Python3进阶--项目打包、类和对象高级、序列、迭代器、生成器、装饰器
第一章 变量、常用循环体、代码结构、代码练习
第二章 列表、元组等数据结构、字符串驻留机制及字符串格式化操作
第三章 函数、面向对象、文件操作、深浅拷贝、模块、异常及捕获
第四章 项目打包、类和对象高级、序列、迭代器、生成器、装饰器
第五章 正则表达式、json、logging日志配置、数据库操作、枚举、闭包、匿名函数和高阶函数、time、datetime
第六章 Socket编程、多线程(创建方式、线程通信、线程锁、线程池)
项目打包
先安装第三方模块
pip install PyInstaller
执行打包操作:
-F :指定文件
pyinstaller -F E:....\stusystem.py
windows系统时,打包后,会获得一个exe可执行文件,打包完成
执行即可

知识点
-
随机数
import random random.randint(1000,1500) # 获取1000-1500之间的随机数 -
展示列表中 索引和值
year = [88, 82, 89, 29, 30]
for index, value in enumerate(year):
print(index, value)
# 输出
0 88
1 82
2 89
3 29
4 30
-
lambda表达式
stu_list = [{'english':90},{'python':80}] stu_list.sort(key=lambda x: int(x['english'])) # lambda表达式 -
手动抛出异常
抛出的异常,由except捕获
try: raise Exception('程序错误') except Exception as e: print(e) -
时间格式化
import time ls = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())) print(ls)
Python类和对象高级
python中一切皆对象
-
python(动态语言)的面向对象比Java(静态语言)面向对象更加地彻底。
-
python中的
类和函数,都属于对象,都是python的一等公民- 可赋值给一个变量
- 可以添加到集合对象中
- 可以作为参数传递给函数
- 可以当做函数的返回值
def ask(name='bobby'): print(name) class Person: def __init__(self): print('bobbyPerson') def print_type(item): print(type(item)) my_func = ask # 函数赋值给变量 my_func('java') my_class = Person # 类对象赋值给变量 my_class() obj_list = [] obj_list.append(ask) # 添加到列表 obj_list.append(Person) # 添加到列表 for i in obj_list: print(i()) print_type(ask) # 作为参数传递 print_type(Person) # 作为参数传递 def decorator_func(): print('dec start') return ask # 作为返回值传递 my_ask = decorator_func() my_ask('tom')
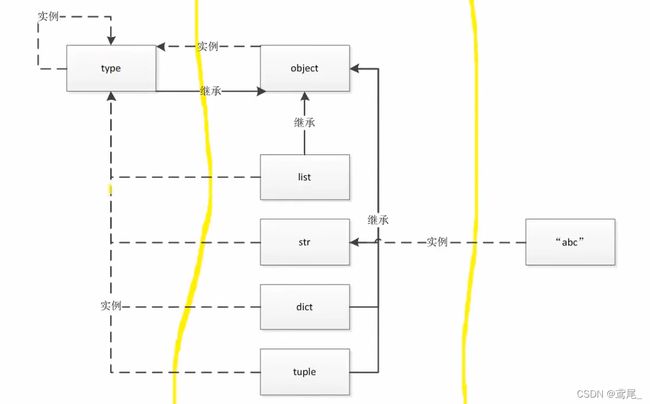
type、object和class的关系
type —> class(类) —> object(实例对象)
type生成类对象,类对象可实例化为实例对象
object是最顶层的基类,所有对象的类型最后都会推导出object是最顶层父类
print(type(1)) # type类的基类(父类)
print(object.__bases__) # () object类的基类(父类)
object是type的实例(所有对象都是type的实例),而type又继承了object
同时type也是type自身的实例
如下str是类,同时也是type的实例(实例对象),也叫对象
设计理念::为了动态修改类属性,类方法…(像java中修改类信息时,会用到java的反射之类的知识点较为复杂,而Python是不需要的,直接修改即可,这就是python设计一切皆对象的好处)
python中常见内置类型
- 变量的组成或者叫对象的三个特征(id,type,value)
- None(全局只有一个)
- 迭代类型
- 序列类型
- list
- range
- str…
- 映射类型(dict)
- 集合
- set
- frozenset
- 上下文管理类型(with)
魔法函数
什么是魔法函数?
