深度强化学习
深度强化学习
- 14.1 强化学习问题
-
- 14.1.1 强化学习定义
- 14.1.2 马尔可夫决策过程
- 14.1.3 强化学习的目标函数
- 14.1.4 值函数
- 14.1.5 深度强化学习
- 14.2 基于值函数的学习方法
-
- 14.2.1 动态规划算法
- 14.2.2 蒙特卡罗方法
- 14.2.3 时序差分学习方法
- 14.2.4 深度 Q 网络
- 14.3 基于策略函数的学习方法
- 14.4 演员 - 评论员算法
强化学习( Reinforcement Learning , RL ),也叫增强学习,是指一类从(与环境)交互中不断学习的问题以及解决这类问题的方法.
14.1 强化学习问题
14.1.1 强化学习定义
在强化学习中,有两个可以进行交互的对象:智能体和环境.
- 智能体( Agent )可以感知外界环境的状态( State )和反馈的奖励( Reward ),并进行学习和决策.智能体的决策功能是指根据外界环境的状态来做出不同的动作( Action ),而学习功能是指根据外界环境的奖励来调整策略.
- 环境( Environment )是智能体外部的所有事物,并受智能体动作的影响而改变其状态,并反馈给智能体相应的奖励.
强化学习的基本要素包括:
- 状态
- 动作
- 策略
· 确定性策略
· 随机性策略 - 状态转移概率
- 即时奖励
14.1.2 马尔可夫决策过程
智能体从感知到的初始环境 s0 开始,然后决定做一个相应的动作 a0 ,环境相应地发生改变到新的状态 s1 ,并反馈给智能体一个即时奖励 r1 ,然后智能体又根据状态 s1做一个动作a1,环境相应改变为s2,并反馈奖励 r2 .这样的交互可以一直进行下去.
智能体与环境的交互过程可以看作一个马尔可夫决策过程( Markov Deci-sion Process , MDP ).
马尔可夫决策过程在马尔可夫过程中加入一个额外的变量:动作 a,下一个时刻的状态 st+1 不但和当前时刻的状态 st 相关,而且和动作 at 相关.
14.1.3 强化学习的目标函数
总回报:给定策略 (a|s) ,智能体和环境一次交互过程的轨迹 所收到的累积奖励为总回报( Return )
目标函数:强化学习的目标是学习到一个策略 (a|s)来最大化期望回报( Expected Return ),即希望智能体执行一系列的动作来获得尽可能多的平均回报.
14.1.4 值函数
为了评估策略 的期望回报,我们定义两个值函数:状态值函数和状态 - 动作值函数.
- 状态值函数:表示从状态 s 开始,执行策略 得到的期望总回报.
- 状态 - 动作值函数(Q 函数):初始状态为 并进行动作 ,然后执行策略 得到的期望总回报.
值函数可以看作对策略 的评估,因此我们就可以根据值函数来优化策略.
14.1.5 深度强化学习
深度强化学习( DeepReinforcementLearning )是将强化学习和深度学习结合在一起,用强化学习来定义问题和优化目标,用深度学习来解决策略和值函数的建模问题,然后使用误差反向传播算法来优化目标函数.
14.2 基于值函数的学习方法
基于值函数的策略学习方法中最关键的是如何计算策略 的值函数,一般有动态规划或蒙特卡罗两种计算方式.
14.2.1 动态规划算法
这种模型已知的强化学习算法也称为基于模型的强化学习( Model-Based ReinforcementLearning )算法,这里的模型就是指马尔可夫决策过程.
在模型已知时,可以通过动态规划的方法来计算.常用的方法主要有策略迭代算法和值迭代算法.
策略迭代( Policy Iteration )算法中,每次迭代可以分为两步:
- 策略评估( Policy Evaluation ):计算当前策略下每个状态的值函数.
- 策略改进( Policy Improvement ):根据值函数来更新策略.
值迭代( Value Iteration )算法将策略评估和策略改进两个过程合并,来直接计算出最优策略.
基于模型的强化学习算法实际上是一种动态规划方法.在实际应用中有以下两点限制:
- 要求模型已知
- 效率问题
14.2.2 蒙特卡罗方法
模型未知,基于采样的学习算法也称为模型无关的强化学习( Model-Free Rein-forcement Learning )算法.
如果模型未知, Q 函数可以通过采样来进行计算,这就是蒙特卡罗方法.
