findContentChildren(vector<int>& g, vector<int>& s) {
sort(g.begin(), g.end());
sort(s.begin(), s.end());
int numOfChildren = g.size(), numOfCookies = s.size();
int count = 0;
for (int i = 0, j = 0; i < numOfChildren && j < numOfCookies; i++, j++) {
while (j < numOfCookies && g[i] > s[j]) {
j++;
}
if (j < numOfCookies) {
count++;
}
}
return count;
}
};
462.最少移动次数使数组元素相等II

public class Solution {
public int minMoves2(int[] nums) {
Arrays.sort(nums);
int sum = 0;
for (int num : nums) {
sum += Math.abs(nums[nums.length / 2] - num);
}
return sum;
}
}
快速排序找中位数
class Solution {
public:
//快速选择寻找中位数
int patition(vector<int> &arr, int l, int r) {
int ran = rand() % (r - l + 1) + l;
swap(arr[ran], arr[r]);
int index = l - 1, x = arr[r];
for(int i = l; i < r; ++i) {
if(arr[i] <= x) {
swap(arr[++index], arr[i]);
}
}
swap(arr[++index], arr[r]);
return index;
}
int quickSelect(vector<int> &arr, int l, int r, int target) {
//递归到树底返回
if(l == r)return arr[r];
//获取局部排序下标
int index = patition(arr, l, r);
//找到返回,没找到缩小范围
if(index == target)return arr[index];
else if(index > target) {
return quickSelect(arr, l, index - 1, target);
}else {
return quickSelect(arr, index, r, target);
}
}
int minMoves2(vector<int>& nums) {
srand((unsigned)time(0));
int n = nums.size();
int midNum = quickSelect(nums, 0, n - 1, n / 2);
int ans = 0;
for(int &num : nums) {
ans += abs(midNum - num);
}
return ans;
}
};
475.供暖器


class Solution {
public:
int findRadius(vector<int>& houses, vector<int>& heaters) {
sort(houses.begin(), houses.end());
sort(heaters.begin(), heaters.end());
int ans = 0, i = 0, j = 0;
while (i < houses.size()) {
int pre = ans;
ans = max(ans, abs(houses[i] - heaters[j]));
// while内的逻辑是当下一个加热器 heater[j + 1] 距离当前房屋较近时,即取下一个加热器
while (j < heaters.size() - 1 && abs(houses[i] - heaters[j]) >= abs(houses[i] - heaters[j + 1])) {
++j;
ans = max(pre, abs(houses[i] - heaters[j]));
}
++i;
}
return ans;
}
};
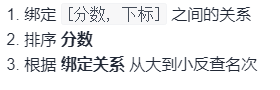
506.相对名次

class Solution {
public:
vector<string> findRelativeRanks(vector<int>& score) {
vector<string> res(score.size());
map<int, int> worker;
for (int i = 0; i < score.size(); ++i)
worker.insert({score[i], i});
int i = 0;
for (auto it = worker.rbegin(); it != worker.rend(); ++it, ++i) {
switch(i) {
case 0: res[it->second] = "Gold Medal";
break;
case 1: res[it->second] = "Silver Medal";
break;
case 2: res[it->second] = "Bronze Medal";
break;
default: res[it->second] = to_string(i + 1);
}
}
return res;
}
};
522.最长特殊序列II

老实说,不太懂
class Solution {
private:
bool IsSub(const string& a, const string& b)
{
int i = 0;
int j = 0;
for (; i < a.size() && j < b.size(); ++j)
{
if (a[i] == b[j])
{
++i;
}
}
// a里每一个都在b里找到了
return i == a.size();
}
public:
int findLUSlength(vector<string>& strs) {
// 按照长度从大到小进行排序
sort(strs.begin(), strs.end(), [](const string& a, const string& b){
return a.size() > b.size();
});
int n = strs.size();
for (int i = 0; i < n; ++i)
{
int j = 0;
for (; j < n; ++j)
{
if (i != j)
{
if (IsSub(strs[i], strs[j]))
{
break;
}
}
}
if (j == n)
{
return strs[i].size();
}
}
return -1;
}
};
532.数组中的k-diff数对


遍历一遍 将数据和次数 存入哈希表中,再遍历一遍统计结果
class Solution {
public:
int findPairs(vector<int>& nums, int k) {
unordered_map<int,int> mp;
int res = 0;
for(const auto& i : nums){//数据的值和出现的次数
mp[i]++;
}
for(const auto& m : mp){
if(k == 0){
res += (m.second > 1);
} else {
res += mp.count(m.first - k);
}
}
return res;
}
};