Rust之所有权(一):所有权
开发环境
- Windows 10
- Rust 1.54.0

- VS Code 1.59.1
项目工程
这里继续沿用上次工程rust-demo
所有权
所有权是Rust最独特的特性,它使Rust能够在不需要垃圾收集器的情况下保证内存安全。因此,了解Rust中所有权是如何工作的是很重要的。
什么是所有权
Rust的核心特征是所有权。虽然这个特性很容易解释,但它对语言的其他部分有着深刻的含义。
所有程序都必须在运行时管理它们使用计算机内存的方式。有些语言有垃圾回收机制,在程序运行时不断寻找不再使用的内存;而在另外一些语言中,程序员必须显式地分配和释放内存。Rust使用了第三种方法:内存管理通过拥有系统所有权来管理,编译器在编译时会检查这些规则。在程序运行时,所有的所有权特性都不会减慢程序的运行速度。
由于所有权对于许多程序员来说是一个新概念,因此需要一些时间才能适应。好消息是,使用Rust和所有权系统规则的经验越多,您就越能够自然地开发安全和高效的代码。
栈和堆
在许多编程语言中,您不必经常考虑堆栈和堆。但是在像Rust这样的系统编程语言中,无论值在堆栈上还是堆上,对语言的行为以及为什么您必须做出某些决定都有更大的影响。部分所有权将在本章后面的部分堆栈和堆中进行描述,因此这里是准备工作中的一个简要说明。
堆栈和堆都是内存的一部分,您的代码可以在运行时使用它们,但是它们是以不同的方式构造的。堆栈按照获取值的顺序存储值,并以相反的顺序删除值。这被称为“先进后出”。想想一堆盘子:当你加更多的盘子,你把它们放在堆的顶部,当你需要一个盘子时,你把一个从上面取下来。从中间或底部添加或移除盘子将不起作用!将数据添加到堆栈上称为压栈,而删除数据则称为出栈。
存储在栈上的所有数据都必须具有已知的固定大小。编译时大小未知的数据或可能更改的大小必须存储在堆中。堆没有那么有组织:当您将数据放到堆上时,需要一定的空间。内存分配器在堆中找到一个足够大的空点,将其标记为在使用中,并返回一个指针,该指针是该位置的地址。这个过程称为堆上的分配,有时简称为仅仅分配。将值推送到堆栈上不考虑分配。因为指针是已知的、固定的大小,所以可以将指针存储在堆栈上,但是当需要实际数据时,必须遵循指针。
想想坐在餐厅里。当你进入时,你向工作人员说明用餐的人数,工作人员找到一个空且合适的桌子,并带领你去那里。如果你的团队中有人迟到了,他们可以通过问你坐到哪里而找到你。
压栈比在堆上分配空间要快,因为栈不需要搜索存储新数据的位置;该位置总是在堆栈的顶部。相比之下,在堆上分配空间需要更多的工作,因为分配程序必须首先找到足够大的空间来保存数据,然后标记以准备下一次分配。
访问堆中的数据比访问堆栈上的数据要慢,因为您必须遵循指针才能到达那里。如果在内存中跳得更少的话,当代处理器的速度会更快。如果处理器能够更好地处理接近其他数据的数据(如堆栈上的数据),而不是离堆更远的数据(就像堆上的数据那样),处理器可以做得更好。在堆上分配大量空间也需要时间。
当代码调用函数时,传递给函数的值(可能包括指向堆上数据的指针)和函数的局部变量会被压栈。当函数结束时,这些值将从栈中弹出。
跟踪代码的哪些部分在堆上使用什么数据,最小化堆上重复数据的数量,清理堆上未使用的数据,这样就不会耗尽空间,这些都是所有权解决的问题。一旦您理解了所有权,您就不需要经常考虑栈和堆了,但是知道管理堆数据是所有权存在的原因可以帮助解释为什么它是这样工作的。
所有权规则
- Rust中的每个值都有一个变量,称为所有者
- 一次只能有一个所有者
- 当所有者超出范围时,该值将被删除
变量的作用域
作为所有权的第一个例子,我们将查看一些变量的范围。作用域是项目对其有效的程序中的范围。假设我们有一个变量,如下所示:
let s = "hello";变量s引用字符串文本,其中字符串的值被硬编码到我们程序的文本中。从声明变量到当前作用域结束为止,变量都是有效的。
在看一个列子
{ // s在这里无效,还没有声明
let s = "hello"; // 从这一点开始,s是有效的。
// do stuff with s
} // 此作用域现已结束,s不再有效。换句话说,这里有两个重要的时间点:
- 当s进入范围时,它是有效的
- 在超出范围之前仍然有效
此时,作用域和变量是否有效之间的关系类似于其他编程语言中的关系。现在,我们将在此理解的基础上引入字符串类型string。
字符串类型
前面介绍的类型都存储在堆栈上,并在其作用域结束时从栈中弹出,但我们希望查看堆上存储的数据,并研究Rust如何知道何时清理该数据。
这里我们将使用String作为示例,并集中讨论与所有权相关的String部分。这些方面也适用于其他复杂的数据类型,无论它们是由标准库提供的还是由个人创建的。
