【JavaEE初阶】 文件内容的读写 —— 数据流
文章目录
- 数据流的概念
-
- 数据流分类
- 字节流的读写
-
- InputStream(从文件中读取字节内容)
-
- 实例一
- 实例二
- 利用 Scanner 进行字符读取
- OutputStream(向文件中写内容)
-
- 实例一
- 实例二
- 实例三
- 字符流的读写
-
- Reader(读操作)
- Writer(写操作)
- 小程序练习
-
- ⚽练习一
- 练习二
- ⚾练习三
- ⭕总结
数据流的概念
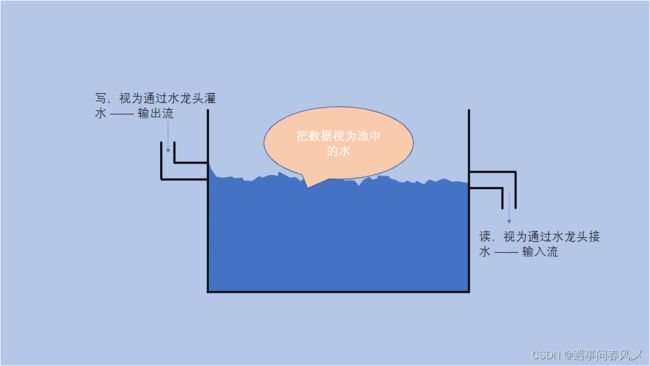
数据流是一串连续不断的数据的集合,就象水管里的水流,在水管的一端一点一点地供水,而在水管的另一端看到的是一股连续不断的水流。
数据写入程序可以是一段、一段地向数据流管道中写入数据,这些数据段会按先后顺序形成一个长的数据流。对数据读取程序来说,看不到数据流在写入时的分段情况,每次可以读取其中的任意长度的数据,但只能先读取前面的数据后,再读取后面的数据。
不管写入时是将数据分多次写入,还是作为一个整体一次写入,读取时的效果都是完全一样的。
“流是磁盘或其它外围设备中存储的数据的源点或终点。”
在电脑上的数据有三种存储方式,一种是外存,一种是内存,一种是缓存。比如电脑上的硬盘,磁盘,U盘等都是外存,在电脑上有内存条,缓存是在CPU里面的。外存的存储量最大,其次是内存,最后是缓存,但是外存的数据的读取最慢,其次是内存,缓存最快。这里总结从外存读取数据到内存以及将数据从内存写到外存中。
对于内存和外存的理解,我们可以简单的理解为容器,即外存是一个容器,内存又是另外一个容器。那又怎样把放在外存这个容器内的数据读取到内存这个容器以及怎么把内存这个容器里的数据存到外存中呢?
在Java类库中,IO部分的内容是很庞大的,因为它涉及的领域很广泛:
标准输入输出,文件的操作,网络上的数据流,字符串流,对象流,zip文件流等等,java中将输入输出抽象称为流,就好像水管,将两个容器连接起来。将数据冲外存中读取到内存中的称为输入流,将数据从内存写入外存中的称为输出流。
流是一个很形象的概念,当程序需要读取数据的时候,就会开启一个通向数据源的流,这个数据源可以是文件,内存,或是网络连接。类似的,当程序需要写入数据的时候,就会开启一个通向目的地的流。
总结的基本概念如下:
- 数据流:一组有序,有起点和终点的字节的数据序列。包括输入流和输出流。
- 输入流(Input Stream):程序从输入流读取数据源。数据源包括外界(键盘、文件、网络…),即是将数据源读入到程序的通信通道
- 输出流(Output Stream):程序向输出流写入数据。将程序中的数据输出到外界(显示器、打印机、文件、网络…)的通信通道。
采用数据流的目的就是使得输出输入独立于设备。Input Stream不关心数据源来自何种设备(键盘,文件,网络)Output Stream不关心数据的目的是何种设备(键盘,文件,网络)
数据流分类
流序列中的数据既可以是未经加工的原始二进制数据,也可以是经一定编码处理后符合某种格式规定的特定数据。因此Java中的流分为两种:
-
字节流:数据流中最小的数据单元是字节
-
字符流:数据流中最小的数据单元是字符, Java中的字符是Unicode编码,一个字符占用两个字节。
字节流的读写
InputStream(从文件中读取字节内容)
该类提供的方法有以下几种
| 修饰符及返回值类型 | 方法签名 | 说明 |
|---|---|---|
| int | read() | 读取一个字节的数据,返回 -1 代表已经完全读完了 |
| int | read(byte[] b) | 最多读取 b.length 字节的数据到 b 中,返回实际读到的数量;-1 代表以及读完了 |
| int | read(byte[] b,int off, int len) | 最多读取 len - off 字节的数据到 b 中,放在从 off 开始,返回实际读到的数量;-1 代表以及读完了 |
| void | close() | 关闭字节流 |
注意:InputStream 只是一个抽象类,要使用还需要具体的实现类。关于 InputStream 的实现类有很多,基本可以认为不同的输入设备都可以对应一个 InputStream 类,我们现在只关心从文件中读取,所以使用FileInputStream
FileInputStream 的 构造方法
| 签名 | 说明 |
|---|---|
| FileInputStream(File file) | 利用 File 构造文件输入流 |
| FileInputStream(String name) | 利用文件路径构造文件输入流 |
