PointNet 论文阅读
论文链接
PointNet
Abstract
- 对于点云问题,由于其格式不规则,大多数研究人员将此类数据转换为规则的 3D 体素网格或图像集合。然而,这会导致数据不必要地庞大并导致问题
- 在本文中,我们设计了一种直接消耗点云的新型神经网络,它很好地尊重了输入中点的排列不变性。我们的网络名为 PointNet,为从对象分类、部分分割到场景语义解析等应用提供了统一的架构。
Intro
提出PointNet的原因
由于点云或网格不采用常规格式,因此大多数研究人员通常将此类数据转换为常规 3D 体素网格或图像集合(例如视图),然后再将其输入深度网络架构。这种数据表示转换使生成的数据变得不必要地庞大,同时还引入了可能掩盖数据自然不变性的量化伪影。
简述PointNet怎么做的
将点云作为输入并输出整个输入的类标签或输入的每个点的每个点段/部分标签。关键使用单个对称函数——最大池化
- 网络学习一组优化函数/标准,用于选择点云中有趣或信息丰富的点,并对它们选择的原因进行编码。
- 最终全连接层将这些学习到的最佳值聚合到整个形状的全局描述符中,用于形状分类或用于预测每个点标签(形状分割)
- 我们的输入格式很容易应用刚性或仿射变换,因为每个点都是独立变换的
文章主要贡献
- 设计了一种新颖的深度网络架构,适合使用三维的无序点集
- 展示了如何训练这样的网络来执行 3D 形状分类、形状部分分割和场景语义解析任务
- 对方法的稳定性和效率提供全面的实证和理论分析
- 展示了网络中选定神经元计算的 3D 特征,并对其性能进行了直观的解释。
Related Work
点云特征
-
大多数点云特征都是针对特定任务进行设计的
-
点特征通常对点的某些统计属性进行编码,并被设计为对某些变换不变,这些变换通常被分类为内在或外在两种,
或者也可以分为局部特征和全局特征
基于三维数据的深度学习
- 基于容积的卷积神经网络(Volumetric CNNs)—— 容积表示受到数据稀疏性和三维卷积的计算成本的限制
- FPNN 和Vote3D 提出了解决稀疏问题的特殊方法 —— 操作仍然在稀疏体积上,对于处理非常大的点云来说是具有挑战性
- 多视角CNNs(Multiview CNNs)—— 扩展到场景理解或其他三维任务(如点分类和形状补全)非常困难
- 谱卷积神经网络(Spectral CNNs)—— 仅限于类似有机物的流形网格,如何将其扩展到非等度形状(如家具)并不明显
- 基于特征的深度神经网络(Feature-based DNNs)—— 受到提取特征的表示能力的限制
在无序数据集上的深度学习
从数据结构的角度来看,点云是一个无序向量集合。点集上进行的深度学习工作并不多。
Problem Statement
输入:无序数据点集, P i = ( x , y , z ∣ 颜色,法线等 ) P_i=(x,y,z|颜色,法线等) Pi=(x,y,z∣颜色,法线等)
目标分类任务:深度网络为所有k个候选类别输出k个得分
语义分割任务:输入可以是单个目标用于部分区域分割,或者是从3D场景中的子体积用于目标区域分割
模型会为每个n个点和每个m个语义子类别输出n×m个得分
Deep Learning on Point Sets
