tracy 学习
https://github.com/wolfpld/tracy
适用于游戏和其他应用的实时、纳秒分辨率、远程控制、支持采样和帧率检测
Tracy 支持分析 CPU(为 C、C++ 和 Lua 集成提供直接支持。同时,互联网上存在许多其他语言的第三方绑定,例如 Rust 、Zig、C # 、 OCaml 、 Odin等。 )、GPU(所有主要图形 API:OpenGL、Vulkan、Direct3D 11/12、OpenCL。)、内存分配、锁定、上下文切换、自动将屏幕截图归因于捕获的帧等等。
Client ,采样数据的生产者,即我们要分析的程序
Server ,采样数据的接受者,同时是一个数据的viewer,并支持数据存储,以及导出csv。
步骤:
1. Add the Tracy repository to your project directory.
2. Tracy source files in the project/tracy/public directory.
3. Add TracyClient.cpp as a source file. •
4. Add tracy/Tracy.hpp as an include file.
5. Include Tracy.hpp in every file you are interested in profiling.
6. Define TRACY_ENABLE for the WHOLE project.
7. Add the macro FrameMark at the end of each frame loop. •
8. Add the macro ZoneScoped as the first line of your function definitions to include them in the profile. •
9. Compile and run both your application and the profiler server.
10. Hit Connect on the profiler server.
11. Tada! You’re profiling your program!
作为一个性能检测工具,它自身的性能和精确度如何保证的呢?
折线图TracyPlot
#define TracyPlot( name, val ) tracy::Profiler::PlotData( name, val )
static tracy_force_inline void PlotData( const char* name, int64_t val )
{
#ifdef TRACY_ON_DEMAND
if( !GetProfiler().IsConnected() ) return;
#endif
TracyLfqPrepare( QueueType::PlotDataInt );
MemWrite( &item->plotDataInt.name, (uint64_t)name );// 名称,之所以搞成了值,是为了避免拷贝
MemWrite( &item->plotDataInt.time, GetTime() );// 时间
MemWrite( &item->plotDataInt.val, val );// 折线图的值
TracyLfqCommit;
}
template
tracy_force_inline void MemWrite( void* ptr, T val )
{
memcpy( ptr, &val, sizeof( T ) );
}
#define TracyLfqPrepare( _type ) \
moodycamel::ConcurrentQueueDefaultTraits::index_t __magic; \
auto __token = GetToken(); \
auto& __tail = __token->get_tail_index(); \
auto item = __token->enqueue_begin( __magic ); \
MemWrite( &item->hdr.type, _type );
#define TracyLfqCommit \
__tail.store( __magic + 1, std::memory_order_release );
看起来是一个无锁队列。
实现细节:
A Fast General Purpose Lock-Free Queue for C++
Memory Reordering Caught in the Act
#define WIN32_LEAN_AND_MEAN
#include
#include
#include
// Set either of these to 1 to prevent CPU reordering
#define USE_CPU_FENCE 1
#define USE_SINGLE_HW_THREAD 0
//-------------------------------------
// MersenneTwister
// A thread-safe random number generator with good randomness
// in a small number of instructions. We'll use it to introduce
// random timing delays.
//-------------------------------------
#define MT_IA 397
#define MT_LEN 624
class MersenneTwister
{
unsigned int m_buffer[MT_LEN];
int m_index;
public:
MersenneTwister(unsigned int seed);
// Declare noinline so that the function call acts as a compiler barrier:
__declspec(noinline) unsigned int integer();
};
MersenneTwister::MersenneTwister(unsigned int seed)
{
// Initialize by filling with the seed, then iterating
// the algorithm a bunch of times to shuffle things up.
