架构选型之痛,如何构造 HTAP 数据库来收敛技术栈?
HTAP,是目前数据库领域比较流行的一个新理念。
近日,国际顶级专业分析机构 451 Research 发表了一篇关于 TiDB 的报告《PingCAP eyes US market with database targeting operational and analytical workloads》,其中就提到 TiDB 是一款同时面对在线处理业务和数据分析业务的混合数据库,也就是现在流行的新理念 HTAP。
此外,报告还很清晰地向数据库大鳄集中的美国市场宣布,中国狼来了。那什么是 HTAP?如何进行构造?本文我们就以 TiDB 为例一起详细解读下。

我们到底需要多少数据副本?
首先从业务数据副本数量开始。先问大家一个问题,在你们公司(假设在一个信息化比较完整公司),核心业务数据在整个公司数据生命周期里有多少份数据副本?这其实是个很大的问题。
按照主流概念,系统架构分为在线处理系统(OLTP)和在线数据分析系统(OLAP)。从数据流的角度,往往 OLTP 在上游、OLAP 在下游,中间还有一层数据通道,包括 WAl 等日志及相关解析工具,比如 MySQL 的 Syncer、Databus,以及数据队列(MQ)、数据清洗(ETL) 等。
在常规的高可用环境下,这三层数据都需要进行冗余,那么副本数量到底有多少?我们按照这几个阶段简单进行下统计。


OLAP 产品百花齐放
关注大数据的同学会发现,现在的大数据库产品在最近十年可以说百花齐放,涌现出了很多优秀技术栈以及对应的产品,比如 Hadoop 系的 HBase & Hive,搜索引擎 ES、Sorl,数仓组合 Kudu & Impala ,文档数据库 Mongodb 等等......这些产品都有表现很优秀的场景和特长。
但另一个现状是,每个产品适用场景都有相对清晰的边界(当然每个产品都在通过自身的迭代来扩展空间)。而业务需求是无边界的,所以很多大一点的公司在大数据层面都存在若干个 OLAP 产品。因此这里面隐藏了比较大的技术、人力成本,以及数据同步的成本,这造成的最直接结果就是在泛 OLAP 需求上存在很多数据副本。
大数据发展路线图:


业务系统(OLTP)为何也存在多副本?
相对 OLAP,OLTP 的技术创新相对会平淡很多。
从 DB engine 排名来看,近几十年,前几名一如既往的是那几个耳熟能详的关系型数据库。当然每个数据库产品都在按照自己的方向进行迭代、升级,Oracle 在技术层面持续领先和极致优化,MySQL 5.6 / 5.7 / 8.0 迭代越来越快,也有很多关键特性如 MGR、Innodb cluster、并行复制等、PostgreSQL 被评为2017年度数据库、SQL Server 得意于中型用户,近两年数据库市场份额在稳步提升。
但是这些传统的单机数据库,在存储容量、吞吐容量(读写 QPS)、单表行数方面都有一定的上限。以 MySQL 为例,为了满足业务更大的吞吐量需求,普遍采取分库分表的妥协方案(Sharding + Proxy),这套方案对应用侵入很大,而且还需要业务进行一定的妥协。比如,拆表会带来业务多维度查询的问题。以电商业务为例,分库分表往往是按照用户的维度进行拆分,但从业务角度,一定有商家维度查询或者其他某业务属性维度的查询,比如 deal、地域、门店、类型等等。那普遍作法是按照商家(或者某业务属性)再做一份数据,然后用双写或者异步队列的方式进行异步同步,中间还会根据需要维护一份多维度对应关系(Mapping)。这样业务多一个维度需求,就会多一份数据冗余,而在一些细分行业,业务维度是很难控制的,比如餐饮行业的报表 SaaS 服务,业务维度往往有十个之多。


我们真的需要这么多副本吗?
从高可用角度都需要进行数据副本冗余,如果有跨 IDC 高可用需求副本冗余再进行相应增加。在 master - slave,slave 普遍用于进行承担读流量,而在实际情况下,由于读容量及不同读流量的隔离考虑,往往是一主 N 从库。再加上分表后多维度的问题,假设需要 M 个维度,那么在 OLTP 场景下,副本数据量就变成了 (1+N)*M。
数据通道会有份 WAL 日志,以及日志解析后的队列,算上高可用的至少一份冗余,那么数据通道至少会存在 2-3 X 副本(X 是技术栈数量),最后数据流入中台系统,以及大数据分析用的后台系统(OLAP)。
假如 OLAP 场景有 Y 个技术产品,同样以三份冗余进行高可用,那么整个副本数量变成了 (1+N)*M + 2X + 3Y。
场景分类 |
代表业务系统 |
预计数量 |
合计 |
OLTP |
业务系统 |
M = 3 N = 2 |
9 |
数据通道 |
日志、队列等 |
X = 2~3 |
4~6 |
OLAP |
数据查询平台(中台)、ODS、数据仓库等 |
Y = 3 |
9 |
总计 |
— |
(1+N)*M + 2X + 3Y |
24 |
如何在满足各种业务需求的同时,尽量减少副本数量、收敛技术栈就变的很重要,所以构造一款能同时支持在线处理业务和在线分析业务的混合数据库(HTAP),就是一个非常理想的解决方案。


