Python案例代码 | 使用正则表达式判别微博用户mbti类型
使用Python爬虫采集 「微博搜索」中含mbti信息的推文, 使用正则表达式判别用户mbti类型。相比实验室做实验或者发调查问卷,这种方式收集到的用户类别是非常自然且真实的。今日爬虫不是今日主题,就不做分享了。

import pandas as pd
#采集自微博搜索中含mbti类型的推文
df = pd.read_csv('mbti_test.csv')
#剔除content列中的nan数据
df.dropna(inplace=True, subset=['content'])
df

正则表达式练习题
-
提取含有mbti的记录
-
提取出含mbti类型出现的前后5个字符的文本 (前5个字符,后5个字符, 含mbti本身, 窗体最长的长度是14)
-
识别出含mbti的记录中对应的mbti类型, 未识别的标记为"未识别"
一、 提取含有mbti的记录
实现方法有两种
-
pd.Series.str.contains(regex_pattern)
-
定义一个正则处理函数regex_func, 使用 pd.Series.apply(regex_func)
正则表达式含义
mbtis = '[infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj]'
-
[ 和 ]:这是字符类(character class)的起始和结束标记,表示要匹配方括号内的任何字符。 -
infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj:这是一个字符类内的字符集合,用于匹配MBTI类型词汇。每个MBTI类型词汇都以竖线 | 分隔,表示“或”的关系。这意味着正则表达式会匹配其中任何一个MBTI类型词汇。 -
+:这是一个量词,表示匹配前面的字符集合(MBTI类型词汇)一次或多次。它使正则表达式可以匹配包含一个或多个MBTI类型词汇的文本。
mbtis = '[infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj]'
df.content.str.contains(mbtis)
0 True
1 True
2 True
3 True
4 True
…
495 False
496 False
497 False
498 False
499 False
Name: content, Length: 497, dtype: bool
import re
def has_mbti(text):
mbtis = '[infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj]+'
if re.findall(mbtis, text):
return True
else:
return False
df.content.apply(has_mbti)
0 True
1 True
2 True
3 True
4 True
…
495 False
496 False
497 True
498 False
499 True
Name: content, Length: 497, dtype: bool
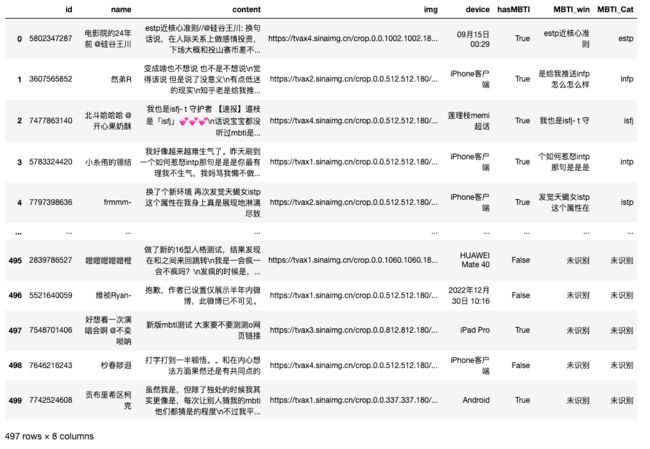
df['hasMBTI'] = df['content'].apply(has_mbti)
df

二、mbti前后内容
提取出含mbti类型出现的前后5个字符的文本(前5个字符,后5个字符, 含mbti本身, 窗体最长的长度是14)。
这样后续的分析任务,就可以通过查看mbti字眼前后出现的字符,来更新正则表达式。
正则表达式含义
mbti_win = "(.{0,5}(?:infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj).{0,5})"
-
(和)这些括号用于将整个匹配结果捕获为一个分组 -
.{0,5}:这是一个量词,表示匹配前面的字符(.表示匹配任意字符)零次到五次。这部分用于匹配前面的文本,确保最多匹配前面的五个字符。 -
(?:infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj):这是一个非捕获分组,用于将多个MBTI类型词汇用 | 连接起来,表示匹配其中任何一个。 -
.{0,5}:这部分同样是一个量词,表示匹配后面的字符,确保最多匹配后面的五个字符。
def mbti_window(text):
#识别mbti的正则表达式
mbti_win = "(.{0,5}(?:infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj).{0,5})"
try:
return re.findall(mbti_win, text)[0]
except:
return "未识别"
df['MBTI_win'] = df['content'].apply(mbti_window)
df

三、识别mbti类型
刚刚的代码比较粗糙,只能判断文本中是否有mbti信息,但并不能判断该用户是否为某种mbti类型。
微博文本中,只有 //@ 前字符内容是微博用户所写内容。为了识别用户的mbti类型,可以先将我们看到的表达方式列举一下
-
``我是[mbti]
-
自己是[mbti] -
从[mbti]变为[mbti] -
一直是[mbti] -
[mbti]我 -
本[mbti] -
…
可以基于此设计一个严格的正则表达式,能识别到的记录,肯定能判断该用户的mbti类型。未识别到的标记为 “未识别”
正则表达式含义
mbti_regex = "[我|自己|变成|一直|是|本]*(infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj)[我|俺|本|自己]*"
-
[我|自己|变成|一直|是|本]*:这部分是一个字符集合,用于匹配前面的字符(关键词)。方括号[...]表示字符类,其中的字符是可选的,并且 * 表示匹配零次或多次。这意味着它可以匹配零个或多个出现在方括号中的字符,例如可以匹配"我"、“自己”、“变成”、“一直”、“是”、"本"等这些关键词。 -
(infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj):这是一个分组,其中包含了MBTI类型词汇,用竖线|分隔,表示"或"的关系。这部分用于匹配任意一个MBTI类型词汇。 -
[我|俺|本|自己]*:这部分与第1部分类似,是一个字符集合,用于匹配后面的字符(关键词)。同样,方括号[...]表示字符类,其中的字符是可选的,并且*表示匹配零次或多次。
def identify_mbti(text):
if '//@' in text:
new_text = text.split('//@')[0]
else:
new_text = text
#识别mbti的正则表达式
mbti_regex = "[我|自己|变成|一直|是|本]*(infj|entp|intp|intj|entj|enfj|infp|enfp|isfp|istp|isfj|istj|estp|esfp|estj|esfj)[我|俺|本|自己]*"
try:
return re.findall(mbti_regex, text)[0]
except:
return "未识别"
#mbti类型
df['MBTI_Cat'] = df['content'].apply(identify_mbti)
df
#各类型记录数
df['MBTI_Cat'].value_counts()
MBTI_Cat
未识别 297
infp 35
isfj 20
enfp 18
intp 17
isfp 16
intj 14
entp 12
entj 11
infj 11
enfj 8
estj 8
istp 8
istj 7
esfp 6
estp 5
esfj 4
Name: count, dtype: int64
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除