双下划线开头,双下划线结束
一定要使用python定义好的魔法函数,不然是没有用处的
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __getitem__(self, item):
return self.employee[item]
company = Company(['tom', 'job', 'jane'])
for em in company: # 会去调用 __getitem__()函数,并依次将索引传入参数
print(em) # 实际上会先去找 __iter__() 函数,找不到则去找 __getitem__()函数
company1 = company[:2] # 还可以进行切片操作(序列类型)
如果以上不创建 __getitem__()函数,下面遍历时会报错,该对象不是一个可迭代类型
也就是说,我们在Company类对象中创建了一个魔法函数__getitem__(),使Company的实例对象变成了一个可迭代的对象,并且每次迭代都会去调用__getitem__()方法
定义魔法函数:将会直接影响到python语法,而且魔法函数不需要手动调用,python解释器会去帮我们调用
鸭子类型和多态
鸭子类型
当看到一只鸟走起来像鸭子,叫起来像鸭子,那么这只鸟就可以被称之为鸭子。
表现为,我们可以通过使用魔法函数,使某一些对象具备一些类型
比如,一个类对象添加了一个魔法函数__getitem__(),那么它就成为了一个可迭代对象。
多态(纯天然,不必像静态语言一样需要满足某些条件)
直接调用方法即可,只要方法名相同,传入任何类型都可以
class Cat:
def say(self):
print('i am a cat')
class Dog:
def say(self):
print('i am a dog')
animal_list = [Cat, Dog]
for i in animal_list:
i().say() # i am a cat i am a dog
抽象基类(abc模块) 类似java接口
抽象基类:
- 不能实例化
- 单继承
- 子类需要实现父类的方法
判断对象是否是某种类型(包括基类)
isinstance(obj, type) # 判断对象是否是某种类型(包括基类)
模拟一个抽象基类·
不经常使用0.0,了解一下
import abc
class CacheBase(metaclass=abc.ABCMeta):
@abc.abstractmethod
def get(self, key):
pass
@abc.abstractmethod
def set(self, key, value):
pass
class RedisCache(CacheBase): # 继承自CacheBase类后,未重写父类抽象方法
pass
class RedisCache(CacheBase): # 继承后,重写所有抽象方法
def get(self, key):
pass
def set(self, key, value):
pass
redis_cache = RedisCache() # 如果RedisCache没有重写CacheBase中所有抽象方法
# 那么会程序报错,抛出异常
类和实例属性的查找顺序
class A:
name = 'A'
def __init__(self, age):
self.age = age
a = A(20)
print(a.name) # 先找 实例对象中有没有 name属性,发现没有再去A类中找类属性
当存在复杂继承关系时,可使用__mro__查看查找顺序
print(A.__mro__)
类方法和静态方法
class Date:
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
@staticmethod
def parse_from_str(date_str):
year, month ,day = date_str.split('-')
return Date(int(year),int(month),int(day)) # 采取硬编码Date类对象
@classmethod
def parse_str(cls, date_str):
year, month, day = date_str.split('-')
return cls(int(year), int(month), int(day)) # 可直接返回 cls本身
上下文管理器高级
import contextlib
# 使之成为一个上下文管理器 利用了生成器的作用
@contextlib.contextmanager
def file_open():
print('file_open...')
yield {} # yield之前的相当于是 __enter__()函数的内容 yield之后的代码块 相当于__exit__()函数的内容
print('file_end...')
with file_open() as fi:
print('file processing') # 此代码块执行时,位置是 上面 yield{} 中的代码块
# 执行结果
file_open...
file processing
file_end...
