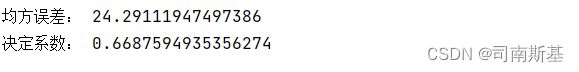使用线性回归模型预测波士顿房价
使用线性回归模型预测波士顿房价
本篇使用sklearn中自带的波士顿房价数据集,该数据集包含了506个样本和13个特征。通过数据预处理、训练模型、模型评估和结果可视化等步骤来完成。
加载数据集
首先,需要从sklearn中加载波士顿房价数据集。使用load_boston()函数来加载数据集,并将特征和标签分别赋值给变量X和y。
from sklearn.datasets import load_boston
# 加载数据集
boston = load_boston()
X = boston.data
y = boston.target
数据预处理
在训练模型之前,需要对数据进行预处理。在本例中,使用train_test_split()函数将数据集拆分为训练集和测试集。保留20%的数据作为测试集,并将剩余的80%用于训练模型。
from sklearn.model_selection import train_test_split
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
训练模型
使用LinearRegression()类创建一个新的线性回归模型,并使用fit()方法训练模型。
from sklearn.linear_model import LinearRegression
# 创建线性回归模型并训练
model = LinearRegression()
model.fit(X_train, y_train)
模型评估
在训练模型之后,需要对模型进行评估。使用mean_squared_error()函数计算均方误差,并使用score()方法计算模型的决定系数。
from sklearn.metrics import mean_squared_error
# 对测试集进行预测
y_pred = model.predict(X_test)
# 计算均方误差和决定系数
mse = mean_squared_error(y_test, y_pred)
r2 = model.score(X_test, y_test)
print("均方误差:", mse)
print("决定系数:", r2)
结果可视化
最后使用matplotlib库将模型的预测结果和真实值可视化。使用plot()函数绘制一条对角线,以便比较预测结果和真实值之间的差异。
import matplotlib.pyplot as plt
# 绘制预测结果和真实值的散点图
plt.plot([0, 50], [0, 50], '--k')
plt.scatter(y_test, y_pred)
plt.xlabel("True Values")
plt.ylabel("Predictions")
plt.show()
下面是完整的代码:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 加载数据集
boston = load_boston()
X = boston.data
y = boston.target
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型并训练
model = LinearRegression()
model.fit(X_train, y_train)
# 对测试集进行预测
y_pred = model.predict(X_test)
# 计算均方误差和决定系数
mse = mean_squared_error(y_test, y_pred)
r2 = model.score(X_test, y_test)
print("均方误差:", mse)
print("决定系数:", r2)
# 绘制预测结果和真实值的散点图
plt.plot([0, 50], [0, 50], '--k')
plt.scatter(y_test, y_pred)
plt.xlabel("True Values")
plt.ylabel("Predictions")
plt.show()
运行结果