selenium安装配置
Python安装
-
selenium客户端库
# win pip install selenium # mac sudo pip3 install selenium-
验证是否安装成功
控制台输入命令pip list查看列表中是否存在selenium,如果有,则说明安装成功。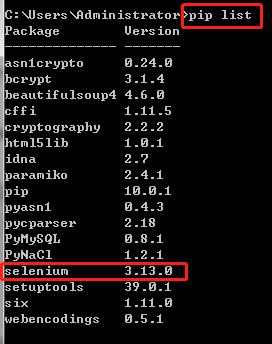 image
image
-
-
谷歌浏览器驱动chromedriver
notes.txt文件可以查看对应的chrome版本- 下载地址1-官网
- 下载地址2-第三方
- 确保浏览器版本和驱动版本相对应相关版本查看方法
引自WeiFong
-
将浏览器驱动文件(chromedriver.exe)放到环境变量中配置的路径内
- 如果不放入环境变量,则每次使用时需填写浏览器驱动文件所在的路径
- 必须为系统的环境变量,临时设置的环境变量无效
- 快速设置:mac 可以把浏览器驱动文件放到
/usr/local/bin下 - 快速设置:win 可以把浏览器驱动文件放到
C:\Windows下
# 在系统环境变量中 from selenium import webdriver # driver = webdriver.Chrome(chromedriver) driver = webdriver.Chrome() driver.get('https://www.baidu.com/') # 不在系统环境变量中 from selenium import webdriver test = r'E:/python/chromedriver' driver = webdriver.Chrome(test) driver.get('https://www.baidu.com/') -
补充:安装三大浏览器驱动(driver)
- chromedriver 下载地址:参考第三点
# 启动谷歌浏览器 from selenium import webdriver browser = webdriver.Chrome() browser.get('http://www.baidu.com/')- Firefox的驱动geckodriver 下载地址:https://github.com/mozilla/geckodriver/releases/
# 启动火狐浏览器 from selenium import webdriver browser = webdriver.Firefox() browser.get('http://www.baidu.com/')- IE的驱动IEdriver 下载地址:http://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
# 启动IE浏览器 from selenium import webdriver browser = webdriver.Ie() browser.get('http://www.baidu.com/') -
简单操作方法
- 导入
from selenium import webdriver - 打开浏览器
driver = webdriver.Chrome() - get方法打开指定网址
driver.get('https://www.baidu.com/') - 通过id获取元素
element_keyword = find_element_by_id('kw') - 对输入框输入文字内容
element_keyword.send_keys('松勤') - 对按钮进行点击
element_search_button.click() - 获取某个元素的内容
one_yuansu.text - 关闭浏览器
driver.quit() - 设置浏览器固定宽、高
driver.set_window_size(480,800) - 控制浏览器前进、后退:前进
driver.forward()后退driver.back() - 示例如下:
from selenium import webdriver driver = webdriver.Chrome() #get方法打开指定网址 driver.get('https://www.baidu.com/') # 查找到那个搜索输入栏网页元素,返回一个表示该元素到WebElement对象 element_keyword = driver.find_element_by_id('kw') # 输入字符 element_keyword.send_keys('测试') # 找到搜素按钮 element_search_button = driver.find_element_by_id('su') # 点击该按钮 element_search_button.click() import time time.sleep(2)# 设置等待时间 ret = driver.find_element_by_id('1') # 获取第一条信息 print(ret.text) # if ret.text.startswith('松勤'): # print('测试通过') # else: # print('测试不通过') # 退出(关闭浏览器) driver.quit() # 控制台输出效果 测试_百度百科 测试英文名Test、Measure;中文拼音cè shì;由中文“测”与中文“试”两个字组成的词语。是动词、名词。测试行为,一般发生于为检测特定的目标是否符合标准而采用专用的工具或... 词语 综合式测试 心理测试 baike.baidu.com/ - 导入
元素选择之常规方法
Selenium 选择、操作web元素01
Selenium 自动化主要就是:
- 选择界面元素
依靠selenium库难点 - 操作界面元素
依靠selenium库- 输入操作:点击、输入文字、拖拽等
- 输出操作:获取元素的各种属性
- 根据界面上获取的数据进行分析和处理
依靠编程语言,例如Python等难点
选择元素
- WebDriver:操作整个浏览器和当前整个页面
- 当前页面上的选择符合查找条件的对象