for (int i = 0; i < MT_LEN; i++)
m_buffer[i] = seed;
m_index = 0;
for (int i = 0; i < MT_LEN * 100; i++)
integer();
}
unsigned int MersenneTwister::integer()
{
// Indices
int i = m_index;
int i2 = m_index + 1; if (i2 >= MT_LEN) i2 = 0; // wrap-around
int j = m_index + MT_IA; if (j >= MT_LEN) j -= MT_LEN; // wrap-around
// Twist
unsigned int s = (m_buffer[i] & 0x80000000) | (m_buffer[i2] & 0x7fffffff);
unsigned int r = m_buffer[j] ^ (s >> 1) ^ ((s & 1) * 0x9908B0DF);
m_buffer[m_index] = r;
m_index = i2;
// Swizzle
r ^= (r >> 11);
r ^= (r << 7) & 0x9d2c5680UL;
r ^= (r << 15) & 0xefc60000UL;
r ^= (r >> 18);
return r;
}
//-------------------------------------
// Main program, as decribed in the post
//-------------------------------------
HANDLE beginSema1;
HANDLE beginSema2;
HANDLE endSema;
int X, Y;
int r1, r2;
DWORD WINAPI thread1Func(LPVOID param)
{
MersenneTwister random(1);
for (;;)
{
WaitForSingleObject(beginSema1, INFINITE); // Wait for signal
while (random.integer() % 8 != 0) {} // Random delay
// ----- THE TRANSACTION! -----
X = 1;
#if USE_CPU_FENCE
MemoryBarrier(); // Prevent CPU reordering
#else
_ReadWriteBarrier(); // Prevent compiler reordering only
#endif
r1 = Y;
ReleaseSemaphore(endSema, 1, NULL); // Notify transaction complete
}
return 0; // Never returns
};
DWORD WINAPI thread2Func(LPVOID param)
{
MersenneTwister random(2);
for (;;)
{
WaitForSingleObject(beginSema2, INFINITE); // Wait for signal
while (random.integer() % 8 != 0) {} // Random delay
// ----- THE TRANSACTION! -----
Y = 1;
#if USE_CPU_FENCE
MemoryBarrier(); // Prevent CPU reordering
#else
_ReadWriteBarrier(); // Prevent compiler reordering only
#endif
r2 = X;
ReleaseSemaphore(endSema, 1, NULL); // Notify transaction complete
}
return 0; // Never returns
};
int main()
{
// Initialize the semaphores
beginSema1 = CreateSemaphore(NULL, 0, 99, NULL);
beginSema2 = CreateSemaphore(NULL, 0, 99, NULL);
endSema = CreateSemaphore(NULL, 0, 99, NULL);
// Spawn the threads
HANDLE thread1, thread2;
thread1 = CreateThread(NULL, 0, thread1Func, NULL, 0, NULL);
thread2 = CreateThread(NULL, 0, thread2Func, NULL, 0, NULL);
#if USE_SINGLE_HW_THREAD
// Force thread affinities to the same cpu core.
SetThreadAffinityMask(thread1, 1);
SetThreadAffinityMask(thread2, 1);
#endif
// Repeat the experiment ad infinitum
int detected = 0;
for (int iterations = 1; ; iterations++)
{
// Reset X and Y
X = 0;
Y = 0;
// Signal both threads
ReleaseSemaphore(beginSema1, 1, NULL);
ReleaseSemaphore(beginSema2, 1, NULL);
// Wait for both threads
WaitForSingleObject(endSema, INFINITE);
WaitForSingleObject(endSema, INFINITE);
// Check if there was a simultaneous reorder
if (r1 == 0 && r2 == 0)
{
detected++;
printf("%d reorders detected after %d iterations\n", detected, iterations);
}
}
return 0; // Never returns
}
上面的VC++ 代码,可直观的体验内存序异常
无锁编程需要解决的是:编译器和CPU 为了优化,只保证单线程的内存序和代码顺序一致。
为了让多线程编码变得可行,需要增加恰当的指令,让编译器和cpu 都保证内存一致性(粒度不同性能不同)
A Fast Lock-Free Queue for C++
折线图消费及渲染
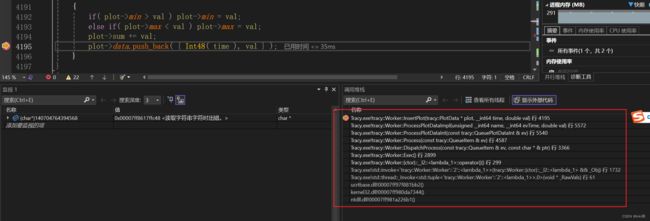
tracy 在工作线程拿到对应的数据后,会将其插入到plot 列表中。
之后在主线程的渲染循环中,展示在UI 上: