性能测试1
一、学习前的认知
我们在学习性能测试之前,需要有个新的认识:性能测试,不再是像功能测试一样单纯的找 Bug,而是去找性能指标
1.转变思维
- 在做功能测试、自动化测试的时候,我们基本都是依托界面进行测试,也称 GUI 测试,我们的目的就是为了跑通功能、程序,并成功找到 Bug
- 但在做性能测试的时候,我们大部分是 headless 模式(所谓的:无头,无界面模式),目的不再是单纯的为了找到 Bug,而是要分析性能指标等等(后续讲到)
2.性能测试的时间一般会比自动化、功能测试长,为啥?
- 因为性能测试的步骤跟自动化、功能测试的步骤不一样,比如说前期的准备(了解系统,环境搭建),后期的压力测试(7*24h)等等
- 在后面,我们通过讲述性能测试步骤来仔细了解
3.性能测试一定要工具,手工不行吗?
- 性能测试是模拟系统在被很多很多用户同时使用时,系统能不能正常使用和提供服务
- 重点: 很多很多用户
- 功能测试: 一个人点点点就知道功能通不通,有没有 Bug 了
- 性能测试: 用手工的话,可以模拟几个、十几个用户,但是当需要模拟上千万个用户时,手工又怎么模拟数据量多的场景呢?
- 类比,吃饭场景: 一个人可以吃好几碗,但是叫你吃几百碗是不可能的
- 结论: 工具就可以模拟大数据量的场景,可以做到人做不到的事情
4.大数据量测试是性能测试吗?
大数据量测试
简单理解:一个接口返回的数据比较多(假设:不使用分页,把所有数据同时返回)
结论
- 返回大数据量的接口的响应时间会变长
- 这么大的数据量,我们需要考虑:网络传输数据、服务器查询这些数据、服务器处理这些数据等等分别需要多少时间
- 这已经跟响应时间挂钩,所以已经属于性能测试的范围,但不归纳于性能分析范围
5.大数据测试是性能测试吗?
大数据测试的功能属于功能测试哦
6.性能测试过程发现问题需要立即提交吗?
在性能测试过程中发现一些问题,假设定位到某一段代码有问题,可以截图提交 Bug 给开发,但这并不是我们性能测试的最终目的,最终目的是找出性能指标
有哪些性能指标?
- 比如说响应时间:10个人、100个人 、1000个人 、10000个人向服务器发起请求,服务器响应请求的平均响应时间是多少,这就是一个指标
- 又好比TPS:服务器在当前的配置下,不同用户数发起请求,服务器的 TPS 处理能力是多少,这也是一个指标
- 后续详细介绍
性能测试中发现的 Bug
- 性能测试过程中发现的 Bug 属于一个衍生品,并不是最终得到的结果
- 但像功能测试,最终目的就是为了找出 Bug
关于这个问题的总结
- 做性能测试,当数据量变大后,会出现连接超时、连接拒绝、500、502等异常问题;在性能测试中,这些异常问题基本都会出现的,但不会去立即提 Bug
- 对于性能测试工程师,我们要做的是分析为什么在当前数据量下会出现连接超时、连接拒绝,响应时间超时、服务器异常等异常问题
- 这就需要我们去分析性能瓶颈,并不会单独去看某个异常问题出现在哪里,而是分析为什么会出现这个异常问题,分析的是服务器或者是代码,而不是让开发人员马上来修复这些异常问题
7.我们常说的压测是指压力测试吗?
- 并不是,而是指负载测试,一般都是为了找出系统的最大负载量
- 就好像你老板说:你去压测下,看看系统能支撑多少用户同时访问我们的系统
二、性能测试
1.什么是性能测试
狭义理解
- 通过工具,找出或获得系统在不同工况下的性能指标值
- 性能测试过程中,重点是找出 性能指标,而不再是找出 Bug,
- 性能测试的产出绝对不只是 Bug
什么时候能找出性能指标值
假设当前有一个业务
电商系统,下单业务,目前还不知道系统支持多少人同时下单,那么我们需要找到服务器能正常支持多少人同时下单
性能测试初始阶段(第一次做)
- 先把基础的性能指标值找出来 (第一次性能测试也叫做基准测试)
- 比如:100个人同时下单系统正常,但120个人同时下单就会出现部分请求的响应时间超长,连接异常
- 那么100-120范围内的某个值就是当前服务器能达到的性能指标值 (基准值)
版本迭代,进行第二次做性能测试,重新跑一遍之前的性能脚本
- 又会得到一些性能指标值,对比上个版本的性能指标值,看是否有优化(性能变化)
- 假设这个时候120个人同时下单是正常的,150个人才有异常,那么接口已经有优化了
假设公司是从0开始做性能测试
- 第一阶段:做好性能测试,得到性能指标值
- 第二阶段:假设性能比之前差,哪些性能指标值不满足预期值,就需要分析是哪里有问题
广义理解
- 只要与服务器性能指标相关的测试都属于性能测试
- 比如:响应时间、并发用户数、服务器处理能力、吞吐量等性能指标
- 负载测试、压力测试、容量测试、可靠性测试都属于性能测试
- 通常嘴巴上说的做性能测试就是广义的性能测试,它包括了很多内容,并不只是针对某一个测试类型
“官方”解释
以下含义来源高老的解释,比较“官方”的术语
- 性能测试针对系统的性能指标,建立性能测试模型
- 制定性能测试方案
- 制定监控策略
- 在场景条件下执行性能场景
- 分析判断性能瓶颈并调优
- 最终得出性能结果来评估系统的性能指标是否满足既定值
其实也算是一个简洁描述的性测试流程了
注意
- 性能测试不像自动化测试那样很多东西大家都是公认的,性能测试没有一套标准的知识体系,只能说是相似的
- 基本每个人都有自己的一套知识体系,就好像高老也会说他给性能测试的定义很大可能会被轰炸一样
- 只要属于自己的知识体系建立起来了,那么就能助力你正确的完成性能测试
- 不用太过纠结于哪个人对性能测试概念的解释是最准确的
2. 哪些网站需要做性能测试?
B/S架构:浏览器与服务器
C/S架构:客户端与服务器
- 无论B/S架构、还是C/S架构只有访问量比较大的都需要进行性能测试、比如电商网站、售票网站、网游、金融类、互联网 的产品。
- B/S、C/S架构都是服务器后端的测试
3. 性能测试目的
性能测试与功能测试有所不同,性能测试更加关注系统的性能表现。而性能测试就是排除系统瓶颈,使系统更加健壮。可以从以下几个方面理解:
1)评估当前系统。系统未做过任何性能测试,对系统的当前性能情况不了解,缺少必要的的性能评估。
2)寻找瓶颈,优化性能。 常见的现象为,某业务操作响应时间很长、某系统上线一段时间后运行越来越慢,这些都需要分析定位并调优。
3)预测未来性能。当用户数和业务量增加时能否及时应对?如何调整?是增加应用服务器,还是数据库服务器?还是要优化代码逻辑?这一系列问题都值得思考,这也是性能测试目的所在。
4. 性能测试指标
响应时间
响应时间越短,用户体验越好
吞吐量
-
单位时间内,网络处理的请求数量(事务/s)
-
网络没有瓶颈时,吞吐量≈TPS
-
TPS:每秒钟事务数。举例:例如每秒钟能完成200次注册操作,TPS的值越大越好
资源利用率
CPU、内存、磁盘、网络(磁盘速度最慢)

5. 如何实施性能测试
- 采用工具模拟大量的用户访问网站,达到性能测试的目的
- 工具采用线程模拟人,线程执行的是业务接口(多线程访问接口)
三、测试分类
故事引入
有一个农夫决定买一匹骡子,他认为这个骡子至少 得能扛动3袋大米,他才会决定买这匹骡子(这相当于用户提出的性能需求)。结果他来到农贸集市上,试了好几头骡子,都不合适,最后终于有一头骡子能够比较轻松的扛动这3袋大米,而且还潇洒的走了几步(这相当于于性能测试通过)。 然后农夫高高兴兴地牵着这头骡子回家,而且给它扛了4袋大米(相当于让系统超负荷运行),因为他跑了太远才买到了这匹不可多得的骡子,他想看看它到底能有多强,所以农夫决定, 让这匹骡子就扛着这四袋大米走回家试试看,这匹骡子真的很厉害,刚开始的时候还一颠一跑的,可是后来实在路太远了,骡子越驮越费劲(在超负荷情况下检验系 统能正常运行多久,这相当于压力测试),快到家的时候,已经是走两步歇一步了。终于到家了, 农夫非常自豪地叫出自己的老婆,说:“老婆子,快来看看,看我买到了一头多么厉害的骡子啊!”,老婆出来后,农夫把他和骡子在一路上的经历都告诉了老太 婆,谁知这个老太婆却说:“你真蠢,这么大老远的路,也不让骡子驮着你,竟然和这头傻骡子一样走回来!”,农夫听了,觉得非常后悔,说:“那好吧,既然在 路上它没有驮我,那就让它现在补上,也算是对我的补偿。”,骡子还没有反应过来,就看那老农夫一个箭步,跳到了骡子背上(这相当于容量测试的极限点),可怜的骡子,无论如何也不会想到,这狠心的农夫竟然在它走了这么久之后,不但没有帮 它卸掉身上的重担,更没有给它喝口水,竟然变本加厉的跳到了它那本已弯曲的背上。可怜的骡子啊,就这么一命呜乎了!就看见那个骡子、农夫和4袋麦子一起轰然倒地。(相当于已经到了系统的最大拐点,造成了系统瘫痪,无法使用,容量测试结束)。
性能测试(Performance Test):通常收集所有和测试有关的所有性能,通常被不同人在不同场合下进行使用。测试软件在系统中的运行性能,度量系统与预定义目标的差距。
关注点:how much和how fast
负载测试(Load Test):负载测试是一种性能测试,指数据在超负荷环境中运行,程序是否能够承担。通过逐步增加系统负载,确定在满足性能指标的情况下,系统所能承受的最大负载量。
关注点:how much
压力测试(Stress Test):压力测试是一种高负载下的负载测试,也就是说被系统处于一个负载的情况,再继续对他进行加压,形成双重负载,知道系统崩溃,并关注崩溃后系统的恢复能力,以前再加压的一个过程,看看系统到底是否已经被彻底破坏掉了。
有个很形象的说法就是:你能够承担100千克的重量,而且也能走,但是你能否承担100千克的重量行走1个月。
我觉得有一句话描述的很好:外部的负载叫压力,内部的压力叫负载。负载注重关注内部的以及系统自身一些情况;而压力更关注系统外部的表象.
1. 基准测试
- 性能测试中第一次测试,使用单线程执行测试,来看一下系统的反应
- 基准测试需要进行多次,每一次在执行的过程里可以更换服务器的硬件
- 做基准测试只是为了预估,如果1个线程CPU100%了,就没必要测试了
2. 负载测试
概念
-
通过逐步增加系统负载,确定在满足性能指标的情况下,系统所能承受的最大负载量。
-
为了寻找最佳用户数,最大用户数
最佳用户数:只要CPU、内存、硬盘某一项达到80%那么就是最佳用户数
最大用户数:系统崩溃之前的的用户数。比如1000个用户CPU达到100%,这时系统还能正常运行,但是一旦多家1个用户这个时候系统就会崩溃,那么1000就是最大用户数。
如何增加负载
通过增加“用户数”,就是常说的并发数
场景类比
天平秤,称东西的时候,需要逐步加砝码,最终达到砝码和物品重量的平衡点,因为它不可能一下子就达到平衡点【好比不可能一下子找到系统能承受的最大负载量】
- 称东西:业务场景
- 加砝码:逐步加压
- 达到平衡点:找到最大负载量
实际场景
- 有一个业务,增加到40个人的时候,服务器还能正常使用,没有异常
- 当你增加到50个人的时候,服务器已经开始有异常了,那么就能确定40-50之间某个值就是系统所能承受的最大负载量 【出现性能拐点,找到了服务器性能瓶颈的范围值】
- 最后减小加压梯度(比如:从40个人开始每次增加1个人、2个人),确认最大负载量 【确认性能拐点】
服务器又有哪些可能会出现的异常呢
- 响应时间超长: 正常服务器处理请求时间是 1s,但现在变成3s - 5s
- 服务报错: 无法同时正常响应多个请求
- 服务器宕机: 系统完全用不了
3. 压力测试
概念
-
往往是在负载测试的基础上进行的,是一种高负载下的负载测试(过载)。说白了就是系统已经处于负载下,再对它进行加压,形成双重负载,直到系统崩溃。
-
向服务器发送大量的请求,并且长时间运行,用于测试服务器在高负载情况下的稳定。
高负载:保持最大用户数
-
压力测试就是求当前系统的极限值
压力测试持续运行时间要多久?
- 标准性能测试里面,一般是7*24小时,或者是它的倍数
- 但是实际工作中,并不会这么久,一般2*24或3*24小时。
- 项目要是紧急的话最低也不能低于8小时。
场景类比
问: 大家什么时候会觉得工作压力大?
答: 996、007;因为你不会觉得955压力山大吧
结论: 所以在我们日常工作中,长时间工作强度高,才会觉得压力大;如果你一周就加班一天也说压力大…(那就别干这一行了)
压力测试用来干嘛的
测试系统的稳定性
什么时候会做压力测试
- 生产环境下,系统隔三差五的出现不稳定的情况
- 这个时候,就需要通过压力测试去测试系统的稳定性情况
啥情况算不稳定?稳定性差?
隔三差五的出现下面的情况
- 服务异常:响应错误、响应时间超时等
- 服务器出现异常:宕机
怎么分析是服务异常还是服务器异常
- 如果所有请求都是一片红,应用程序发送的所有请求都报红,就是服务器出现了异常
- 如果有些请求偶尔成功响应,偶尔又失败,则是服务异常,出现不稳定的情况
如何取压力值
- 在负载测试中,我们确认了系统所能承受的最大负载量
- 压力值 < 最大负载量,一般取80%左右
总结
压力测试长时间运行,可能会逐渐增加系统的内存占用空间,若得不到有效的内存回收,当达到内存最大值时,系统就会崩掉
先负载测试还是压力测试?
- 先负载测试
- 负载测试可以找到服务器性能瓶颈的范围值,若生产环境中系统稳定性较差,再做压力测试
- 所以 压力测试是可做可不做的
4. 并发测试
- 并发测试是指通过模拟多个用户并发访问同一个应用、存储过程或数据记录及其他并发操作,测试是否存在死锁、数据错误等故障。为了避免数据库或者函数方法在并发下的错误,需要专门针对每个模块进行并发测试。
- 没有绝对的并发,不可能同一时间
- 如果项目有抢购、秒杀可以做
5.可靠性测试
概念
- 在给定的一定的业务压力下,持续运行一段时间,查看系统是否稳定
- 关键字: 是否稳定,一定业务压力
- 注意: 不是较大压力哦
业务场景栗子
电商秒杀场景,几十个商品几十万个人同时秒杀抢购
如何理解可靠性测试
- 编写性能脚本:假设一秒内有一万个人同时发起请求
- 有压力吗?有,一万个人同时发起请求
- 但是持续时间短,不像压力测试一样需要持续一段时间
- 目的是为了验证当这么多人同时发起请求时,成功秒杀的用户能否继续完成后续下单付款等操作 【一定业务压力下,系统是否稳定运行】
6.容量测试
概念
- 在一定的软、硬件条件下,在数据库不同数据量级数据量的情况下,对系统中 读/写比较多的业务 进行测试,从而获得不同数据量级下的性能指标值
- 关键字: 不同数据量级
数据库数据量对性能测试结果有没有影响?
肯定有
- 比如数据库已经有几百条数据和几百万条数据,查询的速度肯定不一样,所以肯定会影响性能测试结果
- 数据量级的差异,会影响TPS、响应时间、网络等
场景类比
从一袋米中找一个绿豆,和一碗米中找一个绿豆,找的时间肯定是千差万别的
7.稳定性测试
基于负载测试的性能指标,通过长时间运行。一般是48-72小时。
有些企业把稳定性测试也叫压力测试。
8.实际测试顺序
基准测试-----负载测试-----压力测试
四、测试指标
1. 响应时间
定义及解释
-
响应时间
从发起请求到收到请求响应的时间整个过程所耗费的时间。越快越好,响应时间越短,用户体验越好
等价于: 发起请求网络传输时间 + 服务器处理时间 + 数据库系统处理时间 + 返回响应网络传输时间
操作浏览器发送请求: 点击前端页面-->后端接口-->通过网络发送给服务器-->在数据库里面查询获取需要的内容-->返回给后端接口-->后端接口再给前端-->前端页面负责展示 这些一系列过程加起来的时间才是响应时间,网络情况也会影响响应时间 -
平均响应时间
指系统稳定运行时间段内,同一交易的平均响应时间。一般而言,交易响应时间指的就是平均响应时间。
参考标准
不同行业不同业务可接受的响应时间是不同的,一般情况,对于在线实时交易:
- 互联网企业:500毫秒以下,例如淘宝业务10毫秒左右。
- 金融企业:1秒以下为佳,部分复杂业务3秒以下。
- 保险企业:3秒以下为佳。
- 制造业:5秒以下为佳。
对于批量交易:
- 时间窗口:即整个压测过程的时间,不同数据量则时间不一样,例如双11和99大促,数据量级不
一样则时间窗口不同。大数据量的情况下,2小时内可完成压测。
衡量响应时间的指标
-
HPS:每秒钟点击数。
-
TPS:每秒钟事务数。每秒钟处理的业务越多越好。例如每秒钟能完成200次注册操作,TPS的值越大越好
-
QPS:每秒钟查询数。
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么TPS=QPS=HPS,一般情况下用TPS来衡量整个业务流程,用QPS来衡量接口查询次数,用HPS来表示对服务器单击请求。
2.HPS
- 每秒点击数
- 可直接理解为用户在界面上的点击次数
- 一般在性能测试中,都用来描述 HTTP Request,那它代表每秒发送 HTTP 请求的数量,和 RPS 概念完全一样
- HPS 越大对 Server 的压力越大
3.TPS
-
每秒钟事务数。每秒钟处理的业务越多越好。例如每秒钟能完成200次注册操作,TPS的值越大越好
-
衡量服务器处理能力的最主要指标
4.QPS
- 每秒钟查询数。在数据库中每秒执行 SQL 数量。比如百度搜索就是查询,搜索某个人名,把这个人名的相关信息查询出来
- 一个请求可能会执行多条 SQL
- 某些企业可能会用QPS代替TPS
- 也是衡量服务端处理能力的一个指标,但不建议使用
5.RPS
- 每秒请求数,用户从客户端发起的请求数

