如何利用Jmeter从0到1做一次完整的压测?这2个步骤很关键!
压测,在很多项目中都有应用,是测试小伙伴必备的一项基本技能,刚好最近接手了一个小游戏的压测任务,一轮压测下来,颇有收获,赶紧记录下来,与大家分享一下,希望大家能少踩坑。
一、压测的时机
压测的时机很重要,如果时间选择不对,可能会做无用功,简单总结下5个常见的压测场景:
1、活动上线前压测
活动类的项目,常规操作是在活动上线前,对系统进行一个摸高压测,根据预估的流量,对系统配置进行优化调整,保证活动期间,系统能正常运行。
本次的小游戏项目,就属于活动类,在上线前进行了压测。
2、项目上线稳定后,对系统评估
系统上线后,随着用户量不断增加,承受的压力会越来越大,为了让系统在未来的时间内稳定运行,需要通过压测对系统进行评估,以调整配置或优化接口,来充分应对不断增长的用户量。
3、项目研发后期,对系统的检验
在项目后期,由于领导或团队的要求,需要对系统的稳定性做校验,保证系统短时间内流量陡增时能稳定运行,可以给系统的部署提供参考。
4、线上出现性能问题
有些项目为了抢占市场,节省时间,完成了基本的功能就上线了,没有做压测,当用户突然增加出现线上性能问题后,反过来做压测,这种情况的风险是很大的,不推荐。
5、合作方要求
有些合作方对性能有明确的要求,并且写进了合同,这种情况下就必须去做压测了。
二、压测过程
可做压测的工具很多,业界用得比较多的是Jmeter,今天我们就以Jmeter为例,分享下做压测的6个步骤:
1、编写压测脚本

1)添加HTTP请求
填写请求方法,路径,请求参数
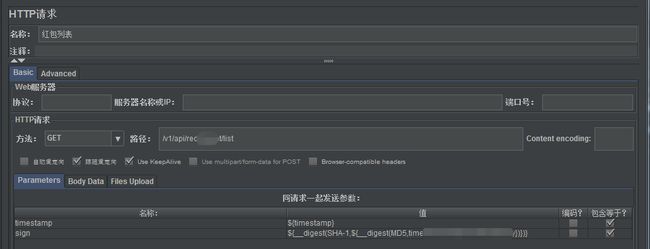
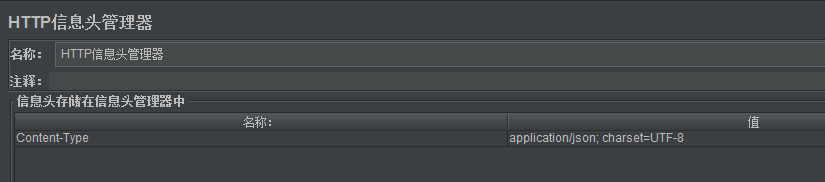
2)添加HTTP信息头管理器
有些请求不需要添加,使用默认值,有些需要添加,与开发同学确认即可,注意请求体为Body Data时,大部分情况下需要添加请求头Content-Type: application/json
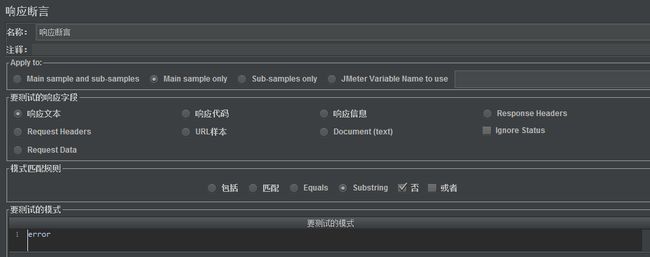
3)添加响应断言
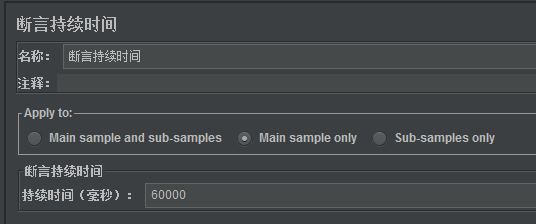
4)添加断言持续时间
根据项目情况确定,一般设置为60s
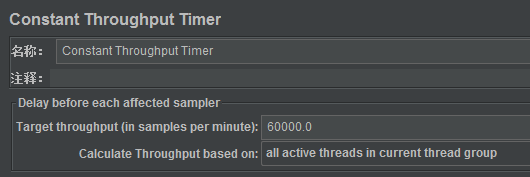
5)评估是否需要限制吞吐率(添加Constant Throughput Timer)
有时候为了模拟真实的使用场景,尽量保证线程组设置的并发数与聚合报告中的吞吐率一致

