一文看懂——序列数据的生成:GAN的方法

![]()
导读:序列数据指的是一种按照先后顺序排列的离散数据,这类数据虽然不如图像数据那么直观,但其实在实际生活中非常常见。比如我们平时浏览网站的行为其实就是序列数据,我们会不断地在各种不同的网页链接之间跳转,从而形成一个序列的网页链接列表;又比如我们平时使用的自然语言,就是由一系列按照顺序排列的文字所构成。
![]() 作者:史丹青
作者:史丹青
来源:华章计算机(hzbook_jsj)

GAN的模型直接用于训练是一个非常自然的想法,只需要能够收集大量真实的序列数据就可以通过生成器和判别器的对抗来完美实现对与离散数据的生成。这个想法看似十分美好,但是在实践过程中会发现两个致命的问题。首先,是离散数据的可导性。GAN的创造者IanGoodfellow之前曾表示由于GAN需要计算生成器输出的梯度,因此在有连续输出的地方才能很好的工作,而像文本这样离散的数据不具备可导性很难使用GAN进行生成。其次,是如何去判断一个还没有生成完毕的序列数据是“真”或“假”。在实际的生成过程中,序列数据是一个一个逐步产生的,除了最终状态之外的大部分情况都是一个未完成的序列,比如一句还没有说完的话,或是一系列没有完成的网页操作。在这个未完成的状态下,如何让判别器判断当前的序列是“真”是“假”就变成了一个棘手的问题。
SeqGAN
SeqGAN首先提出了GAN在序列生成上的方法。为了解决在之前提到的那些问题,SeqGAN把序列数据生成的过程看作是一个序列决策的过程,在生成数据的过程中一步一步决定下一个元素是什么。
SeqGAN使用了一种基于强化学习的方法,它的生成器正是强化学习中的代理(Agent),而模型的状态(State)是当前已经生成的序列,行为(Action)则是下一步需要生成的元素。但和传统的强化学习不同的是,在整个模型训练过程中并不会有一个明确的奖励函数(Reward),而是使用了GAN架构中的判别器网络来评估当前生成的序列,从而指导生成器的训练。首先,对于离散数据难以进行反向传播的问题,由于SeqGAN的生成器是一个随机策略模型,可以直接使用强化学习中的策略梯度方法(PolicyGradient)完美规避了这个问题。因为在Policy Gradient中并不用针对误差来进行反向传播,而是根据当前选择的结果来决定每种行为在各种状态下的概率,如果该行为最终得到了一个比较好的分数,则下次在相同情况下该行为将会有一个比较大的概率,反之的话则该行为的概率则会降低。其次,对于无法判断不完整序列的问题,SeqGAN在中间过程中使用了蒙特卡洛搜索的方法,会把中间序列进行补全,这也使得判别器可以始终用评估完整序列的方式来评估中间序列。
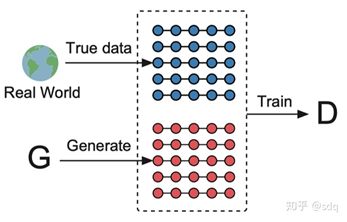
SeqGAN架构示意图(图9-1)
上图展示了SeqGAN的架构,从整体上来看和传统的GAN架构基本是一致的,唯一的差别是数据上的差异,判别器D会基于真实世界的序列数据和生成器G产生的假序列数据进行训练。
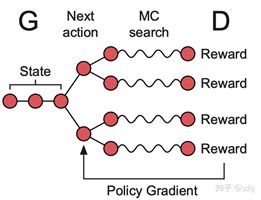
SeqGAN生成过程示意图(图9-2)
我们来看一下SeqGAN的生成的细节。对于强化学习来说通常需要能够清晰定义马尔科夫决策模型,其中最重要的三个元素就是状态(State)、行为(Action)以及奖励函数(Reward)。对于SeqGAN中的生成器G来说,State正是当前已经生成的中间序列,Action是序列中下一个会使用的元素,而Reward则是由判别器D给出的结果,用于后续的策略梯度算法。图中的曲线表示对于中间序列采用了蒙特卡洛搜索的方式来对未完成的序列进行采样补全,从而可以让判别器对完整的序列结果进行评估。
自然语言生成
在离散序列数据中最常用的就是自然语言,文字是天然的序列数据,每个元素代表自己独立的含义又和前后文保持关联。如果SeqGAN在序列数据上能够保证生成的质量,那在此基础上就可以自动生成让人难以分辨真假的文本数据。在SeqGAN的论文中,作者在中国的诗词和奥巴马的政治演讲上分别进行了测试,其中在诗词任务中使用了16384个中文诗句,在演讲任务中则使用了11092段奥巴马的句子。为了保证自动化的完整性,没有使用任何先验知识。在实验结果中可以发现,使用SeqGAN生成的自然语言文本已经和真实的数据比较接近了。为了更进一步提高文本生成的质量,研究者们在判别器上提出进一步优化的想法。传统GAN的判别器往往是对于数据进行二分类,判断为“真”或为“假”,但是在自然语言的场景下这样的判断就显得限制过多了,因为自然语言的表现是非常丰富的,很难用单纯的二分类对一句句子下定义。
