Scala入门基础
前言
Scala是一门多范式的编程语言。是一种纯面向对象的语言,每个值都是对象。同时也是一种函数式语言,其函数也能当成值来使用。由于Scala整合了面向对象和函数式编程的特性,因此Scala相对于Java、C#、C++等其它语言更简洁。本文章将通过简单的案例教会大家如何简单的使用Scala编程,大家也可以模仿案例动手实践有助于自己入门学习。
目录
编程准备
1 数据类型
1.1常用数据类型
2 常量与变量
2.1 声明常量
2.2 声明变量
3 运算表达式
4 Array(数组)
4.1 定义数组
4.2 定义多维数组
4.3 数组的基本操作方法
4.4 数组的常用方法
4.5 长度可变数组
5 函数
5.1 函数定义和调用
5.2 函数种类
5.2.1 普通函数
5.2.2 匿名函数
5.2.3 高阶函数
5.2.4 参数变长函数
6 控制结构
6.1 if判断
6.2 循环
6.2.1 while循环
6.2.2 for循环
6.3 循环控制
7 Tuple(元组)
7.1初始化元组
7.2 访问元组
7.3 迭代元组
7.4 元组转字符串
8 List(列表)
8.1 初始化列表
8.2 常用方法
8.3 可变列表
9 Vector(向量)
10 Set(集合)
10.1 初始化Set
10.2 Set操作
11 Map(映射)
11.1 初始化
11.2 Map操作
12 函数组合器
12.1 map
12.2 foreach
12.3 filter
12.4 flatten
12.5 flatMap
12.6 groupBy
安装配置
Scala也是运行在JVM上的语言,所以必须确认环境中安装了Java。
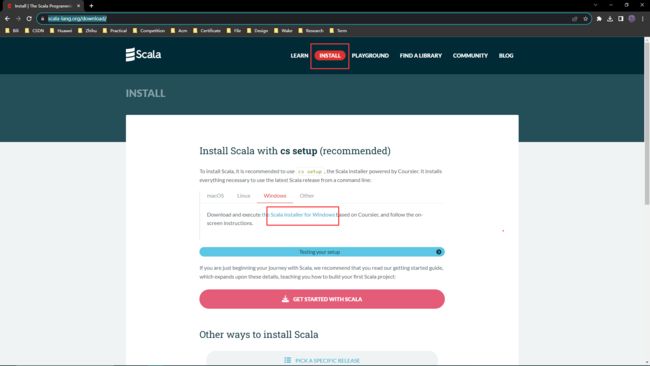
直接在官网下载(点击此处进入下载官网)。
Windows安装点击文中蓝色字体下载安装包。
Linux和macOS官网给出的是终端命令进行下载安装。
在本地高级系统设置中添加bin目录地址环境即可。
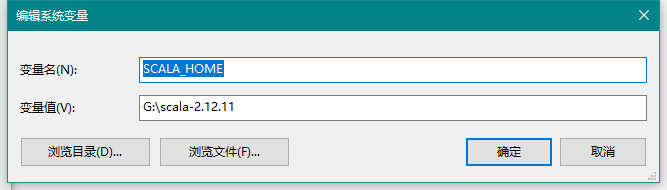
系统环境变量:
新建
SCALA_HOME
# 变量值替换成自己的安装路径
G:\scala-2.12.11

Path环境变量:
%SCALA_HOME%\bin

即可进入终端测试:
Scala解释器也称REPL(Read-Evaluate-Print-Loop,读取-计算-打印-循环)。Win+R输入“cmd”打开命令提示符,直接输入“scala”就能进入REPL。也可以直接在Win+R中运行对话框中输入“scala”。


