TensorRT量化实战课YOLOv7量化:YOLOv7-PTQ量化(二)
目录
-
- 前言
- 1. YOLOv7-PTQ量化流程
- 2. 模型标定
- 3. 敏感层分析
前言
手写 AI 推出的全新 TensorRT 模型量化实战课程,链接。记录下个人学习笔记,仅供自己参考。
该实战课程主要基于手写 AI 的 Latte 老师所出的 TensorRT下的模型量化,在其课程的基础上,所整理出的一些实战应用。
本次课程为 YOLOv7 量化实战第三课,主要介绍 YOLOv7-PTQ 量化
课程大纲可看下面的思维导图
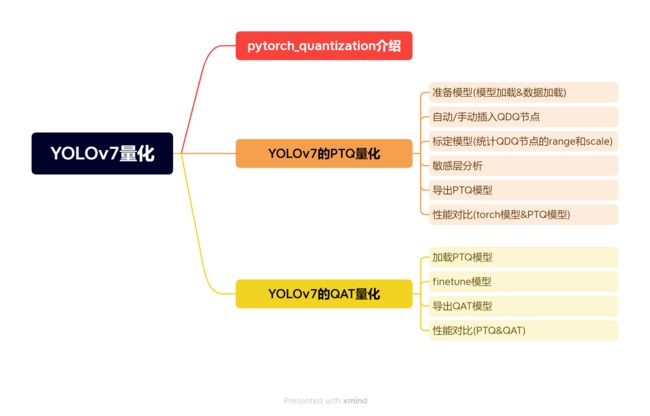
1. YOLOv7-PTQ量化流程
在上节课程中我们介绍了 YOLOv7-PTQ 量化中 QDQ 节点的插入,这节课我们将会完成 PTQ 模型的量化和导出。
从上面的思维导图我们可以看到 YOLOv7-PTQ 量化的步骤,我们代码的讲解和编写都是按照这个流程来的。
在编写代码开始之前我们还是再来梳理下整个 YOLOv7-PTQ 量化的过程,如下:
1. 准备工作
首先是我们的准备工作,我们需要下载 YOLOv7 官方代码和预训练模型以及 COCO 数据集,并编写代码完成模型和数据的加载工作。
2. 插入 QDQ 节点
第二个就是我们需要对模型插入 QDQ 节点,它有以下两种方式:
- 自动插入
- 使用 quant_modules.initialize() 自动插入量化节点
- 手动插入
- 使用 quant_modules.initialize() 初始化量化操作或使用 QuantDescriptor() 自定义初始化量化操作
- 编写代码为模型插入量化节点
3. 标定
第三部分就是我们的标定,其流程如下:
- 1. 通过将标定数据送到网络并收集网络每个层的输入输出信息
- 2. 根据统计出的信息,计算动态范围 range 和 scale,并保存在 QDQ 节点中
4. 敏感层分析
第四部分是敏感层分析,大致流程如下:
- 1. 进行单一逐层量化,只开启某一层的量化其他层都不开启
- 2. 在验证集上进行模型精度测试
- 3. 选出前 10 个对模型精度影响比较大的层,关闭这 10 个层的量化,在前向计算时使用 float16 而不去使用 int8
5. 导出 PTQ 模型
第五个就是我们在标定之后需要导出 PTQ 模型,导出流程如下:
- 1. 需要将我们上节课所说的 quant_nn.TensorQuantizer.use_fb_fake_quant 属性设置为 true
- 2. torch.onnx.export() 导出 ONNX 模型
6. 性能对比
第六个就是性能的对比,包括精度和速度的对比。
上节课我们完成了 YOLOv7-PTQ 量化流程中的准备工作和插入 QDQ 节点,这节我们继续按照流程走,先来实现模型的标定工作,让我们开始吧!!!
