【从零开始学习Redis | 第四篇】基于延时双删对Cache Aside的优化
前言:
在如今的单体项目中,为了减轻大量相同请求对数据库的压力,我们采取了缓存中间件Redis。核心思想为:把数据写入到redis中,在查询的时候,就可以直接从Redis中拿取数据,这样我们原本对数据库的磁盘操作就变为了对Redis的内存操作,大大减轻了服务器大大压力,但是一个新的问题却应运而生:如何保持缓存与数据库数据的一致性?

目录
前言:
常见的策略:
Cache Aside Pattern:
基于延时双删的对Cache Aside的优化
为什么不使用锁?
总结:
这样的场景其实很常见:
假设线程A对数据库进行了修改,而由于我们的设置,B线程拿取数据是从缓存中拿取的,这就意味着数据库的数据与缓存出现了不一致的情况。
常见的策略:
缓存更新策略常见的有三种:
- 内存淘汰:Redis内存不足的时候,会自动淘汰部分数据,这样就可以在下次查询的时候更新数据,但他对数据的一致性的维护差,但是维护成本低。
- 超时剔除:我们手动为Redis中的数据设置一个有效期,等有效期过了,就需要从数据库中查询,再次写入Redis中,这样就完成了数据的更新,但是这种方式可能会导致Redis的击穿和雪崩问题。
- 主动更新:编写业务逻辑代码,在修改数据库的时候就更新缓存。
今天我们主要讲解一下主动更新策略,而主动更新策略还有三种常见思想:
- Cache Aside Pattern
- 开发人员在更新数据库的时候就直接更新缓存
- Read/Write Through Pattern
- 把缓存和数据库整合成为一个服务,由这个服务来维护一致性
- Write Behind Caching Pattern
- 开发人员只操作缓存,增删改查全部都在缓存中进行,由其他异步线程把缓存数据持久化到数据库,最终保持一致性。
而2和3所展露出来的思想,都有各自的缺点。2是市面上缺乏对应的服务,需要我们自己编写业务代码,提高了我们的业务复杂度;3则是如果我们把对数据的增删改查都放到Redis中,因为Redis是基于内存的,如果服务器宕机或者损坏,就会丢失所有还未写到数据库的数据,这对于一个项目来讲是灾难性的后果。
因此,在今天,我们主要把目光聚集到 Cache Aside Pattern,也就是在更新数据库的时候就更新缓存。
Cache Aside Pattern:
缓存旁路模式的基本流程:
-
读取数据:
- 应用程序从缓存中尝试获取所需数据。
- 如果缓存中存在数据,直接返回给客户端。
- 如果缓存中不存在数据,则进入下一步。
-
获取数据:
- 应用程序从后端存储(如数据库)中读取所需数据。
- 检查后端存储中是否存在数据。
- 如果存在数据,则将数据存储到缓存中,然后返回给客户端。
- 如果不存在数据,则返回空结果给客户端。
-
更新数据:
- 当需要更新数据时,应用程序首先更新后端存储。
- 然后,应用程序手动使缓存失效或删除缓存中对应的数据项,以确保下次读取时可以从后端存储获取最新数据。
因此Cache Aside Pattern是一种先更新数据库,再删除缓存的模式
而在这个操作中,我们需要考虑三个问题:
1.为什么不更新缓存而是选择删除缓存?
我们选择删除缓存,相比较于更新缓存来说,删除缓存的效率更高,如果在更新数据库的时候同步更新缓存,则无用的写操作比较多,不如直接把整个缓存删掉,在查询对应数据的时候重新写入缓存。
2.如何保证缓存与数据库的操作同时成功或失败
在单体项目中,我们使用的是思想是:将缓存与数据库放到一个事务中。
在分布式系统中,我们使用的思想是:利用TCC等分布式事务方案
3.为什么不先删除缓存再更新数据
对于缓存和数据库,一共就两种操作,我们分类讨论:
- 先删除缓存,再操作数据库。
- 先操作数据库,再操作缓存。
这两种操作在多线程的环境下都有自己的弊端,我逐一为大家介绍一下:
在这过程中,我们暂时先不引入锁的概念,在后面我会告诉大家为什么不适用锁来解决这里的数据不一致问题
(1)先删缓存再操作数据库:
在正常情况下:
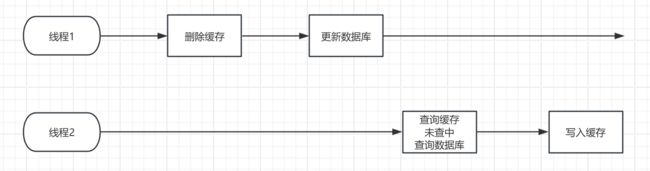
在这种情况下相安无事,可是我们都知道线程是交替执行的,既然是交替执行的,就极有可能发生以下这种情况:
- 线程1删除缓存后,切换到了线程2
- 线程2查询缓存,未命中,查询数据库,得到旧数据,并写入缓存
- 线程1此时重新拿回执行权,执行更新数据库
也就是说,在这种情况下,发生了缓存中的是旧数据,数据库的是新数据的错误事件。
(2)先操作数据库再删除缓存:
在正常情况下:

在这种情况下相安无事,可是我们都知道线程是交替执行的,既然是交替执行的,就极有可能发生以下这种情况:

- 线程2拿到执行权之后,恰巧缓存数据过期,需要查询数据库,此时查到了旧数据
- 切换到线程1,线程1此时进行更新数据库。更新结束后。
- 切换到线程2,线程2把查询到的旧数据写入缓存
- 此时又到线程1,删除了缓存
也就是说,在这种情况下,也发生了缓存中是旧数据,数据库是新数据的错误数据
由此可以看出,其实两个操作都会有相同的问题,那么我们应该使用哪一种策略呢?
答案是先操作数据库,再删除缓存。这是因为这种操作下的异常情况出现的概率要小很多,首先要恰好缓存数据过期。
而且,写入缓存本就是一个很快的过程,从理论上讲,在一个时间切片内,查询缓存未查中,转向查数据库和写入缓存是可以执行完的,这也就意味着很难出现 查询缓存未查中,查询数据库后,转向线程1,执行更加费时的更新数据库操作。
简单的讲就是说:在先操作数据库,再删除缓存这种操作思想的背景下,出现问题的概率要比先删除缓存,再更新数据库要小。
再者来说,就算是基于两个操作都异常的情况下,但我们先删除缓存再更新数据库的时候,我们的缓存与数据库不一致的时间要长:
在这些步骤完成后,数据库与缓存数据不一致的时期为:
直到缓存失效或者下一次删除缓存
而在先更新数据库再删除缓存的时候,我们的缓存与数据库不一致时间要短
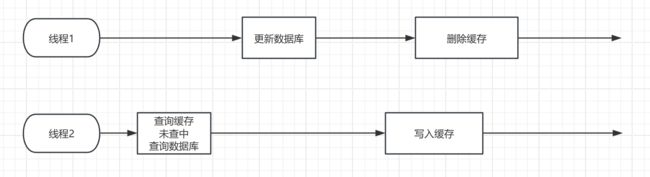
也就是说当先删除缓存,再更新数据库的时候,缓存与数据库数据不一致的时间只有:
从线程2写入缓存到线程1删除缓存
也就是说先更新数据库,再删除缓存这种操作,所带来的缓存与数据库数据不一致的窗口时期,也比先删缓存在更新数据库要短。
而且我们都知道:Redis是基于内存的,也就是说它没有回滚操作。当我们的数据库更新异常时,如果是先更新数据库,再删除缓存的策略,此时我们只需要回滚数据库就可以了。而如果是先删除缓存,再更新数据库这种机制,那就完蛋了,因为Redis没有回滚操作,除非我们自己手动实现,这样又会增加业务的复杂程度。
也就是说,在不引入锁的前提下,先操作数据库再删除缓存 这种操作策略,可以在最大程度上保持缓存与数据库数据的一致性。
而我们的Cache Aside 这种策略模式,不适合于需要高命中率的场景,因为他会对缓存进行频繁的删除。换句话来讲,Cache Aside 更加适合读多写少的场景。
基于延时双删的对Cache Aside的优化
我们可以从上面的图中看出,即使是使用先删数据库,再删缓存的情况下,也仍然有数据不一致的窗口期,而且我们给出的图还是理想的情况下,而在实际生活中,是很有可能出现写入缓存在删除缓存之后的这种极端情况的,用图可以表示为:

一旦出现这种情况,那么数据不一致的窗口期就变为了:直到缓存过期或者下一次删除缓存。
那么为了解决这种问题的出现,一种新的技术就出现了:延时双删
我们用人话来理解一下延时双删的思想:既然删除缓存之后,又把旧的数据写入缓存了,那我们再删一次不就好了!
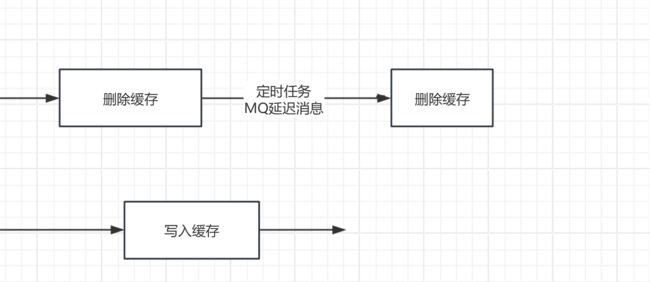
延时双删 就是当我们第一次删除缓存之后,设置一个定时任务或者MQ延迟消息,设置在几秒之后再次删除缓存,这样就避免了出现这种极端情况导致的数据不一致窗口期大大加长。
如果想要保证缓存与数据库数据强一致,那么就需要使用锁,而基于Cahce Aside + 延时双删这种模式,你再怎么优化,也不可以做到缓存与数据库数据强一致
为什么不使用锁?
如果只是为了解决缓存和数据库数据不一致的情况,那么是可以用分布式锁的。但是分布式锁会导致整个项目的并发性彻底完蛋。因此我们尽量要在无锁的情况下解决这种问题。
总结:
面对数据库与缓存的数据不一致的问题,我们普遍采用Cache Aside + 延时双删的无锁思想来解决这个问题。但是它并不能真正解决,只是在不断的缩短数据不一致的窗口期,如果想要做到数据库与缓存数据的强一致,那么就需要使用分布式锁,来使得单个线程操作数据库和Redis具有原子性,但是大量的分布式锁会导致项目的并发性完蛋。因此解决此类问题,还是要在无锁的思想基调下进行。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!