R n \mathbb {R}^n Rn 点集性质
- 点云是一组没有特定顺序的点
- 点不是孤立的,相邻点形成一个有意义的子集。模型需要能够捕获附近点的局部结构,以及局部结构之间的组合相互作用
- 作为一个几何对象,学习到的点集表示对于某些变换应该是不变的
PointNet 架构
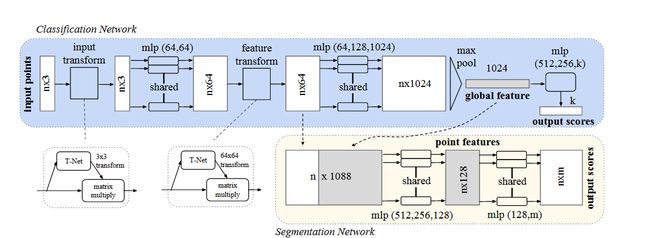
如上图所示。分类网络以n个点作为输入,应用输入和特征变换,然后通过最大池化聚合点特征。输出是 k 个类别的分类分数。分割网络是分类网络的扩展。它连接全局和局部特征并输出每点分数。 “mlp”代表多层感知器,括号中的数字是层大小。 Batchnorm 用于 ReLU 的所有层。 Dropout 层用于分类网络中的最后一个 MLP
三个关键模块
- 最大池化层作为对称函数来聚合来自所有点的信息,局部和全局信息组合结构
- 两个对齐输入点和点特征的联合对齐网络
无序输入的对称函数
目的:使模型输入排列不变
策略:
-
将输入排序成规范顺序
-
将输入视为训练 RNN 的序列,通过排列来扩充数据
-
通过对称函数来聚合每个点的信息
对称函数 - 输入:n 个向量 - 输出:一个与输入阶数无关的新向量
不足:
- 在高维空间中实际上不存在稳定的排序,因此,排序并不能完全解决排序问题,并且由于排序问题仍然存在,网络很难学习从输入到输出的一致映射
- 虽然 RNN 对于小长度(数十个)序列的输入排序具有相对较好的鲁棒性,但很难扩展到数千个输入元素,这是点集的常见大小
解决方案:
对集合中的变换元素应用对称函数来近似定义在点集上的通用函数
f ( { x 1 , . . . , x n } ) ≈ g ( ( h ( x 1 ) , . . . , h ( x n ) ) f : 2 R N → R , h : R N → R K , g : R K × . . . × R K ⏟ n → R f(\{x_1,...,x_n\})\approx g((h(x_1),...,h(x_n)) \\\\ f:2^{\mathbb{R}^N}\rightarrow \mathbb{R},\ \ h:\mathbb{R}^N\rightarrow\mathbb{R}^K,\ \ g:\underbrace{\mathbb{R}^K \times...\times \mathbb{R}^K}_{n} \rightarrow \mathbb{R} f({x1,...,xn})≈g((h(x1),...,h(xn))f:2RN→R, h:RN→RK, g:n RK×...×RK→R
实验证实:通过多层感知器网络来近似 h,通过单变量函数和最大池函数的组合来近似 g
局部与全局信息融合
原因:
无序输入对称函数的输出形成一个向量 [ f 1 , . . , f K ] [f_1,..,f_K] [f1,..,fK],在形状全局特征上训练 SVM 或多层感知器分类器以进行分类,但点分割需要局部和全局知识的结合
解决方案:

- 计算全局点云特征向量后,我们通过将全局特征与每个点特征连接起来将其反馈给每个点特征
- 根据组合的点特征提取新的每点特征
联合对准网络
**原因:**如果点云经历某些几何变换(例如刚性变换),则点云的语义标记必须保持不变
方案:
- 通过迷你网络(T-net)预测仿射变换矩阵,并将该变换直接应用于输入点的坐标(迷你网络本身类似于大网络,由点无关特征提取、最大池化和全连接层等基本模块组成)

将该想法扩展到特征空间的对齐
-
在点特征上插入另一个对齐网络并预测特征转换矩阵以对齐来自不同输入点云的特征
-
在 softmax 训练损失中添加了一个正则化项,将特征变换矩阵限制为接近正交矩阵
L r e g = ∣ ∣ I − A A T ∣ ∣ F 2 L_{reg}=||I-AA^T||^2_F Lreg=∣∣I−AAT∣∣F2
A 是迷你网络预测的特征对齐矩阵,正交变换不会丢失输入中的信息,因此是理想的
理论分析
普遍逼近
假设 f : X → R f: \Chi \rightarrow \mathbb{R} f:X→R 是一个关于 Hausdorff 距离 d H ( ⋅ , ⋅ ) d_H(\cdot , \cdot) dH(⋅,⋅) 的连续集合函数,则 ∀ ϵ > 0 \forall \epsilon > 0 ∀ϵ>0 都存在一个连续函数 h 和对称函数 g ( x 1 , . . . , x n ) = γ ∘ M A X g(x_1,...,x_n)=\gamma \circ MAX g(x1,...,xn)=γ∘MAX,对于任意的 S ∈ X S\in \Chi S∈X 都有下式成立
∣ f ( S ) − γ ( M A X x i ∈ S { h ( x i ) } ) ∣ < ϵ |f(S)-\gamma(\underset {x_i \in S}{MAX}\{h(x_i)\})|<\epsilon ∣f(S)−γ(xi∈SMAX{h(xi)})∣<ϵ
它将 n 个向量作为输入并返回元素级最大值的新向量。关键思想是,在最坏的情况下,网络可以通过将空间划分为大小相等的体素来学习将点云转换为体积表示
瓶颈维度和稳定性
从理论上和实验上我们发现我们网络的表达能力受到最大池化层的维度的强烈影响。
令 u = M A X x i ∈ S { h ( x i ) } u=\underset {x_i \in S}{MAX}\{h(x_i)\} u=xi∈SMAX{h(xi)} , f = γ ∘ u f=\gamma\circ u f=γ∘u,则有
a ) ∀ S , ∃ C S , N S ⊆ X , f ( T ) = f ( S ) i f C S ⊆ T ⊆ N S b ) ∣ C S ∣ ≤ K \begin{aligned} &a) \forall S,\exist C_S,N_S \subseteq \Chi,f(T)=f(S)\ \ \ \ \ if\ C_S\subseteq T\subseteq N_S \\\\ &b)|C_S|\leq K \end{aligned} a)∀S,∃CS,NS⊆X,f(T)=f(S) if CS⊆T⊆NSb)∣CS∣≤K
- 表示如果 C S C_S CS 中的所有点都被保留,则 f ( S ) f (S) f(S) 在输入损坏之前保持不变;对于高达 N S N_S NS 的额外噪声点,它也保持不变。