- 打开网址,回退,前进,刷新网页
- 获取、改变浏览器窗口大小,关闭浏览器,截屏
- 获取、设置cookies
- WebElement:操作和对应web元素
- 当前web元素的所有子元素里面符合查找条件的对象
- 操作该web元素,比如
- 点击元素
- 输入字符
- 获取元素坐标、尺寸、文本内容、其他的属性信息
通过id选择元素
-
id是DOM中唯一标志这个元素的属性
- 查找效率高
- 写法一:
element = driver.find_element_by_id("kw") - 写法二:
from selenium.webdriver.common.by import By element = driver.find_element(by=By.ID,value="kw") 没有找到id时将报错
selenium.common.exceptions.NoSuchElementException-
没有id时,可以通过根据上层的id,然后获取内部的源代码,然后找到相关信息(str)
当开发做一定的变动时,此方法就失效了
没有id时,使用BeautifulSoup4
详见后续内容
获取元素信息
text属性
显示该元素在web页面显示出来的文本内容-
get_attribute方法
非界面值- 某个属性的值
ele.get_attribute('href') - 该元素对应的html源代码
ele.get_attribute('outerHTML')
出现问题时,将相关源代码打印到日志里,以便快速定位问题
- 该元素的内部部分的html源代码
ele.get_attribute('innerHTML')
- 某个属性的值
Selenium 选择、操作web元素02
选择元素的方法
通过name选择元素 id是唯一的,name不一定是唯一的
- 返回第一个找到的元素
如果找不到,抛出异常
# 方法一:
cheese = driver.find_element_by_name('cheese')
# 方法二:
from selenium.webdriver.common.by import By
cheeses = driver.find_emement(By.NAME,'cheese')
# 示例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(r'file:///E:/Python/tmp/own/test.html')
button = driver.find_element_by_name('button')
print(button.text)
# 执行结果
按钮01
#找不到时
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(r'file:///E:/Python/tmp/own/test.html')
try:
button = driver.find_element_by_name('button4')
print(button.text)
except:
print('未找到')
# 执行结果
未找到
- 返回所有的元素(list)
如果找不到,返回空列表,不抛出异常
# 方法一:
cheese = driver.find_elements_by_name('cheese')
# 方法二:
from selenium.webdriver.common.by import By
cheeses = driver.find_emements(By.NAME,'cheese')
# 示例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(r'file:///E:/Python/tmp/own/test.html')
button = driver.find_elements_by_name('button')
for a in button:
print(a.text)
# 执行结果
按钮01
按钮02
按钮03
通过class选择元素非唯一值,通常用来选择多个元素
- 返回所有的元素(list)
cheeses = driver.find_elements_by_class_name('cheese')
通过tag名选择元素
- 如果tag名是唯一的,可以根据tag名定位
- 如果tag名不是唯一的,返回到是第一个
frame = driver.find_element_by_tag_name('iframe')
通过链接文本选择元素
- 对于链接,可以通过其链接文本的内容
转到百度
ele = driver.find.element_by_link_text("转到百度")
- 只通过部分文本去找到该链接元素
适用于文本内容过长时
ele = driver.find.element_by_partial_link_text(u"百度") # 此处可以不写u,python2中此处的“u”必写
页面操作(补充)
学习地址
查找时间
- 每半秒查找一次,直到10秒后
driver.implicitly_wait((10)) - 强制睡眠10秒
import time
time.sleep(10)
模拟回车键enter的操作
- 使用
\n方法
from selenium.webdriver.common.keys import Keys
driver.find_element_by_id('toStationText').send_keys('杭州东\n')
- 使用enter方法
from selenium.webdriver.common.keys import Keys
driver.find_element_by_id('toStationText').send_keys('杭州东')
driver.find_element_by_id('toStationText').send_keys(Keys.ENTER) # 模拟键盘enter
页面交互
WebDriver提供了各种方法来寻找元素。例如下面有一个表单输入框。
element = driver.find_element_by_id("passwd-id")
