2021 XV6 5:Copy-on-Write Fork
目录
1.概述
2.修改uvmcopy
3.修改trap.c
4.引用计数机制
5.修改copyout
6.结果
1.概述
首先,这是一个很有意义的性能优化方案。
提出的背景是,如果我们每次fork的时候,都完整分配一系列物理页把父进程的内容拷贝进来,是一种十分不明智的行为。不仅浪费空间,而且还耗费调用fork时的时间。
那么解决这种问题的方法就是COW,一种写时复制的机制,思路如下:
1.在fork的时候,不要求申请新的内存空间,而是把原来的物理页映射到用户页表里面,但是我们打上不可写和COW两个标记位,这样,在下一次写必要的原来可写的页的时候,就会触发一个异常。具体异常和exception code对应关系如下,我们在这里触发的是15:

2.触发异常后,我们就知道,原来这个页原来是可写的,但是现在打上了COW的标记位,那么我们在这个时候再分配一个物理页来给程序,并且修改原来的页表项,恢复写的标记,除去COW标记位,并且把新的物理页映射进去。
虽然看起来简单,但是实现起来还是有一些细节的,以下是具体实现。
2.修改uvmcopy
在xv6里面的fork里面调用uvmcopy来让子进程复制父进程的物理空间,原来的方法是分配了一个和父进程一样大小的物理空间。

但是我们现在要COW,所以把原来的页表项拿出来,改一下标志位,具体来说就是去掉write标志位,这可以引发异常便于我们后续分配物理页,加上COW标记,可以在COW分配物理页时检查是否合法。
具体代码如下所示:
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
// char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
// 清空页表项中的PTE_W
*pte &= ~PTE_W;
*pte |= PTE_COW;
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
// 这里没有申请新的物理页 没有必要释放pa
// 将原来的物理页直接映射到子进程的页表中 标志位设置不可写 COW
if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
goto err;
}
addref(pa);
//
// 注释分配一个物理页的代码
// if((mem = kalloc()) == 0)
// goto err;
// memmove(mem, (char*)pa, PGSIZE);
// if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){
// kfree(mem);
// goto err;
// }
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}其中addref之后在引用计数的机制里边说。
3.修改trap.c
具体来说我们在下一次写一个COW页的时候会触发15号异常,我们在trap.c里的usertrap里边修改一个处理的代码:
else if(r_scause() == 15){// Store/AMO page fault
// 取出无法翻译的地址
// printf("cow\n");
uint64 va=r_stval();
if(handler_cow_pagefault(p->pagetable, va)<0){
//杀死进程
p->killed=1;
}我在vm.c里面实现了这个函数的定义,这样对于访问类似于walk函数啥的会更加方便(因为walk没有对外提供),而且对外提供一个封装接口:
// 取出COW的物理页
// 分配一个新的页映射到进程页表中 并且将原来的物理页拷贝到新的页中
// 修改页表项的flag 除去COW位 加上write标志位
int
handler_cow_pagefault(pagetable_t pagetable, uint64 va)
{
// 取出原来无法翻译的va地址
if (va >= MAXVA)
return -1;
pte_t *pte=walk(pagetable, va, 0);
if (pte == 0 || (*pte & PTE_COW)==0)
return -1;
uint64 pa=PTE2PA(*pte);
// 分配一个新的物理页 将原来物理页中内容拷贝至新物理页
pagetable_t new_page=(pte_t*)kalloc();
if (new_page==0)
return -1;
memmove((char*)new_page, (char*)pa, PGSIZE);
// 减少原来物理页引用计数
kfree((void*)pa);
// 将新的物理页映射至页表中 去除COW位 加上write位
pte_t flags=PTE_FLAGS(*pte);
flags &= ~PTE_COW;
flags |= PTE_W;
// printf("In cow set: cow:%d w:%d\n",flags&PTE_COW, flags&PTE_W);
*pte=PA2PTE(new_page) | flags;
return 0;
}4.引用计数机制
我们这里说是要COW,但是我们细想一下,采用COW会带来什么问题?
