Apache Hadoop YARN详解
官方文档Apache Hadoop YARN: https://hadoop.apache.org/docs/r3.3.5/hadoop-yarn/hadoop-yarn-site/YARN.html
一、什么是Yarn ?
YARN(Yet Another Resource Negotiator,另一种资源协调者)是hadoop2.0后推出的一个资源管理器。YARN是一个通用资源管理系统和调度平台,负责为运算程序提供服务器计算资源,相当于一个分布式的操作系统平台,而 MapReduce、Spark、Flink 等运行程序则相当于运行于操作系统平台之上的应用程序。

MRv2重用了MRv1中的编程模型和数据处理引擎 。但运行时环境(ResourceManager、NodeManager)被完全重写,由YARN来专门进行资源管理和任务调度。
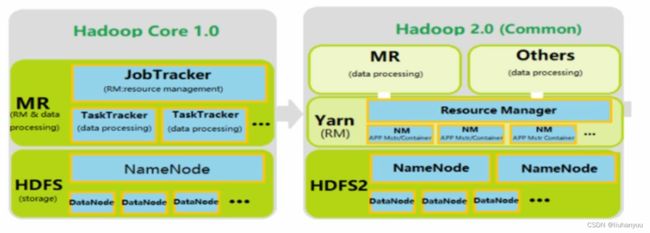
Apache Hadoop YARN是一个主从架构集群,其中ResourceManager为Master,NodeManager为Slave。
常见的是一主多从集群,也可以搭建RM的HA高可用集群,也就是多主多从集群。
二、YARN的架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container组成,其中ResourceManager和NodeManager是物理集群层面的节点,ApplicationMaster是应用层面的应用,Container(Resource Container,简称Container)是一个抽象的资源分配单位。

1、ResourceManager(全局资源管理)
ResourceManager(RM)为YARN中的主角色,是一个全局的资源管理器,负责整个系统的资源管理和分配。RM接收用户的作业提交,并通过NodeManager分配、管理各个机器上的计算资源。
ResourceManager(RM)主要包括两个组件,即调度器(Scheduler)和应用程序管理器(Applications Manager)。
调度器
调度器根据容量、队列等限制条件将系统中的资源分配给各个正在运行的应用程序中,需要注意的是,该调度器是一个纯调度器,它不再从事任何与具有应用程序相关的工作,调度器仅根据各个应用程序的资源需求按照container进行资源分配。此外该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供多种直接可用的调度器,比如 fair scheduler和capacity scheduler等。
应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重启它等。
2、NodeManager(节点上的资源和任务管理器)
NodeManager是YARN中的从角色,是每个节点上的资源和任务管理器。一方面(执行),它根据ResourceManager的命令,接收并处理来自AM的container启动/停止等各种请求;另一方面(监视),它会定时地向RM汇报本节点上的资源使用情况和各个container的运行状态,使得ResourceManager能统一管理全局资源。
3、ApplicationMaster(监控应用执行)
ResourceManager接收用户提交的作业,按照作业的上下文信息以及从NodeManager收集来的容器状态信息,启动调度过程,为用户作业启动一个ApplicationMaster。负责监控或者跟踪应用的执行状态、重新启动因应用程序失败或者硬件故障而产生的失败任务等。
4、Container(动态资源分配单位)
容器(Container)作为动态资源分配单位,将内存、cpu、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。当AM向RM申请资源时,RM为AM返回的资源便是Container表示的,YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。
三、Yarn集群的部署
集群部署原则
1、理论上YARN集群可以部署在任意机器上,但是实际中,通常把NodeManager和DataNode部署在同一台机器上。(有数据的地方就有可能产生计算,移动程序的成本比移动数据的成本低)。
2、作为Apache Hadoop的一部分,通常会把Yarn集群和HDFS集群一起搭建。
| 服务器 | 运行角色 |
| 节点1 | NameNode、DataNode、ResourceManager、NodeManager |
| 节点2 | SecondaryNameNode、DataNode、NodeManager |
| 节点3 | DataNode、NodeManager |
| ... | 后续扩展只需要增加DataNode、NodeManager |
四、Spark向Yarn提交任务的基本流程
1、client模式
- Cluster模式:
- Client提交Application到ResourceManager,RM分配Container并在对应NM上启动ApplicationMaster,启动Driver进程,并向分配的节点分配Executor进程。
- Application Master节点向ResourceManager申请资源(节点和内存)来运行Spark作业。
- ResourceManager根据可用资源的数量和分配策略向Application Master节点分配节点和内存。
- Driver进程负责解析应用程序代码、设置作业配置、构建RDD(弹性分布式数据集)和DAG(有向无环图)等,最后将任务分配给Executor进程。
- Executor进程运行计算任务,读取数据和中间结果,将结果写入HDFS或其他存储系统中,并向Driver进程报告任务的进度和结果。
- Driver进程收集和汇总Executor进程返回的结果,并将最终结果写入HDFS或其他存储系统中。
- Client模式:
- 在本地客户端机器上启动Driver进程,该进程负责解析应用程序代码、设置作业配置、构建RDD和DAG等。
- Driver进程向ResourceManager申请资源来启动Executor进程。
- ResourceManager根据可用资源的数量和分配策略向客户端节点分配节点和内存。
- Executor进程在分配的节点上启动并运行计算任务。
- Executor进程读取数据和中间结果,将结果写入HDFS或其他存储系统中,并向Driver进程报告任务的进度和结果。
- Driver进程收集和汇总Executor进程返回的结果,并将最终结果写入HDFS或其他存储系统中。
总的来说,两种模式的区别在于Driver进程的位置和资源的分配方式,但Spark的执行流程是相似的,即通过Application Master或Driver进程来协调Executor进程的计算任务,将数据存储在HDFS或其他存储系统中,并汇总计算结果。
生产环境下,一般采用Culster模式进行任务提交,否则多个任务运行在提交任务的节点,会造成内存占用过高的问题。
五、Spark启动任务脚本
#!/bin/bash
SPARK_ROOT="xxx"
sh $SPARK_ROOT/bin/run.sh --config-dir $SPARK_ROOT/conf --command spark-submit \
--class xxx --master yarn-cluster --name xxx \
--conf spark.shuffle.consolidateFiles=true \
--conf spark.shuffle.io.retryWait=30s \
--conf spark.reducer.maxSizeInFlight=96m \
--conf spark.shuffle.file.buffer=64k \
--conf spark.executor.memoryOverhead=2048 \
--jars xxx,xxx,xxx \
--executor-cores 8 \
--executor-memory 10g --num-executors 48 \
--driver-memory 4g /xxx/xxx.jar arg1 arg2 arg3六、YRAN的HA高可用实现
在Hadoop中,Zookeeper主要用于实现HA(High Availability),这部分逻辑主要集中在Hadoop Common的HA模块中,HDFS的NameNode与YARN的ResourceManager都是基于此HA模块来实现自己的HA功能,YARN又使用了Zookeeper来存储应用的运行状态。

在运行期间,会有多个ResourceManager并存,并且其中只有一个ResourceManager处于Active状态,另外一些(允许一个或者多个)则处于Standby状态,当Active节点无法正常工作时,其余处于Standby状态的节点则会通过竞争选举产生新的Active节点。
主备切换
ResourceManager使用基于Zookeeper实现的ActiveStandbyElector组件来确定ResourceManager的状态。具体步骤如下
1. 创建锁节点。在Zookeeper上会有一个类似于/yarn-leader-election/pseudo-yarn-rm-cluster的锁节点,所有的ResourceManager在启动时,都会去竞争写一个Lock子节点(/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock),子节点类型为临时节点,利用Zookeeper的特性,创建成功的那个ResourceManager切换为Active状态,其余的为Standby状态。
2. 注册Watcher监听。所有Standby状态的ResourceManager都会向/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock节点注册一个节点变更监听,利用临时节点的特性,能够快速感知到Active状态的ResourceManager的运行情况。
3. 主备切换。当Active的ResourceManager无法正常工作时,其创建的Lock节点也会被删除,此时,其余各个Standby的ResourceManager都会收到通知,然后重复步骤1。
隔离(Fencing)
在分布式环境中,经常会出现诸如单机假死(机器由于网络闪断或是其自身由于负载过高,常见的有GC占用时间过长或CPU负载过高,而无法正常地对外进行及时响应)情况。假设RM集群由RM1和RM2两台机器构成,某一时刻,RM1发生了假死,此时,Zookeeper认为RM1挂了,然后进行主备切换,RM2会成为Active状态,但是在随后,RM1恢复了正常,其依然认为自己还处于Active状态,这就是分布式脑裂现象,即存在多个处于Active状态的RM工作,可以使用隔离来解决此类问题。
YARN引入了Fencing机制,借助Zookeeper的数据节点的ACL权限控制机制来实现不同RM之间的隔离。在上述主备切换时,多个RM之间通过竞争创建锁节点来实现主备状态的确定,此时,只需要在创建节点时携带Zookeeper的ACL信息,目的是为了独占该节点,以防止其他RM对该节点进行更新。
还是上述案例,若RM1出现假死,Zookeeper会移除其创建的节点,此时RM2会创建相应的锁节点并切换至Active状态,RM1恢复之后,会试图去更新Zookeeper相关数据,但是此时其没有权限更新Zookeeper的相关节点数据,因为节点不是由其创建的,于是就自动切换至Standby状态,这样就避免了脑裂现象的出现。