多进程下载小说的爬虫
之前写过一篇文章来下载小说,不过速度堪忧,因为大量的时间都浪费在了文件的写入上,那么有没有办法优化呢?
文章目录
-
-
- 优化面临的问题
- 解决办法
- 图示
- 队列的建立
- 为不同的进程分配不同的队列
- 进程的任务
- 爬虫的自我修养
- 完整代码
- 如何理解多进程
-
优化面临的问题
- 文章是有序的
- 文件的读写(一般来说当前文件正在读写时是不允许其它程序来访问该文件)
解决办法
文章是有序的
可以使用队列来进行FIFO操作,这样能确保有序
文件的读写(一般来说当前文件正在读写时是不允许其它程序来访问该文件)
如果我们能把小说拆分为两个甚至更多的部分(本文把文章拆成了两部分),让程序并行地存储不同的部分,那么就能提高文件的写入效率(不同的进程写入的文件是不一样的)
图示
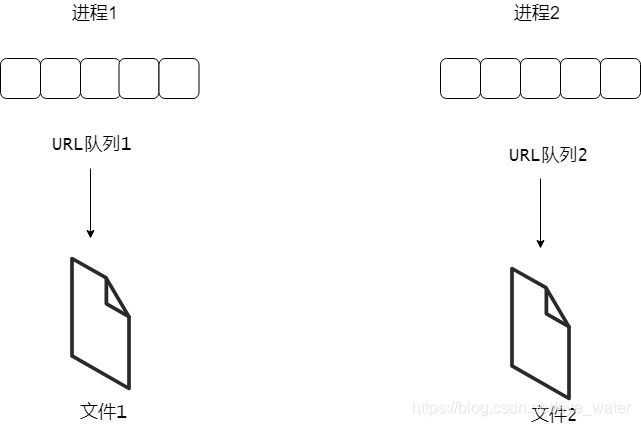
总得来说,就是创建两个进程,每一个线程分配一个URL队列和一个文件,线程会根据URL队列进行网页的爬取并把结果存到文件里面
队列的建立
首先,我们要先得到所有章节的链接,并把链接拆分成为两个部分
def add_tasks(dict_queue):
original_url = 'http://www.37zw.net/0/761/'
original_url_soup = spider(original_url)
i = 0
for a in original_url_soup.find(id = "list").find_all('a'):
url = original_url + str(a.get('href'))
'''
把章节数大于700的存入到第二个队列
小于700的存入到第二个队列
'''
if i > 700:
dict_queue[2].put(url)
else:
dict_queue[1].put(url)
i += 1
return dict_queue
one = multiprocessing.Queue()
two = multiprocessing.Queue()
dict_queue = {1: one, 2:two}
full_queue = add_tasks(dict_queue)
为不同的进程分配不同的队列
for i in range(1, 3):
'''
full_queue[i]代表了不同的队列
'''
p = multiprocessing.Process(
target=process_tasks, args=(full_queue[i], i))
processes.append(p)
'''
启动进程
'''
p.start()
for p in processes:
'''
等待进程的完成
'''
p.join()
进程的任务
每一个线程分配一个
URL队列和一个文件,线程会根据URL队列进行网页的爬取并把结果存到文件里面
def process_tasks(queue, i):
'''
对于不同的进程打开不同的文件
'''
f = open('第{}部分.txt'.format(i), 'w', encoding='utf-8')
while not queue.empty():
'''
从队列里面获取URL
'''
url = queue.get()
soup = spider(url)
'''
获取章节名
'''
chapter_name = soup.find("div", {"class": "bookname"}).h1.string
print(chapter_name)
try:
f.write('\n' + chapter_name + '\n')
except:
pass
'''
获取章节内容
'''
for each in soup.find(id = "content").strings:
try:
f.write('%s%s' % (each.replace('\xa0', ''), os.linesep))
except:
pass
f.close()
return True
如此频繁的进行文件写入操作,难免会出现一两个写入错误,我的建议是如果出现错误就不要管它,如果我们管了那么很不幸,其中一个进程就会卡死,我曾经试过这样写
try:
f.write('\n' + chapter_name + '\n')
except:
f.write("章节丢失")
这样写有个好处就行可以记录丢失的章节,但是别忘了,我们是怎么记录的?f.write()写是文件操作仍有可能造成文件的写入错误
最好的方法当然不是直接pass掉,而是使用日志等记录下来,可是对于我们这个程序来说丢失一两章完全不影响,难不成我们记录了日志还要去网上复制粘贴到文件里面去?