- 表示 C S C_S CS 仅包含有限数量的点,由 K 确定。换句话说, f ( S ) f(S) f(S) 实际上完全由小于或等于K个元素的有限子集 C S ⊆ S C_S ⊆ S CS⊆S 决定
将 C S C_S CS 称为 S 的临界点集,将 K 称为 f 的瓶颈维度。
Experiment
应用领域
3D 目标分类
-
在 ModelNet40 形状分类基准上评估我们的模型。有来自 40 个人造物体类别的 12,311 个 CAD 模型,分为 9,843 个用于训练和 2,468 个用于测试。

-
我们的模型在基于 3D 输入(体积和点云)的方法中实现了最先进的性能。仅通过全连接层和最大池化,我们的网络在推理速度方面取得了领先优势,并且也可以轻松地在 CPU 中并行化。我们的方法和基于多视图的方法(MVCNN)之间仍然存在很小的差距,我们认为这是由于渲染图像可以捕获的精细几何细节的丢失造成的。
3D 对象部分分割
-
部分分割是一项具有挑战性的细粒度 3D 识别任务。给定 3D 扫描或网格模型,任务是将零件类别标签(例如椅子腿、杯子手柄)分配给每个点或面
-
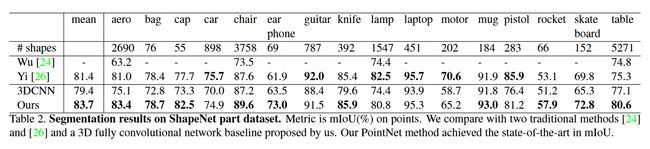
我们对ShapeNet 零件数据集进行评估,该数据集包含来自 16 个类别的 16,881 个形状,总共注释了 50 个零件
-
评估指标是点上的 mIoU。对于类别 C 的每个形状 S,计算形状的 mIoU
-
我们观察到平均 IoU 提高了 2.3%,并且我们的网络在大多数类别中都优于基线方法
-
测试这些方法的稳健性,仅损失了 5.3% 的平均 IoU
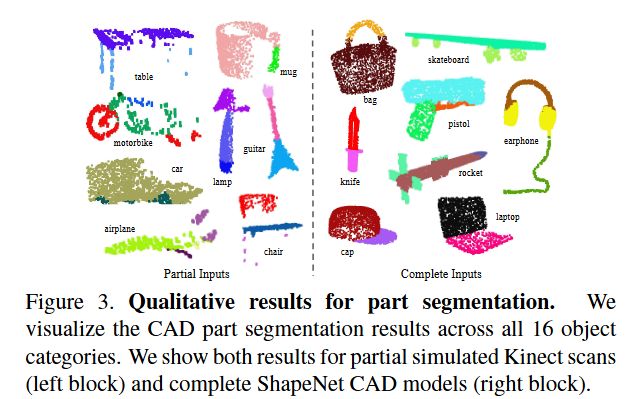
场景中的语义分割
-
部分分割网络可以轻松扩展到语义场景分割,其中点标签成为语义对象类而不是对象部分标签。
-
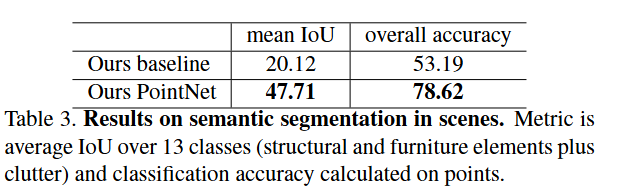
在斯坦福 3D 语义解析数据集上进行实验。该数据集包含 Matterport 扫描仪对 6 个区域(包括 271 个房间)的 3D 扫描结果。扫描中的每个点都用来自 13 个类别(椅子、桌子、地板、墙壁等以及杂乱)的语义标签之一进行注释

架构设计分析
与其他顺序不变方法的比较

- 我们比较的基线(如图 5 所示)包括将未排序和排序点作为 n×3 数组的多层感知器、将输入点视为序列的 RNN 模型以及基于对称函数的模型
- 本文实验的对称操作包括最大池化、平均池化和基于注意力的加权和
- 从每个点特征预测标量分数,然后通过计算 softmax 跨点对分数进行归一化。然后根据归一化分数和点特征计算加权和
输入和特征转换的有效性

- 最基本的架构已经取得了相当合理的结果。使用输入转换可将性能提升 0.8%
鲁棒性测试
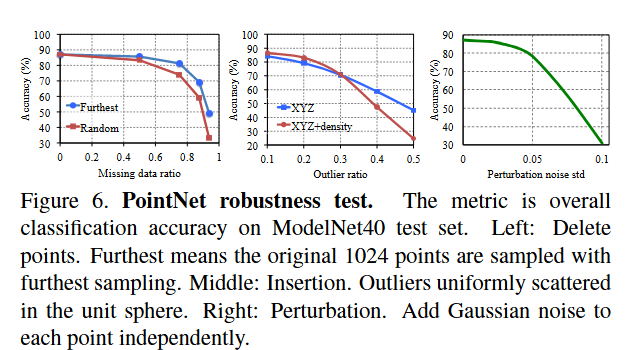
- 我们使用与图 5 的最大池化网络相同的架构。输入点被标准化为单位球体
- 当缺失 50% 的点时,准确率仅下降 2.4% 和 3.8%
- 如果网络在训练期间发现了异常点,那么它对异常点也具有鲁棒性
- 评估两种模型:一种在具有 (x, y, z) 坐标的点上进行训练;另一种在具有 (x, y, z) 坐标的点上进行训练加上点密度