我们已经看到了字符串文本,其中字符串值被硬编码到我们的程序中。字符串文字很方便,但并不适合我们可能想使用文本的每一种情况。原因之一是它们是不可变的。另一个原因是,当我们编写代码时,并不能知道每个字符串的值:例如,如果我们想获取用户输入并存储它怎么办?对于这些情况,Rust有第二个字符串类型,String。String在堆上分配,因此能够在编译时存储我们不知道的文本数量。可以使用from函数从字符串文本创建字符串,如下所示:
let s = String::from("hello");双冒号(::)是一个操作符,它允许我们在字符串类型下命名这个特定的from函数,而不是使用某种名称,比如string_from。
这种字符串是可变的:
fn main() {
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() 向String对象追加文字
println!("{}", s); // 打印“hello,world”
}
内存及分配
在字符串文本的情况下,我们在编译时知道内容,因此文本直接硬编码到最终的可执行文件中。这就是字符串文字速度快、效率高的原因。但这些属性仅来自字符串文本的不可变性。不幸的是,我们不能为在编译时不知道大小,并且在运行程序时其大小可能发生变化的每一段文本放入二进制文件。
对于String类型,为了支持可变的、可增长的文本,我们需要在堆上分配一定数量的内存(编译时不知道)来保存内容。
- 必须在运行时从内存分配程序中请求内存
- 当我们使用完String时,我们需要一种将这个内存返回给分配器的方法。
第一部分由我们完成:当我们调用string::from时,它的实现请求它所需的内存。这在编程语言中几乎是通用的。
然而,第二部分则有所不同。在带有垃圾回收器(GC)的语言中,GC跟踪并清理不再使用的内存,我们不需要考虑它。在没有GC的情况下,我们有责任识别何时不再使用内存,并调用代码显式地返回它,就像我们请求它一样。历史上,正确地做到这一点一直是一个困难的编程问题。如果我们忘记了,我们就会浪费内存。如果我们做得太早,就会有一个无效的变量。如果我们做两次,那也是个bug。我们需要对应的allocate 和free。
Rust采用不同的路径:一旦拥有它的变量超出作用域,内存就会自动返回。
{
let s = String::from("hello"); // s从这一刻开始有效
// do stuff with s
} // 这个范围现在结束了,s不再有效
当变量超出作用域时,Rust会为我们调用一个特殊的函数。这个函数叫做drop。
变量和数据交互的方式:移动
看如下示例
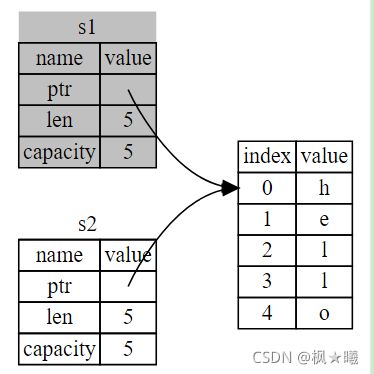
let s1 = String::from("hello");
let s2 = s1;String变量由三个部分组成,显示在左边:一个指向存储字符串内容的内存的指针、一个长度和一个容量。这组数据存储在堆栈上。右边是存放内容的堆上的内存。如图所示
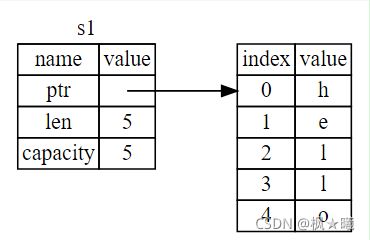
长度是字符串当前使用的内存(以字节为单位)的大小。容量是字符串从分配器接收的内存总量(以字节为单位)。长度和容量之间的区别很重要,但在这种情况下不重要,所以现在,忽略容量是很好的。
当我们将S1分配给S2时,字符串数据将被复制,这意味着我们复制堆栈上的指针、长度和容量。我们不复制指针引用的堆上的数据。如图1

如果Rust也复制堆数据时内存的样子。如果RUST这样做,如果堆上的数据很大,S2=S1操作在运行时性能方面可能会非常昂贵。如图2
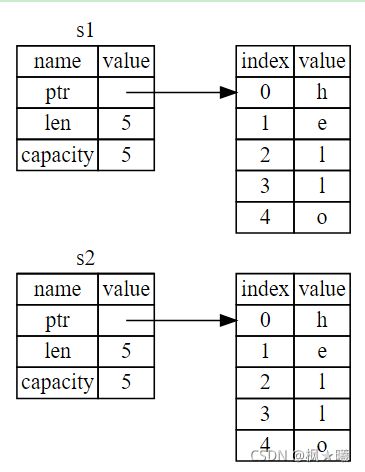
前面我们说过,当变量超出作用域时,Rust会自动调用DROP函数,并为该变量清理堆内存。但是图上图1显示了指向同一个位置的两个数据指针.这是一个问题:当s2和s1超出作用域时,它们都会尝试释放相同的内存。这被称为double free error,是我们前面提到的内存安全错误之一。两次释放内存会导致内存损坏,这可能会导致安全漏洞。
为了确保内存安全,在Rust中发生的事情还有一个细节。与其试图复制分配的内存,Rust认为s1不再有效,因此,当s1超出作用域时,Rust不需要释放任何东西。
我们可以尝试编译运行上述代码。
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
}运行
cargo run
如果您在使用其他语言时听说过浅拷贝和深拷贝,那么在不复制数据的情况下复制指针、长度和容量的概念可能听起来像是在做一个浅拷贝。但是因为Rust也使第一个变量无效,而不是被称为浅拷贝,所以它被称为“移动”。在这个例子中,我们可以说s1被移动到s2中。所以实际的情况如图3
这解决了我们的问题!只有s2有效,当它超出作用域时,它将单独释放内存,我们就完成了。
此外,还有一个设计选择是这样暗示的:Rust永远不会自动创建数据的“深”副本。因此,就运行时性能而言,可以假定任何自动复制都是廉价的。
变量和数据交互方式:克隆
如果我们想要深入复制字符串的堆数据,而不仅仅是栈数据,我们可以使用一个名为克隆的通用方法。示例
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);这就可以很好地解决上述问题。
栈唯一的数据:复制
先看下面的示例
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);这段代码似乎与我们刚刚学到的内容相矛盾:我们没有调用克隆,但是x仍然有效,没有被移动到y中。
原因是编译时具有已知大小的类型(如整型)完全存储在栈上,因此实际值的副本很快就会生成。这意味着在我们创建变量y之后,我们没有理由阻止x是有效的。换句话说,这里的深度复制和浅层复制没有区别,所以调用克隆不会做任何与通常的浅拷贝不同的事情,我们可以忽略它。
Rust有一个特殊的注释,叫做复制特征,我们可以把它放在类型上,比如存储在堆栈上的整数。如果类型实现了复制特性,则在赋值后,旧变量仍然可用。如果类型或其任何部分实现了drop特性,那么Rust会让我们用复制特征注释类型。如果当值超出范围并将复制注释添加到该类型时,类型需要一些特殊的操作,那么我们将得到一个编译时错误。
下面是实现了copy的一些类型:
- 所有整数类型,如u32
- 布尔类型bool,值为true和false
- 所有浮点类型,如f64
- 字符类型,char
- 元组,如果它们只包含也实现复制的类型。例如(I32,I32)实现复制,但(I32,String)没实现
所有权和函数
将值传递给函数的语义与将值赋值给变量的语义相似。将变量传递给函数将像赋值一样移动或复制。如:
fn main() {
let s = String::from("hello"); // 声明s
takes_ownership(s); // s在函数中移动
// s无效
let x = 5; // 声明x
makes_copy(x); // x将移动到此函数中
// 但是i32属于复制,所以这里是可以的
}
fn takes_ownership(some_string: String) {
println!("{}", some_string);
} // 这里, some_string出作用域,并且Rust会调用drop函数,内存以释放
fn makes_copy(some_integer: i32) {
println!("{}", some_integer);
} // 这里, some_integer出作用域,什么也不会发生
如果我们试图在调用takes_ownership之后使用s,Rust会抛出编译错误。这些静态检查保护我们不犯错误。
运行
返回值和范围
返回值也可以传递所有权。如:
fn main() {
let s1 = gives_ownership(); // gives_ownership移动了它的返回值,并赋给s1
let s2 = String::from("hello"); // s2
let s3 = takes_and_gives_back(s2); // takes_and_gives_back将s2移动,同时此函数移动了返回值,赋给s3
} // s3出作用域被释放 s2出作用域但是被移动 s1出作用域被释放
fn gives_ownership() -> String { // gives_ownership将会移动返回值
let some_string = String::from("hello"); // some_string
some_string // some_string作为返回值,并且被移动
}
fn takes_and_gives_back(a_string: String) -> String { // a_string
a_string // a_string 作为返回值,并且被移动
}
运行

变量的所有权每次都遵循相同的模式:将值分配给另一个变量会移动它。当包含堆上数据的变量超出作用域时,将通过DROP清除该值,除非数据已被移动为另一个变量所拥有。
获取所有权,然后用每个函数返回所有权,这有点乏味。如果我们想让一个函数使用一个值,而不使用它的所有权,该怎么办?非常恼人的是,如果我们想要再次使用它,那么传入的任何内容都需要被传回,另外还有我们可能希望返回的函数体产生的任何数据。
可以使用元组返回多个值。示例
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字符串的长度
(s, length) // 返回字符串和长度
}
运行

本章重点
- 所有权
- 移动
- 克隆
- 复制