如果一个用户点击了一次,发出来 3 个 HTTP Request,调用了 2 次订单服务,调用了 2 次库存服务,调用了 1 次积分服务
**问:**Request 数量如何计算
**答:**3+2+2+1 = 8?不, 应该是 3,因为发出了 3 个 Request,而调用服务会有单独的描述,以便做性能统计
6.CPS/CPM
- 每秒/每分钟调用次数
- 通常用来描述 Service 层的单位时间内被其他服务调用的次数
上图的订单服务、库存服务、积分服务,各调用了2、2、1次,还是比较好理解的
标准
无论TPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好,根据经验,一般情况下:
- 金融行业:1000TPS~50000TPS,不包括互联网化的活动
- 保险行业:100TPS~100000TPS,不包括互联网化的活动
- 制造行业:10TPS~5000TPS
- 互联网电子商务:10000TPS~1000000TPS
- 互联网中型网站:1000TPS~50000TPS
- 互联网小型网站:500TPS~10000TPS
7. 吞吐量
- 吞吐量反映的就是业务的处理能力,越大越好
- 单位时间内,网络处理的请求数量(事务/s)
- 网络没有瓶颈时,吞吐量≈TPS
8.吞吐率
单位时间内,在网络传输的数据量的平均速率(kB/s)
9.资源利用率
CPU
-
定义及解释
中央处理器是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。 CPU Load: 系统正在干活的多少的度量,队列长度。系统平均负载。
-
简称
Central Processing Unit:CPU
-
标准
CPU指标主要指的CPU使用率利用率,包括用户态(user)、系统态(sys)、等待态(wait)、空闲态(idle)。CPU 利用率要低于业界警戒值范围之内,即小于或者等于75%;CPU sys%小于或者等于30%, CPU wait%小于或者等于5%。单核CPU也需遵循上述指标要求。CPU Load要小于CPU 核数。
Memory(内存)
-
定义及解释
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。内存使用率不能超过80%
-
简称
Memory就是内存的简称。
-
标准
现代的操作系统为了最大利用内存,在内存中存放了缓存,因此内存利用率100%并不代表内存有瓶颈,衡量系统内有瓶颈主要靠SWAP(与虚拟内存交换)交换空间利用率,一般情况下,SWAP交换空间利用率要低于70%,太多的交换将会引起系统性能低下。
-
SWAP
内存中swap交换区间的使用完成意味着,物理内存耗尽,一般要避免这种情况,物理内存使用不要超过80%
SWAP分区:我们在安装系统的时候已经建立了 swap 分区。swap 分区通常被称为交换分区,这是一块特殊的硬盘空间,即当实际内存不够用的时候,操作系统会从内存中取出一部分暂时不用的数据,放在交换分区中,从而为当前运行的程序腾出足够的内存空间。
也就是说,当内存不够用时,我们使用 swap 分区来临时顶替。这种“拆东墙,补西墙”的方式应用于几乎所有的操作系统中。
计算机用户会经常遇这种现象。例如,在使用Windows系统时,可以同时运行多个程序,当你切换到一个很长时间没有理会的程序时,会听到硬盘“哒哒”直响。这是因为这个程序的内存被那些频繁运行的程序给“偷走”了,放到了Swap区中。因此,一旦此程序被放置到前端,它就会从Swap区取回自己的数据,将其放进内存,然后接着运行。
磁盘吞吐量
-
定义及解释
磁盘吞吐量是指在无磁盘故障的情况下单位时间内通过磁盘的数据量。
-
简称
Disk Throughput。
-
标准
磁盘指标主要有每秒读写多少兆,磁盘繁忙率,磁盘队列数,平均服务时间,平均等待时间,空间利用率。其中磁盘繁忙率是直接反映磁盘是否有瓶颈的重要依据,一般情况下,磁盘繁忙率要低于70%。不要频繁读取磁盘
网络吞吐量
-
定义及解释
网络吞吐量是指在无网络故障的情况下单位时间内通过的网络的数据数量。单位为Byte/s。网络吞吐量指标用于衡量系统对于网络设备或链路传输能力的需求。当网络吞吐量指标接近网络设备或链路最大传输能力时,则需要考虑升级网络设备。
-
简称
Network Throughput
-
标准
网络吞吐量指标主要有每秒有多少兆流量进出,一般情况下不能超过设备或链路最大传输能力的70%。性能测试中最好不要测上传和下载功能
10.并发、并发用户数
1.并发
狭义
指同一个时间点执行相同的操作(如:秒杀)
广义
- 同一时间点,向服务器发起的请求(可能是不同的请求)
- 只要向服务器发起请求,那么服务器在这一时间点内都会收到请求(不管是不是同一个请求)
场景类比
高速公路上,同时有多少辆车经过同一个关卡,但不一定是同一个牌子的汽车
2.并发用户数
- 同一时间点,发出请求的用户数,一个用户可以发出多个请求
- 场景不一定是同一个
- 和 CPU、响应时间有关系
和并发的关系
假设有 10 个用户数,每个用户同一时间点内发起 2 个请求,那么服务器收到的请求并发数就是 20
性能测试小场景一
- 不同身份的用户,访问不同的页面或发起不同的请求(广义的并发)
- 观察 CPU 使用率和响应时间
性能测试小场景二
- 所有用户,同一个时间点发送同一个请求(狭义的并发)
- 观察 CPU 使用率和响应时间
3.系统用户数(注册用户数)
- 系统累计注册用户数,不一定在线
- 注册之后也可以一直不在线
- 因为用户信息是存在数据库的,而数据库数据就是存在磁盘中,所以系统用户数和磁盘空间有关系
性能测试小场景
- 写一个脚本添加很多条用户信息插入到数据库
- 目的:测试系统容量,方便了解系统的最大容量
- 实际项目中,当系统容量接近最大容量时,系统需要进行容量扩容(加磁盘空间),否则就会爆掉
4.在线用户数
- 在线用户可能是正常发起请求,也可能只是挂机啥操作都没有,不一定同时做某一件事情
- 在线用户可能是游客(未注册的用户),也可能是系统用户(已注册的用户)
- 在线用户数≠并发用户数
- 和内存有关系
性能测试小场景
- 使用 Jmeter 让不同的用户不断上线,且不下线和发起其他请求,看看内存使用情况
- 实际场景: 12306 以前很多用户在线,响应时间会拉的很长
11.Think Time 思考时间
从业务角度看
- 它指的是用户进行操作时,每个请求之间的时间间隔
- 比如: 加入购物车后,多久之后会点击下单?浏览一个商品多久会加入购物车
从性能测试角度看
- 为了模拟用户两次操作之间的时间间隔,才有 Think Time,更加真实的模拟用户的真实操作
- 它和用户行为有关系,所以应该分析的是用户行为而非用户数
五、Jmeter5.3
1. 手动编写脚本


2. 录制脚本
1.Badboy工具录制
-
Badboy是里面内置了一款IE浏览器,通过人为操作内置的这个浏览器,工具会帮助我们自动生成脚本
-
Badboy内置的IE浏览器不兼容,如果项目兼容了IE那么可以用此工具
-
下载地址
http://www.badboy.com.au/ -
教程地址
https://www.cnblogs.com/auguse/articles/13881806.html


2.Jmeter录制
-
jmeter自带的非测试元件中HTTP代理服务器录制
jmeter会启动一个监听端口,默认是8888
新建测试计划

创建HTTP代理服务器
测试计划----->添加----->非测试元件----->HTTP代理服务器
jmeter会启动一个监听端口默认8888,可以修改,建议修改10000以上端口号


