【ElasticSearch系列-07】ES的开发场景和索引分片的设置及优化
ElasticSearch系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】ElasticSearch下载和安装 | https://zhenghuisheng.blog.csdn.net/article/details/129260827 |
| 【二】ElasticSearch概念和基本操作 | https://blog.csdn.net/zhenghuishengq/article/details/134121631 |
| 【三】ElasticSearch的高级查询Query DSL | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【四】ElasticSearch的聚合查询操作 | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【五】SpringBoot整合elasticSearch | https://blog.csdn.net/zhenghuishengq/article/details/134212200 |
| 【六】Es集群架构的搭建以及集群的核心概念 | https://blog.csdn.net/zhenghuishengq/article/details/134258577 |
| 【七】ES的开发场景和索引分片的设置及优化 | https://blog.csdn.net/zhenghuishengq/article/details/134302130 |
ES的开发场景和索引分片的设置及优化
- 一,ES的开发场景和索引分片的设置及优化
-
- 1,ES应用场景
-
- 1.1,信息搜索库
- 1.2,时间序列库
- 2,分片的设计和管理
-
- 2.1,单个分片
- 2.2,多个分片
-
- 2.2.1,算分不准原因
- 2.3,分片的设计
-
- 2.3.1,分片类型选择以及优缺点
- 2.3.2,主分片设计与案例
- 2.3.3,副本分片设计
- 3,ElasticSearch底层读写原理
-
- 3.1,数据的写入
-
- 3.1.1,数据写入的流程
- 3.2.2,数据存储文件形式
- 3.2,数据的读取
-
- 3.2.1,根据id查询
- 3.2.2,根据关键字查询
- 3.3,数据读写优化
一,ES的开发场景和索引分片的设置及优化
在上一篇中,讲解了Es集群的搭建,以及一些索引,分片,副本等的概念,接下来这篇主要讲解在实际开发中,ElasticSearch的一些应用场景
1,ES应用场景
在实际开发中,es主要有两种应用场景:一种是基于数据量大,但是数据增长量慢的应用场景,如订单查询,商品查询等;一种是基于数据量大,数据增长量快的应用场景,如每天都会有大量的日志信息,通过时间序列对日志进行存储和查询等。
1.1,信息搜索库
这就是第一种情况,针对于数据量大,但是增长量慢的应用场景。如在一个商城app中,其商品的信息、订单的信息等,在数据加入到es之后,可以选择通过商品的类型或者名称进行分片存储,在查询时只需要根据商品类型或者名称查询对应的分片结点即可
这种场景更加需要考虑的是搜索的相关度,如涉及算分,权重这些,与时间的范围无关。

如上图中搜索框中输入的家电,下面会展示所有的家电信息,品牌等,那么在es中做索引分片时,就可以根据品牌进行分片存储等。需要注意的是,单个分片最好不要数据量太大,如不要超过20g,如果数据量太多,可以通过增加副本分片的数量,从而提高吞吐量
如果是单个索引的数据量太大,可以通过reindex进行索引拆分,可以根据某种枚举字段进行拆分,如订单可以根据区域进行拆分,商品根据品牌进行拆分等。
1.2,时间序列库
根据时间序列进行统计,容日志的查询等,一般每条数据都会有一条时间戳,并且每条文档基本上都不会更新,主要是为了查询,因此对数据的写入要求会比较高。如每天有几万条数据插入到es数据库中
在创建索引时,可以直接根据时间进行创建索引,如每天或者每周或者每月的方式进行划分,如每天有上万条日志信息,那么就可以直接根据时间进行创建索引,每天晚上可以开启一个定时任务去创建索引,随后今天一天的数据全部存储在这个索引中,后续作统计时,只需要定位到这个索引片即可
