大数据毕业设计选题推荐-自媒体舆情分析平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、部分代码设计
- 五、论文参考
- 六、系统视频
- 结语
一、前言
随着互联网的普及和信息技术的快速发展,自媒体已成为人们表达观点、分享信息、交流意见的重要平台。然而,自媒体的自由性和开放性也带来了一系列的问题,如虚假信息的传播、网络暴力的发生、以及舆论的失控等。这些问题不仅严重影响了网络空间的健康秩序,也对社会现实产生了不可忽视的影响。因此,对自媒体舆情进行监控和分析,成为了一个亟待解决的问题。
目前,虽然有一些自媒体舆情监控平台,但是它们主要集中在舆情的简单监控和预警方面,缺乏对舆情数据的分析和挖掘。具体来说,这些平台往往只关注舆情的数量和热度,而忽视了舆情的内容和质量;只关注舆情的当前状态,而忽视了舆情的过去和未来趋势;只关注舆情的普遍性,而忽视了舆情的特殊性和个别性。因此,现有的自媒体舆情监控平台往往无法提供准确、深入的舆情分析和预警,也就无法满足社会对网络舆情管理的实际需求。
本研究旨在开发一个基于数据的自媒体舆情监控平台,通过收集和分析自媒体中的信息,实现对舆情的监控、分析。具体来说,本平台将实现以下功能:
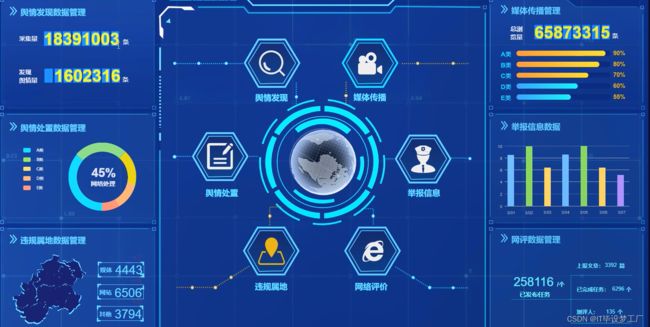
舆情发现数据:通过对自媒体信息的收集和筛选,及时发现和掌握网络舆情的热点和趋势。
舆情处置数据:通过对网络舆情的分析,实现对网络舆情的及时引导和处置。
违规属地数据:通过对自媒体信息的监管和分析,发现和打击网络犯罪和网络不良行为。
媒体传播数据:通过对自媒体信息的传播路径和影响范围的分析,了解和掌握网络舆情的传播规律和影响效应。
举报信息数据:通过对用户举报信息的收集和处理,及时发现和处理网络不良信息和网络违法行为。
网评数据:通过对自媒体信息的情感分析和观点挖掘,了解和掌握用户对某一事件或话题的评价和态度。
本研究的意义在于,通过对自媒体舆情的监控和分析,实现对网络舆情的准确预警和引导,为政府和企业提供更加、准确、及时的网络舆情管理方案,网络空间的健康有序发展。同时,本研究也可以为学术界提供更加丰富、准确、深入的网络舆情数据和研究案例,推动网络舆情研究的深入发展。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts、机器学习
- 软件工具:Pycharm、DataGrip、Anaconda、VM虚拟机
三、系统界面展示
- 自媒体舆情分析平台界面展示:




四、部分代码设计
- 自媒体舆情分析平台项目实战-代码参考:
try:
# 实例化调度器
scheduler = BackgroundScheduler()
# 调度器使用DjangoJobStore()
scheduler.add_jobstore(DjangoJobStore(), "default")
# 'cron'方式循环,周一到周五,每天9:30:10执行,id为工作ID作为标记
# ('scheduler',"interval", seconds=1) #用interval方式循环,每一秒执行一次
@register_job(scheduler, 'cron', day_of_week='mon-fri', hour='12', minute='30', second='10', id='task_time')
# @register_job(scheduler, 'interval', id='test', hours=0, minutes=1)
def test_job():
t_now = time.localtime()
print(t_now)
@register_job(scheduler, 'interval', id='test', hours=0, minutes=0, seconds=10)
def test_two():
CommentService.set_count()
# get_scrapyd_cli().schedule('yu_qing', 'movie')
t_now = time.localtime()
print(t_now)
@register_job(scheduler, 'date', id='tt') # 只执行一次的非阻塞异步任务 这里可以写rabbitmq的消费任务
# @register_job(scheduler, 'interval', id='test', hours=0, minutes=0, seconds=1)
def test_rabbitmq():
connection = pika.BlockingConnection(settings.rabbitmq_connection_parameters)
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
t_now = time.localtime()
print(t_now)
#
# connection.close()
@register_job(scheduler, 'date', id='yq_meituan_comment') # 只执行一次的非阻塞异步任务 这里可以写rabbitmq的消费任务
# @register_job(scheduler, 'interval', id='test', hours=0, minutes=0, seconds=1)
def consumer_mt_yq_comment():
connection = pika.BlockingConnection(settings.rabbitmq_connection_parameters)
channel = connection.channel()
channel.queue_declare(queue='yq.mt.comment')
def callback(ch, method, properties, body):
result = json.loads(body)
for key, value in enumerate(result):
ota_spot_id = value['ota_spot_id']
review_id = value['review_id']
user_name = value['user_name']
user_url = value['user_url']
comment = value['comment']
pic_urls = value['pic_urls']
comment_time = value['comment_time']
reply_cnt = value['reply_cnt']
zan_cnt = value['zan_cnt']
read_cnt = value['read_cnt']
user_id = value['user_id']
star = value['star']
menu = value['menu']
CommentMeituan.objects(ota_spot_id=ota_spot_id, review_id=review_id).update_one(
set__user_name=user_name,
set__user_url=user_url,
set__comment=comment,
set__pic_urls=pic_urls,
set__comment_time=comment_time,
set__reply_cnt=reply_cnt,
set__zan_cnt=zan_cnt,
set__read_cnt=read_cnt,
set__user_id=user_id,
set__star=star,
set__menu=menu,
upsert=True
)
channel.basic_consume(queue='yq.mt.comment', on_message_callback=callback, auto_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
t_now = time.localtime()
print(t_now)
# 监控任务
register_events(scheduler)
# 调度器开始
scheduler.start()
except Exception as e:
print(e)
# 报错则调度器停止执行
scheduler.shutdown()
五、论文参考
- 计算机毕业设计选题推荐-自媒体舆情分析平台-论文参考:

六、系统视频
自媒体舆情分析平台-项目视频:
大数据毕业设计选题推荐-自媒体舆情分析平台-Hadoop
结语
大数据毕业设计选题推荐-自媒体舆情分析平台-Hadoop-Spark-Hive
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:私信我
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目