我们在使用该实例化对对象进行操作时我们该可以分为以下几步
-
打开文件
-
进行读写操作
-
关闭文件
但是这里我们需要注意的是,每一次打开文件都会消耗一些相应的资源,而每一个进程的资源时有限的,所以我们一定要注意关闭文件操作,但是关闭文件操作可能会因为某些情况忘记写,或者没执行到。这时候就会出现问题
这时候我们想到一个办法,使用final进行执行这一步操作
InputStream reader = new FileInputStream("D:/tmp.txt");
try {
//一系列读写操作
} finally {
reader.close();
}
但是这样写太繁琐,代码也不美观,所以Java里面提供了以下写法
try(InputStream reader = new FileInputStream("D:/tmp.txt")) {
// 一系列操作
}
这里虽然没有写会执行到close,但是在try执行结束后就会执行到;
这是因为该类实现了Closeable接口

实例一
首先我们准备一个文件内容和路径如下:
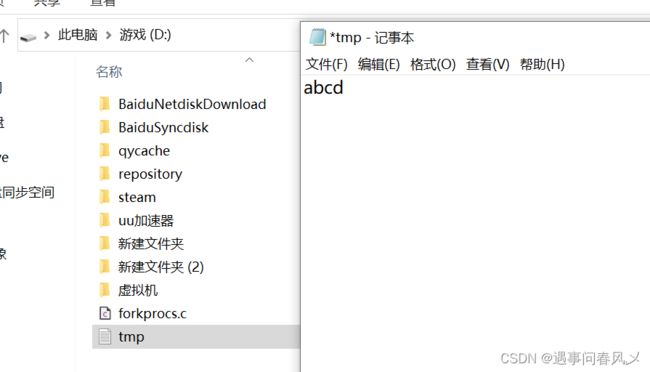
接下来展示两种文件读的方式
- 方式一:一个一个读
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream is = new FileInputStream("D:/tmp.txt")) {
while (true) {
int b = is.read();
if (b == -1) {
// 代表文件已经全部读完
break;
}
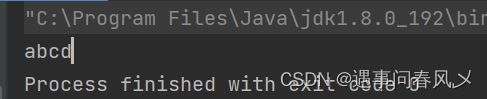
System.out.print((char)b + "");
}
}
}
}
结果如下:
- 方式二:缓冲区读法
先将一部分读取字节装入一个字节数组里,然后再读取数组里面的数据
代码如下:
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream is = new FileInputStream("D:/tmp.txt")) {
while (true) {
byte[] buffer = new byte[1024];
int b = is.read(buffer);
if (b == -1) {
// 代表文件已经全部读完
break;
}
for(int i = 0; i < b ; i ++) {
System.out.print((char) buffer[i] + "");
}
}
}
}
}
结果如下:

- 两种方式对比:
更推荐方式二,效率更高,就比如你练习网球发球,你需要不断的发球,一大筐网球放在体育教材室里面,你现在有两种做法,第一种一次:拿一个来发球,发完了,又回去拿,第二种:一次拿一筐放在脚边不断发球
很明显第二种效率更高,上述两种方式也是如此
实例二
这里我们把文件内容中填充中文看看,tmp.txt 中填写 “你好中国”

注意:写中文的时候使用 UTF-8 编码。如果强转为char会出现乱码问题。
我们使用16进制对结果进行输出时,就输出的是它们各自对应的 UTF-8 编码,如下所示:

三个字节表示一个字
这里我们就可以利用了这几个中文的 UTF-8 编码后长度刚好是 3 个字节和长度不超过 1024 字节的现状,但这种方式并不是通用的
代码如下:
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream is = new FileInputStream("D:/tmp.txt")) {
while (true) {
byte[] buffer = new byte[1024];
int b = is.read(buffer);
if (b == -1) {
// 代表文件已经全部读完
break;
}
// 每次使用 3 字节进行 utf-8 解码,得到中文字符
// 利用 String 中的构造方法完成
// 这个方法了解下即可,不是通用的解决办法
for (int i = 0; i < b; i += 3) {
String s = new String(buffer, i, 3, "UTF-8");
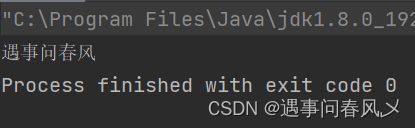
System.out.printf("%s", s);
}
}
}
}
}
结果入下:
利用 Scanner 进行字符读取
上述例子中,我们看到了对字符类型直接使用 InputStream 进行读取是非常麻烦且困难的,所以,我们使用一种我们之前比较熟悉的类来完成该工作,就是 Scanner 类
| 构造方法 | 说明 |
|---|---|
| Scanner(InputStream is, String charset) | 使用 charset 字符集进行 is 的扫描读取 |
代码实现如下:
import java.io.*;
import java.util.Scanner;
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream is = new FileInputStream("d:/tmp.txt")) {
try (Scanner scanner = new Scanner(is, "UTF-8")) {
while (scanner.hasNext()) {
String s = scanner.next();
System.out.print(s);
}
}
}
}
}
结果如下:
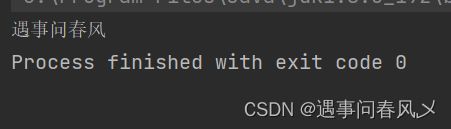
OutputStream(向文件中写内容)
该类的方法有:
| 修饰符及返回值类型 | 方法签名 | 说明 |
|---|---|---|
| void | write(int b) | 写入要给字节的数据 |
| void | write(byte[]b) | 将 b 这个字符数组中的数据全部写入 os 中 |
| int | write(byte[]b, int off,int len) | 将 b 这个字符数组中从 off 开始的数据写入 os 中,一共写 len 个 |
| void | close() | 关闭字节流 |
| void | flush() | 重要:我们知道 I/O 的速度是很慢的,所以,大多的 OutputStream 为了减少设备操作的次数,在写数据的时候都会将数据先暂时写入内存的一个指定区域里,直到该区域满了或者其他指定条件时才真正将数据写入设备中,这个区域一般称为缓冲区。但造成一个结果,就是我们写的数据,很可能会遗留一部分在缓冲区中。需要在最后或者合适的位置,调用 flush(刷新)操作,将数据刷到设备中 |
OutputStream 同样只是一个抽象类,要使用还需要具体的实现类。我们现在还是只关心写入文件中,所以使用 FileOutputStream,构造方法与上述FileInputStream构造方法一样的,与实现都是一样的,这里就不做过多诠释
接下来简单展示一下几个实例
我们先准备该路径下的该文件
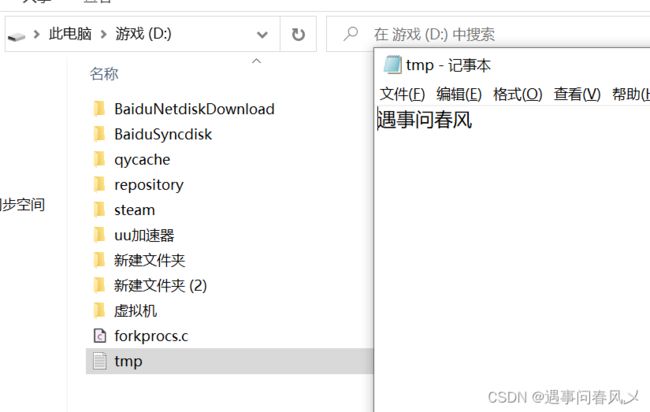
实例一
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class IODemo1 {
public static void main(String[] args) {
try(OutputStream writ = new FileOutputStream("D:/tmp.txt")) {
writ.write('A');
writ.write('B');
writ.write('C');
writ.write('D');
writ.write('E');
writ.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
结果如下:
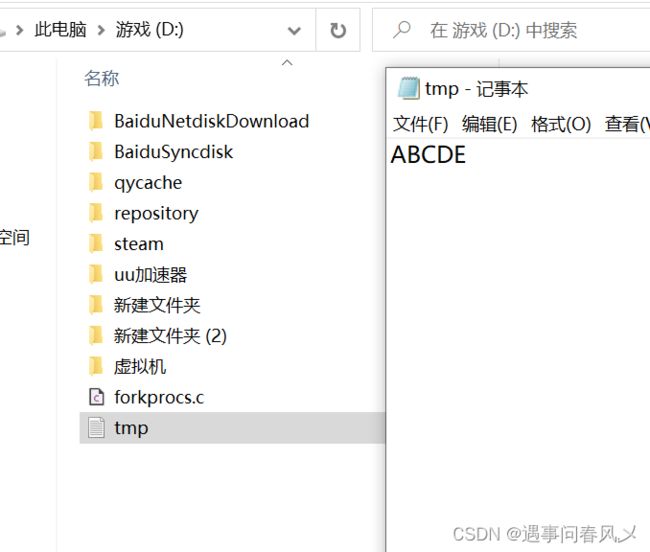
注意:此处的write操作会先清除该文件里面的内容再进行填充
那么如何才能不清除文件而实现续写呢?其实很简单,我们只需要在构造对象时,使用带有true参数的构造方法就好
比如以下代码对上述文件进行续写操作
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class IODemo1 {
public static void main(String[] args) {
try(OutputStream writ = new FileOutputStream("D:/tmp.txt",true)) {
writ.write('F');
writ.write('F');
writ.write('F');
writ.write('F');
writ.write('F');
writ.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
结果如下:

最后注意一点:
- 我们在写操作完成后,一定要flush冲刷一下,也就是刷新一下
实例二
使用字符数组
- 代码一
import java.io.*;
public class IOdemo2 {
public static void main(String[] args) throws FileNotFoundException {