isinstance() 和 type()区别
isinstance(obj,type)判断时,会去找继承链,如果obj的类型是继承自type(某一种类型,不是指type类),那么返回结果为Truetype(): 返回当前对象的类型
序列
序列分类
- 容器序列(可放入多个元素):list、tuple、deque
- 扁平序列:str、bytes、bytearray、array.array
- 可变序列:list、deque、bytearray、array
- 不可变序列:str、tuple、bytes
序列类型的abc继承关系
# abc模块,进入abc模块可查看
from collections import abc
list的extend方法
# +
a = [1,2]
c = a + [3, 4] # [1,2,3,4]
c = a + (3, 4) # 直接报错。。
# +=
a = [1,2]
a += (3,4) #[1,2,3,4]
a += [3,4] #[1,2,3,4]
# += 实际是调用了 __iadd__()魔法函数,是调用了extend方法
a = [1,2]
a.extend(range(3)) # [1,2,0,1,2]
实现可切片的对象
import numbers
class Group:
def __init__(self, group_name, company_name, staffs):
self.group_name = group_name
self.company_name = company_name
self.staffs = staffs
def __getitem__(self, item): # 实现切片的关键是,定义__getitem__()魔法函数
cls = type(self)
if isinstance(item, slice): # 如果item是 slice类型(切片类型)
return cls(self.group_name, self.company_name, self.staffs[item])
elif isinstance(item, numbers.Integral): # item是 数字类型
return cls(self.group_name, self.company_name, [self.staffs[item]])
def __contains__(self, item): # 判断对象是否在Group实例对象的staffs列表中
if item in self.staffs:
return True
else:
return False
staffs = ['bobby1', 'bobby2', 'bobby3']
group = Group('user', 'immoc', staffs)
sub_group = group[:2]
sub_group = group[0]
'bobby1' in group # True 解释器去找__contains__()魔法函数
bisect维持已排序的序列
简介:
bisect是python内置模块,用于有序序列的插入和查找。
- 查找: bisect(array, item)
查找该数值将会插入的位置并返回,而不会插入 - 插入: insort(array,item) 会自动维持顺序
特点:
- 二分查找效率高
- 维持顺序
import bisect
inter_list = []
bisect.insort(inter_list, 3) # 插入元素
bisect.insort(inter_list, 2)
bisect.insort(inter_list, 1)
bisect.insort(inter_list, 5)
print(inter_list) #[1, 2, 3, 5]
print(bisect.bisect_left(inter_list, 0)) # 获取元素0的插入位置,遇到相同元素时,返回相同元素左边的位置
array
array和list的区别:
- array只能存放指定类型的数据
import array
my_array = array.array('i') # 只接受int类型数据
my_array.append(1)
my_array.append('abc') # 报错
列表生成式
列表生成式性能高于列表操作,建议多用,但是逻辑过于复杂的话不建议使用(增强代码的可读性)
# 列出 1-20之间的奇数
# 当i是奇数时,返回给 for 前面的 i
o_list = [i for i in range(1,21) if i % 2 ==1]
# 复杂逻辑 奇数平方
def handle_item(item):
return item**2
o_list = [handle_item(i) for i in range(1,21) if i % 2 ==1]
生成器表达式
o_list = (i for i in range(1,21) if i % 2 ==1) # 是一个生成器对象,可以遍历,也可以转换为list列表
字典生成式
# 将字典中 key和value互换
my_dict = {'bobby1':22, 'bobby2':23,'wlh':21}
reversed_dict = {value:key for key,value in my_dict.items()}
集合生成式
# 把所有的key放入my_set中
my_dict = {'bobby1':22, 'bobby2':23,'wlh':21}
my_set = {key for key,value in my_dict.items()} # 方式一:可加入逻辑判断 集合生成式
my_set2 = set(my_dict.keys()) # 方式二:单一,不能判断
set和dict
dict
- dict属于Mapping类型
a = {}
# dict类型实现了一些MutableMapping的魔法函数,满足MutableMapping协议
# 所以它被判断为是MutableMapping类型(鸭子类型)
isinstance(a, MutableMapping)
dict类型的方法
- fromkeys (生成一个dict)
- setdefault(key,value) 添加一对k-v,并且返回value值(效率高)
- update() 添加至少一个k-v
lst = ['joke','python']
new_dict = dict.fromkeys(lst, 1) # 生成一个dict,key是 joke、python,value都是1
default_value = new_dict.setdefault('java',2) # 新增元素,并且返回value
print(default_value) # 2
print(new_dict) # {'joke': 1, 'python': 1, 'java': 2}
# 方式一
new_dict.update(a = '1', b = '2')