浏览器代理设置
Edge、Firefox、Chrome使用插件SwitchyOmega创建一个情景模式

创建线程组
测试计划----->添加----->线程----->线程组

创建录制控制器
添加录制控制器:线程组----->逻辑控制器------->录制控制器

设置目标控制器


点击上面的启动按钮
如果报下面异常,需要更改端口号,SwitchyOmega也需要更改。建议10000以上

3. 脚本开发
1.关于线程组
- 创建线程组

-
参数解释
名称:可以给线程组设置一个个性化的命名 注释:可以对线程组添加备注以标记 在取样器错误后要执行的动作:就是在错误之后要如何执行,可选继续执行后续的、停止执行等。 线程数:就是需要设置多少线程执行测试。 Ramp-up Period (in Seconds):用于告知JMeter 要在多长时间内建立全部的线程。多长时间内需要把上面的线程数均匀启动完。 默认值是0。如果未指定ramp-up period ,也就是说ramp-up period 为零, JMeter 将立即建立所有线程。假设ramp-up period 设置成T 秒, 全部线程数设置成N个, JMeter 将每隔T/N秒建立一个线程。 循环次数:就是决定一个线程要跑多少次测试。 Delay Thread creation until needed:直到需要时延迟线程的创建 调度器:选中之后可以配置启动时间,立即或者预定的时间名称:可以给线程组设置一个个性化的命名 注释:可以对线程组添加备注以标记 在取样器错误后要执行的动作:就是在错误之后要如何执行,可选继续执行后续的、停止执行等。 线程数:就是需要设置多少线程执行测试。 Ramp-up Period (in Seconds):用于告知JMeter 要在多长时间内建立全部的线程。多长时间内需要把上面的线程数均匀启动完。 默认值是0。如果未指定ramp-up period ,也就是说ramp-up period 为零, JMeter 将立即建立所有线程。假设ramp-up period 设置成T 秒, 全部线程数设置成N个, JMeter 将每隔T/N秒建立一个线程。 循环次数:就是决定一个线程要跑多少次测试。 Delay Thread creation until needed:直到需要时延迟线程的创建 调度器:选中之后可以配置启动时间,立即或者预定的时间
2.HTTP请求默认值
线程组----->添加----->配置元件----->HTTP请求默认值
- 请求默认值填写了协议、IP地址、端口后其他请求就不用在设置了,共用这一个默认值
- 放在哪个线程组下面,当前线程组下面的请求就会使用 http请求默认值 里面的内容


3.HTTP信息头管理器
-
创建信息头管理器
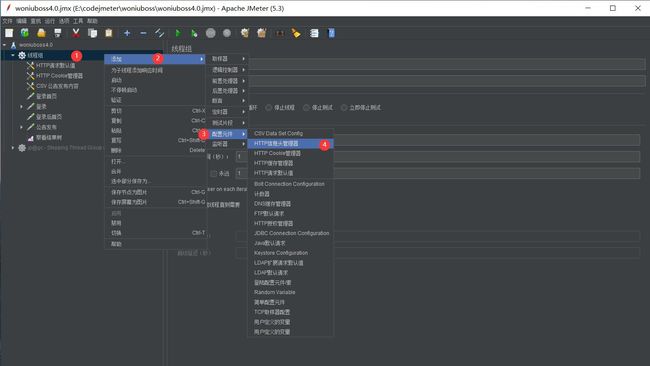
-
填写参数
请求中遇见特殊请求应该使用信息头管理器,请求时携带者。比如:X-Requested-With、User-Agent

4.关联
教程:https://www.cnblogs.com/auguse/articles/13908104.html
- 关联其实就是将接口请求维持会话的值,取出来设置让后续请求都携带着,大部分情况下是指:sessionid或者token
- 由于http协议是无状态的,为了解决就有了session和token,后续每次请求都需要携带session或token的值
正则表达式提取
-
创建正则表达式提取器

-
提取sessionid
1.引用名称 自己定义的变量名称,后续请求将要引用到的变量名,如填写的是:user_id,后面的引用方式是${user_id} 2.正则表达式 提取内容的正则表达式,相当于lr中的关联函数 3.模板 如果一条正则表达式有多个提取结果,则提取结果是数组形式 模板 $1$、$2$.....表示把解析到的第几个值赋给变量,从 1 开始匹配 $0$ 表示整个表达式匹配的内容(后续具体看栗子) 若只有一个结果,只能是$1$ 4.匹配数字 0:随机,默认 -1:所有的值 1:第一个值。 如果使用-1的话,还可以通过${user_id_1}的方式来取第1个匹配的内容,${user_id_2}来取第2个匹配的内容。 5.缺省值 缺省值,匹配不到值的时候取该值将正则表达式的结果存储在变量名sid

-
创建cookie管理器,添加sessionid
后续请求携带,使用HTTP cookie管理器实现,注意使用变量的值的形式: ${sid}


5.参数化
教程:https://www.cnblogs.com/auguse/articles/13904546.html
业务中脚本中有登录操作,需要输入用户名和密码,假如系统不允许相同的用户名和密码同时登录,或者想更好的模拟多个用户来登录系统。这个时候就需要对用户名和密码进行参数化,使每个虚拟用户都使用不同的用户名和密码进行访问。
方式一:csv data et config(txt)
- 文本编码格式要求utf-8
- 测试数据

-
创建csv

-
csv data设置

-
替换参数

-
创建调试取样器
仅仅用于调试,真实场景要和察看结果树禁用掉
添加调试取样器后在察看结果树中能看到我们在脚本中所有参数化变量所取的值,这样有利于我们排错

方式二:函数助手CSV Read(尽量少用,很容易出现编码问题)
测试数据:不能有表头,比如username,password

txt编码格式需要另存为ANSI格式。

创建函数助手
点击生成后,会自动复制,在参数化时直接复制即可

-
CSV file to get values from | *alias:这里需要填入txt或者csv文件的绝对路径,我这里用txt作为保存数据
-
CSV文件列号| next| *alias:表示当前变量读取第几列数据,第一列是0。
-
填完之后,就点击生成。这里就会生成函数字符串了,先复制这段字符串
参数化
将我们写好的函数复制到“登录”页面用户名和密码的位置。

如果txt不转换编码生成后下面不出现内容,理应出现第1列内容


可以使用${__Random}随机读取数据

- 第一个参数表示读取的最小值,第二个参数表示读取的最大值,第三个参数是用户自定义的,留空
6.思考时间
教程:https://www.cnblogs.com/auguse/articles/13908271.html
-
思考时间(Think Time)也称为“休眠时间”,是指用户在进行操作时,每个请求之间的时间间隔。对于交互系统来说,用户不可能持续不断地发出请求,一般情况下,用户在向服务端发送一个请求后,会等待一段时间再发送下一个请求。性能测试过程中,为了模拟这个过程而引入思考时间的概念。在测试脚本中,思考时间为脚本中两条请求语句之间的间隔时间。当前对于不同的性能测试工具提供了不同的函数来实现思考时间。
-
调试脚本别用,影响效率,真实场景下可以用
1秒=1000毫秒
固定定时器
1.创建定时器
需要让每个线程在请求之前按相同的指定时间停顿,就可以使用这个定时器;需要注意的是,固定定时器的延时不会计入单个sampler的响应时间,但会计入事务控制器的时间
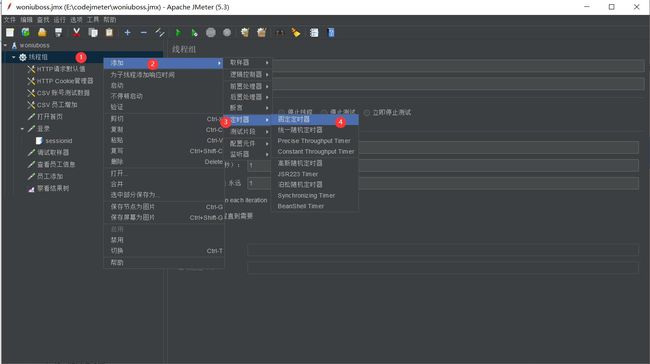
2.设置间隔时间

3.定时器作用域

统一随机定时器
1.创建定时器
该计时器将每个线程请求暂停一个随机的时间量,每个时间间隔的发生概率相同。总的延时 = 随机延时 + 偏移延时值。
Random Delay Maximum(in milliseconds):随机延迟最大值(以毫秒为单位)
Constant Delay Offset(in milliseconds):恒定延迟偏移量(以毫秒为单位)

2.设置间隔时间
每个步骤之间的时间间隔 = 随机值+恒定值

7.断言
教程:https://www.cnblogs.com/auguse/articles/11684181.html
模式匹配规则
选项有: 包括、 匹配、 Equals、 Substring 、否。
a.包括:返回结果包括你指定的内容,支持正则匹配相当于 equals 。当返回值固定时,可以返回值做断言,效果和equals相同
b.匹配 :
● 相当于 equals 。当返回值固定时,可以返回值做断言,效果和equals相同
●正则匹配 。 用正则表达式匹配返回结果,但必须全部匹配。 即正则表达式必须能匹配整个返回值,而不是返回值的一部分。
c.Equals : 返回结果与你指定断言完全一致
d.SubString:与 “包括”差不多,都是指返回结果包括你指定的内容,但是subString不支持正则字符串
e.否:就相当于取反。 如果上面断言结果为true,勾选“否”后,最终断言结果为false。如果上面断言结果为false,勾选“否”后,则最终断言结果为 true。
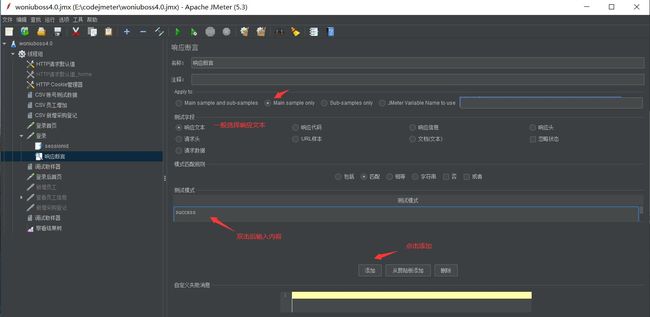
1.创建响应断言

2.填写断言内容,一般选择文本断言
8.集合点
教程:https://www.cnblogs.com/auguse/articles/11684066.html
- 就是为了模拟多个用户同时进行某个业务的操作,就类似于小学生参加夏令营活动,200个学生,8点钟在学校门口一起出去,先来的同学等一等,等到所有的人都来了再一起出发。
- 虽然我们的“性能测试”理解为“多用户并发测试”,但真正的并发是不存在的,为了更真实的实现并发的操作,我们可以在需要压力的地方设置集合点。以登录功能为例,每到输入用户名和密码登录的地方,所有的虚拟用户都相互之间等一等,然后一起访问,这样对服务器的冲击力更大,例如:可以在秒杀、抢购等高并发场景使用
1.创建同步定时器

2.设置集合点
-
Number of Simulated Users to Group by
虚拟用户组的数量:一定要小于或者等于当前脚本线程组中的线程数
-
Timeout in milliseconds
超时时间:如果设置为0,达到了Number of Simulated Users to Group by设置的值才会释放。
如果大于0,那么超过等待时间后还没到达Number of Simulated Users to Group by设置的值,Timer(定时器)将不再等待,会释放已到达的线程
如果设置为0,且线程组的数量无法达到Number of Simulated Users to Group by设置的值,那么将无限等待,除非手动停止
-
Synchronizing timer 仅作用于同一个JVM中的线程,所以,如果使用并发测试,确保"Number of Simultaneous Users to Group by"中设置的值不大于它所在线程组包含的用户数。
-
Synchronizing Timer是在每个sampler(采样器)之前执行的,而不是之后,不管这个定时器的位置放在sampler之后,还是之前。
-
作用域:当执行一个sampler之前时,和sampler处于相同作用域的定时器都会被执行。
-
如果希望定时器仅应用于其中一个sampler,则把该定时器作为子节点加入,如下图:Synchronizing Timer 所属于 HTTP请求。

9.监听器
教程:https://www.cnblogs.com/auguse/articles/13908340.html
监听器预览

察看结果树
-
调式代码的时候用,真实场景要禁用,因为大量请求时,启用该监听器时打印的日志比较多,会造成大IO消耗,影响压力机性能
-
显示请求和响应的细节。比如取样器结果、请求体、请求头、响应体、响应头
-
察看结果树放在线程组下面则会查看所有请求;放在某个请求下面,只查看当前请求;放在某个控制器,则查看此控制器下节点执行的结果

注意:在没有对请求断言的情况下,显示绿色并不一定是成功,只代表响应码是200或300系列,显示红色说明响应码是400或500系列。所以要想确定请求返回的是正确的,必须要加上断言,只有断言成功才会显示绿色。
汇总报告
-
汇总报告,为测试中的每个不同命名的请求创建一个表行。这与聚合报告类似,只是它使用更少的内存。提供了最简要的测试结果信息,同时可以配置 将相应的信息保存至指定的文件中(支持xml、csv格式的文件)。单击Configure按钮,可以配置结果保存各种选项