2. 模型标定
模型量化校准主要是由以下三个函数完成的:
1. calibrate_model
def calibrate_model(model, dataloader, device):
# 收集前向信息
collect_stats(model, dataloader, device)
# 获取动态范围,计算 amax 值,scale 值
compute_amax(model, method = 'mse')
该函数主要是讲两个校准步骤组合起来,用于模型的整体校准,整体步骤如下:
- 使用 collect_stats 函数收集前向传播的统计信息
- 调用 compute_amax 函数计算量化的尺度因子 amax
2. collect_stats
def collect_stats(model, data_loader, device, num_batch = 200):
model.eval()
# 开启校准器
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.disable_quant()
module.enable_calib()
else:
module.disable()
# test
with torch.no_grad():
for i, datas in enumerate(data_loader):
imgs = datas[0].to(device, non_blocking=True).float() / 255.0
model(imgs)
if i >= num_batch:
break
# 关闭校准器
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.enable_quant()
module.disable_calib()
else:
module.enable()
该函数的目的是收集模型在给定数据集上的激活统计信息,这通常是模型量化校准过程中的第一步,具体步骤如下:
- 设置模型为 eval 模型,确保不启用如 dropout 这样的训练特有的行为
- 遍历模型的所有模块,对于每一个 TensorQuantizer 实例
- 如果有校准器存在,则禁用量化(不对输入进行量化)并启动校准模式(收集统计信息)
- 如果没有校准器,则完全禁用该量化器(不执行任何操作)
- 使用 data_loader 来提供数据,并通过模型执行前向传播
- 讲数据转移到 device 上,并进行适当的归一化
- 对每个批次数据,模型进行推理,但不进行梯度计算
- 收集激活统计信息直到处理指定数量的批次
- 最后,遍历模型的所有模块,对于每一个 TensorQuantizer 实例
- 如果有校准器存在,则启用量化并禁用校准模式
- 如果没有校准器,则重新启用该量化器
3. compute_amax
def compute_amax(model, **kwargs):
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
if isinstance(module._calibrator, calib.MaxCalibrator):
module.load_calib_amax()
else:
module.load_calib_amax(**kwargs)
module._amax = module._amax.to(device)
一旦收集了激活的统计信息,该函数就会计算量化的尺度因子 amax(动态范围的最大值),这通常是模型量化校准过程中的第二步,步骤如下:
- 遍历模型的所有模块,对于每一个 TensorQuantizer 实例
- 如果有校准器存在,则根据收集的统计信息计算 amax 值,这个值代表了激活的最大幅值,用于确定量化的尺度
- 将 amax 值转移到 device 上,以便在后续中使用
下面我们简单总结下模型量化校准的流程:
-
1.数据准备: 准备用于标定的数据集,通常是模型训练或验证数据集的一个子集。
-
2.收集统计信息: 通过 collect_stats 函数进行前向传播,以收集模型各层的激活分布统计信息。
-
3.计算 amax: 使用 compute_amax 函数基于收集的统计信息计算量化参数(如最大激活值 amax)。
通过上述步骤,模型就可以得到合适的量化参数,从而在量化后保持性能并减小精度损失。
完整的示例代码如下:
import os
import yaml
import test
import torch
import collections
from pathlib import Path
from models.yolo import Model
from pytorch_quantization import calib
from absl import logging as quant_logging
from utils.datasets import create_dataloader
from pytorch_quantization import quant_modules
from pytorch_quantization import nn as quant_nn
from pytorch_quantization.tensor_quant import QuantDescriptor
from pytorch_quantization.nn.modules import _utils as quant_nn_utils
def load_yolov7_model(weight, device='cpu'):
ckpt = torch.load(weight, map_location=device)
model = Model("cfg/training/yolov7.yaml", ch=3, nc=80).to(device)
state_dict = ckpt['model'].float().state_dict()
model.load_state_dict(state_dict, strict=False)
return model
def prepare_val_dataset(cocodir, batch_size=32):
dataloader = create_dataloader(
f"{cocodir}/val2017.txt",
imgsz=640,
batch_size=batch_size,
opt=collections.namedtuple("Opt", "single_cls")(False),
augment=False, hyp=None, rect=True, cache=False, stride=32, pad=0.5, image_weights=False
)[0]
return dataloader
def prepare_train_dataset(cocodir, batch_size=32):
with open("data/hyp.scratch.p5.yaml") as f:
hyp = yaml.load(f, Loader=yaml.SafeLoader)
dataloader = create_dataloader(
f"{cocodir}/train2017.txt",
imgsz=640,
batch_size=batch_size,
opt=collections.namedtuple("Opt", "single_cls")(False),
augment=True, hyp=hyp, rect=True, cache=False, stride=32, pad=0, image_weights=False
)[0]
return dataloader
# input: Max ==> Histogram
def initialize():
quant_desc_input = QuantDescriptor(calib_method='histogram')
quant_nn.QuantConv2d.set_default_quant_desc_input(quant_desc_input)
quant_nn.QuantMaxPool2d.set_default_quant_desc_input(quant_desc_input)