# 方式二
new_dict.update([('a','1'),('b','2')]) # {'joke': 1, 'python': 1, 'java': 2, 'a': '1', 'b': '2'}
UserDict
一般情况下,不建议去继承list和dict
可以去继承c语言模拟的类UserDict
from collections import UserDict
class MyDict(UserDict):
def __setitem__(self, key, value):
super().__setitem__(key, value*2)
my_dict = MyDict(a = 1)
print(my_dict) # {'a': 2}
defaultdict类
此类实现了__missing__()魔法函数,可处理当[key]找不到key时,自动设置一个默认值
可以去继承它,也可以直接使用
from collections import defaultdict
my_dict = defaultdict(dict)
my_value = my_dict['a']
print(my_value) # 默认值是一个空字典 {}
set和frozenset(不可变集合)
s = set('abcde') # 接收可迭代对象
a.add('c') # 可新增
s = forzenset('abcde') # 定义好后,就不能更改了(不可变的集合),一般可作为dict的key
set性能很高,要记住set集合关系运算的几种操作,很方便
a,b = {1,2},{1,3}
a & b # 取交集
a | b # 取并集
a ^ b # 取对称差集
a - b # 取差集
dict和set实现原理
dict和list性能
-
dict的查找性能远远大于list
dict采用k-v存储方式,直接根据k可找到value值,时间复杂度是o(1)的存在
-
在list中,随着list数据量增大,查找时间成正比
-
在dict中,不会随着dict数据量增大而查找时间增大
-
根据key的hash值计算元素的存储位置
set
-
set其实也是根据key的hash值计算元素的存储位置,不同的是set只有key没有value
-
元素必须是一个可hash的元素(实现了
__hash__()魔法函数)
对象引用和垃圾回收
对象引用
python中一切皆对象,一个变量的组成由id标识、type类型和value值组成
id标识就是对象的引用地址
is比较id标识
class Person:
pass
p = Person()
print(type(p) is Person) # True
垃圾回收
算法是采用引用计数
当一块内存地址被标识(变量)指向时,引用计数+1,当一块内存地址被标识(变量)取消指向后,引用计数-1,当引用计数变成0时,python会进行垃圾回收,清理内存。
a = 1
b = a
del a,b # 此时1这个值的计数器-2 然后1 这个值在内存中会被删除
__del__()魔法函数,当元素被 del的时候会去调用,我们可以按照自己的逻辑定义
常见参数错误
类中定义的列表默认值
class Company:
def __init__(self, name, staffs=[]):
self.name = name
self.staffs = staffs
def add(self, staff_name):
self.staffs.append(staff_name)
def remove(self, staff_name):
self.staffs.remove(staff_name)
com1 = Company("com1")
com1.add("jane1")
com2 = Company("com2")
com2.add("jane2")
# 而com3不使用默认值
com3 = Company("com3",["jane3"])
print(com1.staffs) # ['jane1', 'jane2']
print(com2.staffs) # ['jane1', 'jane2']
print(com3.staffs) # ['jane3']
# 由于com1和com2都是使用的[]默认值,也就是Company.__init__.__defaults__的值,所以两个对象中的staffs列表都指向了一个内存
# 但是com3的staffs列表传入了参数,没有使用默认值,那么staffs就不会指向Company.__init__.__defaults__
元类编程
property动态属性
from datetime import date, datetime
class User:
def __init__(self, name, birthday):
self.name = name
self.birthday = birthday
self._age = 0
@property # 类似java的get方法
def age(self):
# 2022-1999
return datetime.now().year - self.birthday.year
@age.setter # set方法
def age(self,value):
self._age = value
if __name__ == '__main__':
user = User('bobby', date(year=1999,month=1,day=1))
user.age = 19 # 赋值后,调用了 @age.setter下的age(self,value)方法
print(user._age) # 19
print(user.age) # 23 # 调用的 age(self)方法
魔法函数(getattr、getattribute)
__getattr__(): 查找不到属性
# __getattr__() 在查找不到属性的时候调用此魔法函数
from datetime import date, datetime
class User:
def __init__(self, name, birthday):
self.name = name
self.birthday = birthday
def __getattr__(self, item):
return "not find attr"
if __name__ == '__main__':
user = User('bobby', date(year=1999,month=1,day=1))
print(user.age) # 一般查找不到属性,直接报错了,但是写了 __getattr__(),返回了字符串
# 所以打印 not find attr
----------------------------------------------------------------------
# 练习二
class User:
def __init__(self, info={}):
self.info = info