try (OutputStream os = new FileOutputStream("output.txt")) {
byte[] b = new byte[] {
(byte)'G', (byte)'o', (byte)'o', (byte)'d'
};
os.write(b);
// 不要忘记 flush
os.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
- 代码二
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (OutputStream os = new FileOutputStream("output.txt")) {
byte[] b = new byte[] {
(byte)'G', (byte)'o', (byte)'o', (byte)'d', (byte)'B',
(byte)'a', (byte)'d'
};
os.write(b, 0, 4);
// 不要忘记 flush
os.flush();
}
}
}
- 代码三
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (OutputStream os = new FileOutputStream("output.txt")) {
String s = "Nothing";
byte[] b = s.getBytes();
os.write(b);
// 不要忘记 flush
os.flush();
}
}
}
这里就不展示结果了
实例三
写入汉字
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (OutputStream os = new FileOutputStream("output.txt")) {
String s = "遇事问春风";
byte[] b = s.getBytes("utf-8");
os.write(b);
// 不要忘记 flush
os.flush();
}
}
}
结果如下:

字符流的读写
字符流的操作比字节流操作更加简单,而且方法类似,下面只是简单展示一下基本用法。不做过多赘述
Reader(读操作)
这里是需要实例化一个 FileReader进行操作,可使用的方法参考字节流
这里的字符流操作与字节流操作类似,这里不做过多赘述,直接看代码
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class IODemo3 {
public static void main(String[] args) {
try(Reader reader = new FileReader("D:/tmp.txt")) {
while(true) {
int n = reader.read();
if(n == -1) {
break;
}
System.out.print((char)n + "");
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
结果如下:
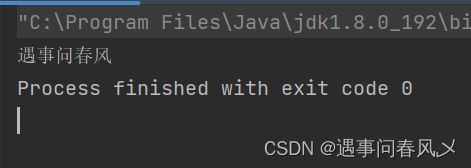
再来一个数组版本的吧
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class IODemo3 {
public static void main(String[] args) {
char[] arr = new char[1024];
try(Reader reader = new FileReader("D:/tmp.txt")) {
while(true) {
int n = reader.read(arr);
if(n == -1) {
break;
}
for(int i = 0; i < n ; i ++) {
System.out.print(arr[i] + "");
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
结果如下:
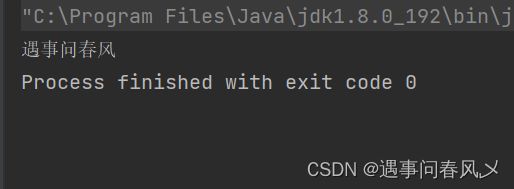
Writer(写操作)
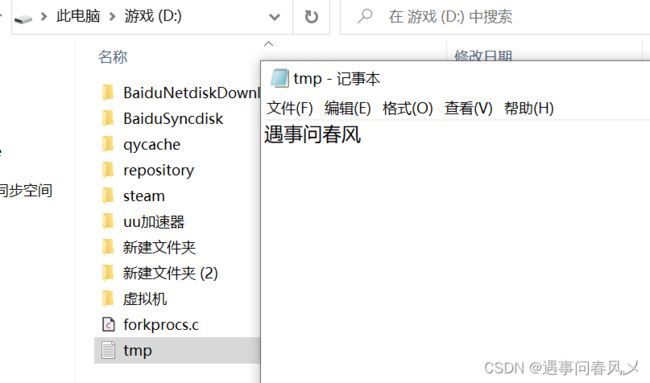
准备文件路径内容如下:
实例代码如下:
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class IODemo4 {
public static void main(String[] args) {
try(Writer writ = new FileWriter("D:/tmp.txt")) {
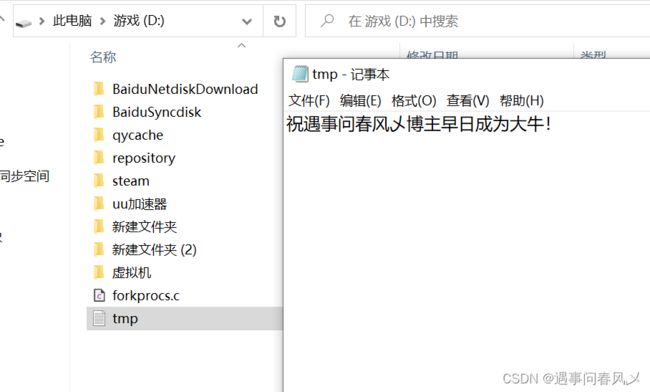
writ.write("祝遇事问春风乄博主早日成为大牛!");
writ.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
结果展示如下:
小程序练习
这里不做过多赘述,只展示代码,有需要讲解的小伙伴可以私信博主
⚽练习一
扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要
删除该文件
import java.io.*;
import java.util.*;
public class Test1 {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.print("请输入要扫描的根目录(绝对路径 OR 相对路径): ");
String rootDirPath = scanner.next();
File rootDir = new File(rootDirPath);
if (!rootDir.isDirectory()) {
System.out.println("您输入的根目录不存在或者不是目录,退出");
return;
}
System.out.print("请输入要找出的文件名中的字符: ");
String token = scanner.next();
List<File> result = new ArrayList<>();
// 因为文件系统是树形结构,所以我们使用深度优先遍历(递归)完成遍历
scanDir(rootDir, token, result);
System.out.println("共找到了符合条件的文件 " + result.size() + " 个,它们分别是");
for (File file : result) {
System.out.println(file.getCanonicalPath() + " 请问您是否要删除该文件?y/n");
String in = scanner.next();
if (in.toLowerCase().equals("y")) {
file.delete();
}
}
}
private static void scanDir(File rootDir, String token, List<File> result) {
File[] files = rootDir.listFiles();
if (files == null || files.length == 0) {
return;
}
for (File file : files) {
if (file.isDirectory()) {
scanDir(file, token, result);
} else {
if (file.getName().contains(token)) {
result.add(file.getAbsoluteFile());
}
}
}
}
}
练习二
进行普通文件的复制
import java.io.*;
import java.util.*;
public class Test2 {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.print("请输入要复制的文件(绝对路径 OR 相对路径): ");
String sourcePath = scanner.next();
File sourceFile = new File(sourcePath);
if (!sourceFile.exists()) {
System.out.println("文件不存在,请确认路径是否正确");
return;
}
if (!sourceFile.isFile()) {
System.out.println("文件不是普通文件,请确认路径是否正确");
return;
}
System.out.print("请输入要复制到的目标路径(绝对路径 OR 相对路径): ");
String destPath = scanner.next();
File destFile = new File(destPath);
if (destFile.exists()) {
if (destFile.isDirectory()) {
System.out.println("目标路径已经存在,并且是一个目录,请确认路径是否正确");
return;
}
if (destFile.isFile()) {
System.out.println("目录路径已经存在,是否要进行覆盖?y/n");
String ans = scanner.next();
if (!ans.toLowerCase().equals("y")) {
System.out.println("停止复制");
return;
}
}
}
try (InputStream is = new FileInputStream(sourceFile)) {
try (OutputStream os = new FileOutputStream(destFile)) {
byte[] buf = new byte[1024];
int len;
while (true) {
len = is.read(buf);
if (len == -1) {
break;
}
os.write(buf, 0, len);
}
os.flush();
}
}
System.out.println("复制已完成");
}
}
注意:此处复制时,只需要源文件存在就行,目的文件如果不存在,目的文件路径下会自动创建一个文件
⚾练习三
扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
注意:我们现在的方案性能较差,所以尽量不要在太复杂的目录下或者大文件下实验
import java.io.*;
import java.util.*;
public class Test3 {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.print("请输入要扫描的根目录(绝对路径 OR 相对路径): ");
String rootDirPath = scanner.next();
File rootDir = new File(rootDirPath);
if (!rootDir.isDirectory()) {
System.out.println("您输入的根目录不存在或者不是目录,退出");
return;
}
System.out.print("请输入要找出的文件名中的字符: ");
String token = scanner.next();
List<File> result = new ArrayList<>();
// 因为文件系统是树形结构,所以我们使用深度优先遍历(递归)完成遍历
scanDirWithContent(rootDir, token, result);
System.out.println("共找到了符合条件的文件 " + result.size() + " 个,它们分别是");
for (File file : result) {
System.out.println(file.getCanonicalPath());
}
}
private static void scanDirWithContent(File rootDir, String token,
List<File> result) throws IOException {
File[] files = rootDir.listFiles();
if (files == null || files.length == 0) {
return;
}
for (File file : files) {
if (file.isDirectory()) {
scanDirWithContent(file, token, result);
} else {
if (isContentContains(file, token)) {
result.add(file.getAbsoluteFile());
}
}
}
}
// 我们全部按照utf-8的字符文件来处理
private static boolean isContentContains(File file, String token) throws
IOException {
StringBuilder sb = new StringBuilder();
try (InputStream is = new FileInputStream(file)) {
try (Scanner scanner = new Scanner(is, "UTF-8")) {
while (scanner.hasNextLine()) {
sb.append(scanner.nextLine());
sb.append("\r\n");
}
}
}
return sb.indexOf(token) != -1;
}
}
⭕总结
关于《【JavaEE初阶】 文件内容的读写 —— 数据流》就讲解到这儿,感谢大家的支持,欢迎各位留言交流以及批评指正,如果文章对您有帮助或者觉得作者写的还不错可以点一下关注,点赞,收藏支持一下!