大数据之非常详细Sqoop安装和基本操作
大数据
大数据之非常详细Sqoop安装和基本操作
目录
- 大数据
- Sqoop
-
- 1、上传解压
- 2、配置环境变量
-
- 配置sqoop环境变量
- 配置sqoop-env.sh
- 3、加入mysql的jdbc驱动包
- 4、验证
-
- 验证是否安装成功
- 验证启动
- 5、导入mysql 表数据到HDFS
- 6、导出 HDFS数据到 mysql
- 总结
Sqoop
1、上传解压
使用xftp将sqoop的安装包上传到虚拟机

解压
tar -zxf /opt/software/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/`
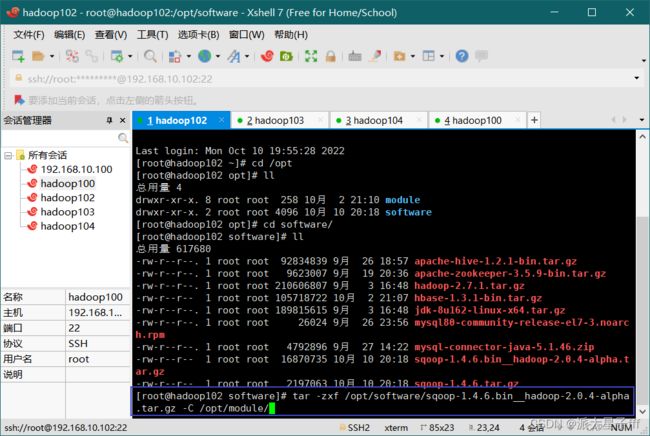

解压完成后,修改个名字方便以后使用
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop

2、配置环境变量
配置sqoop环境变量
vi /etc/profile

使环境变量生效:
source /etc/profile

配置sqoop-env.sh
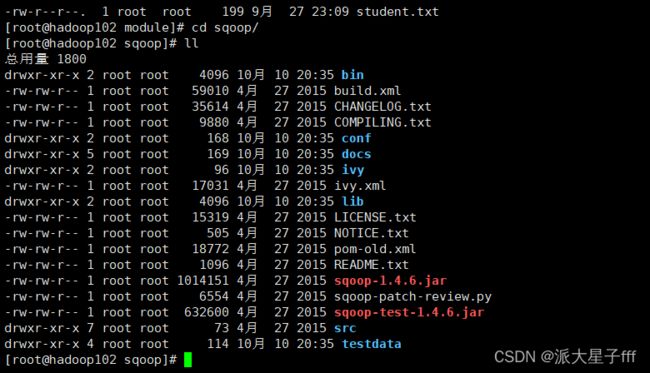
首先先将sqoop-env-template.sh 修改(也可以复制一个)名字为sqoop-env.sh,添加Hadoop,hbase,hive和zookeeper的配置(zookeeper可以先不配置)
命令为
mv sqoop-env-template.sh sqoop-env.sh
cp sqoop-env-template.sh sqoop-env.sh
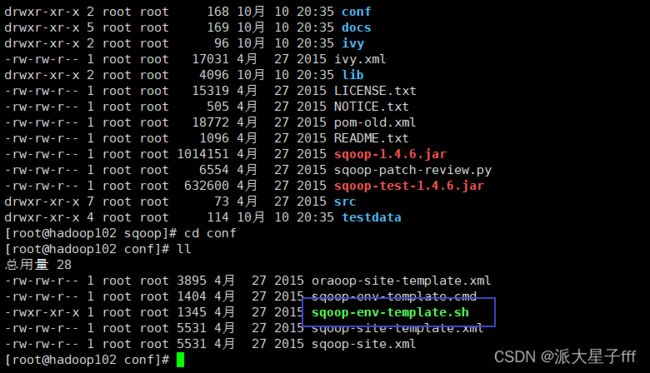