6)查看结果树
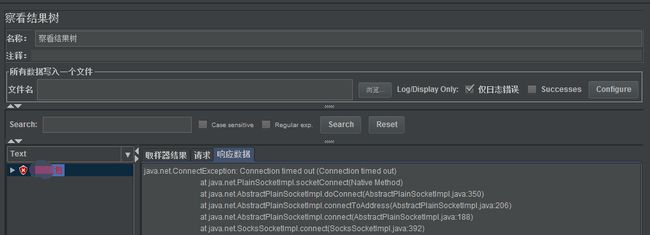
开始压测时勾选仅错误日志,便于查看报错信息,调试时需要查看所有日志,保证接口脚本能正常调通
7)聚合报告

2、准备压测服务器(测试服务器/线上服务器)
有些项目需要在测试服务器上进行,而有些则直接在线上服务器进行,例如还未上线的活动类项目,就可直接在线上压测,不同的服务器配置,压出来的结果是不同的。
3、开始压测
提前与开发和产品同学确认并发量,如果项目有明确的用户数,比如500用户,那就直接用500并发或者稍稍高于500的并发,如果项目没有明确的并发,可根据当前项目情况酌情施压。
在压测过程中,注意观察服务器资源消耗情况,例如cpu,内存,磁盘,网络等以及服务器Nginx的日志。
观察服务器的压力,如果在测试环境,可以在服务器上装个nmon工具,可实时查看服务器的资源消耗情况,如果是线上环境,一般不能直接远程服务器,可以找运维同学要链接,比如这次运维同学直接给了夜莺(Nightingale)的链接地址,登录可直接查看服务器的资源消耗情况。
查看服务器的Nginx,主要是看是否有报错信息以及请求是否打到了测试服务器上。
4、记录结果
主要包括服务器配置,压测场景、Jmeter聚合报告以及接口报错情况,服务器资源监控等。
1)服务器配置
测试环境机器配置:单台机器,配置为6核6G内存
线上环境机器配置:两台Web应用程序服务器负载均衡,一台数据库服务器,每台配置为6核6G内存
2)压测场景
打开红包+猜测红包大小+获取红包状态接口(写上接口的URI)
/v1/api/red
3)聚合报告
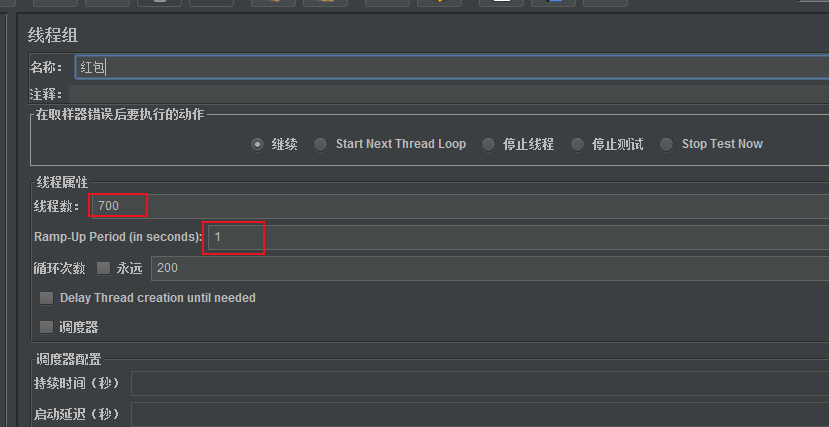
1s起1000个线程数,循环次数500次,压测时间:2023/01/17 15:00~15:05(记录压测时间是为了在夜莺(Nightingale)上查看时间段内的资源消耗情况图)

主要关注平均响应时间Average,Error%,Throughput
4)测试结果
查看结果树,将报错的类型全部列举出来,例如存在连接超时的报错:Connection timed out

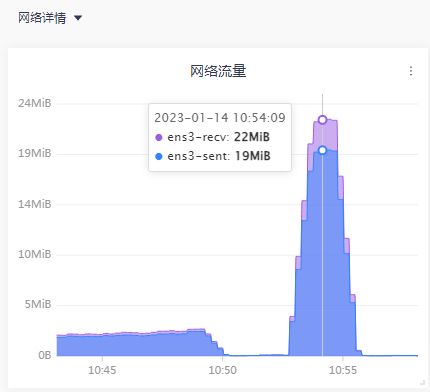
5)资源监控
关注CPU使用率,内存使用率,网络流量

5、提性能Bug和验证Bug
如果有的接口有性能Bug,提Bug给开发,开发修复后,再次压测,进行回归测试,验证Bug已修复。
6、发送压测报告
将步骤4的结果进行简单的文字分析总结,发送压测报告
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