-
参数说明
Name:名称,可以随意设置,甚至为空; Comments:注释,可随意设置,可以为空; Label 取样器别名,如果勾选Include group name ,则会添加线程组的名称作为前缀 Samples 取样器运行次数 Average 请求(事务)的平均响应时间 Min 请求的最小响应时间 Max 请求的最大响应时间 Std. Dev 响应时间的标准方差 Error % 事务错误率 Throughput 吞吐量 也就是TPS Received KB/sec 每秒收到的千字节 Sent KB/sec 每秒发送的千字节 Avg. Bytes 响应平均流量
聚合报告
- 聚合报告,记录这次性能测试的总请求数、错误率、用户响应时间(中间值、90%、最少、最大)、吞吐量等,用以帮助分析被测试系统的性能。
- 在聚合报告中,各个响应时间不能超过客户的要求,就是合格,例如不能超过响应时间3s,大于3s就是不合格的.聚合报告应该是最详细的报告了,也是最为常用的报告。是在压测过程中最常用的监听器。该监听器对于每个请求,它统计响应信息并提供请求数,平均值,最大,最小值,中位数、90%、95%、错误率,吞吐量(以请求数/秒为单位)和以kb/秒为单位的吞吐量。单击Configure按钮,

- 参数说明:
Name:名称,可以随意设置,甚至为空; Comments:注释,可随意设置,可以为空; Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值 #Samples :表示测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里就显示对应的 HTTP Request的执行次数是100 Average :平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,也可以以Transaction 为单位显示平均响应时间 Median :50%用户的响应时间 90%Line :90%用户的响应时间 95%Line :95%用户的响应时间 99%Line :99%用户的响应时间 Min :最少响应时间 Max :最大响应时间 Error% :本次运行测试中出现错误的请求的数量/请求的总数 Throughput :吞吐量,默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数 Received KB/src:每秒从服务器端“接收”到的数据量 Sent KB/src :每秒从服务器端“发送”到的数据量
10.Jmeter插件管理
教程:https://www.cnblogs.com/auguse/articles/13908379.html
六、woniuboss4.0练习
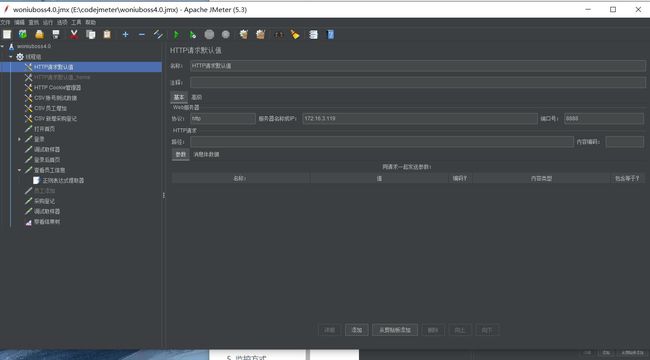
1.请求默认值
创建请求默认值
填写协议、ip地址、端口号。起到全局作用。这样别的请求不用在继续输入协议+ip+端口了
2.登录首页
性能测试中,为了模拟人的操作,所以我们要做打开登录首页的请求

3.登录

3.1正则表达式提取器提取sessionid
3.2 创建cookie管理器,添加sessionid
后续请求携带,使用HTTP cookie管理器实现,注意使用变量的值的形式: ${sid}
3.3响应断言
4.登录后首页

5.新增员工

6.查看员工信息(当前所有员工)
woniuboss系统中手动查询员工信息。
不输入值,直接点击查询按钮,即可抓包所有员工信息。想看一个人的,输入人名即可

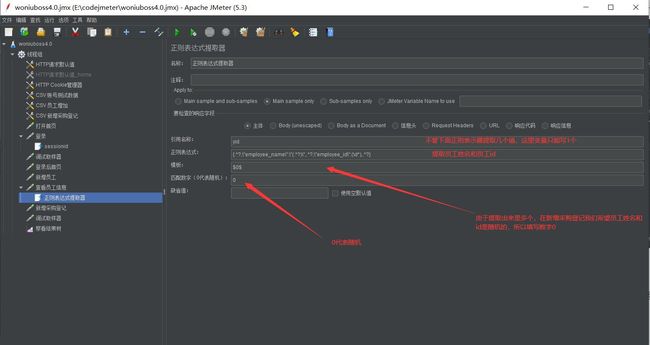
6.1创建正则表达式提取器
通过正则表达式提取当前所有员工名字和员工id。新增采购登记需要员工名和员工id
7.新增采购登记
purchase_employee:填写通过正则表达式随机出来的员工名
ass.purchase_employee_id:填写通过正则表达式随机出来的员工id

察看结果树执行后会发现新增失败,通过调试取样器发现,随机出来的员工名和id的变量名不是正则表达式提取的变量名yid,而是最下面的yid_g1和yid_g2,那么就需要在新增采购登记请求中修改变量名了

修改新增采购登记的变量名

新增成功

七、Jmeter监控服务器
教程:https://www.cnblogs.com/auguse/articles/13909758.html
1.安装插件
Servers Performance Monitoring
2.将 ServerAgent-2.2.3.zip上传到linux服务器中,放在tmp目录下解压
a.ServerAgent-2.2.3要可以启动,必须要有java环境,其实就是安装jdk
https://www.cnblogs.com/auguse/p/13325310.html
b.要在防火墙里面开放端口 4444
https://www.cnblogs.com/auguse/p/13325522.html
c.启动
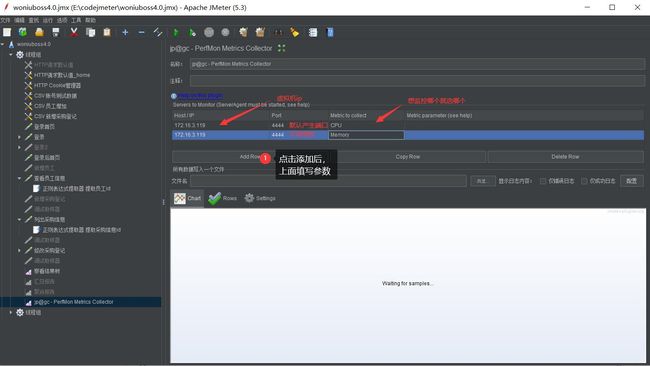
3.创建 PerfMon Metrics Collector

4.参数填写
八、Jmeter事务的划分
事务(Transaction)是指用户在客户端做一种或多种业务所需要的操作集,通过事务函数可以标记完成该业务所需要的操作内容;另一方面可以用来统计用户操作的相应时间。事务响应时间是指通过记录用户请求的开始时间和服务器返回内容到客户时间的差值来计算用户操作响应时间的。
事务是一系列操作步骤的集合,操作步骤是属于事务里面的,就是说以后我们在线程组下面先要添加事务,在事务中添加请求。
线程组----->事务控制器----->请求
1.创建事务控制器

2.所有请求放在事务控制器下
九、Jmeter生成html报告
教程:https://www.cnblogs.com/auguse/articles/13909953.html
1.通过命令行生成报告
1.命令生成
jmeter.bat路径+woniuboss4.0.jmx路径+报告存储路径+log
E:\testtool\apache-jmeter-5.3\bin\jmeter.bat -n -t E:\codejmeter\woniuboss4.0.jmx -e -o E:\codejmeter\report -l denglu.log
-n:以非GUI形式运行Jmeter
-t:脚本文件(.jmx)的路径
-l:记录样本到文本,可以看成日志,文件名为.log即可
-e:在脚本运行结束后生成html报告
-o:用于存放html报告的路径
report是手动创建的测试报告文件夹,每次启动命令之前,文件夹内容必须清空,否则报错
2.执行完毕后,用浏览器打开生成的文件目录下的index文件
十、阶梯式加压
教程:https://www.cnblogs.com/auguse/articles/11684117.html
1.前言
- 在实际压测过程中用户在做不同操作之间有时间停顿,或者延迟,思考时间就是模拟用户的操作过程中的停顿的间
- 同时需要注意:步伐,速度,主要包括,大量用户发送请求和退出时间,控制迭代之间的时间,例如,现场用户10个,设置5秒内全部进入
- 压力测试时间:假如需要100个人同时测试20分钟,这里持续20分钟就是压测时间。
- 在以上几点中HP loadrunner 负载场景设置由为强大,而jmeter本身场景设置插件功能较弱,则需要使用 Stepping Thread Group 插件来完成
2.Stepping Thread Group的特性
- 可使用预览图显示设置的负载
- 可延迟启动执行各线程组
- 可持续增加执行负载
- 可设置最大负载的持续运行时间
3.Stepping Thread Group的作用
- 减少服务器在某个瞬间的压力,做性能测试应该持续加压,而不是瞬间加压
- 逐步增压越平缓越好,更容易从结果看到多少压力值下,有性能瓶颈
4.安装的插件
打开JMeter上的plugin manager,点击AvailablePlugns下拉滚动条到底部,勾选Custom Thread Group,点击右下角的Apply Changes and Restart JMeter,安装好了会出现在Installed Plugins列表里。
5.参数说明
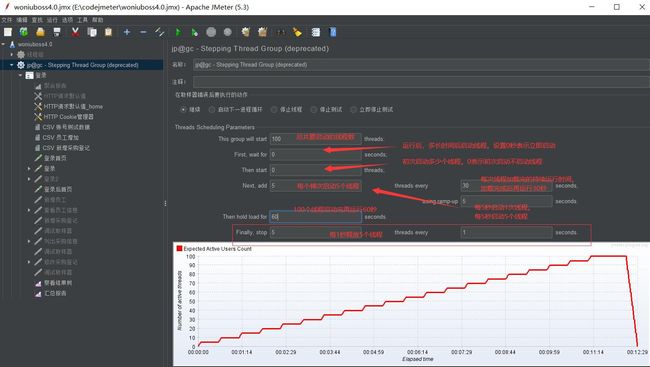
- **this group will start:**表示总共要启动的线程数;若设置为 100,表示总共会加载到 100 个线程
- **first,wait for:**从运行之后多长时间开始启动线程;若设置为 0 秒,表示运行之后立即启动线程
- **then start:**初次启动多少个线程;若设置为 0 个,表示初次不启动线程
- **next add:**之后每次启动多少个线程;若设置为 10个,表示每个梯次启动 10 个线程
- **threads every:**当前运行多长时间后再次启动线程,即每一次线程启动完成之后的持续时间;若设置为 30 秒,每梯次启动完线程之后再运行 30 秒
- **using ramp-up:**启动线程的时间;若设置为 5 秒,表示每次启动线程都持续 5 秒(和基础线程组的ramp-up一样意思)
- **then hold load for:**线程全部启动完之后持续运行多长时间,如图:设置为 60 秒,表示 100 个线程全部启动完之后再持续运行 60 秒
- **finally,stop/threads every:**多长时间释放多少个线程;若设置为 5 个和 1 秒,表示持续负载结束之后每 1 秒钟释放 5 个线程
6.注意
执行线程释放过程中,执行的线程依然在运行
十一、性能测试场景设计模型
门型场景
并发用户数直接上升到最大用户数,持续一段时间后全部停止,一般用于压力测试或可靠性测试
拱形场景
并发用户数逐渐上升,持续一段后慢慢下降,从而确定当前配置的系统环境能够支撑的最大/最佳用户数
复杂场景
模拟还真是服务器访问情况,需要大量历史数据作为支撑
混合场景
综合利用上述场景
十二、注册用户数和在线用户数
注册用户数
注册用户数一般指的是数据库中存在的用户数。
一般情况下,注册用户数,不一定会对服务器产生压力,在选择线程数的时候,一般老板或者客户告诉你的都是注册用户数,线程取其中到5%-20%之间即可,一般选择5%。
在性能测试中1个线程不是指1个用户,代表100左右个用户。
在线用户数
在线用户数只是 ”挂” 在系统上,对服务器不产生压力,注册用户数一般指的是数据库中存在的用户数。**
线程怎么分配给各个业务场景?场景建模
2000个线程怎么分配?
需要统计页面的访问量(pv),根据访问的数量比例计算
十三、监控方式的选择
Spotlight
不能使用root用户,需要新建用户
#新建用户
useradd -g root chen
#设置密码123456
passwd chen
使用Jmeter SeverAangt(不推荐)
Jmeter本身是需要产生压力也就是线程的,如果使用它监控,产生的线程就会减少
使用Linux命令监控
top:实时监控系统资源
vimstat 2:每隔2秒监控系统资源。数字可改变
free:查看当前系统的内存情况,包括swap空间
top详解
https://www.cnblogs.com/auguse/articles/13934391.html
vimstat详解
https://www.linuxprobe.com/linux-vmstat-do.html
普罗米修斯监控
-
监控容器的
-
适合使用docker容器部署的项目
Zabbix监控
适合监控传统方式部署的项目
十四、Jmeter参数化从Mysql读取数据
教程:https://www.cnblogs.com/auguse/category/1563005.html
1. 驱动下载
-
不建议下载最新版
-
以读取MySQL数据库为例,下载一个mysql驱动包,mysql官网下载网址:https://downloads.mysql.com/archives/c-j/
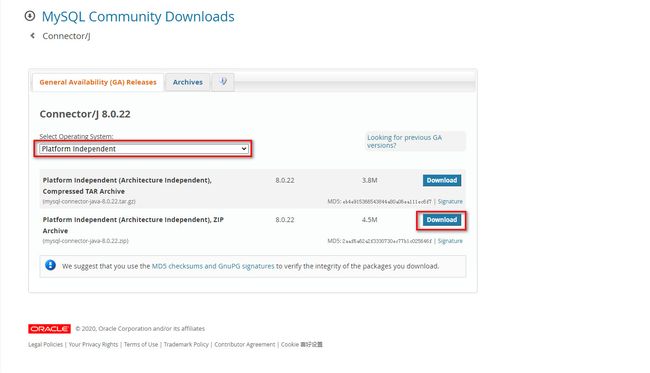
Select Operating Systems:选择Platform independent
然后选择zip包,点击Download。对其进行解压,找到mysql-connector-java-8.0.22.jar文件
2. 导入MySQL驱动包
打开jmeter,新建一个测试计划,选中测试计划,点击浏览,选择上文找到的mysql-connector-java-8.0.22.jar,点击Open就好。