进入后
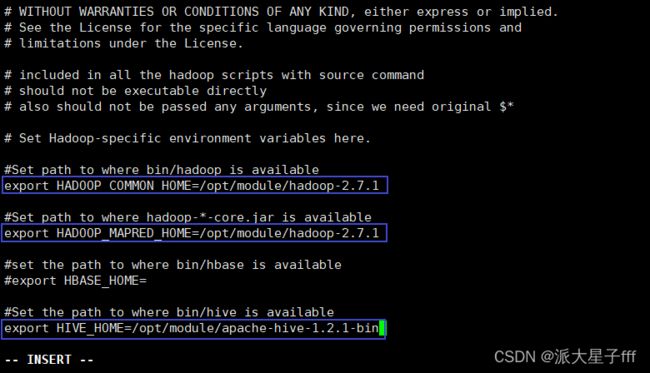
vi sqoop-env.sh
export HADOOP_COMMON_HOME= /opt/module/hadoop-2.7.1
export HADOOP_MAPRED_HOME= /opt/module/hadoop-2.7.1
export HIVE_HOME= /opt/module/apache-hive-1.2.1-bin
3、加入mysql的jdbc驱动包
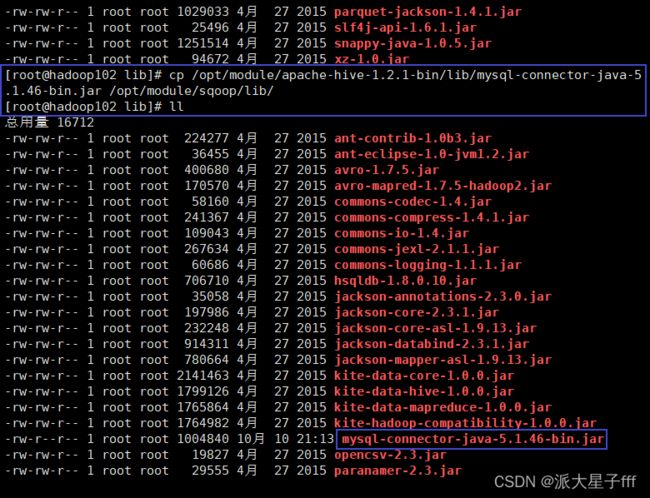
将mysql的jar包拷贝到sqoop的lib目录下,可以拷贝hive的lib目录下的mysql的jar包
cp /opt/module/apache-hive-1.2.1-bin/lib/mysql-connector-java-5.1.46-bin.jar /opt/module/sqoop/lib/
4、验证
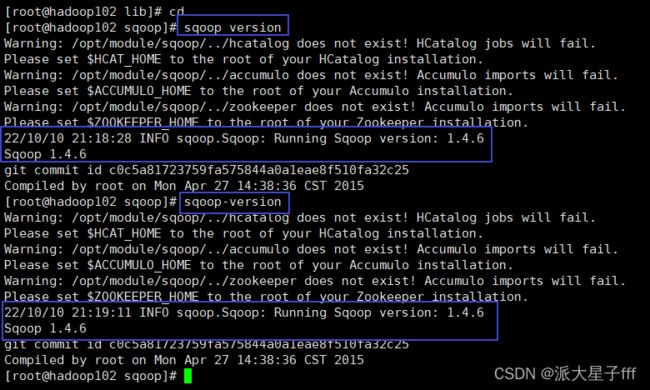
验证是否安装成功
sqoop version
sqoop-version
验证启动
sqoop/bin/sqoop list-databases \
--connect jdbc:mysql://localhost:3306/ \
--username root --password 1234
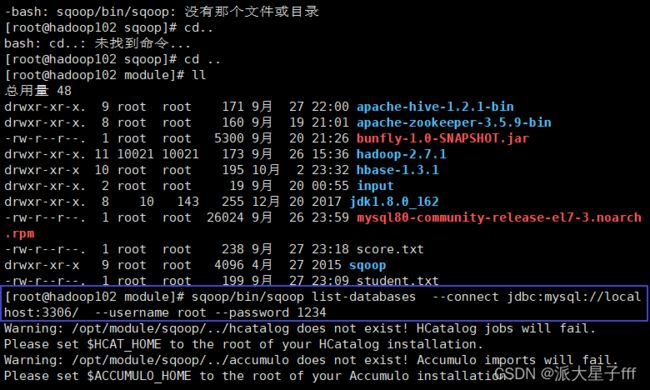
本命令会列出所有mysql的数据库。

到这里,整个Sqoop安装工作完成。
5、导入mysql 表数据到HDFS
sqoop/bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/test \
--username root \
--password 1234 \
--delete-target-dir \
--target-dir /output/sqoop \
--table t1 --m 1 \
--fields-terminated-by ','
其中–target-dir 可以用来指定导出数据存放至 HDFS 的目录;
mysql jdbc url 请使用 ip 地址。
jdbc:mysql://hadoop102:3306
为了验证在 HDFS 导入的数据,请使用以下命令查看导入的数据:
hadoop fs -cat /output/sqoop/part-m-00000
可以看出它会在 HDFS 上默认用逗号,分隔 emp 表的数据和字段。可以通过
–fields-terminated-by '\t’来指定分隔符。
6、导出 HDFS数据到 mysql
将数据从 Hadoop 生态体系导出到 RDBMS 数据库导出前,目标表必须存在于目标数据库中。
export 有三种模式:
# 默认操作是从将文件中的数据使用 INSERT 语句插入到表中。
# 更新模式:Sqoop 将生成 UPDATE 替换数据库中现有记录的语句。
# 调用模式:Sqoop 将为每条记录创建一个存储过程调用。
以下是 export 命令语法:
$ sqoop export (generic-args) (export-args)
执行导出命令
sqoop/bin/sqoop export \
--connect jdbc:mysql://hadoop102:3306/test \
--username root \
--password 1234 \
--table t2 \
--export-dir /output/t1.txt \
--fields-terminated-by ',' --m 1
t \
--connect jdbc:mysql://hadoop102:3306/test \
--username root \
--password 1234 \
--table t2 \
--export-dir /output/t1.txt \
--fields-terminated-by ',' --m 1
总结
以上就是今天要讲的内容,本文仅仅简单介绍了大数据之非常详细Sqoop安装和基本操作,结合以上步骤和书中内容相信你也可以的,加油。