quant_nn.QuantLinear.set_default_quant_desc_input(quant_desc_input)
quant_logging.set_verbosity(quant_logging.ERROR)
def prepare_model(weight, device):
# quant_modules.initialize()
initialize()
model = load_yolov7_model(weight, device)
model.float()
model.eval()
with torch.no_grad():
model.fuse() # conv bn 进行层的合并, 加速
return model
def tranfer_torch_to_quantization(nn_instance, quant_module):
quant_instances = quant_module.__new__(quant_module)
# 属性赋值
for k, val in vars(nn_instance).items():
setattr(quant_instances, k, val)
# 初始化
def __init__(self):
# 返回两个 QuantDescriptor 的实例 self.__class__ 是 quant_instance 的类, QuantConv2d
quant_desc_input, quant_desc_weight = quant_nn_utils.pop_quant_desc_in_kwargs(self.__class__)
if isinstance(self, quant_nn_utils.QuantInputMixin):
self.init_quantizer(quant_desc_input)
# 加快量化速度
if isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):
self._input_quantizer._calibrator._torch_hist = True
else:
self.init_quantizer(quant_desc_input, quant_desc_weight)
if isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):
self._input_quantizer._calibrator._torch_hist = True
self._weight_quantizer._calibrator._torch_hist = True
__init__(quant_instances)
return quant_instances
def torch_module_find_quant_module(model, module_list, prefix=''):
for name in model._modules:
submodule = model._modules[name]
path = name if prefix == '' else prefix + '.' + name
torch_module_find_quant_module(submodule, module_list, prefix=path) # 递归
submodule_id = id(type(submodule))
if submodule_id in module_list:
# 转换
model._modules[name] = tranfer_torch_to_quantization(submodule, module_list[submodule_id])
def replace_to_quantization_model(model):
module_list = {}
for entry in quant_modules._DEFAULT_QUANT_MAP:
module = getattr(entry.orig_mod, entry.mod_name) # module -> torch.nn.modules.conv.Conv1d
module_list[id(module)] = entry.replace_mod
torch_module_find_quant_module(model, module_list)
def evaluate_coco(model, loader, save_dir='', conf_thres=0.001, iou_thres=0.65):
if save_dir and os.path.dirname(save_dir) != "":
os.makedirs(os.path.dirname(save_dir), exist_ok=True)
return test.test(
"data/coco.yaml",
save_dir=Path(save_dir),
conf_thres=conf_thres,
iou_thres=iou_thres,
model=model,
dataloader=loader,
is_coco=True,
plots=False,
half_precision=True,
save_json=False
)[0][3]
def collect_stats(model, data_loader, device, num_batch = 200):
model.eval()
# 开启校准器
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.disable_quant()
module.enable_calib()
else:
module.disable()
# test
with torch.no_grad():
for i, datas in enumerate(data_loader):
imgs = datas[0].to(device, non_blocking=True).float() / 255.0
model(imgs)
if i >= num_batch:
break
# 关闭校准器
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.enable_quant()
module.disable_calib()
else:
module.enable()
def compute_amax(model, **kwargs):
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
if isinstance(module._calibrator, calib.MaxCalibrator):
module.load_calib_amax()
else:
module.load_calib_amax(**kwargs)
module._amax = module._amax.to(device)
def calibrate_model(model, dataloader, device):
# 收集前向信息
collect_stats(model, dataloader, device)
# 获取动态范围,计算 amax 值,scale 值
compute_amax(model, method = 'mse')
if __name__ == "__main__":
weight = "yolov7.pt"
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 加载数据
print("Evalute Dataset...")
cocodir = "dataset/coco2017"
val_dataloader = prepare_val_dataset(cocodir)
train_dataloader = prepare_train_dataset(cocodir)
# 加载 pth 模型
pth_model = load_yolov7_model(weight, device)
# pth 模型验证
print("Evalute Origin...")