如何构造 HTAP?
既然如此,那么如何构造 HTAP?
其实最早的混合数据库还要从 Oracle 说起。在最早期,Oracle 就通过针对性的技术点,比如分区、并行计算、位图索引、Hash Join、物化视图、单次 IO 吞吐量等技术点来支持 OLAP 场景。
正如前文所说,单机数据库的容量限制制约了其在海量数据场景下的使用,而与此同时 OLTP 业务更关注的是并发能力、事务、实时更新、响应时间,而 OLAP 业务更关注的是容量、计算能力、吐吞量等。所以 OLTP、OLAP 为了面对各种的需求,一个再分、一个再合,从技术实现上开始分道扬镳。
因此,在海量数据下如果要实现 HTAP 需要满足至少以下几点:
底层数据要么是一份,要么可以快速复制,并且要同时满足高并发的实时更新;
要满足海量数据的容量问题,在存储、计算、吞吐量都具有很好的线性扩展能力;
表最好不要进行分片,至少在逻辑层需要是一张表,尽量避免去处理跨分片 Join 的问题;
要充分利用分布式多节点优势,要有很好的并行计算、并行 IO 扫描能力,不管是表扫描还是索引扫描;
有很好的优化器,支持多种关联算法,如 Hash Join、Sort Merge 等;
既要支持 OLTP 必须的事务、标准 SQL,高并发读写、二级索引,还要支持诸如分区表、并行下推计算、bitmap(或者列引擎)、并行数据寻址、向量化等 OLAP 常用技术。

新一代数据库 TiDB 在 HTAP 的尝试
首先要解决数据库容量和吞吐量的问题,而且是在不进行分表前提下。
熟悉 TiDB 的同学应该知道,TiDB 在存储层通过自动分片分裂技术(auto region split)实现了逻辑表与底层分片一对多的关系(可以理解就是一张表),避免了分表 Join 问题,并且通过在不同字段支持二级索引的方式,规避里分库分表业务多维度查询的问题。具体这块不展开,大家可以关注官网进行架构解读(https://pingcap.com/docs-cn/)。
尽可能地利用本地(存储)计算能力。
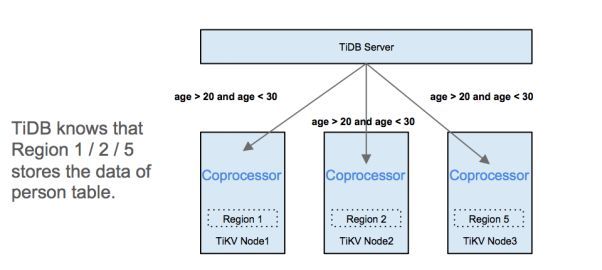
TiDB 底层是个分布式存储系统,每个存储节点都有自己独立的计算层(Coprocessor)和缓存层,我们可以采取最大程度的下推策略(谓词、计算、小表广播等)来尽可能地利用本地(存储)计算能力。
这样实现了一个类似 MPP 的并行计算模型。不但大规模地减少网络交互,还极大提升了整个集群的并行计算能力,如下图:
具有多种表关联算法。
大家都知道,MySQL 里所有表的关联只有嵌套循环一种算法(Nest Loop)。嵌套循环其实就是两层循环,数据量较少外层(驱动表)数据集(表)取一条数据,然后和数据量较大的内层(被驱动表)数据集(表)进行逐条匹配。这种算法是响应时间优先,只适合于小表做驱动表的情况,对最后匹配数据(吐吞量)并不友好。
这个有点类似当下流行的相亲会节目《非诚勿扰》,每次就四五个男生(小表)作为驱动表逐个亮相,然后被一群女嘉宾(大表)进行选择。假如男生数量也很多,显然这种算法就会很低效,尤其是当你更关注最终结果时候(吐吞量优先业务,比如想知道最终相亲成功多少对),所以这种算法远远不够,尤其是我们要面向更大量的数据时候。
所以 TiDB 表关联的时候不但支持 Nest Loop,还支持 Hash Join 、Sort Merge 、Index Join 对吐吞量更友好的算法。同时在进行 Hash Join 的过程与驱动表还支持并行匹配,而数据寻址过程不管是表还是索引都支持并行扫描,这些都变得很重要。具体见下图:

计算与存储分离。
我们可以在存储系统部署不同的计算层。除了默认的 TiDB Sever,我们还可以借助 Spark 平台本身的优势,同时融合 TiKV 分布式集群的优势,让 Spark 识别存储层数据格式、索引结构、统计信息等,进而实现计算下推、CBO、二级索引等功能。最终我们可以提供 TiSpark 的解决方案,面向索引筛选粒度很低,甚至没有很好索引的大表复杂查询场景。
除了默认的行存数据库,拼图上还需要一款列存储引擎。
在列式数据库里,数据是按照列进行存储,每一列单独存放,数据即是索引。由于数据类型一致,会有非常高的压缩比,应用只需查询对应的列,所以整个扫描的 I / O会很低。同时列存也非常适合批量数据处理、即时查询,尤其是聚合、分析查询。
所以在 TiDB 架构上,我们选择一个异步的同步副本存储在列存储引擎上,面对更重、更复杂的聚会等查询。进而实现了底层两款不同的存储引擎、上层两款不同的计算引擎组合架构。具体见下图:


SQL ON TiDB
如果我们把 SQL 按照复杂程度做个几层分类,TiDB 至少以下四个级别的场景都有对应的解决方案和思路,包括:
高并发的实时写入更新、随机点查、范围查(典型 OTLP);
多表及大表关联等一般复杂查询(数据中台);
索引过滤低的高吞吐计算查询(OLAP);
复杂聚合、分析等重查询(OLAP)。
具体见下图:

当然我们并不是想表达 TiDB 就是 HTAP 的银弹。就像前面所说的,在数据库产品体系中,尤其是 OLAP 技术栈百花齐放,每个产品都有表现非常好的场景,TiDB 并不是要替换谁,设计思路是从最上游业务系统就接入数据,用底层复制技术来替换传统的数据通道,进而实现数据的实效性。然后再通过不同的计算层、不同的存储层来面对不同的业务需求,同时依赖自身的架构优势,可以实现通过增加计算节点、存储节点来实现读、写、存储容量的线性扩展,通过设置、分配后台不同等级队列、副本读、Slave cluster 等思路来实现 OLTP 查询和 OLAP 查询底层的资源隔离。
这样就给大家提供一个新的选择,尤其对不想花很大精力去维持多个技术产品、平台,或者对数据分析有一定实效性的需求的公司。
![]()
最后
TiDB 是先致力解决 OLTP 单机容量的问题,在这个场景相对于传统的 Proxy + Sharding 优势很大。但与此同时,我们也发现在很多业务中台、OLAP 也有很好的场景,尤其是在一些垂直行业。
比如餐饮行业的 SaaS 服务,他们会为商家提供各种业务维度的统计报表,这些业务维度高达十个之多。最早商家总是质疑:既然我们的订单、外卖、排队、营销等等都是实时产生数据,为何相关维度报表要 T+1 之久?最早服务商会通过加机器、预处理、Mapping 等手段去优先少部分业务维度需求,显然这种处理方式性价比很低,而且商家也不太理解(有的时候,使用者不懂技术会成为一种生产力)。
而在 TiDB 里,不需要分表,这些维度都可以简单抽象成某字段列二级索引的形式进行满足,进而实现真正意义的任意业务维度实时报表。目前这个垂直行业大部分提供商都已经上线或者 POC TiDB 中。
在《汽车总动员三》中,大家发现除了我们喜爱的闪电麦昆外,这条赛道里涌现了很多新的面孔。而在数据库的漫长赛道里,从 EF.Codd 提出关系型数据库模型到现在,关系型数据库已经在主导这个赛场近半个世纪,而本世纪初大数据滋生了十年之久 NoSQL 的思潮,产品可以说百花齐放。
在此基础之上,近几年各种 NewSQL 产品也逐步崭露头角。正如前文所述,喜闻乐见的是在这场新的角逐了也涌现了很多中国力量。正如那个有趣的《吓尿指数理论》,数据库变革也在加速。在新的赛场上,下一个明星可能是新一代的黑风暴杰克逊,或者是那个一直不被看好的小妞酷姐拉姆雷斯。
作者:房晓乐(dbaoutdo),PingCAP 架构师,前美团点评数据库专家,前搜狗、百度资深 DBA。
声明:本文为作者投稿,版权归作者个人所有。