element = driver.find_element_by_name("passwd")
element = driver.find_elements_by_tag_name("input")
element = driver.find_element_by_xpath("//input[@id='passwd-id']")
获取了元素之后,下一步当然就是向文本输入内容了,可以利用下面的方法
element.send_keys("some text")
同样你还可以利用 Keys 这个类来模拟点击某个按键
element.send_keys("and some", Keys.ARROW_DOWN)
可以用下面的方法来清除输入文本的内容。
element.clear()
填充表单
元素选择之BeautifulSoup4
BeautifulSoup4
BS是可以从HTML或XML文件中提取数据的库
Selenium可以用来远程获取数据
有的时候,感觉用Selenium获取某些元素数据不太方便
可以将其父节点的html获取回来,利用BS在本地做分析
我们可以将它和selenium两种技术融合使用,达到我们的目的
-
安装BeautifulSoup4
pip install beautifulsoup4 # pip install beautifulsoup4 -i https://pypi.douban.com/simple/ pip install html5lib -
常见用法(详见示例内的代码及注释)
- 示例及具体方法
# 本例采用的是本地的html with open ('test.html',encoding = 'utf8') as f : html_doc = f.read() # 导入beautifulsoup from bs4 import BeautifulSoup # 指定html5lib来解析html文档 soup = BeautifulSoup(html_doc,'html5lib') print(soup.title) # 获取标签整体内容 print(soup.p)# 有多个时,获取的是第一个 print(soup.title.name) # 获取标签名称 print(soup.title.string) # 获取点前节点标签的内容 print(soup.title.get_text()) # 获取当前节点及子节点的所有内容 print(soup.body.get_text("|")) # 获取当前节点及子节点的所有内容,以|分隔每个节点的内容 print(soup.title.parent)# 获取当前节点及父节点的内容 print(soup.body['style']) # 获取属性值 print(soup.body.get('style')) # 获取属性值 # 有多个标签想获取非第一个 # 方法一;先返回所有的,在根据下标查找 print(soup.find_all('p')) #返回的是一个列表所以可以使用列表获取元素的方法 print(soup.find_all('p')[1]) # 根据下标获取第二个 # 方法二:根据属性找 print(soup.find_all('p',id='b')) # 根据id获取第二个 # 执行结果测试 第一个p
title 测试 测试 | 标题1 | | 标题2 | |第一个p| |第二个p| |第三个p|测试 background-color: yellow background-color: yellow [第一个p
,第二个p
,第三个p
]第二个p
[第二个p
]- 演示文件
# html文件(本地)测试 标题1
标题2
第一个p
第二个p
第三个p
元素选择之css
语法
# 选择单个元素 driver.find_element_by_css_selector('...') # 选择多个元素 driver.find_elements_by_css_selector('...')
子元素(child)选择器
-
选择元素的子元素(直接子节点)
- 对比:后代选择器(非直接子节点)
#choose_car option- 语法举例
#choose_car > option footer > p- 可以是很多级
ul > ol > li > em -
组选择:同时选择多个元素,逗号隔开
,- 语法:
, - 举例:
p,button #food,.cheese-
组合使用
- 选择id为food的所有span子元素和所有的p(包括非food的子元素)
#food >span, p- 选择id为food的:所有span子元素和所有的p子元素
#food > span,#food > p- 选择id为food的所有子元素
#food > *
- 语法:
兄弟节点选择
-
选择紧跟在另一个元素后的元素,二者有相同的父元素
+- 举例
#food + div #many > div > p.special + p -
选择在另一个元素后的元素,二者有相同的父元素
~- 举例
#food ~ div
属性选择器
-
可以根据元素的属性及属性值来选择元素
- 举例
*[style] # 选择所有的元素中属性中含style的元素 p[spec = len2] # 选择元素p的属性spec=len2的元素(spec ='len2 len3'时,不会选中) p[spec = 'len2 len3'] p[spec* = 'len2'] # 选择元素p的属性spec包含len2的元素(spec ='len2 len3'时,也会选中) p[spec^ = 'len2'] # 选择元素p的属性spec以len2开头的元素(spec ='len2 len3'时,也会选中) p[spec$ = 'len2'] # 选择元素p的属性spec以len2结尾的元素(spec ='len2 len3'时,不会选中) p[class = special][name = p1] # 选择元素p的属性class = special,同时name = p1的元素
编辑框的一些操作
-