ap = evaluate_coco(pth_model, val_dataloader)
# 获取伪量化模型(手动 initial(), 手动插入 QDQ)
model = prepare_model(weight, device)
replace_to_quantization_model(model)
# 模型标定
calibrate_model(model, train_dataloader, device)
# # PTQ 模型验证
print("Evaluate PTQ...")
ptq_ap = evaluate_coco(model, val_dataloader)
值得注意的是我们校准时是在训练集上完成的,测试时是在验证集上完成的,运行效果如下:
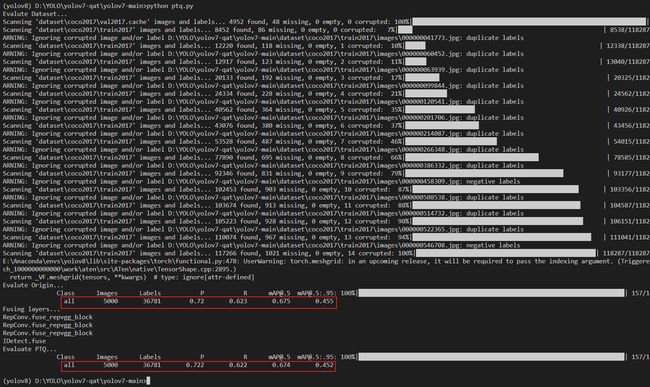
可以看到量化校准后的模型的 mAP 仅仅下降了 0.003 个点。
博主学得有点混淆了,先梳理下一些概念,我们收集统计信息的目的是为了确定当前 tensor 的 amax 即幅度的最大值,然后根据不同的校准方法和获取的统计信息去校准计算 amax,其中包括 Max 和直方图两种校准方法,Max 校准方法直接选择 tensor 统计信息的最大值来作为 amax,而直方图校准中又包含 entropy、mse、percentile 三种方法来计算 amax,上述过程仅仅是进行了校准确定了 amax 值,得到了量化时所需要的 scale,但是还没有利用 scale 进行具体的量化操作,模型的权重或激活值还没有改变,应该是这么理解的吧
下面我们来对比下 Max 和直方图校准方法的 PTQ 模型的对比,来看看不同的校准方法对模型的影响
上面我们测试了直方图校准后的 PTQ 模型性能,下面我们来看 Max 校准方法,我们将 prepare_model 函数中的手动 initialize 函数注释,打开自动初始化 quant_module.initialize
再次执行代码如下所示:

可以看到我们使用默认的 Max 校准方法得到的 mAP 值是 0.444,相比于之前直方图校准的效果要差一些,因此后续我们可能就使用直方图校准的方式来进行量化。
下面我们来看看 PTQ 模型的导出,导出函数如下:
def export_ptq(model, save_file, device, dynamic_batch = True):
input_dummy = torch.randn(1, 3, 640, 640, device=device)
# 打开 fake 算子
quant_nn.TensorQuantizer.use_fb_fake_quant = True
model.eval()
with torch.no_grad():
torch.onnx.export(model, input_dummy, save_file, opset_version=13,
input_names=['input'], output_names=['output'],
dynamic_axes={'input': {0: 'batch'}, 'output': {0: 'batch'}} if dynamic_batch else None)
执行后效果如下:
我们将导出的 PTQ 模型和原始的 YOLOv7 模型对比,
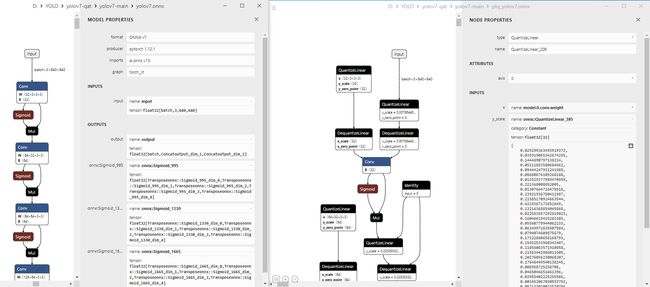
左边是我们原始的 ONNX,右边是我们 PTQ 模型的 ONNX,可以看到导出的 PTQ 模型中多了 QDQ 节点的插入,其中包含了校准量化信息 scale。
以上就是 torch 和 PTQ 模型的对比,下面我们来进行敏感层的分析。
3. 敏感层分析
To be continue…