Unity Perception合成数据生成、标注与ML模型训练

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 3D场景编辑器
任何训练过机器学习模型的人都会告诉你,模型是从数据得到的,一般来说,更多的数据和标签会带来更好的性能。 收集数据,尤其是标记数据非常耗时,因此成本高昂。 因此,机器学习专业人士越来越多地寻求通过使用人工生成的数据样本变体来“增强”其数据集的更有效方法,但也越来越多地使用混合或完全合成的数据。
游戏引擎公司 Unity 提供了一个名为 Unity Perception 的工具,它允许你以不同的方式模拟对象并拍摄模拟的虚拟图片。 通过这种方式,可以从对象扫描中生成大量标记图像,这些图像可用作训练数据。
另一种更好的方法是使用UnrealSynth 虚幻合成数据生成器,基于虚幻引擎开发的UnrealSynth渲染效果极其逼真,并且自动标注生成的图像,非常方便:

官网:https://tools.nsdt.cloud/UnrealSynth
在这篇博文中,我介绍了我在 ML6 实习的结果,在此过程中我研究了使用 Unity Perception 为对象检测模型生成训练数据。 更具体地说,我将描述我如何:
- 使用激光雷达相机获得物体扫描
- 使用 Unity 为这些对象生成合成数据集
- 使用合成图像和真实图像训练目标检测模型
- 评估将合成图像添加到训练集中的潜在好处
1、扫描物体
为了创建对象网格,我在带有激光雷达摄像头的手机上使用了名为 Scaniverse 的应用程序。 为了做好这件事,有一些要求。 你必须能够从各个侧面捕捉物体,并且需要物体的所有角度都有良好且均匀的照明
因此,我将对象放在光线良好的底座上,使用应用程序扫描对象,然后单独拍摄底部表面的照片,将其添加到 Blender 中的对象网格中。 使用 Scaniverse,你可以将对象导出为 fbx 或 obj 文件,两者均可与 Blender 和 Unity 配合使用。

Blender 中的对象扫描示例
然而,并非所有物体都易于扫描。 尤其是具有反射表面、薄或透明部分的物体,使用这种方法进行扫描时会出现问题。 如果扫描结果不太好,仍然可以使用 Blender 进行编辑。
主要用于裁剪和重新调整它们的位置; 或者将它们与底面组合以获得完整的物体。
我还对每个物体进行了多次扫描,以增加合成图像中物体的变化,并在不同的房间和位置为我扫描的每个物体拍摄了大约 200 张照片。 我尝试将这些物体放置在不同的位置,并从不同的角度拍摄照片。 我确保图片有时更加模糊或仅部分显示物体,以进一步增加变化。
下面是我使用过的 3 个物体的扫描图:一只鞋子、一个可口可乐罐和一个家乐氏麦片盒。
我选择这些对象是因为:
- 它们很容易移动并手动拍照
- 它们将适合室内场景背景
- 它们在颜色、结构和反光性能方面有很大不同

Unity 感知中的对象扫描示例
2、Unity Perception 生成合成数据
Unity Perception 是一个用于生成数据集的工具包。 它相对较新,目前仅适用于基于相机的用例。 它是 Unity 的插件、游戏引擎和跨平台 IDE。
为了生成训练图像,我使用了一种模拟,将对象以随机旋转、缩放和位置放置在背景前面以及光源和相机之前。 物体以相同的概率被抽出; 每个类别都有相同数量的表示。
Unity Perception UI
为了获得更多变化,我随机化了照明强度,并对对象和不同类型的背景生成使用了不同的平滑度属性。 我使用了与 Unity 在 Unity Perception 教程中使用的相同的背景生成方案,该方案由具有随机纹理作为背景的随机对象组成。 这确保了每次模拟都有非常不同的背景,除了对象类之外没有其他可识别的对象。 出于一般目的,这是一个很好的起点(这种情况在下图中称为模拟 )。

Unity Perception背景模拟
然而,仅对这些图像进行训练并没有产生很好的结果,因此我尝试切换到随机背景图像。 这些背景图像是从室内场景的在线数据集中采样的。 这极大地改善了结果,如下图所示。 应根据对象类的自然上下文来选择从这些背景图像中采样的数据集。

背景图像模拟
为了进一步改善场景,我添加了随机对象,但现在数量更少并且位于前景中。 这些对象有时会部分地掩盖类别,但也使场景更加多样化。

背景图像和随机物体的模拟
我所做的另一个改进是对同一对象类使用多个对象网格。 这改善了更复杂对象的结果。
3、训练目标检测模型
我使用 Tensorflow 对象检测 API 来训练模型。 我从 Tensorflow 模型库导入了预先训练的模型,然后根据我的数据对它们进行微调。 我选择使用mobilenet,因为它是一个相对较快的模型,可以让我在短时间内获得不错的结果。
拍照时,我每张照片都会将物体移动到不同的位置,并从多个角度进行拍摄。 我还拍摄了一些物体要么部分被遮挡,要么不完全在画面中的照片。 所有照片都是用同一部手机以相同的质量拍摄的。
我使用 LabelImg 手动标记图片,然后将它们划分为训练集 (80%)、验证集 (10%) 和测试集 (10%)。 验证集用于选择模型超参数和用于最终评估的测试集。 测试集的照片与训练集的照片是在不同的房间拍摄的; 验证集相同。
我确保每个班级在所有分区中都有平等的代表。 我将合成图像添加到训练集中; 验证和测试集仅包含真实世界的图片。
为了衡量模型的性能,我使用了联合得分 0.5 交集处的平均精度 (mAP) 和 10 个预测的平均召回率 (AR)(当在前 10 个预测中检测到对象时为真阳性)。
mAP 擅长衡量检测的准确度。 AR 衡量模型发现所有积极因素的能力。
4、测试训练好的模型
我仅使用真实世界图片、合成图像或两者的混合来训练模型。 通过比较结果,我展示了添加合成图像的好处以及训练图像中最佳的真实世界/合成分割。 对真实世界和合成图像使用相同的采样方案来训练混合模型。 通过不同的采样方案,您可能可以制作出更好的模型。 然而,为了简单起见,我使用了相同的采样。
训练这些模型的另一种方法是首先仅在合成数据上训练它们,然后根据真实数据对其进行微调。 对我来说,这给出了类似但稍差的结果。 然而,这些模型相当简单,我相信这可以改进。
我在上一节中显示的 4 种不同类型的背景模拟上训练了混合模型。 下表总结了这些模拟的 mAP/AR 结果:

模拟1:教程模拟; 模拟2:使用背景图片; 模拟3:使用具有随机对象的背景图像; 模拟 4:为每个对象使用多个网格。 使用 1000 个合成图像和 500 个真实图像训练的模型
5、不同合成/真实分割之间的性能比较
首先,我想看看纯合成数据训练的模型有多好,以及获得不错的结果所需的最少真实世界图片量是多少。 我用 1000/2000/5000/100000 合成图像训练了纯合成模型; 所有的得分都大致相同,约为 0.3 [email protected],这不是很好。 不同模型的一些示例结果可以在本博文末尾的图片中找到。
然后,除了 1000 张合成图像之外,我还使用 0、30、100、300 和 530 张真实世界图片训练模型并比较结果。
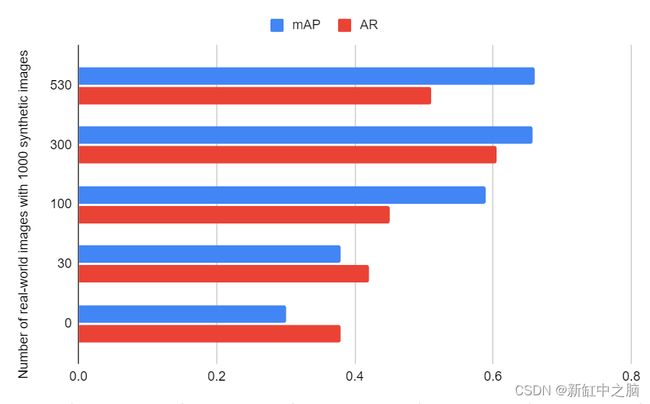
在不同数量的真实世界图像上训练的模型之间的比较
我注意到,随着我向训练集中添加更多真实世界图像,mAP 和 AR 分数会增加,直到添加了 300 个真实世界图像; 最后一个包含 530 张真实世界训练图像的模型中额外的 230 张图像似乎没有多大帮助。 1000 个合成/300 个真实世界图像模型可以检测图像中的大多数物体,主要缺少一些鞋子检测。
到目前为止,我只表明两者的混合比仅合成更好,但没有说明合成数据对我们的模型有何改进。 因此,我仅使用 300 张真实世界图像训练模型。 其表现非常差,甚至比纯合成模型还要差。 在评估这个模型时,我注意到该模型几乎只检测可口可乐罐; 向我展示了虽然 100 张图片足以训练可口可乐罐的对象检测模型,但对于其他 2 个类别来说还不够。 然而,出于测试目的,我继续为每个班级使用大约 100 张图片的相同训练集。
然后,我仅向训练集中添加了 300 个合成图像,并且已经注意到分数增加了一倍多。 然而,当我不断添加更多的合成数据时,模型的表现开始变得更差。 也许对现实世界的数据使用不同的采样方案可以让我向训练集中添加更多的合成图像。

在不同数量的合成图像上训练的模型之间的比较
6、不同类别之间的性能比较
在手动评估模型时,我注意到某些模型检测类别的效果存在重大差异。 因此,我分别对每个类别进行了评估并查看了结果。
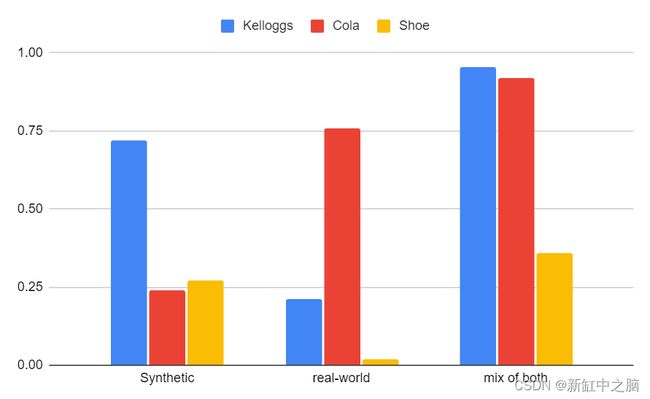
使用 5000 个合成图像、500 个真实世界图像以及 2000 个合成图像和 300 个真实世界图像的混合训练模型; 分别对每个分类进行评估
大多数型号的鞋类得分都很差; 这是我使用的最复杂的对象,也是最不鲜艳的对象,这可能导致其得分较低。 我所说的复杂是指它从各个角度看起来都不同,并且有一些可以在鞋带中移动的细片段。
现实世界的模型非常擅长识别可口可乐罐,但对于其他类别,它们却失败了。 然而,使用合成模型,可乐罐并不那么容易被检测到。 这可能是由于它们的反射特性,在 Unity Perception 中没有很好地模拟。 然而,Unity 中有一些选项可以更好地模拟反射,我没有充分利用这些选项,但肯定可以在这里提供帮助。
家乐氏麦片盒是一个“更简单”的物体,在纯合成数据中得分非常高; 这表明对于这些类型的对象,纯合成数据集本身已经可以提供很好的结果。

在 300 张真实图像上训练的模型检测示例

在 1000 张合成图像上训练的模型检测示例

在 300 张真实图像和 1000 张合成图像上训练的模型检测示例
7、结束语
在这篇文章中,我展示了将合成图像添加到对象检测模型中可以极大地改进你的模型。 我一步步解释了如何做到这一点,从扫描对象到训练对象检测模型。
我表明,最好的结果是通过在真实世界和合成图像的混合上训练的模型获得的,并且如果添加合成数据,可以用很少的真实世界图像获得不错的结果。 我还得出结论,简单的物体(例如家乐氏盒子)可以从添加合成图像中受益匪浅。 从具有薄、透明或反射部分的对象中获取代表性网格变得更加困难; 然而,即使是在这些对象上训练的模型,通过添加合成数据也可以获得更好的结果。
也许对于具有大量定性现实世界图像的模型来说,添加合成数据不会带来改进。 然而,对于很少有定性现实世界图像的模型(例如我的示例),添加合成数据可以极大地提高结果。 总而言之,我对结果感到满意,因为添加合成数据的改进甚至超出了预期。 我希望你觉得这篇文章有用,它会激励你尝试这一点并进一步改进模拟以获得更好的结果!
原文链接:Unity Perception — BimAnt