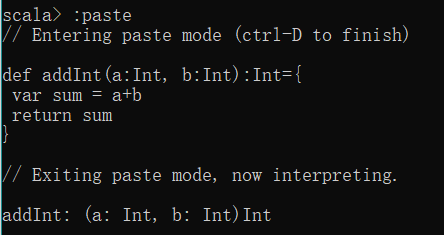
Scala的REPL提供paste模式,用于编写大量的代码,输入“:paste”代码编写完成后可以通过“Ctrl+D”组合键退出paste模式。
:paste
1 数据类型
1.1常用数据类型
| Int | 32位有符号补码整数。数值区间为-32 768~32 767 |
| Float | 32位IEEE754单精度浮点数 |
| Double | 64位IEEE754双精度浮点数 |
| String | 字符序列 |
| Boolean | true或false |
| Unit | 表示无值,和Java中的void等同,用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成() |
Float和Double都表示浮点数,浮点数后面有f或F后缀时,表示这是一个Float类型,否则为Double类型。

String表示字符串,其用法是双引号包含一系列字符,单引号会报错。

Scala会区分不同类型值,并基于使用值的方式来确定其类型,称之为类型推断。例如在加法中混用Int和Double类型时,Scala会确定其结果值为Double类型。

2 常量与变量
Scala中数据分为两种类型,常量(也称值)和变量。通过“val"定义常量,通过”var“定义变量。
2.1 声明常量
val name:type=initial_value
val关键字后面跟着常量、类型、等号和初始值。由于Scala具备类型推断功能,因此定义常量时可以不用显示地说明其数据类型。
若是需要显式地指明常量类型,可以在常量名后通过”:type“说明其类型。

常量名要求以字母或下划线开头后面跟着其他的字母、数字或下划线。注意变量名中不能使用美元符号($)。
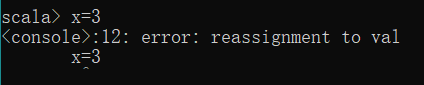
一旦初始化常量val,就不能再进行修改,若强行修改会提示”error: reassignment to val“的错误。
2.2 声明变量
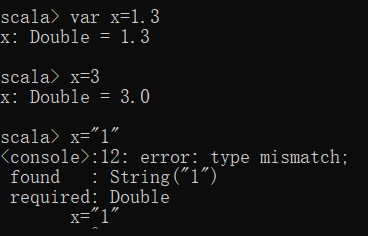
变量的命名规则与常量一样,变量也可以不显式地说明其数据类型,但值得注意的是,只能将同类型的值重新赋值给变量,否则会提示” error: type mismatch“的错误。
var name:type=initial_value
而与var则不同, 变量定义之后还能重新赋值,注意只能修改为同类型值。
3 运算表达式
| 算术运算符 | + | 两数相加 | 1+2或1.+(2) |
| - | 两数相减 | 1-2或1.-(2) | |
| * | 两数相乘 | 1*2或1.*(2) | |
| / | 两数相除 | 1/2或1./(2) | |
| % | 两数取余 | 1%2或1.%(2) | |
| 关系运算符 | > | 判断左值是否大于右值,正为真,负为假 | 1>2或1.>(2) |
| < | 判断左值是否小于右值,正为真,负为假 | 1<2或1.<(2) | |
| >= | 判断左值是否大于等于右值,正为真,负为假 | 1>=2或1.>=(2) | |
| <= | 判断左值是否小于等于右值,正为真,负为假 | 1<=2或1.<=(2) | |
| == | 判断左值是否等于右值,正为真,负为假 | 1==2或1.==(2) | |
| != | 判断左值是否不等于右值,正为真,负为假 | 1!=2或1.!=(2) | |
| 逻辑运算符 | && | 逻辑与,若两个条件成立为真,否则为假 | 1>2&&2>3或1>2.&&(2>3) |
| || | 逻辑或,若两个条件有一个成立为真,否则为假 | 1>2||2>3或1>2.||(2>3) | |
| ! | 逻辑非,对当前结果取反 | !(1>2) | |
| 位运算符 | & | 位与,参加运算的两个数据,按进制位进行&运算,两位同时为1结果才为1,否则为0 | 0&1或0.&(1) |
| | |
位或,参加运算的两个数据,按进制位进行|运算,两位只要有一个为1结果则为1 | 0|1或0.|(1) | |
| ^ | 位非,参加运算的两个数据,按进制位进行^运算,两位不同时为1,相同为0 | 0^1或0.^(1) | |
| 赋值运算符 | = | 将右侧值赋于左侧 | val/var a = 1 |
| += | 执行加法后再赋值左侧 | a += 2 | |
| -= | 执行减法后再赋值左侧 | a -= 1 | |
| *= | 执行乘法后再赋值左侧 | a *= 3 | |
| /= | 执行除法后再赋值左侧 | a /= 3 | |
| %= | 执行取余后再赋值左侧 | a %= 2 | |
| <<= | 左移位后赋值左侧 | a <<= 2 | |
| >>= | 右移位后赋值左侧 | a >>= 2 | |
| &= | 按位运算&后赋值左侧 | a &= 2 | |
| |= | 按位运算|后赋值左侧 | a |= 2 | |
| ^= | 按位运算^后赋值左侧 | a ^= 2 |
4 Array(数组)
4.1 定义数组
数组是一种存储了相同类型元素的固定大小的顺序集合。
var name:Arry[type] = new Array[type](num)或
var name:Array[type] = Array[type](ele1, ele2, ...)
例如,声明一个不可变数组array1,长度是3,并为每个元素设置值。
初始化方式1:
var array1:Array[String]=new Array[String](3)
array1(0)="baidu";array1(1)="google";array1(2)="edge"
初始化方式2:
var array1:Array[String]=Array[String]("baidu", "google", "edge")
4.2 定义多维数组
多维数组一个数组中的值可以是另一个数组,另一个数组的值也可以是一个数组。定义一个包含3个数组的二维数组。
初始化方式1:
var mdarr:Array[Array[Int]]=new Array[Array[Int]](n)
mdarr(0)=Array();mdarr(1)=Array();mdarr(2)=Array()
下面定义一个 3行的二维数组mdarr。
var mdarr:Array[Array[Int]]=new Array[Array[Int]](3)
初始化方式2:
var mdarr:Array[Array[Int]]=Array(Array(),Array(),Array())
直接定义一个3行3列的二维数组madrr1。
var mdarr1:Array[Array[Int]]=Array(Array(1,2,3),Array(2,3,4),Array(3,4,5))
4.3 数组的基本操作方法
| arr.length | 返回数组的长度 |
| arr.head | 查看数组第一个元素 |
| arr.tail | 查看数据中除了第一个元素外的其他元素 |
| arr.isEmpty | 判断数组是否为空,返回布尔型结果 |
| arr.contains(x) | 判断数组是否包含元素x |

4.4 数组的常用方法
下表中为Scala中处理数组的重要方法,使用前需要引入包 import Array._
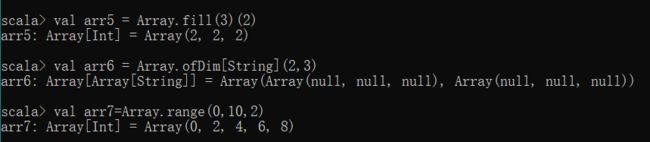
| def concat[T](xss:Array[T]*) | 合并数组 |
| def fill[T](n:Int)(elem:=>T) | 返回数组,长度为第一个参数指定,每个元素使用第二个参数进行填充 |
| def ofDim[T](ele1:Int, ele2:Int) | 创建二维数组,只有一个ele参数时为一维定长数组 |
| def range(start:Int, end:Int) | 创建指定区间内的数组,step为每个元素间的步长,默认为1 |
合并连接数组:连接两个数组既可以使用操作符“++”,也可以使用concat方法。但是使用concat方法需要先引入包“import Array._”。

4.5 长度可变数组
初始化ArrayBuffer数组:
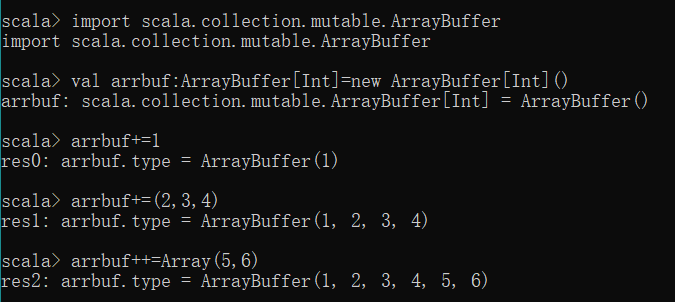
创建可变数组需要导入包 import scala.collection.mutable.ArrayBuffer
val arrbuf:ArrayBuffer[type]=new ArrayBuffer[type]()
import scala.collection.mutable.ArrayBuffer
val arrbuf:ArrayBuffer[Int]=new ArrayBuffer[Int]()使用+=操作符,可以添加一个或多个元素。
使用++=操作符,可以添加其它集合中的所有元素。
| insert(ele1, ele2) | 在指定位置ele1插入元素ele2 |
| remove(ele1, ele2) | 移除指定位置的元素,有两个元素时移除区间位置内元素 |
| toArray | 由可变数组转换为不可变数组 |
| toBuffer | 由不可变数组转换为可变数组 |

5 函数
5.1 函数定义和调用
定义函数
def functionName (参数列表) : [return type] = {}
例如,定义一个函数add,返回两个整型数据之和。
def add (x:Int, y:Int):Int = {x+y} 
此处两种函数作用效果一样,上面函数直接返回相加的结果,下面函数通过定义中间量sum计算两个整型的和并返回。
:paste
def add (x:Int, y:Int):Int = {
var sum = 0
sum = x+y
return sum
}
函数的定义由def关键字开始,add为函数名,紧接着是可选的参数列表需要指定参数类型,之后冒号“:”后接着函数的返回类型,一个等号“=”,最后“{}”部分为函数的方法体。
如果函数无返回值,则函数的返回类型为Unit。
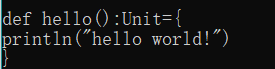
调用函数
函数一旦定义,可通过函数名调用。
functionName(参数列表)

函数可以赋值给变量,注意,赋值给变量需要在函数后面加空格和下划线。

5.2 函数种类
5.2.1 普通函数
函数一旦定义完成,可通过函数名调用函数。
:paste
def add (x:Int, y:Int):Int = {
var sum = 0
sum = x+y
return sum
}
5.2.2 匿名函数
匿名函数即在定义函数时不给出函数名,经常成为“Lambda表达式”。匿名函数使用箭头“=>”定义,箭头左边是参数列表,箭头右边是表达式,表达式将产生函数的结果。
(参数列表) => 表达式

调用匿名函数可以将函数赋值给一个常量或变量,通过常量名或变量名调用该函数 。
val addInt = (a:Int, b:Int)=>a+b
如果函数中的每个参数在函数中最多只出现一次,则可以用占位符“_“代替参数,与上个示例函数相同 。

5.2.3 高阶函数
高阶函数即操作其它函数的函数。高阶函数可以使用函数作为参数,也可以使用函数作为输出结果。
高阶函数经常将只需要执行一次的函数定义为匿名函数作为参数。
val f = (a:Int, b:Int)=>a+b
def addInt(f:Int, c:Int):Int={f+c}
addInt(f(2,3),4)
上函数将匿名函数单独定义调用,下函数在addInt函数内直接定义匿名函数f复用定义相加功能,实现三个数相加的功能。值得注意的是,下函数在函数中定义匿名函数f时只是进行了函数定义,并没有写明代码功能,再进行调用时,可以定义其它运算功能复用。
:paste
def addInt(a:Int, b:Int, c:Int, f:(Int, Int)=>Int):Int = {
return f(a,b)+c
}
val result = addInt(3,4,5,(x,y)=>{x+y}) 
5.2.4 参数变长函数
有时需要将函数定义为参数个数可变的形式,此时可使用变长参数定义函数。
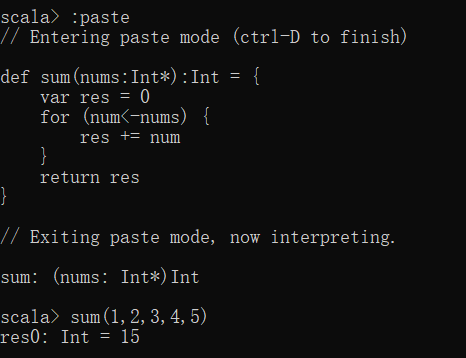
例如,定义一个函数sum传入int类型的数据列表sum,通过for循环遍历列表nums进行累加操作。
:paste
def sum(nums:Int*):Int = {
var res = 0
for (num<-nums) {
res += num
}
return res
}
6 控制结构
6.1 if判断
if (布尔表达式1) {
// 若布尔表达式1为true 则执行该语句块
}else if (布尔表达式2) {
// 若布尔表达式2为true 则执行该语句块
}else {
// 若以上条件都为false 执行该语句块
}
例如,通过if循环判断i的大小区间并对各区间结果进行输出。
var i=5
:paste
if (i<5) {
println("i小于5")
} else if (i>5) {
println("i大于5")
} else {
println("i等于5")
} 
6.2 循环
6.2.1 while循环
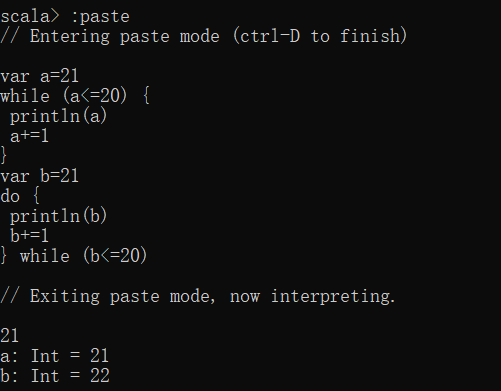
while先判断后执行,do while先执行后判断。
当不满足循环条件时,while循环一次都不会执行,do while循环至少执行一次。
while (表达式) {
循环体
}
do {
循环体
} while (表达式)
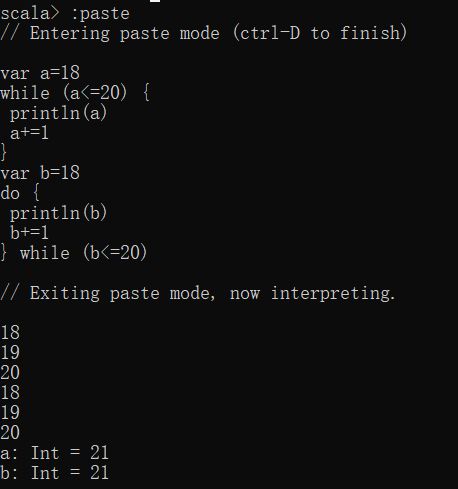
var a=21
while (a<=20) {
println(a)
a+=1
}
var b=21
do {
println(b)
b+=1
} while (b<=20)
6.2.2 for循环
for (变量<-表达式) {
语句块
}
其中”变量<-表达式“被称为”生成器“。
to遍历方式,前后闭合
var a=0
for (a<-1 to 5) {
println("Value of a:"+a)
}
until遍历方式,前闭合后开
var a=0
for (a<-1 until 5) {
println("Value of a:"+a)
}
遍历数组列表
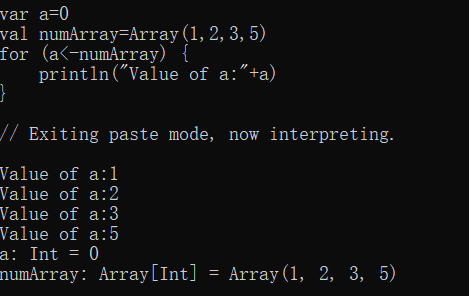
var a=0
val numArray=Array(1,2,3,5)
for (a<-numArray) {
println("Value of a:"+a)
}
for循环中使用if判断语句,循环守卫。等效for循环嵌套if判断。
var a=0
val numArray=Array(1,2,3,4,6,8,9)
for (a<-numArray if a!=3 if a<8) {
println("Value of a:"+a)
}
var a=0
val numArray=Array(1,2,3,4,6,8,9)
for (a<-numArray) {
if (a!=3 && a<8) {
println("Value of a:"+a)
}
} 
for推导式,迭代原数组列表构造新数组列表。
for { 子句 } yield { 变量或表达式 }
var a=0
val numArray=Array(1,2,3,4,6,8,9)
var restVal=for {a<-numArray if a!=3 if a<8} yield a
for (a<-restVal) {println("Value of a:"+a)}

6.3 循环控制
为了提前终止整个循环或跳到一下个循环,Scala没有break和continue关键字。
Scala提供了一个Breaks类(位于包scala.util.control)。
Breaks类有两个方法用于对循环结构进行控制,即breakable和break。
breakable {
...
if ( ... ) break
...
}
import scala.util.control.Breaks._for遍历在breakable方法体中
val array=Array(1,3,10,5,4)
breakable {
for (i<-array) {
if (i>5) break
println(i)
}
}
breakable方法在for循环方法内
val array=Array(1,3,10,5,4)
for (i<-array) {
breakable{
if (i>5) break
println(i)
}
}

7 Tuple(元组)
元组与数组列表一样不可变,但与数组列表不同的是元组可以包含不同类型的元素。
元组的索引从1开始(_1、_2),最大长度支持22。
7.1初始化元组
初始化方式1:
var tup=()

初始化方式2:
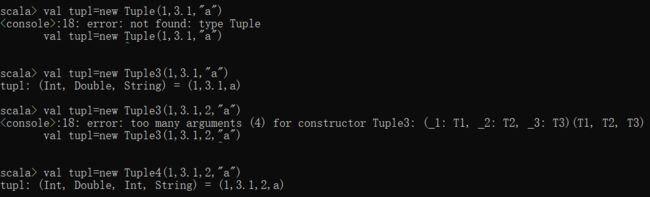
new Tuple后直接加数字表示数组列表的长度。
var tup=new TupleInt()
7.2 访问元组
tup._1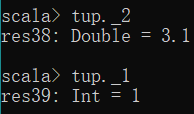
7.3 迭代元组
tup.productIterator.foreach(i=>{println("Value:"+i)})
7.4 元组转字符串
使用Tuple.toString()方法将元组的所有元素组合成一个字符串。

8 List(列表)
8.1 初始化列表
不同于Java的java.util.List,Scala的List一旦被定义就不能改变值,因此声明List时必须初始化。
初始化方式1:
val listName:List[type] = List(ele1,ele2,...)
val list:List[String]=List("baidu","google","edge")
val list1:List[Int]=List(1,2,3)
val list2:List[List[Int]]=List(List(1,2,3),List(4,5,6)) 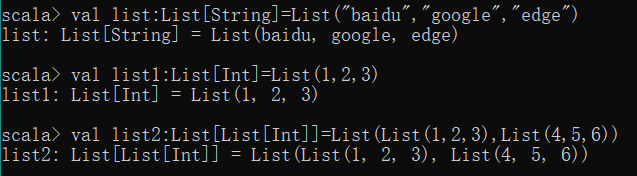
初始化方式2:
val listName:List[type] = ele1::ele2::...::Nil
其中构造列表的两个基本单位时Nil和::,Nil也可以表示为一个空列表,::称为中缀操作符,表示列表从前端拓展,遵循右结合。
val list:List[String]="baidu"::"google"::"edge"::Nil
val list1:List[Int]=1::2::3::Nil
val list2:List[List[Int]]=(1::2::3::Nil)::(4::5::6::Nil)
8.2 常用方法
| def head | 获取列表第一个元素 |
| def init | 返回所有元素,除了最后一个 |
| def last | 获取列表最后一个元素 |
| def tail | 返回所有元素,除了第一个 |
| def :::(prefix:List[A]) | 在列表开头添加指定列表的元素 |
| def take(n:Int) | 获取列表前n个元素 |
| def contains(elem:Array) | 判断列表是否包含指定元素 |
连接列表可以使用 ::: 运算符 或List.:::()方法 或List.concat()方法连接两个或多个列表。
::: 运算符 和List.:::()方法的结果是不同的。
:::运算符在列表后添加,List.:::() 方法在列表前添加。
val site1 = List("google","baidu","edge")
val site2 = List("taobao","facebook")
val site3 = site1:::site2
val site4 = site1.:::(site2)
val site5 = List.concat(site1,site2)

8.3 可变列表
初始化ListBuffer列表:
创建可变列表需要导入包 import scala.collection.mutable.ListBuffer
val list:ListBuffer[type]=new ListBuffer[type]()
import scala.collection.mutable.ListBuffer
val list:ListBuffer[Int]=new ListBuffer[Int]()使用+=操作符 或append 方法,可以添加一个或多个元素。
使用++=操作符可以添加其它集合中的所有元素。

toList 方法转换为List
toBuffer 方法转换为可变数组

list.-= 删除指定值
remove 方法按照索引删除
listBuffer.-=("baidu")
listBuffer.remove(0,2)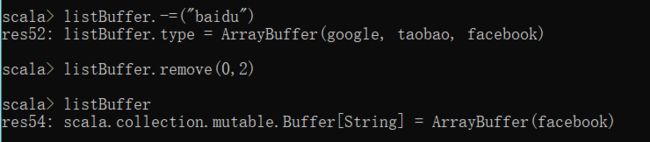
9 Vector(向量)
向量类似动态数组的功能
val vectorName:Vector[Type] = Vector(n1, n2, ,...)
访问向量
val vector1:Vector[Int]=Vector(1,2,3)
vector1(0)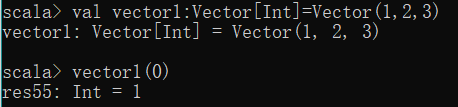
连接向量
可以使用 +: 或 :+ 连接向量和元素
:和+前后的位置根据vector的位置来定
val vector1:Vector[Int]=Vector(1,2,3)
val vector2:Vector[Int]=4+:5+:vector1
val vector3:Vector[Int]=vector1:+4
10 Set(集合)
Set是没有重复对象的集合,所有元素都是唯一的。
Scala集合分为可变集合和不可变集合。
默认使用不可变集合,可变集合需要导入包 import scala.collection.mutable.Set
10.1 初始化Set
val setName:Set[type] = Set(ele1, ele2, ...)
import scala.collection.mutable.Set
val set:Set[Int] = Set(1,2,3) 
10.2 Set操作
Set的方法与列表中同类方法的用法相同,合并列表使用“:::”或concat方法,而合并两个集合使用“++”方法。
| def head | 获取Set第一个元素 |
| def init | 返回所有元素,除了最后一个 |
| def last | 获取Set最后一个元素 |
| def tail | 返回所有元素,除了第一个 |
| def ++(elems:A) | 合并两个Set集合 |
| def take(n:Int) | 获取Set前n个元素 |
| def contains(elem:Any) | 判断Set是否包含指定元素 |
| Set.&或Set.intersect | 查看两个集合的交集 |