爬虫的自我修养
曾经的我作为一个懵懂无知的爬虫小白,上去就是for循环一把梭,诸不知这样会给网站带来很大的负担,因此我们的爬虫程序也需要稍稍休息一下,万一把网站爬坏了,哪来的小说看呢?
def spider(url):
time.sleep(0.01)
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
response = urlopen(req)
'''
忽略中文编码
'''
html = response.read().decode('gbk', 'ignore')
soup = BeautifulSoup(html, 'html.parser')
return soup
当然我在测试时,没有加time.sleep(0.01),不过对于本例来说大部分的时间都用来写入文件,访问的话基本上是每秒100次左右,其实还是有点高了

完整代码
from bs4 import BeautifulSoup
from urllib.request import Request, urlopen
import os
import time
import multiprocessing
def spider(url):
time.sleep(0.01)
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
response = urlopen(req)
'''
忽略中文编码
'''
html = response.read().decode('gbk', 'ignore')
soup = BeautifulSoup(html, 'html.parser')
return soup
def add_tasks(dict_queue):
original_url = 'http://www.37zw.net/0/761/'
original_url_soup = spider(original_url)
i = 0
for a in original_url_soup.find(id = "list").find_all('a'):
url = original_url + str(a.get('href'))
'''
把章节数大于700的存入到第二个队列
小于700的存入到第二个队列
'''
if i > 700:
dict_queue[2].put(url)
else:
dict_queue[1].put(url)
i += 1
return dict_queue
def process_tasks(queue, i):
'''
对于不同的进程打开不同的文件
'''
f = open('第{}部分.txt'.format(i), 'w', encoding='utf-8')
while not queue.empty():
'''
从队列里面获取URL
'''
url = queue.get()
soup = spider(url)
'''
获取章节名
'''
chapter_name = soup.find("div", {"class": "bookname"}).h1.string
print(chapter_name)
try:
f.write('\n' + chapter_name + '\n')
except:
pass
'''
获取章节内容
'''
for each in soup.find(id = "content").strings:
try:
f.write('%s%s' % (each.replace('\xa0', ''), os.linesep))
except:
pass
f.close()
return True
def run():
one = multiprocessing.Queue()
two = multiprocessing.Queue()
dict_queue = {1: one, 2:two}
full_queue = add_tasks(dict_queue)
processes = []
start = time.time()
for i in range(1, 3):
'''
full_queue[i]代表了不同的队列
'''
p = multiprocessing.Process(
target=process_tasks, args=(full_queue[i], i))
processes.append(p)
'''
启动进程
'''
p.start()
for p in processes:
'''
等待进程的完成
'''
p.join()
print(f'Time taken = {time.time() - start:.10f}')
if __name__ == '__main__':
run()
加上注释也就才94行代码,写一个多进程爬虫是不是很简单
如何理解多进程
对于本例子来说,我想到了一个绝佳的方式来理解,那就是开两个命令行来运行两个单进程版的爬虫,那么效果其实是跟这个例子是一样的
本例子的运行结果

可以看到是两个进程在同时下载
那么跟我们开两个命令行来运行单机版的爬虫,一个让它下前七百章,一个让它下后面的章节不是跟本例子的效果是一样的吗?(只是举例,我并没实际运行)
![]()
参考资料:
Python3 multiprocessing 文档