LangChain+LLM实战---私有化部署RAG大模型,ChatGLM2-6B、Baichuan2-13B
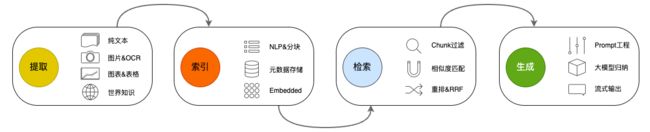
图1:RAG的架构流程
经过之前一段时间的捣腾,个人感觉我们的RAG应用已经来到了一个全新的层面,在语义理解(相关度)和准确度上都有了长足进步。
但是问题来了。之前和菊厂的业务交流中,对方明确提出一些客户的私有化部署意愿是很明确,主要原因是数据安全。这段时间和一些销售人员、潜在客户交流的时候也收到了类似信息。而我们现在的整套技术栈中,唯一还不能私有化的是LLM。而这也是最终客户最担心的问题——他们的数据被送进云上的公共LLM,不管这些LLM在数据安全上如何申明,对于一些数据就是资产的客户来说依然存在忧虑。所以我们最近就在开始做LLM的本地化测试。
LLM选择标准
在选本地化的LLM之前,我们先根据实际情况定义一些选择标准:
- 归纳优先:我们不需要LLM在各个方面都很优秀,不需要它们会很强的coding和复杂逻辑推理能力,RAG最重要的还是出色的归纳能力;
- 体量考虑:不要太大,最好在13B及以下,因为再大就需要一张A100等专业显卡,或者要多张消费级显卡。我们的目标是一张RTX 4090可以解决问题,对很多客户来说,A卡很难买,而且价格太高了;
- 中文能力:我们主要面对的还是中文业务,所以Llama对我们还是成本太高,如果自己做大量训练的话。
大模型试用选择
定义了选择标准之后,我们就来实际试用了。待选的其实也不多,我们自己有一个全量训练的BLOOM-7B,然后另外两个待选是ChatGLM2-6B和Baichuan2-13B。如果您还有其他更好的选择,可以私信我,哈。
试用自训练的BLOOM-7B
部署在公司内网的自训练BLOOM-7B是今年3月份就训练好的,当时也算是走在比较前面的,至少在我们文旅数字化行业,好像当时是没有的。BLOOM-7B在问答方面能力还是可以的,在文旅方面因为有我们自己多年的语料沉淀,在我们覆盖的客户景区的问答上,在当时效果超过ChatGPT。

图2:自训练的BLOOM-7B,没有使用原始权重,从CLM开始训练,使用了8块A100
但是,接入到RAG之后,发现归纳能力不太行。而且近期因为新的开源大模型出来很多,所以暂时也没有打算再去优化这个7B的大模型。所以,首先试用和淘汰的就是我们自己训练的BLOOM-7B,这个行业,真的一日千里啊,3月份训练的大模型,当时是小甜甜,现在已经是牛夫人了。
试用ChatGLM2-6B
目前我们使用的是智谱的标准版(API,在线版),效果应该说很棒,所以我们首先想到的是ChatGLM2-6B的开源版本。
图3:智谱大模型的在线API,能力还是非常不错的。
ChatGLM2-6B因为已经有商业许可,所以两个月前就做了部署,把AutoModel.from_pretrained的指向从本地改成Hugging Face的模型地址让它更新到最新版本,然后接上我们的RAG做测试。说实话,使用同样的Prompt,ChatGLM2-6B的归纳能力只能说是复读机级别的(⊙o⊙)。LLM的归纳能力,太简单了可以通过Prompt优化改成复杂的,但是已经让它按最简单的方式去归纳了,依然是复读机的结果,那就不适用了。

图4:ChatGLM2-6B的归纳能力就是复读机级别的,哪怕我们硬性规定用20个字归纳也不行。
因为ChatGLM2目前开放的就是6B和130B两个版本,但是130B的对于我们来说已经远超定义的选择范围,所以就放弃ChatGLM2了。
试用Baichuan2-13B
百川大模型选型
百川大模型是我们一个在老牌中厂的小伙伴给我们推荐的,据说他们内部已经在实用,而且效果不错,于是我就开始转向Baichuan2-13B。