我们在释放一个页的时候,由于是COW,是不是可能有多个进程可能共享一个一样的映射,那么我们每个进程释放一个页的时候都把这个页放到空闲链表里边不是炸了吗。
所以我们需要解决这个问题,最直接的方法是,给每个页一个引用计数,当这个计数从1变成0的时候,我们就把这个页放到空闲页链表里边,如果是大于1的,我们只需要减小引用计数就行,如果等于0或者小于0,直接panic。
说起来简单,做起来还有一些细节要处理。
首先是数据结构,不要以为一个数组就完事了,由于多核多进程,我们得给这个数组加上一个全局锁,避免数据竞争。其次数组大小是多少呢?就是(PHYSTOP-KERNBASE)/PGSIZE,这里也可以看出来我们如何把一个物理页映射到数组的下标的,把上面的PHYSTOP换成物理页物理地址就行了。
以下是数据结构的定义:
#define INDEX(pa) ((pa - KERNBASE)>>12)
#define INDEXSIZE 32768//由KERNBASE到PHYSTOP共32768个页面
struct {
struct spinlock lock;
int count[INDEXSIZE];
} memref;然后在初始化的时候,我们得把引用计数变成1,变成1的原因是,在init的时候调用freerange,里面用的kfree,会把页面释放然后放到空闲链表里,然后页表引用计数就变成0了。
初始化如下所示:
void
kinit()
{
initlock(&kmem.lock, "kmem");
initlock(&memref.lock,"memref");
freerange(end, (void*)PHYSTOP);
}
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
{
// printf("%d\n",INDEX((uint64)p));
acquire(&memref.lock);
memref.count[INDEX((uint64)p)]=1;
release(&memref.lock);
kfree(p);
}
// kfree(p);
}这里要注意的就是别memset(memref.count,1,sizeof(...)),由于memset是按照字节分配的,这里要是这样写就直接变成010101了,直接炸掉。
接下来是kalloc,我们在成功分配一个页的时候只要把引用计数加一就好了:
void addref(uint64 pa)
{
acquire(&memref.lock);
memref.count[INDEX(pa)]++;
release(&memref.lock);
}
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
{
kmem.freelist = r->next;
addref((uint64)r);
}
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}最后是麻烦的kfree,首先我们理一下思路:
1.检查这个页面的引用计数是否大于1,如果是,直接调整引用计数然后返回
2.检查这个页面的物理地址范围。
3.对引用计数是1和0分别处理。
其实这个0应该放在最开始处理的,但是后来想了想,都是0,panic了,用原来的代码清空一遍也没啥影响了,但是还是要panic。
代码如下所示:
void
kfree(void *pa)
{
struct run *r;
// printf("In kfree:1 %d ref:%d\n",INDEX((uint64)pa),memref.count[INDEX((uint64)pa)]);
acquire(&memref.lock);
if (memref.count[INDEX((uint64)pa)]>1)
{
--memref.count[INDEX((uint64)pa)];
release(&memref.lock);
return;
}
release(&memref.lock);
// printf("In kfree:2\n");
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&memref.lock);
if (memref.count[INDEX((uint64)pa)]==0)
{
release(&memref.lock);
panic("kfree");
}
else if (memref.count[INDEX((uint64)pa)]==1)
{
--memref.count[INDEX((uint64)pa)];
release(&memref.lock);
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
else
{
release(&memref.lock);
panic("kfree");
}
}
5.修改copyout
首先我们要知道为什么要改copyout,因为我们在把内核数据复制到用户空间的时候,也就相当于在写用户的物理地址,如果这个时候对应的页表项是写时复制的,我们应该也做一次新的物理页的分配,也就是之前的handler_cow_pagefault函数。
注意,这里一定要先检查是否是COW的页面,如果不是,去直接调用这个函数是不合理的。
这里前面还得检查一下虚拟地址是否合法,不然在usertests里边会炸掉。
代码如下所示:
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
pte_t *pte;
if (va0 >= MAXVA)
{
return -1;
}
if ((pte=walk(pagetable,va0,0))==0)
{
return -1;
}
if (*pte & PTE_COW)
{
if(handler_cow_pagefault(pagetable, va0)<0)
{
return -1;
}
}
pa0 = walkaddr(pagetable, va0);
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}6.结果
cowtest:
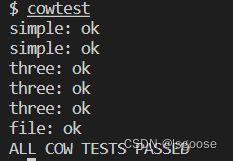
usertests:前面太长了