- 用clear方法清楚该元素里面的字符串
input1.clear()- 输入内容
input1.sed_keys('xxxx')- 获取input元素里面输入的文本内容
input1.get_attribute('value')
单选框-选择单个
-
- 对应的html
男
女
- click方法选择
- 不管原来该元素是否选中,直接去点击该元素没有问题,都可以确保该单选框选中
- 示例
input1 = driver.find_element_by_css_selector('input[value=male]') input1.click()
勾选框-可选择多个
-
- 对应的html
自行车
汽车
- click方法选择
- is_selected方法来获取选择的状态
- 示例
input1 = driver.find_element_by_css_selector('input[value=car]') # 判断是否已经被选中 selected = input1.isselected() if selected: print('car already selected') else: print('car not selected,click on it') input1.click()
复选框
-
- 对应的html
# 按住ctrl可多选 # 单选- Select类
- 方法deselect_all
- 方法select_by_visible_text
- 示例
# 导入Select from selenium.webdriver.support.ui import Select # 获得相应的WebElement select = Select(driver.find_element_by_id('multi')) # 先去选择所有的选项 select.deselect_all() select.select_by_visible_text('雅阁') select.select_by_visible_text('奔驰S300') # 获得相应的WebElement select = Select(driver.find_element_by_id('single')) select.select_by_visible_text('男')
补充01:点击查看selenium之下拉选择框Select 相关补充内容
-
Select提供了三种选择方法:
- select_by_index(index) ——通过选项的顺序,第一个为 0
- select_by_value(value) ——通过value属性
- select_by_visible_text(text) ——通过选项可见文本
-
Select提供了四种方法取消选择:
- deselect_by_index(index)
- deselect_by_value(value)
- deselect_by_visible_text(text)
- deselect_all()
-
Select提供了三个属性方法给我们必要的信息:
- options ——提供所有的选项的列表,其中都是选项的WebElement元素
- all_selected_options ——提供所有被选中的选项的列表,其中也均为选项的WebElement元素
- first_selected_option ——提供第一个被选中的选项,也是下拉框的默认值
补充02:点击CSS3 选择器进入原内容界面查看
- 在 CSS 中,选择器是一种模式,用于选择需要添加样式的元素。
- "CSS" 列指示该属性是在哪个 CSS 版本中定义的。(CSS1、CSS2 还是 CSS3。)
- 选择属于其父元素的第二个子元素的每个
元素。
p:nth-child(2)
数字跟元素类型无关,仅表示父元素下的第几个元素
| 选择器 | 例子 | 例子描述 | CSS |
|---|---|---|---|
.class |
.intro |
选择 class="intro" 的所有元素。 | 1 |
#id |
#firstname |
选择 id="firstname" 的所有元素。 | 1 |
* |
* |
选择所有元素。 | 2 |
element |
p |
选择所有 元素。 |
1 |
element,element |
div,p |
选择所有 元素和所有 元素。 |
1 |
element element |
div p |
选择 元素内部的所有 元素。 |
1 |
element>element |
div>p |
选择父元素为 元素的所有 元素。 |
2 |
element+element |
div+p |
选择紧接在 元素之后的所有 元素。 |
2 |
[attribute] |
[target] |
选择带有 target 属性所有元素。 | 2 |
[attribute=value] |
[target=_blank] |
选择 target="_blank" 的所有元素。 | 2 |
[attribute~=value] |
[title~=flower] |
选择 title 属性包含单词 "flower" 的所有元素。 | 2 |
:link |
a:link |
选择所有未被访问的链接。 | 1 |
:visited |
a:visited |
选择所有已被访问的链接。 | 1 |
:active |
a:active |
选择活动链接。 | 1 |
:hover |
a:hover |
选择鼠标指针位于其上的链接。 | 1 |
:focus |
input:focus |
选择获得焦点的 input 元素。 | 2 |
:first-letter |
p:first-letter |
选择每个 元素的首字母。 |
1 |
:first-line |
p:first-line |
选择每个 元素的首行。 |
1 |
:first-child |
p:first-child |
选择属于父元素的第一个子元素的每个 元素。 |
2 |
:before |
p:before |
在每个 元素的内容之前插入内容。 |
2 |
:after |
p:after |
在每个 元素的内容之后插入内容。 |
2 |
:lang(language) |
p:lang(it) |
选择带有以 "it" 开头的 lang 属性值的每个 元素。 |
2 |
element1~element2 |
p~ul |
选择前面有 元素的每个
|
3 |
[attribute^=value] |
a[src^="https"] |
选择其 src 属性值以 "https" 开头的每个 元素。 | 3 |
[attribute$=value] |
a[src$=".pdf"] |
选择其 src 属性以 ".pdf" 结尾的所有 元素。 | 3 |
[attribute*=value] |
a[src*="abc"] |
选择其 src 属性中包含 "abc" 子串的每个 元素。 | 3 |
:first-of-type |
p:first-of-type |
选择属于其父元素的首个 元素的每个 元素。 |
3 |
:last-of-type |
p:last-of-type |
选择属于其父元素的最后 元素的每个 元素。 |
3 |
:only-of-type |
p:only-of-type |
选择属于其父元素唯一的 元素的每个 元素。 |
3 |
:only-child |
p:only-child |
选择属于其父元素的唯一子元素的每个 元素。 |
3 |
:nth-child(n) |
p:nth-child(2) |
选择属于其父元素的第二个子元素的每个 元素。 |
3 |
:nth-last-child(n) |
p:nth-last-child(2) |
同上,从最后一个子元素开始计数。 | 3 |
:nth-of-type(n) |
p:nth-of-type(2) |
选择属于其父元素第二个 元素的每个 元素。 |
3 |
:nth-last-of-type(n) |
p:nth-last-of-type(2) |
同上,但是从最后一个子元素开始计数。 | 3 |
:last-child |
p:last-child |
选择属于其父元素最后一个子元素每个 元素。 |
3 |
:root |
:root |
选择文档的根元素。 | 3 |
:empty |
p:empty |
选择没有子元素的每个 元素(包括文本节点)。 |
3 |
:target |
#news:target |
选择当前活动的 #news 元素。 | 3 |
:enabled |
input:enabled |
选择每个启用的 元素。 | 3 |
:disabled |
input:disabled |
选择每个禁用的 元素 | 3 |
:checked |
input:checked |
选择每个被选中的 元素。 | 3 |
:not(selector) |
:not(p) |
选择非 元素的每个元素。 |
3 |
::selection |
::selection |
选择被用户选取的元素部分。 | 3 |
[attribute|=value] [lang|=en] 选择 lang 属性值以 "en" 开头的所有元素.
元素选择之xpath
xpath:树型结构
1. 基本概念
使用方法:
find_element_by_xpath("...")根节点:
/-
子节点:
/html/body/...- 直接子节点
/body - 所有子节点(包括直接子节点和非直接子节点)
//body
- 直接子节点
当前节点用“.”表示
./body/...当前节点的上一层节点用“..”表示
../body/...从根节点开始查找
/a/b/c/d不从根节点开始查找(查找所有节点)
//c//b/d-
通配符用
*表示,*可以是任何一种类型//b//* 查找节点b下的所有元素-
xpath与css方法对比
xpath css //div/*div > *
-
-
根据属性查找
- 所有属性,包括id和class
- 示例01:查找属性含style的所有元素
//*[@style] - 示例02:查找p节点下属性spec=len2的元素
//p[@spec='len2']
-
xpath与css方法对比
xpth属性的值必须加引号,css如果没有空格可以不加引号
xpath css //*[@style] *[style] //p[@spec='len2'] p[spec=len2]
2. 举例应用
根据id选择
//*[@id='food']-
选择属于其父元素的第二个p
-
xpath与css方法对比
xpath css //p[2] nth-of-type(2)
-
-
选择属于其父元素的倒数第几个元素
- 最后一个p类型的子元素
//p[last()] - 倒数第二个p类型的子元素
//p[last(-1)] - 所有元素的倒数第二个
//*[last()]
- 最后一个p类型的子元素
-
根据位置选择
position表示位置
所有元素中的前两个元素
//*[position()<=2]除了第一个元素外的其他所有元素
//*[position()>1]所有元素中的最后三个元素
//*[position()>last()-3]-
xpath与css方法对比
- xpath:选择所有的p和所有的button(先选择所有的p再选择button)
//p | //button - css:选择所有的p和所有的button(按结构顺序选择)
p,button
- xpath:选择所有的p和所有的button(先选择所有的p再选择button)
-
当前节点下的所有直接子节点
- css:food下面所有的直接子节点中的div
#food ~ div - xpath:
//*[@id='food']/following-sibling::div - id为food的节点的子节点的第一个节点
//*[@id='food']/following-sibling::*[1] - id是food的上一个节点的div节点
//*[@id='food']/preceding-sibling::div - id为food的父节点(上层节点)
//*[@id='food']/..
- css:food下面所有的直接子节点中的div
-
当前目录与子目录
- 从根目录下开始查找所有的p:
'//p' - 从当前目录下开始查找所有的p:
'.//p' - 从当前节点的父节点开始查找所有的p:
'..//p' - 从当前目录下开始查找直接子节点的p:
'./p'
- 从根目录下开始查找所有的p:
3. 在浏览器中确认查找的元素是否正确
-
浏览器按F2进入开发者模式,点击console
-
xpath与css方法对比
方法 路径前的符号 示例 xpath $x $x("//span")css $$ $$('span')
-
浏览器按F2进入开发者模式,点击elements,按
ctrl+F进入搜索模式,输入xpath或css参数路径
4. 浏览器端根据html查看xpath
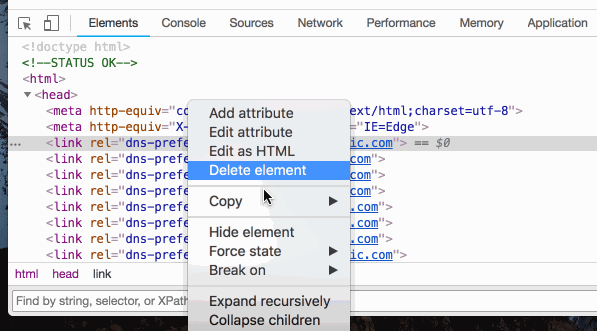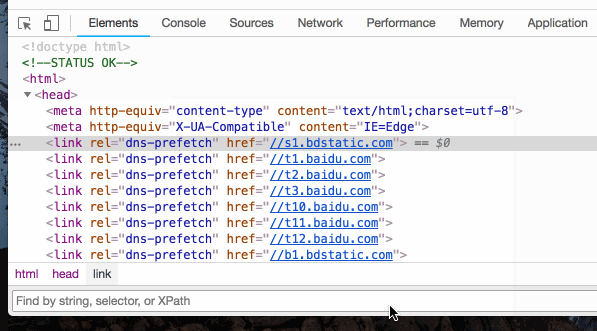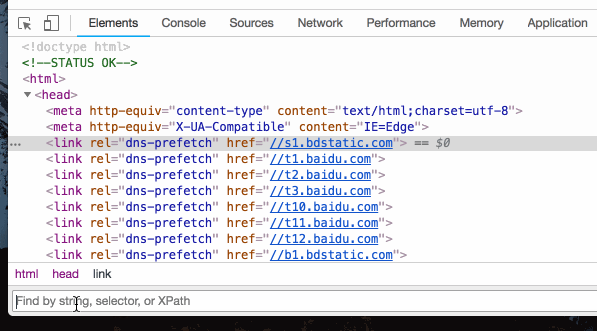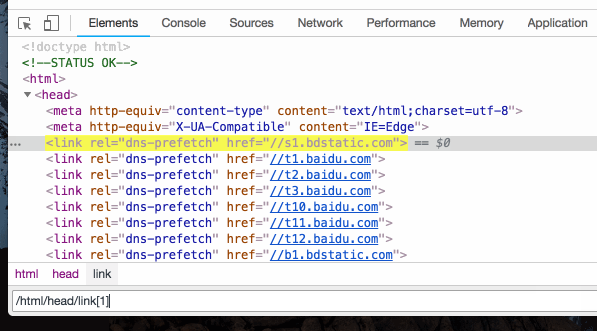
- 选中某个路径,点击鼠标右键,依次选择
copy-->copy xpath即可复制该元素的xpath
查询12306列车
查询有票的列车,并输出列车车次
-
- 要求
- 南京南-杭州东
- 当前时间的第二天
- 0600-1200
- 二等座
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
try:
driver = webdriver.Chrome()
driver.get('https://kyfw.12306.cn/otn/leftTicket/init')
driver.implicitly_wait((10))
# 出发地
driver.find_element_by_id('fromStationText').click() # 点击操作用于清空默认置灰的文字
driver.find_element_by_id('fromStationText').send_keys('南京南')
driver.find_element_by_id('fromStationText').send_keys(Keys.ENTER) # 模拟键盘enter
# 目的地
driver.find_element_by_id('toStationText').click()
driver.find_element_by_id('toStationText').send_keys('杭州东')
driver.find_element_by_id('toStationText').send_keys(Keys.ENTER) # 模拟键盘enter
# 选择时间段
driver.find_element_by_id('cc_start_time').click()
driver.find_element_by_xpath("//*[@id='cc_start_time']/option[@value='06001200']").click()
# 选择日期-->自动查询出结果
driver.find_element_by_xpath(("//*[@id='date_range']/ul/li[2]")).click()
# # 收集数据--方法一(本人首次做出来时使用的方法)
# with_ticket_trains = [] # 有票的车次
# without_ticket_trains =[] # 无票的车次
# all_trains_info = driver.find_elements_by_xpath("//*[@id='queryLeftTable']/tr/td[4]")
# for one_train_info in all_trains_info:
# train_number = one_train_info.find_element_by_xpath("../td[1]//*[@class='number']").text.strip() # 查找车次
# if one_train_info.text in ('--', '无'): # 判断是否有票
# without_ticket_trains.append(train_number)
# else:
# with_ticket_trains.append(train_number)
# # 打印出有票的列车车次
# if len(with_ticket_trains) == 0:
# print('您所选的区间及时间范围内所有列车均已无票')
# else:
# print('以下列车还有票:')
# for i in with_ticket_trains:
# print(f'{i:>6}')
# 收集数据--方法二(后期发现只有有票的才含有class属性,代码如下)
all_trains_info = driver.find_elements_by_xpath("//*[@id='queryLeftTable']/tr/td[4][@class]/../td[1]//a")
for one in all_trains_info:
print(one.text)
finally:
driver.quit()
-
- 结果
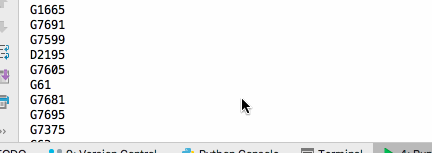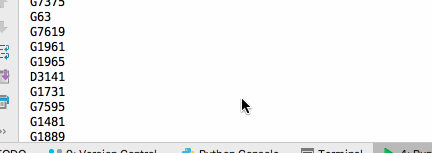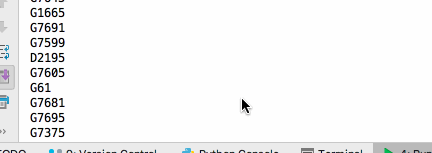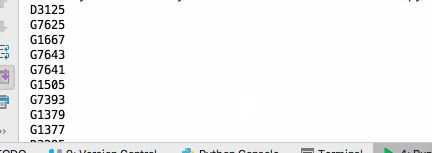
-
- 点击查看补充知识
本文采用其他方法实现功能,暂未涉及链接中介绍的方法,但此方法很实用
- 点击查看补充知识
使用技巧
webdriver对象的一些方法
- 获取某个元素的属性值
# 获取选定元素对应的链接
ele.get_attribute("href")
- 获取当前窗口的title
driver.get('https://www.baidu.com/')
print(driver.title)
driver.find_element_by_id('kw')
print(driver.title)
获取当前窗口的地址栏url地址
driver.current_url随着用户的操作,title和current_url会变化
截屏-全部屏幕
driver.get_screenshot_as_file('ssl.png')
- 截屏-某个元素
ele = driver.find_element_by_id('search')
ele.screenshot_as_png('serch.png')
切换窗口
-
切换到新的窗口里面操作
- 循环遍历所有的窗口 driver.window_handles
- driver.switch_to.window(handle)方法切入新窗口
- 检查该窗口特点,是否为要切入的那个
-
切换到最初的窗口
- 保存主窗口的handle
-
关闭窗口
- close方法
- quit()关闭整个浏览器
-
示例
# 点击某个元素,打开了一个新的窗口 # 保存主窗口handle mainWindow = driver.current_window_handle print(driver.window_handles) for handle in driver.window_handle: # 切换到新窗口 driver.switch_to.window(handle) # 检查是否是我们要进入到window if '百度' in driver.title: break # 进行操作 pass # 切换到主窗口 driver.switch_to.window(mainWindow) # 进行操作 pass
弹出对话框
- 对话框一般来说有三种:
- alert 简单通知(一个按钮)
- confirm (确定,取消)
- prompt (输入内容,确定,取消)
- 操作方法
driver.switch_to.alert.accept() # 点击ok
driver.switch_to.alert.text # 得到对话框内容
driver.switch_to.alert.getText() # 得到对话框的内容
driver.switch_to.alert.dismiss() # 点击Cancel
driver.switch_to.alert.send_keys() # 输入内容
# alert = driver.switch_to.alert() # 获取弹框
-
alert弹窗和html元素弹框
- alert弹窗,用上述方法
- html弹框,查找定位相关元素进行操作
-
如何判断alert弹窗和html弹框
- 点击F12,查看是否可以获得该元素
页面含有input元素,通过插入文件到方式input元素
win32com.client
- 直接发送键盘消息給 当前应用程序。
- 前提是浏览器必须是当前应用(放在最上层,浏览器运行后不要操作
import win32com.client