def __getattr__(self, item):
return self.info[item]
if __name__ == '__main__':
user = User(info={'company_name':'immoc', 'name':'jane'})
print(user.name) # jane
# user.name,由于找不到属性,调用getattr魔法函数,然后返回 info[item]的值
__getattribute__(): 无条件调用,只要调用实例属性,就走__getattribute__函数
优先级比 __getattr__()高
class User:
def __init__(self, info={}):
self.info = info
def __getattr__(self, item):
return self.info[item]
def __getattribute__(self, item):
return "boss"
if __name__ == '__main__':
user = User(info={'company_name':'immoc', 'name':'jane'})
print(user.name) # boss
# 只要写了 __getattribute__()魔法函数,只要调用实例属性,就会走getattribute函数
属性描述符
只要实现了__get__()、__set__()、__delete_()任何一个魔法函数,那么这个类就被称为是属性描述符
可对值进行校验抛出异常
import numbers
class IntField:
def __set__(self, instance, value):
if not isinstance(value, numbers.Integral):
raise ValueError('int value need')
self.value = value
def __get__(self, instance, owner):
return self.value
class User:
age = IntField() # 指向IntField对象
if __name__ == '__main__':
user = User()
user.age = 30 # 给age赋值时,会去调用IntField的 set方法魔法函数
print(user.age) # 获取时,调用IntField的 get方法魔法函数
属性查找顺序
如果user是某个类的实例,那么user.age(以及等价的getattr(user,‘age’)),会去首先调用 __getattribute__()。
如果类中定义了,__getattr__(),那么在 __getattribute__()抛出异常的时候会去调用__getattr__(),
而对于属性描述符(__get__())的调用,是发生在__getattribute__()内部的
user = User()
user.age # 的调用顺序 1-5
1. 如果'age'出现在User或者基类的__dict__中,并且 age是 data descriptor(数据属性描述符),那么就会调用__get__() 方法
2. 'age'如果出现在 user的__dict__中,那么直接返回 user.__dict__['age'],否则
3. 如果'age'出现在User或者基类的__dict__中,并且 age是 non-data descriptor(非数据属性描述符),那么调用 __get__()方法,否则直接返回 __dict__['age']
4. 如果User有 __getattr__方法,调用__getattr__()
5.抛异常
顺序:
- 数据属性描述符
__get__() - 直接调用对象属性
- 非数据属性描述符
__get__() - 类属性
__getattr__- 抛异常
new和init
__new__():用来控制对象的创建的__init__():给对象中的属性进行初始化赋值,如果__new__()中没有返回创建的对象,那么__init__()魔法函数将不会执行的
自定义元类
动态返回类对象
type:创建类的类,可使用type(obj)查询对象类型,同时也可以使用type()创建一个类对象
方式一:
def create_class(name):
if name == "user":
class User:
def __str__(self):
return 'user'
return User
elif name == "company":
class Company:
def __str__(self):
return 'company'
return Company
if __name__ == '__main__':
user = create_class('user')() # 创建User实例对象
print(user) # user
方式二: type()创建类
type(name,bases,attrs)
- name:类名 str类型
- param2:继承自 tuple类型
- param3:属性 dict字典类型
def say(self):
return f'i am {self.name}'
if __name__ == '__main__':
# 方式一 :位置传参
User = type('User',(), {'name':'wlh','say':say}) #创建了一个User类对象,name属性,say实例方法
# 方式二:关键字传参
User = type(name ='User',bases = (),attrs = {'name':'wlh','say':say})
obj = User()
print(obj) # <__main__.User object at 0x0000019F1172FFD0>
print(obj.name) # wlh
print(obj.say()) # i am wlh
什么是元类
元类是创建类的类,比如type就是元类,控制类的创建。
python中类的实例化过程,会先去寻找metaclass,通过metaclass去创建类
找不到metaclass的话,就使用type()创建对象
class MetaClass(type):
def __new__(cls, *args, **kwargs):
return super().__new__(cls, *args, **kwargs)
class User(metaclass=MetaClass):
def __init__(self, name):
self.name = name
def __str__(self):
return 'user'
if __name__ == '__main__':
my_obj = User('jane')
print(my_obj)
获取对象属性方法
-
getattr(obj,key,None) : 获取对象属性值