3. 连接数据库
建一个线程组,右击线程组,添加-配置元件-JDBC Connection Configuration
新建线程组
新建JDBC Connection Configuration

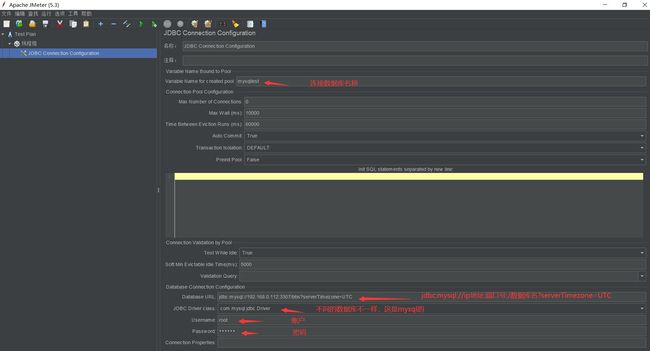
参数说明
Variable Name for created pool:填写一个连接名称,自定义名称(如mysqltest),在后面的JDBC请求中需要用到,以适配连接的是该连接名称的数据库配置。
Database URL:jdbc:mysql://数据库ip:端口号/数据库名 +?serverTimezone=UTC这个是因为,后面JDBC请求不成功,说是时区的问题,所以便加上这个。
如:jdbc:mysql://192.168.0.112:3307/test?serverTimezone=UTC
JDBC Driver class:com.mysql.jdbc.Driver(不同的数据库不一样,这个是mysql的)
Username:数据库登录名
Password:数据库登录密码
4. 查询数据库获取数据(JDBC请求)
右击线程组,添加-取样器-JDBCRequest
新建JDBCRequest

参数说明
Variable Name of Pool declared:对应上文Variable Name for created pool的设置值,如mysqltest
Variable Names:对应sql查询结果的字段值, 表字段值有多少个,则这里对应值就有多少个。如下文查询出username,password,address,emai字段,设置变量名则为username,password,address,emai

5. 查看结果(察看结果树)
右击线程组,添加-监听器-察看结果树 ,然后执行脚本,可以看到Text中JDBC Request请求为绿色的,说明请求成功。响应数据为查询数据库的数据。跟数据库查询结果一致。
新建查看结果树
查询结果

6、其他请求中引用
Jmeter中通过${}形式来取参数值,当取值为变量,${变量名},如上文中引用username的字段值,${username}
十五、性能测试流程
a.性能需求分析
挑选用户使用最频繁的功能来做测试,比如:登陆,搜索,提交订单
确定性能指标,比如:事务通过率为100%;90%的事务响应时间不超过5秒;并发用户为1000人时CPU和内存的使用率在70%以下
b.性能测试计划
确测试时间和测试环境和测试工具的选择
注明测试通过指标以及业务场景
准备性能测试数据
c.搭建性能测试环境
注意这里测试环境一定要和线上正式环境保持一致
d.通过性能测试用例,编写性能测试脚本
性能测试脚本进行调优,设置检查点、参数化、关联、集合点、事务,调整思考时间
e.设计性能测试场景,监控服务器,运行测试场景
f.分析性能测试结果,判断性能瓶颈,反馈结果信息
g.回归性能测试
h.编写性能测试报告
1. 测试需求的提取
老板或者客户说:我们网站会有百万级访问量(百万级不等于线程数量)
实际:
在性能测试中1个线程不等于1个人,这两个不能划等,1个线程可以大约看成100人左右
老板和客户所说额其实是最佳用户数,在测试指标一定的情况,服务器所能承受的访问量:
性能测试目标:
CPU使用率不能超过75%
内存使用率不能超过80%
磁盘的繁忙率不能超过70%
网路的使用率不能超过70%
满足20000个并发用户的访问
2. 测试计划的编写
测试的目标、范围、时间
测试资源:人力、物力(硬件环境、网络环境、软件环境需求)
通过标准
挂起恢复条件
业务场景(业务有哪些)
测试数据准备
3. 根据测试计划开发性能测试脚本
根据业务场景来
4. 执行脚本、场景建模(执行多次)
5. 回归测试
6. 测试报告
十六、分布式
教程:https://www.cnblogs.com/auguse/articles/13928733.html
注意
Jmeter版本、插件、测试数据必须一致
连接对方,对方必须开放端口
.主机应该把Jmeter全部打包给从机,统一起来
十七、性能进阶
1.alfresco项目练习
1.登录页面
fiddler抓包响应结果

jmeter响应结果是英文,如何解决?

解决办法
将Accept-Language和User-Agent添加至HTTP信息头管理器
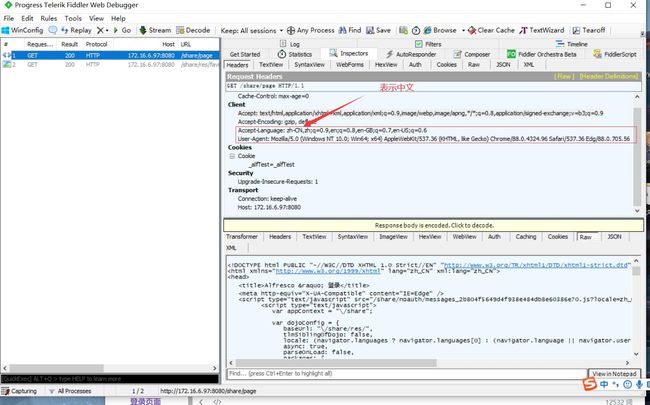
结果展示

2.登录
关于登录接口302重定向
为什么登录抓包显示POST请求,而在jmeter中请求又变成GET请求?
因为开发给接口做了重定向,而Jmeter默认选择了跟随重定向


为什么登录请求在Fiddler响应式空的,而在Jmeter显示html文本,反而像是登录后的显示信息?
因为做了302重定向,而Jmeter默认选择了跟随重定向

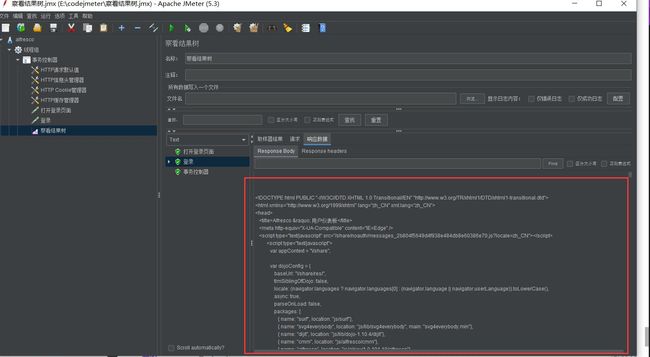
选择自动重定向后,虽然变成了POST请求,但是登录的响应显示不是登录后页面,反而显示未登录状态


正则表达式提取sessionid,调试取样器为什么没有提取出来?
因为登录接口做了重定向,而Jmeter默认选择了跟随重定向,这时需要取消掉跟随重定向和自动重定向


这时响应头也有了sessionid

3.用户仪表板
登录后显示的页面
4.创建文件
与往常做的请求不一样,这次的请求类型是json类型

将消息体数据拷贝进下面位置。
此项目中prop_cm_name和prop_cm_content不能重复,需要改名

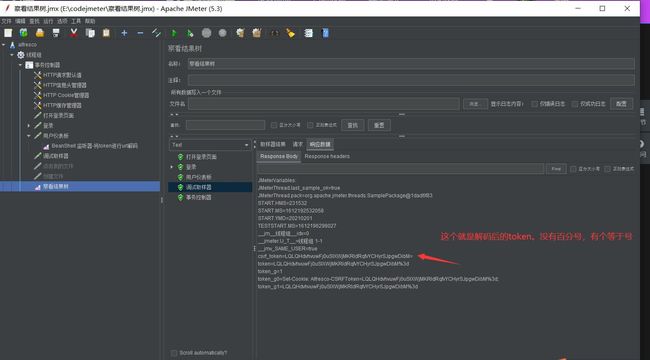
创建文件失败,且发现自动携带了token,我们并没有提取token,为什么就自动携带了呢?是因为之前登录重定向的原因,但是这里请求自动携带的token是没有效果的。请求还是会失败。

所以我们要在登录后的请求时去提取token,需要再添加一个正则表达式。这是需要注意的是这是正则表达式提取不是在网页的主体去提取,而是在次体提取。
在Fiddler找重定向的请求,提取token

创建正则表达式提取token,在次体中提取,同时要将跟随重定向选中

选中跟随重定向,运行脚本,调试取样器就可以看见提取的token了

可是sessionid又去哪了?需要注意的是用户仪表板请求已经携带了sessionid,所以在这个项目中不携带sessionid是可以的

请求头中携带token,和下面的token有何区别?
请看下图,上面的token是经过url解码的,而下面中的token是经过url编码的。下面token解码完成后就是上面的token,所以在这个请求前我们应该将url先进行解码。那么如何解码呢?使用Bran Shell

2.Bean Shell
Jmeter有哪些Bean Shell
-
- 定时器: BeanShell Timer
- 前置处理器:BeanShell PreProcessor
- 采样器: BeanShell Sampler
- 后置处理器:BeanShell PostProcessor
- 断言:BeanShell断言
- 监听器:BeanShell Listener
3.java代码编码解码
package com.demo;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;//解码
import java.net.URLEncoder;//编码
//bianma指的是类名
public class bianma {
public static void main(String[] args) throws UnsupportedEncodingException {
// TODO Auto-generated method stub
//将蜗牛学院 进行编码
String str1 = "蜗牛学院";
String str2 = URLEncoder.encode(str1, "UTF-8");
//输出编码后的内容
System.out.print("这是编码后的:"+str2+"\n");
//解码前的内容
String str3 = "%E8%9C%97%E7%89%9B%E5%AD%A6%E9%99%A2";
//对于编码的结果在进行解码
String str4 = URLDecoder.decode(str3, "UTF-8");
System.out.print("这是解码后的:"+str4);
}
}
用户仪表板解码
在用户仪表板下进行解码。因为是在登录请求之后,用户仪表板之前进行url编码的,所以在用户仪表板下进行解码
方法一:BeanShell Listener
创建BeanShell Listener

java代码对url进行解码

cookie管理器引用

调试取样器查看解码后的token
方法二:应用.java源文件
方法三:引入字节码
方法四:jar
创建文件
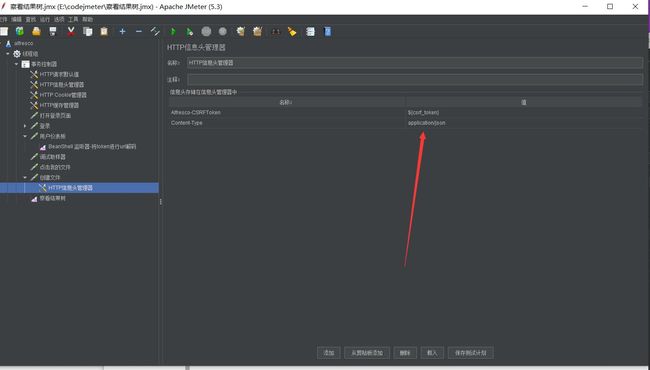
此请求头中有一个url解码的token,所有应该在此请求下单独创建一个HTTP信息管理器,引用解码变量

为什么还会报错?
因为Content-Type是application/json,所以应该此请求的HTTP信息头管理器添加json信息头
不能添加到最上面的HTTP信息头管理器,否则所有请求都是json类型


4.网站如果出现了重定向时
-
登录一定要勾上自动重定向或者跟随重定向,一般选择跟随重定向。不勾获取不到token
-
要在次体中使用正则表达式提取token
十八、LoadRunner
1.安装
以管理员身份(QA)运行
2.组件构成
Virtual User Generator:类似于一个IDE工具,用来进行脚本开发,录制脚本,调试脚本
Controller:设置执行场景,产生线程,进行脚本执行。运行场景,压力测试
Analysis:对于Controller执行的结果进行分析,可以生成可视化测试报告
3.脚本开发
教程:https://www.cnblogs.com/auguse/articles/13965326.html
录制
将LoaderRunner12版本的wplus_init_wsock.exe替换掉11版本bin目录下的。LoaderRunner要处于关闭状态
新建 New Virtual User