shell = win32com.client.Dispath('WScript.Shell')
shell.Senkey(r'd:\p1.jpg' + '\n')
刷新页面,前进,后退
- 页面刷新
refresh - 前进
forward - 后退
back
driver.refresh()
driver.forward()
driver.back()
使用技巧
- 易消失元素的查看技巧
鼠标移到该元素上面才会出现
鼠标移开就会消失
-
5秒后冻结页面
setTimeout(function(){debugger;},5000)image
浏览器定位元素 copy selector
获取元素的方法
cssxpath-
取巧:选中元素,右键点击copy,选择
copy selector,或者选择copy xpath上层节点有id时,此方法比较方便,否则可能会生成比较长的路径;
路径太长时,后期html中被修改的可能性比较大,不好维护
此方法并不适用于所有情况,慎用 动态的id不可使用
异常捕获,确保chrome进程退出
切换到新的窗口里面操作
-
使用try...finally...
try: # 可执行代码 except: print() finally: driver.quit()
特殊动作
-
ActionChains 类
按下,移动,拖动等- acInstance.action1().action2().actionN().perform()
-
移动到某个元素上面
- ActionChains(driver).move_to_element(ele).perform()
from selenium.webdriver.common.action_chains import ActionChains ac = ActionChains(driver) ac.move_to_element(driver.find_element_by_id('zxnav_1')).perform() -
一次性输入多个input内容
t1 = driver.find_element_by_id('t1') t2 = driver.find_element_by_id('t2') t3 = driver.find_element_by_id('t3') from selenium.webdriver.common.action_chains import ActionChains ac = ActionChains(driver) ac.click(t1).send_key('1').click(t2).send_key('2').click(t3).send_key('3').perform()
页面元素不可见
通常不可见元素都是可以操作的
-
如果确实需要改变窗口大小
# 获取窗口大小,返回的size是字典(宽度和高度) size = driver.get_window_size() # 改变大小,()里对应的分别是宽度和高度,数字对应的是像素,size['height']表示保持原高度不变 driver.set_window_size(1100,size['height']) driver.max... 窗口最大化
-
滚动页面
# X坐标的值,Y坐标的值 # 正数往下往右移动,负数往上往左移动 driver.execute_script('window.scrollBy(250,0)') # 可在浏览器的console中输入window.scrollBy(250,0),以查看是否能滚动到自己想要的位置
渲染
- 后端渲染
- 前端渲染
- 前端渲染问题引起的报错:statle element reference
- 解决方法:获取内容前,sleep一下
合理使用半自动化
-
图形界面自动化的难度是比较大的
- 模拟难(12306输入验证码...)
- 检查难(检查logo、布局等...)
-
用半自动化的方法
-难自动化的操作,都提示(beep)让人去做import winsound winsound.Beep(1500,3000) # 发出提示音- 其余部分:自动化 去做
自动化的目的:提高测试效率
自动化面对的问题
- 如何组织我们的自动化脚本?都放在一个大目录里面?
- 一次测试开始了,如何选择测试脚本去执行?难道是手动的一个个运行这些脚本?
- 每个测试脚本中,各个检查点是否通过,如何在测试结果里面清晰的反馈
- 一些通用功能的实现如何以库的形式组织起来,供各个脚本使用
- 执行结果如何以容易查看的报告的形式提交给别人查阅
- 以上这些都可以由自动化测试框架解决