大数据——Elasticsearch(存储+检索+分析)
Elasticsearch
- ELK Stack
- Elasticsearch简介
- Elasticsearch安装和配置
- Elasticsearch数据模型
-
- 文档(Document)管理(一)
- 文档(Document)管理(二)
- 文档(Document)管理(三)
- 文档(Document)管理(四)
- 索引(Index)管理(一)
- 索引(Index)管理(二)
- 索引(Index)管理(三)
- 索引(Index)管理(四)
- Elasticsearch分布式架构
-
- 索引分片
-
- 主分片分配
- 分片检索(一)
- 分片索引(二)
- 倒排索引(Inverted Index)
- Elasticsearch搜索方式
-
- Query DSL(一)
- Query DSL(二)
- Query DSL(三)
- Query DSL(四)
- Query DSL(五)
- Query DSL(六)
- Query DSL(七)
- Query DSL(八)
- Query DSL(九)
- Query DSL(十)
- 分页(一)
- 分页(二)
ELK Stack
- Elasticsearch(存储+检索+分析),简称ES
- Logstash(日志收集)
- Kibana(可视化)

Elasticsearch简介
基于Lucene的开源分布式搜索引擎,大幅降低了PB级海量数据存储、检索、分析门槛
特点:
- 分布式实时文件存储、检索、分析
- 零配置、集群自动发现
- 索引自动分片、副本机制
- RESTful风格接口
- 多数据源
- 自动搜索负载
Elasticsearch安装和配置
Elasticsearch安装和配置
Elasticsearch数据模型
- Index:索引,由多个Document组成
- Type:索引类型,6.x中仅支持一个,以后将逐渐被移除
- Document:文档,由多个Field组成
| RDBMS | Elasticsearch |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
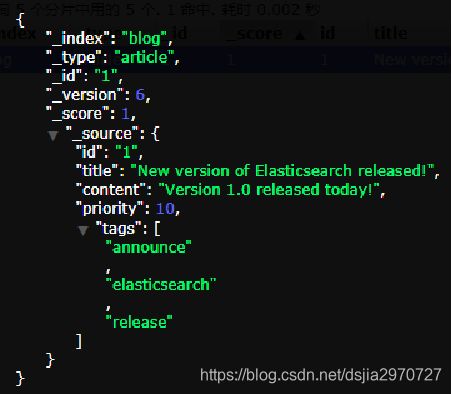
文档(Document)管理(一)
文档是Elasticsearch最小数据单元
-
原始数据
_source:原始JSON格式文档 -
文档元数据
_index:索引名 _type:索引类型 _id:文档编号 _version:文档版本号用于并发控制 _score:在搜索结果中的评分
文档(Document)管理(二)
CRUD
PUT/POST/GEt/DELETE http://ip:端口/索引名称/类型/主键
PUT:更新或创建
POST:创建
GET:查看
DELETE:删除
索引名称:_index
类型:_type
主键:_id,为POST请求时可选,将自动生成
文档(Document)管理(三)
批量操作bulk文件
PUT _bulk
{"index/create/update/delete":{"_index":"...","_type":"...","_id":"..."}}
{"field1":"value1",……}
{"create":{"_index":"stu","_type":"doc","_id":"1"}}
{"id": 1, "studentNo": "TH-CHEM-2016-C001", "name": "Jonh Smith", "major":"Chemistry", "gpa": 4.8, "yearOfBorn": 2000, "classOf": 2016, "interest": "soccer, basketball, badminton, chess"}
{"create":{"_index":"stu","_type":"doc","_id":"2"}}
{"id": 2, "studentNo": "TH-PHY-2018-C001", "name": "Isaac Newton", "major":"Physics", "gpa": 3.6, "yearOfBorn": 2001, "classOf": 2018, "interest": "novel, soccer, cooking"}
$ curl -XPUT 'localhost:9200/_bulk' -H 'Content-Type:application/json' --data-binary @request.json
文档(Document)管理(四)
批量读取文档
GET stu/doc/_mget
{"docs":[{"_id":"1"},{"_id":"2"}]}
GET stu/_mget
{"docs":[{"_type":"doc","_id":"1"},{"_type":"doc","_id":"2"}]}
GET _mget
{"docs":[{"_index":"stu","_type":"doc","_id":"1"},{"_index":"stu","_type":"doc","_id":"2"}]}
索引(Index)管理(一)
创建索引
-
索引名称规范
只支持小写字母 不包括"\ / * ? " < > | ` (空格) , #" ":"在7.0前支持 不能以"- _ +"开头 不能为"."或".." 不能超过255字节 PUT http://ip:端口/索引名称 在不存在的索引中创建文档会自动创建索引 PUT demo.123 //创建索引 GET demo.123 //查看索引
索引(Index)管理(二)
带参数创建索引
PUT demo.1234
{
"settings" : {
"index" : {
"number_of_shards" : 2, #主分片数量,默认5
"number_of_replicas" : 2 #副本数量,默认1
}
}
}
索引(Index)管理(三)
索引的映射
- 定义字段名、字段类型(text、keyword、date、long、double、boolean、ip、completion、geo_point…)
- 定义索引规则
PUT demo.12345
{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"_doc" : {
"properties" : {
"field1" : { "type" : "text" }
}
}
}
}
#_type:_doc
#字段名:field1
#字段类型:text
索引(Index)管理(四)
查看索引映射
GET demo.12345/_mapping
删除索引
DELETE demo.12345
Elasticsearch分布式架构
节点
索引
分片
副本