选择Web(HTTP/HTML),点击Create新建

设置录制选项
选择bin目录下的wplus_init_wsock.exe,然后点击Options

Recording选项:对于web应用,一般选择HTML_BASED SCRIPT模式下的A script ccntaining explicit URLs only进行录制脚本,避免脚本之间的前后依赖关系。

选择UTF-8

取消自动关联

使用代理录制,进行以下参数设置,弹出新增代理服务器设置页面,上面输入系统服务器的地址(IP或者域名不用写http://)和端口号,Service Id 选择http,下面的监听端口号输入浏览器或者手机代理上设置的端口号(端口号不要被占用即可)随后点击Update


浏览器SwitchyOmega代理插件,添加代理。Edge、Chrome、Firefox都可以添加这个插件


点击ok后会卡顿一会,因为11版本用的是12版本的录制插件


处于录制状态,录制时不能关闭弹窗,也不能点击Shutdown按钮,否则无法录制

登录WoniuBoss4.0,做登录和注销操作,然后点击停止录制

停止录制后,会保存,回到LoadrRunner就可以看到录制的脚本了

保存

执行录制的脚本

查看结果

为什么录制脚本时取消了关联,后续的请求还能成功?
因为在录制的过程中,已经把cookie录制进去了,只要cookie没过期那么录制的脚本就能执行成功。有的网站的cookie长期都不会过期,比如WoniuBoss4.0就是这种情况,这样很不安全。
编写
创建函数web_url、web_submit_data

搜索函数

函数及说明
1.web_url: 用于进入或者打开一个网页的时候使用,其实发出一个get请求
url:请求url地址
Resource:0代表非资源,1代表资源
Referer: 后面跟的是当前请求的上一个url地址。由于这个请求时第一个所以后面没有
2.web_submit_data
Method:请求的类型,只支持post 和 get
Action:请求的url地址
ITEMDATA:里面写的请求的参数
代码
Action()
{
//打开首页
web_url("打开首页",
"URL=http://172.16.6.237:8888/WoniuBoss4.0/login",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//登录
web_submit_data("登录",
"Action=http://172.16.6.237:8888/WoniuBoss4.0/login/userLogin",
"Method=POST",
"TargetFrame=",
"Referer=",
ITEMDATA,
"Name=userName", "Value=WNCD000", ENDITEM,
"Name=userPass", "Value=woniu123", ENDITEM,
"Name=checkcode", "Value=0000", ENDITEM,
"Name=remember", "Value=Y", ENDITEM,
LAST);
//登录后首页
web_url("打开首页",
"URL=http://172.16.6.237:8888/WoniuBoss4.0/main",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
return 0;
}
1.关联、代码调试、添加cookie
创建函数
1.创建注册型关联函数
web_reg_save_param_ex(
"ParamName=sid",
"LB=JSESSIONID=",
"RB=;",
SEARCH_FILTERS,
"Scope=HEADERS",
LAST);
2.代码调试
-sessionid一定要放在登录函数前面,而想通过调试打印出sessionid需要放在登录函数后面
lr_error_message(lr_eval_string("{sid}"));
3.将提取出来的sessonid添加到cookie中,跨域DOMAIN后面跟服务器的ip,如果不添加的话脚本可能不执行
web_add_cookie("JSESSIONID={sid}; DOMAIN=172.16.6.237");


代码
Action()
{
//打开首页
web_url("打开首页",
"URL=http://172.16.6.237:8888/WoniuBoss4.0/login",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//注册型函数放在目标函数的前面
// 提取sessionid,赋给变量sid
web_reg_save_param_ex(
"ParamName=sid",
"LB=JSESSIONID=",
"RB=;",
SEARCH_FILTERS,
"Scope=HEADERS",
LAST);
//登录
web_submit_data("登录",
"Action=http://172.16.6.237:8888/WoniuBoss4.0/login/userLogin",
"Method=POST",
"TargetFrame=",
"Referer=",
ITEMDATA,
"Name=userName", "Value=WNCD000", ENDITEM,
"Name=userPass", "Value=woniu123", ENDITEM,
"Name=checkcode", "Value=0000", ENDITEM,
"Name=remember", "Value=Y", ENDITEM,
LAST);
//代码调试,打印出sessionid
lr_error_message(lr_eval_string("{sid}"));
//将提取出来的sessonid添加到cookie中,跨域DOMAIN后面跟服务器的ip,如果不添加的话脚本可能不执行
web_add_cookie("JSESSIONID={sid}; DOMAIN=172.16.6.237");
//登录后首页
web_url("登录后首页",
"URL=http://172.16.6.237:8888/WoniuBoss4.0/main",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//点击公告发布
web_url("点击公告发布",
"URL= http://172.16.6.237:8888/WoniuBoss4.0/notice/add",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//发布公告
web_submit_data("doAdd",
"Action=http://172.16.6.237:8888/WoniuBoss4.0/notice/doAdd",
"Method=POST",
"TargetFrame=",
"RecContentType=text/plain",
"Referer=http://172.16.6.237:8888/WoniuBoss4.0/notice/add",
"Snapshot=t10.inf",
"Mode=HTML",
ITEMDATA,
"Name=title", "Value=哈哈", ENDITEM,
"Name=content", "Value=\如上图所示,这个界面是安装与 JDK 同版本的 JRE张三\n\n\n张三\n\n\n张三\n\n\n张三\n\n
", ENDITEM,
LAST);
return 0;
}
2.参数化
教程:https://www.cnblogs.com/auguse/articles/13972893.html
编辑数据
-
数据存放在txt文档中,参数化文件如果出现乱码,请另存为选择ANSI编码格式
-
在LoadRunner中需要将txt文件后缀格式转换成dat格式
user.dat
添加数据。


界面说明
点击“Add Column…”,添加新的一列信息,点击“Edit with Notepad”再次编辑参数化数据文件

数据分配与更新方式
Select next row【选择下一行】:
Sequential(顺序):按照参数化的数据顺序,一个一个的来取。
Random(随机):参数化中的数据,每次随机的从中抽取数据。
Unique(唯一):为每个虚拟用户分配一条唯一的数据
Update value on【更新时的值】:
每次迭代(Each iteration) :每次迭代时取新的值,假如50个用户都取第一条数据,称为一次迭代;完了50个用户都取第二条数据,后面以此类推。
每次出现(Each occurrence):每次参数时取新的值,这里强调前后两次取值不能相同。
只取一次(once) :参数化中的数据,一条数据只能被抽取一次。(如果数据轮次完,脚本还在运行将会报错)
组合方式推荐:
--前两种用的多
随机+迭代 : 适用于多点登录,可以搜索、发帖、回帖
唯一+迭代 : 适用于单点登录(不推荐),注册
顺序+迭代:适用于多点登录。可以搜索,发帖,回帖,尽量避免使用
唯一+一次:适用于单点登录
如何参数化?以登录为例
表示使用当前文件的第1列数据进行参数化

表示使用当前文件第2列数据参数化,跟随第1列取值方式。第1列取第1个值第二列就取第2个值

代码中引用

有5组数据可以选择执行5次

代码
Action()
{
//打开首页
web_url("打开首页",
"URL=http://172.16.6.237:8888/WoniuBoss4.0/login",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//注册型函数放在目标函数的前面
// 提取sessionid,赋给变量sid
web_reg_save_param_ex(
"ParamName=sid",
"LB=JSESSIONID=",
"RB=;",
SEARCH_FILTERS,
"Scope=HEADERS",
LAST);
//登录
//将账号和密码参数化
web_submit_data("登录",
"Action=http://172.16.6.237:8888/WoniuBoss4.0/login/userLogin",
"Method=POST",
"TargetFrame=",
"Referer=",
ITEMDATA,
"Name=userName", "Value={username}", ENDITEM,
"Name=userPass", "Value={passwd}", ENDITEM,
"Name=checkcode", "Value=0000", ENDITEM,
"Name=remember", "Value=Y", ENDITEM,
LAST);
//代码调试,打印出sessionid
lr_error_message(lr_eval_string("{sid}"));
//将提取出来的sessonid添加到cookie中,跨域DOMAIN后面跟服务器的ip,如果不添加的话脚本可能不执行
web_add_cookie("JSESSIONID={sid}; DOMAIN=172.16.6.237");
//登录后首页
web_url("登录后首页",
"URL=http://172.16.6.237:8888/WoniuBoss4.0/main",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//点击公告发布
web_url("点击公告发布",
"URL= http://172.16.6.237:8888/WoniuBoss4.0/notice/add",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//发布公告
//将标题和内容参数化
web_submit_data("doAdd",
"Action=http://172.16.6.237:8888/WoniuBoss4.0/notice/doAdd",
"Method=POST",
"TargetFrame=",
"RecContentType=text/plain",
"Referer=http://172.16.6.237:8888/WoniuBoss4.0/notice/add",
"Snapshot=t10.inf",
"Mode=HTML",
ITEMDATA,
"Name=title", "Value={notic_title}", ENDITEM,
"Name=content", "Value={notic_contnet}", ENDITEM,
LAST);
return 0;
}
3.检查点
- 就是Jmeter的断言
- 不要选中文,因为在LoadRunner响应式乱码的,如果没有英文检查内容,就不做检查点了
注册型检查函数
//Search后面表示从哪获得查询文本
//Text表示要查询的文本。如果响应错误不再执行下面的请求
web_reg_find("Search=Body",
"Text=success",
LAST);
设置检查点

检查用户登录是否成功
Action()
{
//打开首页
web_url("打开首页",
"URL=http://172.16.6.237:8888/WoniuBoss4.0/login",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//注册型函数放在目标函数的前面
// 提取sessionid,赋给变量sid
web_reg_save_param_ex(
"ParamName=sid",
"LB=JSESSIONID=",
"RB=;",
SEARCH_FILTERS,
"Scope=HEADERS",
LAST);
//设置检查点,就是断言
//注册型函数要放在前面
//检查用户登录是否成功,如果不成功,脚本不在执行其他请求
web_reg_find("Search=Body",
"Text=success",
LAST);
//登录
//将账号和密码参数化
web_submit_data("登录",
"Action=http://172.16.6.237:8888/WoniuBoss4.0/login/userLogin",
"Method=POST",
"TargetFrame=",
"Referer=",
ITEMDATA,
"Name=userName", "Value={username}", ENDITEM,
"Name=userPass", "Value={passwd}", ENDITEM,
"Name=checkcode", "Value=0000", ENDITEM,
"Name=remember", "Value=Y", ENDITEM,
LAST);
//代码调试,打印出sessionid
lr_error_message(lr_eval_string("{sid}"));
//将提取出来的sessonid添加到cookie中,跨域DOMAIN后面跟服务器的ip,如果不添加的话脚本可能不执行
web_add_cookie("JSESSIONID={sid}; DOMAIN=172.16.6.237");
//登录后首页
web_url("登录后首页",
"URL=http://172.16.6.237:8888/WoniuBoss4.0/main",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//点击公告发布
web_url("点击公告发布",
"URL= http://172.16.6.237:8888/WoniuBoss4.0/notice/add",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
//发布公告
//将标题和内容参数化
web_submit_data("doAdd",
"Action=http://172.16.6.237:8888/WoniuBoss4.0/notice/doAdd",
"Method=POST",
"TargetFrame=",
"RecContentType=text/plain",
"Referer=http://172.16.6.237:8888/WoniuBoss4.0/notice/add",
"Snapshot=t10.inf",
"Mode=HTML",
ITEMDATA,
"Name=title", "Value={notic_title}", ENDITEM,
"Name=content", "Value={notic_contnet}", ENDITEM,
LAST);
return 0;
}
检查成功

4.添加信息头
函数
web_add_header();
//添加信息头
web_add_header("Content-Type",
"multipart/form-data");
5.bbs论坛注册
手写
Action()
{
//提取cookie
web_reg_save_param_ex(
"ParamName=lastact",
"LB=19LN_2132_lastact=",
"RB=;",
SEARCH_FILTERS,
"Scope=HEADERS",
LAST);
web_url("首页",
"URL=http://172.16.6.125/bbs/forum.php",
"TargetFrame=",
"Resource=1",
"Referer=",
"Mode=HTML",
LAST);
//lr_error_message(lr_eval_string("{lastact}"));
//cookie管理器
web_add_cookie("19LN_2132_lastact={lastact}; DOMAIN=172.16.6.125");
//提取注册formhash
web_reg_save_param_ex(
"ParamName=reformhash",
"LB=,
"RB=\" />",
SEARCH_FILTERS,
"Scope=BODY",
LAST);
//提取name
web_reg_save_param_ex(
"ParamName=name",
"LB=",
SEARCH_FILTERS,
"Scope=BODY",
LAST);
//提取密码
web_reg_save_param_ex(
"ParamName=pwd",
"LB=",
SEARCH_FILTERS,
"Scope=BODY",
LAST);
//提取确认密码
web_reg_save_param_ex(
"ParamName=new_pwd",
"LB=",
SEARCH_FILTERS,
"Scope=BODY",
LAST);
//提取email
web_reg_save_param_ex(
"ParamName=email",
"LB=",
SEARCH_FILTERS,
"Scope=BODY",
LAST);
web_url("打开注册页面",
"URL=http://172.16.6.125/bbs/member.php?mod=register",
"TargetFrame=",
"Resource=0",
"Referer=",
"Mode=HTTP",
LAST);
//打印formhash
lr_error_message(lr_eval_string("{reformhash}"));
//R9D7GV,MYNNcO,a9r9Q9,xJI2R1会失效,应该在打开注册页面去提取
web_submit_data("注册",
"Action=http://172.16.6.125/bbs/member.php?mod=register&inajax=1",
"Method=POST",
"TargetFrame=",
"Referer=",
"Mode=HTTP",
ITEMDATA,
"Name=regsubmit", "Value=yes", ENDITEM,
"Name=formhash", "Value={reformhash}", ENDITEM,
"Name=referer", "Value=http://172.16.6.125/bbs/./", ENDITEM,
"Name=activationauth", "Value=", ENDITEM,
"Name={name}", "Value=lala", ENDITEM,
"Name={pwd}", "Value=123456", ENDITEM,
"Name={new_pwd}", "Value=123456", ENDITEM,
"Name={email}", "[email protected]", ENDITEM,
LAST);
return 0;
}
6.事务
教程:https://www.cnblogs.com/auguse/articles/13973369.html
什么是事物?
事务(Transaction)是指用户在客户端做一种或多种业务所需要的操作集,通过事务函数可以标记完成该业务所需要的操作内容;另一方面可以用来统计用户操作的相应时间。事务响应时间是指通过记录用户请求的开始时间和服务器返回内容到客户时间的差值来计算用户操作响应时间的。
loadrunner如何划分事物?
1、添加事物
插入事务操作可以在录制脚本过程中,也可以在录制结束后进行。可以在脚本中找到需要添加事务的部分,直接插入:
lr_start_transaction("事务");
lr_end_transaction("事务",LR_AUTO);
注意:1、开始与结束函数必须成对出现
2、事务的名称必须一样。
当然,我们也可以将鼠标定位到要插入事务的位置,通过菜单栏来插入事务(insert—>start transaction/end transaction)

2、事物状态详解
LR事务四种状态,在默认情况下使用LR_AUTO来作为事务状态:
--使用LR_AUTO即可
LR_AUTO:是指事务的状态有系统自动根据默认规则来判断,结果为PASS/FAIL。
LR_PASS:是指事务是以PASS状态通过的,说明该事务正确的完成了,并且记录下对应的时间,这个时间就是指做这件事情所需要消耗的响应时间。
LR_FAIL:是指事务以FAIL状态结束,该事务是一个失败的事务,没有完成事务中脚本应该达到的效果,得到的时间不是正确操作的时间,这个时间在后期的统计中将被独立统计。
LR_STOP:将事务以STOP状态停止。事务的PASS和FAIL状态会在场景的对应计数器中记录,包括通过的次数和事务的响应时间,方便后期分析该事务的吞吐量以及响应时间的变化情况。
代码
Action()
{
lr_start_transaction("注册事务");
//提取cookie
web_reg_save_param_ex(
"ParamName=lastact",
"LB=19LN_2132_lastact=",
"RB=;",
SEARCH_FILTERS,
"Scope=HEADERS",
LAST);
web_url("首页",
"URL=http://172.16.6.125/bbs/forum.php",
"TargetFrame=",
"Resource=1",
"Referer=",
"Mode=HTML",
LAST);
//lr_error_message(lr_eval_string("{lastact}"));
//cookie管理器
web_add_cookie("19LN_2132_lastact={lastact}; DOMAIN=172.16.6.125");
//提取注册formhash
web_reg_save_param_ex(
"ParamName=reformhash",
"LB=,
"RB=\" />",
SEARCH_FILTERS,
"Scope=BODY",
LAST);
web_url("打开注册页面",
"URL=http://172.16.6.125/bbs/member.php?mod=register",
"TargetFrame=",
"Resource=0",
"Referer=",
"Mode=HTTP",
LAST);
//打印formhash
lr_error_message(lr_eval_string("{reformhash}"));
//R9D7GV,MYNNcO,a9r9Q9,xJI2R1会失效,应该在打开注册页面去提取
web_submit_data("注册",
"Action=http://172.16.6.125/bbs/member.php?mod=register&inajax=1",
"Method=POST",
"TargetFrame=",
"Referer=",
"Mode=HTTP",
ITEMDATA,
"Name=regsubmit", "Value=yes", ENDITEM,
"Name=formhash", "Value={reformhash}", ENDITEM,
"Name=referer", "Value=http://172.16.6.125/bbs/./", ENDITEM,
"Name=activationauth", "Value=", ENDITEM,
"Name=R9D7GV", "Value=cddj5", ENDITEM,
"Name=MYNNcO", "Value=123456", ENDITEM,
"Name=a9r9Q9", "Value=123456", ENDITEM,
"Name=xJI2R1", "[email protected]", ENDITEM,
LAST);
lr_end_transaction("注册事务",LR_AUTO);
return 0;
}

7.思考时间
教程:https://www.cnblogs.com/auguse/articles/13973714.html
什么是思考时间
用户访问某个网站,例如一次查询,用户需要时间查看查询的结果是否是自己想要的。例如一次订单提交,用户需要时间核对自己填写的信息是否正确等。也就是说用户在做某些操作时,是会有停留时间的,我把这个时间叫思考时间。但利用代码去执行的时候是没有时间的,当然,脚本运行本身是需要时间的,但比起人的思考时间要小很多。这也是我们为什么要用软件来代替人的某些工作。但有时候,我们在做性能测试时,为了更真实的模拟用户的操作,需要给代码加入思考时间。
loadrunne如何设置思考时间
lr_think_time(13);
思考时间:两个步骤之间的停顿时间
注意:
一般在测试过程中(控制台),需要设置思考时间,思考时间的设置根据测试需求来定;
而在脚本生成器中一般 忽略思考时间,越快越好,这是为了方便调试脚本。
点击Run-time Setting下面的TinkTime,设置项详解如下:
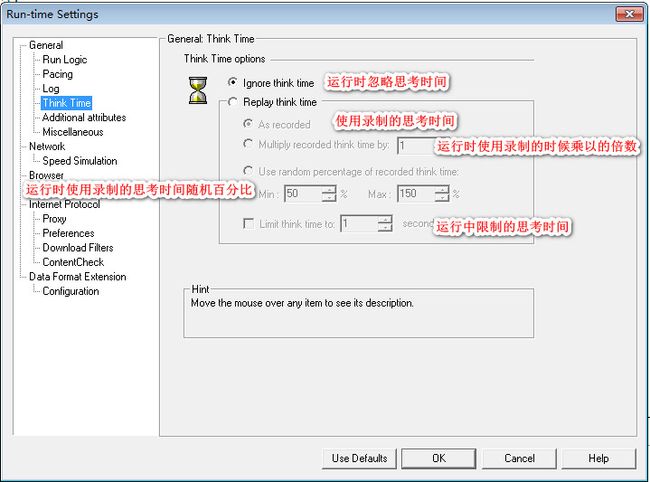
8.bbs论坛注册发布帖子
Action()
{
lr_start_transaction("注册");
web_url("论坛首页",
"URL=http://172.16.6.125/bbs/forum.php",
"TargetFrame=",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t10.inf",
"Mode=HTML",
EXTRARES,
"Url=static/image/common/scrolltop.png", "Referer=http://172.16.6.125/bbs/data/cache/style_1_common.css?oX2", ENDITEM,
LAST);
lr_think_time(7);
//提取formhash
web_reg_save_param_ex(
"ParamName=regformhash",
"LB=,
"RB=\" />",
SEARCH_FILTERS,
"Scope=BODY",
LAST);
//用户名
web_reg_save_param_ex(
"ParamName=name",
"LB=",
SEARCH_FILTERS,
"Scope=BODY",
LAST);
//密码
web_reg_save_param_ex(
"ParamName=pwd",
"LB=9.集合点
教程:https://www.cnblogs.com/auguse/articles/13973530.html
4.loadrunner函数
web_url
语法
int web_url( const char *StepName, const char *url, <List of Attributes>, [EXTRARES, <List of Resource Attributes>,] LAST );
参数说明
URL:请求的URL地址
RecContentType:响应头中ContentType的值
Referer:上一步的url地址
Mode : 录制级别:HTML或HTTP
Resource:代表 URL是否是资源
0 代表不是资源
1代表是资源
TargetFrame:包含当前链接或资源的框架的名称。 点击这里查看更多信息。
web_submit_data
语法:
int web_submit_data( const char *StepName, const char *Action, <List of Attributes>, ITEMDATA, <List of data>, [ EXTRARES, <List of Resource Attributes>,] LAST );
参数说明:
Action:url地址
Method:请求的类型
EncType:post请求提交的Body格式
RecContentType:响应头中ContentType的值
Referer:上一步的url地址
Mode : 录制级别:HTML或HTTP
Resource:代表 URL是否是资源
0 代表不是资源
1代表不是资源
TargetFrame:包含当前链接或资源的框架的名称。 点击这里查看更多信息。
ITEMDATA:里面为提交的参数,格式:
"Name=ctivationauth","Value=",ENDITEM,
web_reg_save_param_ex
注册型函数,要放在提取内容的提前前面,用来做关联操作
语法:
int web_reg_save_param_ex( const char *ParamName, [const char *LB, ][const char *RB,] <List of Attributes>, <SEARCH FILTERS>,LAST );
参数
//关联
web_reg_save_param_ex(
"ParamName=formhash2",
"LB=lr_save_string
lr_save_string函数可以将,将内容赋值一个变量。
使用web_reg_save_param_ex 提取出多个值赋给fids,保存到变量fid,调试代码时应该打印fid。
//从fids里面随机取出一个值,保存给变量fid
lr_save_string(lr_paramarr_random("fids"),"fid");
//调试代码
lr_error_message(lr_eval_string("{fid}"));
代码调试
lr_error_message(lr_eval_string("{formhash1}"));
web_reg_find
- 就是Jmeter的断言
- 不要选中文,因为在LoadRunner响应式乱码的,如果没有英文检查内容,就不做检查点了
//Search后面表示从哪获得查询文本
//Text表示要查询的文本。如果响应错误不再执行下面的请求
web_reg_find("Search=Body",
"Text=success",
LAST);
web_add_cookie
将提取出来的sessonid添加到cookie中,跨域DOMAIN后面跟服务器的ip,如果不添加的话脚本可能不执行
web_add_cookie("JSESSIONID={sid}; DOMAIN=172.16.6.237");
web_add_header
//添加信息头
web_add_header("Content-Type",
"multipart/form-data");
事务
lr_start_transaction("事务");
lr_end_transaction("事务",LR_AUTO);
思考时间
lr_think_time(13);
web_cusetom_rquest
可以发出 get post put delete 类型的请求,一般如果请求的消息体格式json就是
web_custom_request("登录",
"URL=http://192.168.246.133/bbs/member.php?mod=logging&action=login&loginsubmit=yes&infloat=yes&lssubmit=yes&inajax=1",
"Method=POST",
"TargetFrame=",
"Resource=0",
"Referer=http://192.168.246.133/bbs/forum.php",
"EncType=application/x-www-form-urlencoded",
"Body=fastloginfield=username&username=admin&password=123456&quickforward=yes&handlekey=ls",
"RecContentType=text/xml",
LAST);
Body:有多个参数时中间使用$隔开,
十九、Nginx反向代理实现多Tomcat负载均衡
教程:https://www.cnblogs.com/auguse/articles/13951019.html
1.新建虚拟机
2.Centos7更换镜像源
1.备份(针对所有CentOS可用,备份文件在当前路径下)
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2.安装wget
yum install -y wget
3.下载CentOS 7的repo文件
本人使用的阿里云第二个地址
1.阿里云源:
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
#或者
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
2.网易云源:
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.163.com/.help/CentOS7-Base-163.repo
4.更新镜像源
1.#清除缓存
yum clean all
2.#生成缓存
yum makecache
3.更新yum源,等待更新完毕即可。(执行加载完后会卡顿一会)
yum -y update
4.yum clean all
5. yum makecache
3.JDK1.8安装
1.上传文件
上传文件至tmp目录下
2.解压
1.进入tmp,解压到opt目录下。
--注意版本,别傻乎乎直接复制
cd /tmp
tar -zxvf jdk-8u211-linux-x64.tar.gz -C /opt
2.进入opt目录将jdk改名
cd /opt
mv jdk1.8.0_211 jdk1.8
3.配置环境变量
1.进入文件
vi /etc/profile
2.将下面的内容添加在末尾
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
3.执行命令使配置生效
source /etc/profile
4.检测安装是否成功
java
javac
java -version
4.Tomcat8安装
由于是负载均衡,暂时安装2个Tomcat8
1.上传文件
上传至tmp目录下
2.解压
1.进入tmp目录,解压至opt目录下
cd /tmp
tar -zxvf apache-tomcat-8.5.55.tar.gz -C /opt
2.进入opt目录,改名改为tomcat1
cd /opt
mv apache-tomcat-8.5.55 tomcat1
3.启动tomcat
/opt/tomcat1/bin/startup.sh
3.开放8080端口
# 查询端口是否开放
firewall-cmd --query-port=8080/tcp
# 开放8080端口
firewall-cmd --permanent --add-port=8080/tcp
#更新防火墙规则
firewall-cmd --reload
4.访问
别傻乎乎复制,注意自己的ip和端口
http://172.16.6.117:8080/
5.安装第2个Tomcat
复制tomcat
1.进入opt目录,复制tomcat1并重命名为tomcat2
cd /opt
cp -r tomcat1 tomcat2
修改第2个tomcat配置文件
需要注意的是多台tomcat配置在同一个机器上避免冲突,需要修改端口
1.进入server.xml
vi /opt/tomcat2/conf/server.xml
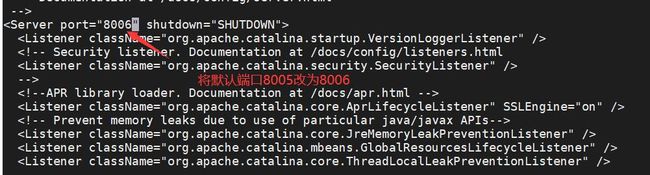