图5:百川大模型2目前的几个版本,7B、13B,以及Base和Chat版
我们首先选择的是13B,因为7B/6B这个级别的我们上面已经试用了,在技术层面没有碾压式的升级之前,参数体量有时候就决定了能力。对于Base和Chat,因为我们现在更多考察的还是归纳能力,所以为了方面考虑,选择了Chat版本。所以目前选择的就是Baichuan2-13B-Chat。
接下来就是考虑量化版本,官方给出了资源表:
| Precision | Baichuan2-7B | Baichuan2-13B |
|---|---|---|
| bf16 / fp16 | 15.3 GB | 27.5 GB |
| 8bits | 8.0 GB | 16.1 GB |
| 4bits | 5.1 GB | 8.6 GB |
表1:量化效果,来源于Baichuan2的Github说明
按一张RTX 4090(24GB)来算的话,最佳的应该是Baichuan2-13B的8bits版本。但是官方只提供了fp16和4bits两个版本,唯独没有8bits量化版本。
安装和运行fp16版本
我的做法是先部署fp16,先试试效果呗。
第一步是git clone代码,然后在Hugging Face上,models的过程是比较痛苦的,三个bin文件近28GB,最近几个月我发现直接下载(wget)总是无法成功,而我的Ubuntu服务器是没有科学上网的。所以只能在家里的Mac上先下载,直到今天凌晨2点才完成(好困~),然后传到Ubuntu上。

图6:Baichuan2-13B的权重文件
先用fp16先安装,把cli_demo.py里面的model地址改成本地的,这样不用每次运行的时候都会查询并下载最新版权重文件,主要是等待时间太长了。
cli_demo.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
print("init model ...")
model = AutoModelForCausalLM.from_pretrained(
"baichuan-inc/Baichuan2-13B-Chat", // 这里改成你自己的本地模型地址
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model.generation_config = GenerationConfig.from_pretrained(
"baichuan-inc/Baichuan2-13B-Chat" // 这里改成你自己的本地模型地址
)
tokenizer = AutoTokenizer.from_pretrained(
"baichuan-inc/Baichuan2-13B-Chat", // 这里改成你自己的本地模型地址
use_fast=False,
trust_remote_code=True
)
|
运行程序:
1 |
python cli_demo.py |
居然跑起来了,但是,推理的速度跟乌龟爬一样慢!
视频1:fp16,在我的RTX4090服务器上推理速度非常感人....
两个回合之后,直接就OutOfMemoryError了。
手工量化int8
那现在只能把fp16量化为8bits,还好,官网有提到量化的方法。
我们需要先安装两个lib:
1 2 3 |
pip install xformers conda install bitsandbytes //也可以使用pip |
然后在原来的models平级目录mkdir一个models_8,然后我用了一个比较偷懒的做法,直接把cli_demo.py复制为quan8.py。

图7:新增models_8文件夹,用来存放离线量化之后的int8权重,quan8.py就是转化脚本
下面修改这个新复制的quan8.py。
quan8.py
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def init_model():
print("quant8int model ...")
model = AutoModelForCausalLM.from_pretrained(
"/home/tumeng/llm/Baichuan2/models",
load_in_8bit=True,
device_map="auto",
trust_remote_code=True
)
model.save_pretrained(
"/home/tumeng/llm/Baichuan2/models_8"
)
return model
|
我是比较偷懒的方式,因为当时太困了!
其他的代码我不管(运行的时候会报错,但不影响),就修改了init_model()函数。AutoModelForCausalLM.from_pretrained里面的第一个参数是原权重文件,save_pretrained里面是量化出来的int8权重文件保存的目录。
运行成功
再次修改cli_demo.py,将model指向到int8的模型
cli_demo.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
def init_model():
print("init model ...")
model = AutoModelForCausalLM.from_pretrained(
"/home/tumeng/llm/Baichuan2/models_8",
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model.generation_config = GenerationConfig.from_pretrained(
"/home/tumeng/llm/Baichuan2/models_8"
)
tokenizer = AutoTokenizer.from_pretrained(
"/home/tumeng/llm/Baichuan2/models_8",
use_fast=False,
trust_remote_code=True
)
return model, tokenizer
|
再次运行cli_demp.py,这次运行成功了,而且推理速度满足要求,棒!
然后就到了检验Baichuan2-13B的归纳能力的时候了,我直接复制了小明给我的Prompt。
视频2:Baichuan2-13B(8ints)的推理速度还可以,归纳能力过关。

图8:基本上归纳的还是比较准确和简洁的。
速度、归纳效果,都还可以!那私有化,暂时就先选型Baichuan2-13B了。
对了,其实Baichuan2-13B的逻辑能力是有短板的,我经常用的一道测试题,它答得不好。

图9:龙凤胎的逻辑推理题,Baichuan2-13B答错了
结论
这次大模型的选型测试主要还是为了私有化的需要,如果没有私有化(甚至完全断网)需求的话,个人感觉智谱的API还是挺好用的。本次选择除了最开始定义的三个过滤条件外,其实还有一个就是可商用,ChatGLM2-6B、BLOOM-7B和Baichuan2-13B都是符合这一条件的。