val set1:Set[Int] = Set(4,5,6)
val set2:Set[Int] = Set(4,5,8)
set1.&(set2)
set1.intersect(set2) 
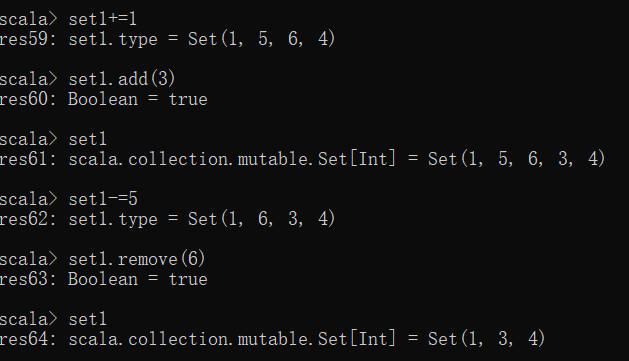
+= 或 add添加元素
-= 或 remove移除指定元素
11 Map(映射)
Map是一种可迭代的键值对结构,所有的值都可以通过建来获取。
键都是唯一的,但值可以不唯一。
同样,Scala映射分为可变映射和不可变映射。
默认使用不可变映射,可变映射需要导入包 import scala.collection.mutable.Map
11.1 初始化
val MapName:Map[keyType, valueType]=Map(key1->value1, key2->value2, ...)
val map:Map[String, Int]=Map("a"->1, "b"->2, "c"->3)
11.2 Map操作
只有可变集合才能添加元素,使用+=添加元素。

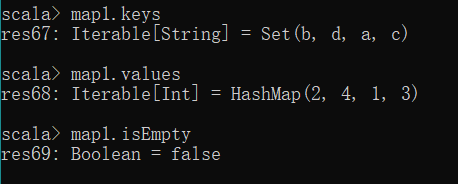
| keys | 返回Map所有的键(key) |
| values | 返回Map所有的值(value) |
| isEmpty | 判断Map是否为空,返回布尔值 |
Map映射与Set集合操作函数用法相同,可以使用++运算符 或Map.++()方法连接两个Map,Map合并时会移除重复的key。

12 函数组合器
Scala为各种数据结构提供了很多函数组合器,运用函数组合器的操作会在集合中的每个元素上分别应用一个函数,即组合器的参数都是一个函数。
12.1 map
map是指通过一个函数重复计算列表中的所有元素,并返回一个相同数量元素的新列表。
例如,声明一个整型列表,使用map对列表num中的每个元素进行平方计算。
val num:List[Int] = List(1,2,3,4,5)
num.map(x=>x*x)
12.2 foreach
foreach和map类似,但是foreach没有返回值,只是为了对参数进行作业。
例如,使用foreach对列表num中的每个元素进行平方并打印出来。
val num:List[Int] = List(1,2,3,4,5)
num.foreach(x=>print(x*x+"\t"))
12.3 filter
filter过滤函数移除传入函数的返回值为false的元素。
例如,过滤移除列表num中的奇数,得到只保留偶数的列表。
val num:List[Int] = List(1,2,3,4,5)
val result = num.filter(x=>x%2==0)
12.4 flatten
flatten可以把嵌套结构展开,或者说flatten可以将一个二维的列表展开成一个一维的列表。
例如,定义一个二位列表list,通过flatten即可将其变成一维数组。
val list:List[List[Int]] = List(List(1,2,3), List(4,5,6))
list.flatten
12.5 flatMap
flatMap结合了flatten和map的功能,接收一个可以处理嵌套列表的函数,然后将返回结果连接起来。
val list:List[List[Int]] = List(List(1,2,3), List(4,5,6))
list.flatMap(x=>x.map(_*2)) 
12.6 groupBy
groupBy是对集合中的元素进行分组操作,结果得到一个Map。
例如,对1~10之间的数字根据奇偶数进行分组,groupBy传入参数是一个计算偶数的函数,得到的结果是一个包含两个键值对的Map,键为false对应的值为奇数的列表,键为true对应的值为偶数的列表。
val num:List[Int] = List(1,2,3,4,5,6,7,8,9,10)
num.groupBy(x=>x%2==0)