启动
/opt/tomcat2/bin/startup.sh
开放8081端口
# 查询端口是否开放
firewall-cmd --query-port=8081/tcp
# 开放8081端口
firewall-cmd --permanent --add-port=8081/tcp
#更新防火墙规则
firewall-cmd --reload
访问
http://172.16.6.117:8081/
6.修改各个Tomcat的index.jsp
为了体现出各个Tomcat的区别,顺便修改一下各个tomcat的index.jsp文件用于区分tomcat
进入第1个Tomcat,找到h1标签
vi /opt/tomcat1/webapps/ROOT/index.jsp

再次访问第1个tomcat就发现不一样了

进入第2个tomcat修改,与上面步骤一样
vi /opt/tomcat2/webapps/ROOT/index.jsp
7.设置Tomcat开机自启
1.先给文件拥有者给 执行权限 x
chmod +x /etc/rc.d/rc.local
2.进入rc.local
vi /etc/rc.d/rc.local
3.在touch开头的下一行,写上需要开机启动的命令
export JAVA_HOME=/opt/jdk1.8
/opt/tomcat1/bin/startup.sh start
/opt/tomcat2/bin/startup.sh start
5.Nginx安装
1.添加 yum 源
Nginx 不在默认的 yum 源中,可以使用 epel 或者官网的 yum 源,本例使用官网的 yum 源。
rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
安装完 yum 源之后,可以查看一下。
yum repolist
下面是安装成功的显示信息
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.huaweicloud.com
* extras: mirrors.huaweicloud.com
* updates: mirrors.aliyun.com
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base 10,070
extras/7/x86_64 CentOS-7 - Extras 413
mysql-connectors-community/x86_64 MySQL Connectors Community 175
mysql-tools-community/x86_64 MySQL Tools Community 120
mysql56-community/x86_64 MySQL 5.6 Community Server 564
nginx/x86_64 nginx repo 206
updates/7/x86_64 CentOS-7 - Updates 1,134
repolist: 12,682
2.安装
yum install nginx
3.配置 Nginx 服务
本次执行启动服务和设置开机启动命令
1.启动服务
systemctl start nginx
2.设置开机启动
systemctl enable nginx
3.重启
systemctl restart nginx
4.停止服务
sudo systemctl stop nginx
5.重新加载,因为一般重新配置之后,不希望重启服务,这时可以使用重新加载。
sudo systemctl reload nginx
4.打开防火墙端口
默认 CentOS7 使用的防火墙 firewalld 是关闭 http 服务的(打开 80 端口)。
firewall-cmd --zone=public --permanent --add-service=http
firewall-cmd --reload
打开之后,可以查看一下防火墙打开的所有的服务
firewall-cmd --list-service
出现下面结果可以看到,系统已经打开了 http 服务。
ssh dhcpv6-client http
Nginx 是一个很方便的反向代理,需要指出的是 CentOS 7 的 SELinux,使用反向代理需要打开网络访问权限。打开网络权限之后,反向代理可以使用了。Nginx安装文件默认在/etc/nginx目录下。
setsebool -P httpd_can_network_connect on
5.访问
直接访问服务器IP,若出现以下信息则说明到这里我们的Nginx就安装成功了!
注意自己的ip
http://172.16.6.117/

6.配置Nginx完成反向代理、负载均衡
1.修改配置文件
修改Nginx配置文件,注意特别注意:里面的内容全部删除,更换为下面的内容。
vi /etc/nginx/nginx.conf
注意下面的ip,每个人都不一样,别傻乎乎直接复制
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
# 各工程最大连接数
worker_connections 1024;
}
http {
# upstream 各服务器地址以及权重,权重越大代表访问率越大
upstream alie.com {
server 172.16.6.117:8081 weight=1;
server 172.16.6.117:8080 weight=1;
}
server {
# 端口默认80
# 配置域名,由于没有域名,因此使用localhost
server_name localhost;
location / {
# 反向代理,这里的地址与上面配置的upstream需一致,实现负载均衡
proxy_pass http://alie.com;
proxy_redirect default;
}
}
}
2.重启
重启Nginx并进行访问测试
systemctl reload nginx
3.访问
直接访问服务器的80端口,Nginx便会通过反向代理将请求转发至配置好的服务器集群中,通过不断刷新即可发现可以访问不同的tomcat。
http://172.16.6.117/
7.redis安装
1.下载fedora的epel仓库
yum install epel-release
2.安装redis数据库
在centos7.3默认安装readis后配置文件在/etc/目录下
yum install redis
3.常见命令介绍
本次执行启动服务和设置开机自启命令
1.启动服务
systemctl start redis
2.设置开机自启动
systemctl enable redis
3.停止服务
systemctl stop redis
4.重启服务
systemctl restart redis
5.查看服务状态
systemctl status redis
6.查看redis进程
ps -ef | grep redis
7.查看端口
netstat -lnp|grep 6379
4.修改redis配置文件
vi /etc/redis.conf
修改配置文件redis.conf 大概在55行左右。修改bind 后面的ip为 0.0.0.0 即可

8.配置tomcat session redis同步
1.上传jar包
通过TomcatClusterRedisSessionManager,这种方式支持redis3.0的集群方式,下载tomcat-cluster-redis-session-manager.zip包,注意:在github要下载最新版的包
将下面4个jar包上传到tomcat1/lib和tomcat1/lib下,直接覆盖原来的jar包
2.配置context.xml
先关闭Tomcat
关闭第1个
/opt/tomcat1/bin/shutdown.sh
关闭第2个
/opt/tomcat2/bin/shutdown.sh
分别配置2个tomcat的context.xml
vi /opt/tomcat1/conf/context.xml
vi /opt/tomcat2/conf/context.xml
将下面的内容放在

3.配置web.xml
配置会话到期时间
分别配置2个tomcat的web.xml
进入下面文件后,输入命令:/session进行搜索
vi /opt/tomcat1/conf/web.xml
vi /opt/tomcat2/conf/web.xml
将会话到期时间30改为60

4.启动tomcat
/opt/tomcat1/bin/startup.sh
/opt/tomcat2/bin/startup.sh
5.测试,增加文件
在tomcat1/webapps/ROOT和tomcat2/webapps/ROOT新建文件session.jsp,然后将下面内容粘贴进去。注意内容上下都要修改
vi tomcat1/webapps/ROOT/session.jsp
<%@page language="java" import="java.util.*" pageEncoding="UTF-8"%>
tomcat-1
Session serviced by tomcat
Session ID
<%=session.getId() %>
<% session.setAttribute("abc","abc");%>
Created on
<%= session.getCreationTime() %>
tomcat-1
vi tomcat2/webapps/ROOT/session.jsp
<%@page language="java" import="java.util.*" pageEncoding="UTF-8"%>
tomcat-2
Session serviced by tomcat
Session ID
<%=session.getId() %>
<% session.setAttribute("abc","abc");%>
Created on
<%= session.getCreationTime() %>
tomcat-2
6.访问
http://172.16.6.117/session.jsp
tomcat-1节点与tomcat-2节点配置相同,测试,我们每次强刷他的sessionID都是一致的,所以我们认为他的session会话保持已经完成,你们也可以选择换个客户端的IP地址来测试


二十、jvm性能调优
教程:https://www.cnblogs.com/auguse/articles/13957658.html
1.内存泄露
内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
2.内存溢出
内存溢出(Out Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出,有时候会自动关闭软件,重启电脑或者软件后释放掉一部分内存又可以正常运行该软件,而由系统配置、数据流、用户代码等原因而导致的内存溢出错误,即使用户重新执行任务依然无法避免 [1] 。
二十一、MySQL性能优化
}
}
### 2.重启
重启Nginx并进行访问测试
systemctl reload nginx
### 3.访问
直接访问服务器的80端口,Nginx便会通过反向代理将请求转发至配置好的服务器集群中,通过不断刷新即可发现可以访问不同的tomcat。
http://172.16.6.117/
## 7.redis安装
### 1.下载fedora的epel仓库
yum install epel-release
### 2.安装redis数据库
在centos7.3默认安装readis后配置文件在/etc/目录下
yum install redis
### 3.常见命令介绍
本次执行启动服务和设置开机自启命令
1.启动服务
systemctl start redis
2.设置开机自启动
systemctl enable redis
3.停止服务
systemctl stop redis
4.重启服务
systemctl restart redis
5.查看服务状态
systemctl status redis
6.查看redis进程
ps -ef | grep redis
7.查看端口
netstat -lnp|grep 6379
### 4.修改redis配置文件
vi /etc/redis.conf
修改配置文件redis.conf 大概在55行左右。修改bind 后面的ip为 0.0.0.0 即可
[外链图片转存中...(img-XkvTP79b-1631522726398)]
## 8.配置tomcat session redis同步
### 1.上传jar包
通过TomcatClusterRedisSessionManager,这种方式支持redis3.0的集群方式,下载tomcat-cluster-redis-session-manager.zip包,**注意:在github要下载最新版的包**
> 将下面4个jar包上传到tomcat1/lib和tomcat1/lib下,直接覆盖原来的jar包
[外链图片转存中...(img-Vn4M5qdi-1631522726400)]
### 2.配置context.xml
> 先关闭Tomcat
关闭第1个
/opt/tomcat1/bin/shutdown.sh
关闭第2个
/opt/tomcat2/bin/shutdown.sh
> 分别配置2个tomcat的context.xml
vi /opt/tomcat1/conf/context.xml
vi /opt/tomcat2/conf/context.xml
将下面的内容放在`标签里面配置`,参考下图中的位置
[外链图片转存中...(img-IrHLxcnQ-1631522726423)]
### 3.配置web.xml
配置会话到期时间
> 分别配置2个tomcat的web.xml
进入下面文件后,输入命令:/session进行搜索
vi /opt/tomcat1/conf/web.xml
vi /opt/tomcat2/conf/web.xml
将会话到期时间30改为60
[外链图片转存中...(img-uYxD7djJ-1631522726425)]
### 4.启动tomcat
/opt/tomcat1/bin/startup.sh
/opt/tomcat2/bin/startup.sh
### 5.测试,增加文件
> 在tomcat1/webapps/ROOT和tomcat2/webapps/ROOT新建文件session.jsp,然后将下面内容粘贴进去。注意内容上下都要修改
</code></pre>
<p>vi tomcat1/webapps/ROOT/session.jsp</p>
<pre><code>
</code></pre>
<p><%@page language=“java” import=“java.util.*” pageEncoding=“UTF-8”%></p> tomcat-1
<h2><font color="red">Session serviced by tomcat</font></h2> <% session.setAttribute("abc","abc");%>
<table border="1">
<tbody>
<tr>
<td>Session ID</td>
<td><%=session.getId() %></td>
</tr>
<tr>
<td>Created on</td>
<td><%= session.getCreationTime() %></td>
</tr>
</tbody>
</table> tomcat-1 ```
<pre><code>vi tomcat2/webapps/ROOT/session.jsp
</code></pre>
<pre><code><%@page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<html>
<head>
<title>tomcat-2
Session serviced by tomcat
Session ID
<%=session.getId() %>
<% session.setAttribute("abc","abc");%>
Created on
<%= session.getCreationTime() %>
tomcat-2
6.访问
http://172.16.6.117/session.jsp
tomcat-1节点与tomcat-2节点配置相同,测试,我们每次强刷他的sessionID都是一致的,所以我们认为他的session会话保持已经完成,你们也可以选择换个客户端的IP地址来测试
[外链图片转存中…(img-GhUCD0Z5-1631522726427)]
[外链图片转存中…(img-faOwHi6f-1631522726429)]
二十、jvm性能调优
教程:https://www.cnblogs.com/auguse/articles/13957658.html
1.内存泄露
内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
2.内存溢出
内存溢出(Out Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出,有时候会自动关闭软件,重启电脑或者软件后释放掉一部分内存又可以正常运行该软件,而由系统配置、数据流、用户代码等原因而导致的内存溢出错误,即使用户重新执行任务依然无法避免 [1] 。