RankGAN[2]是对现在GAN生成方法在语言生成上二分类方法的改进,RankGAN顾名思义是使用了排序的方法去替换二分类的方法。在RankGAN的架构中有两个神经网络,分别是生成器和排序器,对于排序器来说,它的目标是将人类写的句子尽量要排在自动生成的句子之前。如图所示,H表示人类写的句子,而G是机器所写的句子。排序器的输入是一个自动生成的句子和一组人类写的句子。同时,我们会给排序器一个人类写的句子作为参考,它需要依据这个参考项去尽量将自动生成的句子排在比较靠后的位置上。图中的例子表示的是生成器已经完全骗过了排序器,将生成的句子G排在了第一位。
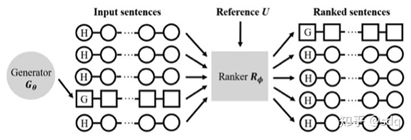
RankGAN架构示意图(图9-3)
上面的工作在生成短文本的任务中已经有了不错的结果,但由于在生成数据的过程中,需要使用采样的方式得到完整句子后才可以得到奖励函数作为反馈,这导致生成的句子在这个过程中会丢失掉中间信息,如果生成的句子一旦超过20个字,效果就会大大降低。
为了解决长文本生成的问题,研究者提出了一种LeakGAN的新框架,让判别器能够将提取到的高阶信息泄露给生成器,以此更好地来指导生成器。如下图所示,LeakGAN的判别器中会提取中间特征,用来透露给生成器,而传统的GAN通常在训练过程中不会将生成器和判别器的中间信息共享,这也是LeakGAN名字的由来。
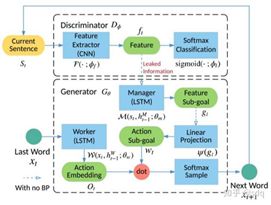
LeakGAN框架示意图(图9-5)
看另一边,生成器会基于前一个单词去预测下一个输出的词是什么。在生成器中包含两个角色,一个是Manager用于接收来自判别器泄漏的信息,并提出指导的生成方向,另一个是Worker用于接收上一个单词并输出向量用于预测下一刻的单词。在生成器中,会需要把Manager的指导和Worker的预测进行整合,考虑两者并最终一起得出句子中的下一个单词。
在真实的数据实验中,LeakGAN获取了比较显著的效果提升,尤其是在长句子上,LeakGAN通常能取得表好的结果。
小结
SeqGAN、RankGAN、LeakGAN等研究是GAN在离散序列数据生成上的探索,这些探索打开了GAN的应用领域,未来我们可以期待GAN在离散数据上有更多的AI应用出现。
参考文献
[1] Yu, L., Zhang, W., Wang, J. and Yu, Y., 2017, February.Seqgan: Sequence generative adversarial nets with policy gradient. InProceedings of the AAAI conference on artificialintelligence(Vol. 31, No. 1).
[2] Lin, K., Li, D.,He, X., Zhang, Z. and Sun, M.T., 2017. Adversarial ranking for languagegeneration. InAdvances in neural information processing systems(pp.3155-3165).
[3] Guo, J., Lu, S.,Cai, H., Zhang, W., Yu, Y. and Wang, J., 2018, April. Long text generation viaadversarial training with leaked information. InProceedings of the AAAIConference on Artificial Intelligence(Vol. 32, No. 1).
以上内容摘自《生成对抗网络入门指南(第2版)》一书

GAN入门佳作时隔3年再升级!支持Tensorflow2,提供全部示例代码。揭秘海量人脸图像生成技术,追踪GAN前沿发展。

加群一起学

扫码关注【华章计算机】视频号
每天来听华章哥讲书

更多精彩回顾
书讯 | 1月书讯(下)| 2022年的第一本书
书讯 | 1月书讯(上)| 2022年的第一本书
资讯 | 重磅!达摩院发布2022十大科技趋势
书单 | 6本书,读懂2022年最火的边缘计算
干货 | Flink1.14.2发布,除了log4j漏洞你还需要关注什么?
收藏 | Docker冲顶技术热词,微服务应用热度不减,中国云原生开发者真实现状如何?
上新 | 【新书速递】金融领域可解释机器学习模型与实践
赠书 | 【第88期】这10本硬核技术书,带你读懂5G、物联网和边缘计算,玩转元宇宙


点击阅读全文了解更多AI好书