# 取的对象的某个属性值,后面可以设置默认值None getattr(obj, 'db_column', None) -
setattr(obj,key,value) : 设置对象属性值
setattr(obj, 'a', 1)
python3 迭代器和生成器、装饰器
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
迭代器的定义:
- 类中定义了
__iter__和__next__两个方法 __iter__方法需要返回对象本身,即:self__next__方法,返回下一个数据,如果没有数据了就要抛出StopIteration的异常
迭代器的使用
可迭代的类型:list、tuple、string、set、dict
其中list,tuple,string都是有序的迭代类型,我们可以按照顺序迭代,而set和dict是无序的,我们不知道next下一个元素是谁
- 字符串,列表或元组对象都可用于创建迭代器:
lst = [1,2,3,4]
it = iter(lst) # 创建迭代器对象
print(next(it)) # 1
print(next(it)) # 2
- 迭代器对象,可使用for进行遍历
lst=[1,2,3,4]
it = iter(lst) # 创建迭代器对象
for x in it:
print (x, end=" ") # 1 2 3 4
自定义迭代器(不常用)理解
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__() 。
__iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 next() 方法并通过 StopIteration 异常标识迭代的完成。
__next__() 方法会返回下一个迭代器对象。
创建一个返回数字的迭代器,初始值为 1,逐步递增 1:
class MyNumbers:
def __iter__(self): # iter(obj)执行时,会执行这里,并且返回自己(由于实现了 __iter__() __next__(),所以就是返回了迭代器对象)
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myc = MyNumbers()
myiter = iter(myc) # 获取迭代器对象
print(next(myiter)) # 1
print(next(myiter)) # 2
print(next(myiter)) # 3
StopIteration
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 __next__() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
class MyNumbers:
def __iter__(self): # iter(obj)执行时,会执行这里,并且返回自己(由于实现了 __iter__() __next__(),所以就是返回了迭代器对象)
self.a = 1
return self
def __next__(self):
if self.a <= 5:
x = self.a
self.a += 1
return x
else:
raise StopIteration
myc = MyNumbers()
myiter = iter(myc) # 获取迭代器对象
print(next(myiter)) # 1
print(next(myiter)) # 2
print(next(myiter)) # 3
print(next(myiter)) # 4
print(next(myiter)) # 5
print(next(myiter)) # 抛异常
生成器(边迭代边输出)
- ()作为推导式,就会得到一个生成器。目的:边迭代边输出,只有用到了元素才会去生成(资源较大)
from collections.abc import Iterable
gen = (i for i in range(1,4000000000)) # 使用推导式创建 生成器
print(isinstance(gen, Iterable)) # True 是一个可迭代对象
print(next(gen)) # 1
print(next(gen)) # 2
- 自定义生成器
使用yield关键字实现斐波那契数列
每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
def fibonacci(n):
a, b = 0, 1
count = 0
while True:
if count > n:
break
yield a
a, b = b, a + b
count += 1
gen = fibonacci(100000000000) # 并不会进行卡顿,因为生成器是需要的时候才生成
for i in gen:
if i > 1000:
break
print(i, end="\t") # 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
装饰器Decorator
装饰模式(设计模式相关)
在不改变目标函数代码的情况下,对目标函数进行业务增强
无参装饰器
例如:要对目标方法进行登录验证
def login_check(func):
def wrapper():
print('login check ..')
func()
return wrapper
@login_check
def f1():
print('this is fun1')
def f2():
print('this is fun2')
f1() # login check .. this is fun1
f2() # this is fun2
当有多个装饰器使用在一个函数上时,优先级会按照顺序执行
@login_check # login_check先执行
@time_check # time_check后执行
def f1():
print('this is fun1')
有参装饰器
def login_check(func):
def wrapper(*args, **kwargs):
print('login check ..')
func(*args, **kwargs)
return wrapper
@login_check
def f1(x):
print('this is fun1', x)
@login_check
def f2(x, y, **kwargs):
print('this is fun2', x, y)
print(kwargs)
f1('abc') # login check .. this is fun1
f2('hello', 'python',a=1,b=2) # login check .. this is fun2 hello python {'a': 1, 'b': 2}