PUT /logs_2023-11-07
也可以直接选择使用这个Date Math表达式,其语法如下
<static_name{date_math_expr{date_format|time_zone}}>
使用这个Date Math的官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.16/date-math-index-names.html
如官方文档给的实例,显示的结果就是创建今天的日期的索引,前缀就是my-index
# PUT /<my-index-{now/d}>
PUT /%3Cmy-index-%7Bnow%2Fd%7D%3E
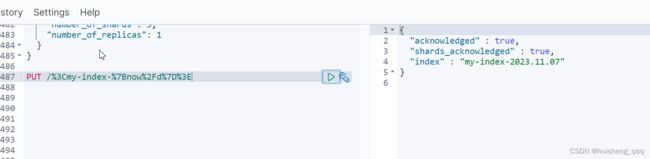
上面的百分号在官网中也有对应的值,只需要根据这些值进行修改即可

官网提供的转义表达式有这些,如now/d等等,从<、-、{、}、/ 等一一的按照上面的值进行替换即可
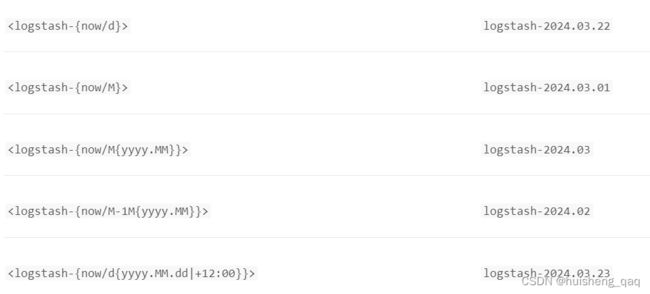
如果是需要查询最近的数据,也可以采用冷热分离的架构,将最近几天的数据加入到hot热点数据中;并且在存储日志这种信息是,丢失几条数据也是没事的,因此在设置副本的数量时,可以直接设置为0
如果前端是要固定的查询一个索引,那么可以通过别名的方式去新增索引,先将原索引删除,然后将创建的新索引的别名设置为原索引的名称
2,分片的设计和管理
2.1,单个分片
在es7开始,在创建一个索引时,默认是只有一个分片和一个副本的。如下例子,本人就是使用的7.7的版本,在创建一个索引之后,其默认的分片数和副本数就是1。因为直接使用单个分片,可以避免很多问题,如算分问题,聚合问题等
"number_of_shards" : "1",
"number_of_replicas" : "1",
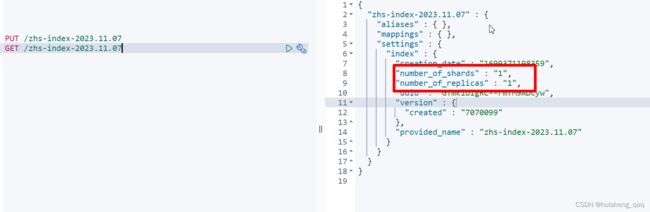
但是单个分片也存在一些缺点,如在集群中,单个分片不能很好的实现水平扩展,除非要手动reindex增加分片,将数据进行拆分
2.2,多个分片
多个分片和单个分片的优缺点刚好相反,多个分片是有利于实现节点的水平扩展的,在性能上会高于单分片的索引。但是多分片也会出现一些问题,如算分不准,聚合查询等问题
2.2.1,算分不准原因
当数据量大的时候,一般数据都是均分分布在各个节点的,因此不会出现这种算分不准的情况,一般是会出现在数据量小的情况,如每个分片的数据量都比较小,举个例子
先创建一个索引,并设置分片数为3
PUT /zhs_db
{
"settings":{
"number_of_shards" : "3"
}
}
随后往文档中插入数据,这里不使用_bulk批量插入,因为批量插入会在一个分片中。往里面插入三条数据,根据hash规则,那么三条数据就会分别落在三个分片中,一个分片中一条数据
POST /zhs_db/_doc/1?routing=zhenghuisheng
{
"content":"Cross Cluster elasticsearch Search"
}
POST /zhs_db/_doc/2?routing=zhenghuisheng2
{
"content":"elasticsearch Search"
}
POST /zhs_db/_doc/3?routing=zhenghuisheng3
{
"content":"elasticsearch"
}
随后进行match查询这个content,并且value为elasticSearch
GET /zhs_db/_search
{
"query": {
"match": {
"content": "elasticsearch"
}
}
}
在执行上面的查询之后,其结果如下,本来是所占文档比率越高,算分的值越大,就是id为3的占百分百,因此按理来说是算分最高的,然而实际在查询出来的是id为1的算分最高,实际id为1的算分是最低的,因此综合来看,这个算分就是不准的
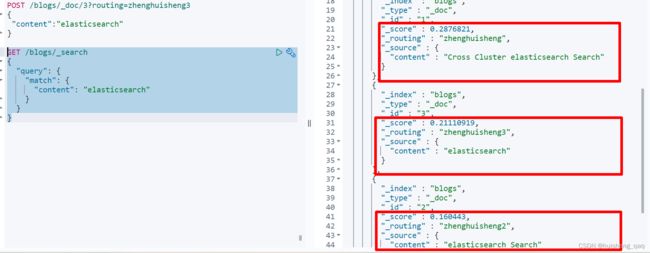
主要原因是每个分片都有自己打分的标准,每个分片都是基于自己分片上的数据的相关度来进行计算的,其最主要原因是数据量少,因此如果是数据量少的情况下,还是建议设置这个分片数为1
当然在数据量小的时候,也有对应的解决方案,就是使用DFS Query Then Fetch ,其原理就是将所有的数据全部搜索出来,然后统一放在一个协调结点中,通过协调节点再进行一次完整的算分。但是在实际开发中,这种方式并不推荐使用,因为其性能相对是较低的
GET /zhs_db/_search?search_type=dfs_query_then_fetch
{
"query": {
"match": {
"content": "elasticsearch"
}
}
}
2.3,分片的设计
2.3.1,分片类型选择以及优缺点
上面说了单个分片和多个分片使用的优缺点,接下来谈谈在实际开发中,是如何设计这个分片的。
往往来说,分片的数量是需要大于结点数的,那么这样基本都是优选考虑多分片数据,这样有利于在新增数据节点时,可以进行自动的分配,并且如果一个索引的数据分布在不同的节点,这样就可以并行的执行,并且在数据写入时,也可以分散到多个机器。
但是分片过多,也会带来一些副作用,因为每一个分片就是一个Lucene索引,其实就是一个进程,如果过多的分片,就会占用机器的资源,导致带来额外的开销,并且所有的分片都是需要Master主节点进行维护和管理,这样就会导致master主节点承受更大的负担,因此分片需要控制在10W之内
2.3.2,主分片设计与案例
在实际开发中,日志类的数据只需要设置主分片数,但是不需要设置副本数,而其他的数据增长量慢的需要设置主分片数和副本数,接下来谈谈主分片数需要如何设计
- 当数据为搜索类时,如商品信息类,那么单个分片不要超过20个G的数据
- 当数据为日志类时,如订单类、流水类,那么单个分片不要超过50G的数据
搜索类设计:如根据品牌进行设计,一个品牌对应一个索引,一个索引对应一个主分片和一个副本分片
日志类设计:每天创建一个日志索引,每个日志索引创建10个分片,一个月需要创建300个分片,不需要副本
2.3.3,副本分片设计
一般在实际开发中,副本都是设置为0或者1,日志类数据不需要副本,可以直接设置为0,搜索类数据一般设置为1,副本就是类似于主分片的一个从分片,有主分片中的全部数据。
副本分片数据就是数据在住分片中插入完成之后,再在副本分片中再保存一份,如果副本分片数过多,那么在存入副本数据时就会花费更多的时间,在写性能上会有一定的影响
但是副本分片也有好处,首先就是可以提高查询的效率,并且可以防止数据丢失,保证数据的安全性,因此副本分片是需要的,但是也不能设计太大,日志类除外。并且可以通过不断的调整副本分片的个数,来是整个系统的查询率和响应率达到最佳状态
为了避免分配的不均衡,分片数的调整如下:
- index.routing.allocation.total_shards_per_node:表示在索引中每个Node的最大分片数量,-1表示无穷大
- cluster.routing.allocation.total_shards_per_node:表示在集群中每个Node结点最大分片的数量,-1表示无穷多个
3,ElasticSearch底层读写原理
上面谈到了分片和副本的一些概念和设计,接下来通过es写入数据的流程来分析,分片和副本的功能到底是什么。
3.1,数据的写入
3.1.1,数据写入的流程
在前面谈到了通过不同的数据节点实现不同的功能,写入请求是需要先通过协调节点,在转发到data数据节点存储,随后先将数据存储到主分片上面,然后再将数据同步到副本分片上面,其具体的流程实现如下
- 1,在用户发起写请求之后,首先该请求会先到协调节点
- 2,协调结点接收到这个请求之后,会通过route路由的方式将请求转发给对应的节点
- 3,随后会将数据同步到该节点的主分片上,如果有副本分片,则将数据给副本分片也同步一份
- 4,当master主分片和副本分片都同步完数据之后,协调节点再给客户端一个存入成功的响应
3.2.2,数据存储文件形式
segment file :在mysql中,mysql是以页为单位存储在磁盘中,在ElasticSearch中,是通过这个Segment file的方式存储,每一个文件的本质就是一个倒排索引,一个大的分片中,都是由各个小的Segment file文件合并成的。文件过多时会自动合并各个小文件,也可以手动强制合并,在合并时会将被标记删除的文档给物理删除
commit point :当将某个文档删除时,ElasticSearch不会立马删除,而是先通过这个commit point文件做一个标志,每个文件中都有.del的一个标志,如果设置了被删除的状态,那么在查询数据时,默认会将这个文档给过滤掉。这个也有点类似于mysql的行格式,里面有字段用于标记是否被删除
translog文件 :类似于mysql的redolog文件,防止因为宕机造成数据丢失,用于做数据恢复
os cache :缓存,每隔一s会进行一个刷盘操作,也可以通过refresh强制刷盘
3.2,数据的读取
数据的查询主要有两种方式,一种是直接根据id进行查询,一种是直接根据关键字进行匹配
3.2.1,根据id查询
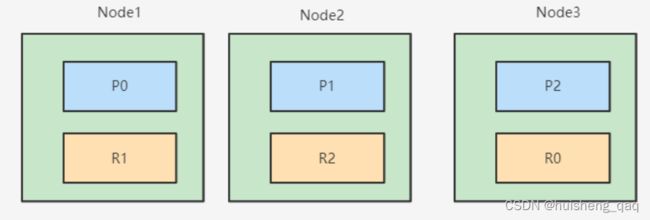
根据id查询的方式是比较简单的,首先也是先由客户端发起请求,随后将请求发送到协调者结点,协调者节点通过这个id进行hash取模定位到Data数据节点,数据节点上有主分片和副本分片,这两种分片都可以进行数据的查询,会通过随机的方式选择副本还在主分片,如下面的P0和R0,会在这两个分片中,选择一个分片作为数据查询的依据,随后将响应结果返回给协调者分片分片,最后再通过协调者分片将数据返回给用户
当然如果副本分片和主分片之间,也可以做一个负载均衡,来提高整个系统的高性能
3.2.2,根据关键字查询
其流程大致和上面的一样,先将请求给协调者节点,随后定位到Data数据节点,但是在查询数据再到返回数据的过程中,需要经历过两个阶段的操作。
因为es底层使用的是倒排索引,因此第一步是先将需要查询带有关键字的数据全部查询出来,随后携带那一行数据的id,再通过id查询,这就是相当于要查询两次,用mysql来解释,就是通过一个加了索引的字段进行数据查询,随后将携带的id进行回表操作
- query phase:第一步就是这个,先将全部的数据返回给协调者节点,再协调者节点中进行过滤、排序等操作
- fetch phase:第二步就是根据第一步所确定的结果,通过数据的id再进行一次查询工作将数据返回
3.3,数据读写优化
上面了解了读写的底层原理,在知道原理之后,那么就可以根据原理进行优化操作。
读取数据优化
如在读取数据时,减少这种通配符查询、前缀查询等需要全文检索的查询;如不需要算分的字段可以使用精确查询;使用Filter Context,利用内部的缓存机制,减少不必要的算分;结合profile、explain分析查询慢的问题等
写入数据优化
在写入数据时,可以使用批量插入数据来增加系统的吞吐量,或者使用多线程的方式插入数据;
分片优化
除了在查询优化,也可以在分片上做优化,数据量不大的情况可以使用单分片,数据量大使用多分片时,需要防止分片过多带来的开销。对于这种时间序列的查询,可以强制的force merge,将不需要的文档删除,从而减少这种segment的数量。
除了上面的几中优化之外,还可以对服务端硬件设备等进行优化,还可以调节这个refresh的频率进行优化、调整translog写入磁盘的频率进行调整等。如下面的这个模板,设置refresh刷新时间,translog刷盘等
DELETE myindex
PUT myindex
{
"settings": {
"index": {
"refresh_interval": "30s", #30s一次refresh
"number_of_shards": "2"
},
"routing": {
"allocation": {
"total_shards_per_node": "3" #控制分片,避免数据热点
}
},
"translog": {
"sync_interval": "30s",
"durability": "async" #降低translog落盘频率
},
"number_of_replicas": 0
},
"mappings": {
"dynamic": false, #避免不必要的字段索引,必要时可以通过update by query
索引必要的字段
"properties": {}
}
}