为了平衡策略的利用和探索,我们可以采用 - 贪心法( -greedy Method ), - 贪心法将一个仅利用的策略转为带探索的策略.
- 采样与改进策略相同的强化学习方法叫作同策略( On-Policy )方法.
- 采样与改进分别使用不同策略的强化学习方法叫作异策略( Off-Policy )方法.
14.2.3 时序差分学习方法
蒙特卡罗方法一般需要拿到完整的轨迹,才能对策略进行评估并更新模型,因此效率也比较低.时序差分学习( Temporal-Difference Learning )方法是蒙特卡罗方法的一种改进,通过引入动态规划算法来提高学习效率 .时序差分学习方法是模拟一段轨迹,每行动一步 ( 或者几步 ) ,就利用贝尔曼方程来评估行动前状态的价值.
时序差分学习方法和蒙特卡罗方法的主要不同为:蒙特卡罗方法需要一条完整的路径才能知道其总回报,也不依赖马尔可夫性质;而时序差分学习方法只需要一步,其总回报需要通过马尔可夫性质来进行近似估计.
SARSA 算法 State Action Reward State Action , SARSA ) 是一种同策略算法.
Q 学习( Q-Learning )算法 是一种异策略的时序差分学习方法.
14.2.4 深度 Q 网络
Q学习中目标函数存在两个问题:
- 是目标不稳定,参数学习的目标依赖于参数本身;
- 是样本之间有很强的相关性.
为了解决这两个问题, 提出了一种深度 Q 网络( Deep Q-Networks , DQN ).深度 Q 网络采取两个措施:
- 一是目标网络冻结( Freezing Target Networks ),即在一个时间段内固定目标中的参数,来稳定学习目标;
- 二是经验回放( Experience Replay ),即构建一个经验池( Replay Buffer )来去除数据相关性.经验池是由智能体最近的经历组成的数据集.
14.3 基于策略函数的学习方法
强化学习的目标是学习到一个策略 (a|s) 来最大化期望回报.一种直接的方法是在策略空间直接搜索来得到最佳策略,称为策略搜索( Policy Search ).
策略搜索本质是一个优化问题,可以分为基于梯度的优化和无梯度优化.
策略梯度( Policy Gradient )是一种基于梯度的强化学习方法.
结合随机梯度上升算法,我们可以每次采集一条轨迹,计算每个时刻的梯度并更新参数,这称为 REINFORCE 算法.
REINFORCE 算法的一个主要缺点是不同路径之间的方差很大,导致训练不稳定,这是在高维空间中使用蒙特卡罗方法的通病.为了减少方差我们改进了该算法,引入了带基准线的 REINFORCE 算法.
14.4 演员 - 评论员算法
演员 - 评论员算法( Actor-Critic Algorithm )是一种结合策略梯度和时序差分学习的强化学习方法.
其中演员( Actor )是指策略函数 (a|s) ,即学习一个策略来得到尽量高的回报,评论员( Critic )是指值函数 V(s) ,
演员则跟据评论员的打分,调整自己的策略 ,争取下次做得更好.开始训练时,演员随机表演,评论员随机打分.通过不断的学习,评论员的评分越来越准,演员的动作越来越好.
虽然带基准线的 REINFORCE 算法也同时学习策略函数和值函数,但是它并不是一种演员 - 评论员算法.因为其中值函数只是用作基线函数以减少方差,并不用来估计回报(即评论员的角色).
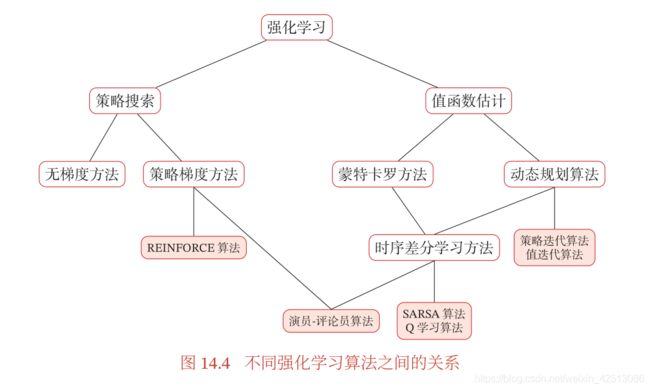
本文中不同算法之间的关系如图 14.4 所示.