索引分片
分片
- 索引是指向一个或多个分片的逻辑命名空间
- 最小级别的工作单元,一个Lucene实例(倒排索引)
主分片
- 静态不可变
- 索引首先被存储在主分片中,然后复制相应的副本分片
副本分片
- 动态可修改
- 用于故障转移,一旦主分片失效,副本分片晋升为主分片
主分片分配

分片检索(一)
文档能够从主分片或任意一个副本分片被检索

分片索引(二)
查询阶段
- 查询被向索引中的每个分片(原本或副本)广播,返回待检索数据的定位

取回阶段
- 根据检索数据的定位,发送一个mget的请求给相关分片

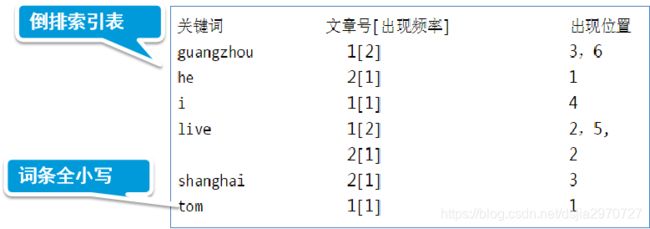
倒排索引(Inverted Index)
-
文章1:
Tom lives in Guangzhou,I live in Guangzhou too. -
文章2:
He once lived in Shanghai.
Elasticsearch搜索方式
主要包括两种
- URI Search:简易方式,可临时使用,不适合构建复杂查询
GET stu,demo*/_search?q=name:john&sort=classOf:desc
#stu,demo* 支持多索引、多类型
#q 查询参数
#name 查询字段
#john 字段值
#sort 排序参数
#classof 排序字段
GET stu/_count
-
Query DSL(Domain Specific Language)
基于JSON的查询语言
Query DSL(一)
叶查询子句(Leaf query clauses)
-
用于在特定字段中查找特定值
match查询 term查询 range查询
复合查询子句(Commpound query clauses)
-
可以包含叶子或者其他的复杂查询语句
bool查询
Query DSL(二)
match_all:返回所有文档
GET stu/_search
{
"query": {
"match_all": {}
}
}
Query DSL(三)
match:布尔匹配查询
- 对查询字符串进行分词,根据分词结果构造布尔查询
GET stu/_search
{
"query": {
"match": {
"name":"John Kerry" #分词结果为join和Kerry两个单词,只要name字段值中包含有其中任意一个,那么返回该文档
}
}
}
Query DSL(四)
match_phrase:短语匹配查询
- 对查询字符串记性分词,字段值必须依次匹配所有分词,注意各分词位置不能改变
GET stu/_search
{
"query": {
"match_phrase": {
"name":"John Kerry" #分词结果为join和Kerry两个单词,如果name字段值中依次包含所有分词,那么返回该文档
}
}
}
Query DSL(五)
match_phrase_prefix:短语前缀匹配查询
- 类似match_phrase但最后一个分词作为前缀匹配
GET stu/_search
{
"query": {
"match_phrase_prefix": {
"name":"John Ke" #最后一个分词作为前缀匹配
}
}
}
Query DSL(六)
multi_match:多字段匹配查询
GET stu/_search
{
"query": {
"multi_match": {
"query": "John like cooking",
"fields": ["name","interest"]
}
}
}
Query DSL(七)
term:词条查询
- 按照存储在倒排索引中的确切字词,对字段进行匹配
GET stu/_search
{
"query": {
"term":{
"name":"john" #换成"join"试一试
}
}
}
Query DSL(八)
terms:多词条查询
- 按照存储在倒排索引中的确切字词,对字段进行多词条匹配
GET stu/_search
{
"query": {
"terms":{
"name":["john","da"]
}
}
}
Query DSL(九)
range:范围查询
GET stu/_search
{
"query": {
"range" : {
"yearOfBorn" : {
"gte" : 1995,
"lte" : 2000
}
}
}
}
Query DSL(十)
bool:布尔查询
- 查询喜欢"cooking"且不在1995-2000间出生的学生
GET stu/_search
{
"query": {
"bool": {
"must": {
"match": { "interest": "cooking"} },
"must_not": {
"range": { "yearOfBorn": { "gte": 1995, "lte": 2000 }}}
}
}
}
分页(一)
from+size浅分页
GET stu/_search?size=5
GET stu/_search?size=5&from=5
GET stu/_search
{
"query": {
"match_all": {}
},
"size": 5, #取出所有文件,截取前5条
"from": 0
}
分页(二)
scroll深分页
- 保存结果快照,需要分页时,直接从结果中获取
GET stu/_search?scroll=5m #返回scroll_id与第一页内容,scroll_id 5分钟有效
{
"from": 0,
"size": 5,
"query": {"match_all": {}}
}
GET _search/scroll
{
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAANy……", #根据scroll_id不断获取下一页内容
"scroll": "5m"
}