大数据毕业设计选题推荐-消防监控平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、部分代码设计
- 五、论文参考
- 六、系统视频
- 结语
一、前言
随着城市化进程的加速和人们对消防安全意识的提高,消防监控系统在保障人们生命财产安全中发挥着越来越重要的作用。然而,传统的消防监控方式往往存在一些问题,如信息传递不及时、不准确等,这些问题可能会导致火灾的误报或漏报,给人们的生命财产安全带来威胁。因此,基于大数据的消防监控平台的研究具有十分重要的现实意义和必要性。
目前,市场上存在的消防监控系统大多基于传统的硬件设备,这些设备存在着一些固有的问题。首先,设备的安装和维护成本较高,给用户带来了较大的经济负担。其次,设备的报警信息往往不能及时传递给用户,错过了火灾扑救时机。此外,设备的误报和漏报问题也比较严重,给用户的正常使用带来了很大的不便。因此,基于大数据的消防监控平台的研究对于解决这些问题具有十分重要的意义。
本课题旨在研究基于大数据的消防监控平台,通过收集和分析各种消防报警数据,如消防主机报警数据、无线烟感报警数据、燃气报警数据、水电报警数据等,实现火灾的实时监测和预警。同时,通过大数据分析和机器学习等技术,对报警数据进行挖掘和分析,提高火灾预警的准确性和及时性。此外,本课题还将研究如何将该平台与现有的消防设施和应急救援体系进行整合,实现资源的优化配置和快速响应。
本课题的研究成果将具有重要的理论和实践意义。从理论上讲,基于大数据的消防监控平台的研究将有助于推动大数据技术在消防安全领域的应用和发展,增进消防安全管理的现代化和智能化。从实践上讲,本课题的研究成果将能够提高火灾预警的准确性和及时性,减少火灾造成的损失和危害,保障人民生命财产安全。此外,本课题的研究还将为其他领域的大数据应用提供有益的参考和借鉴。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts、机器学习
- 软件工具:Pycharm、DataGrip、Anaconda、VM虚拟机
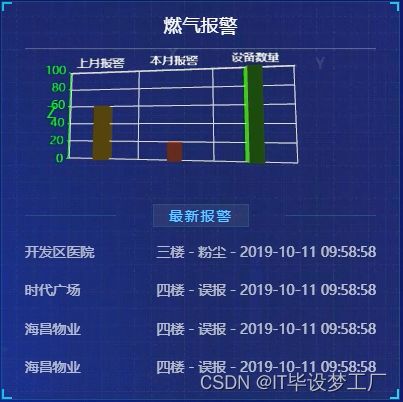
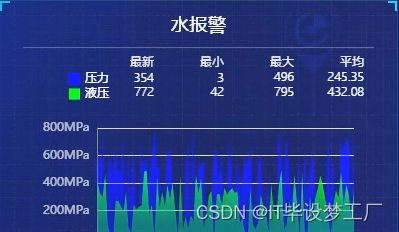
三、系统界面展示
- 基于大数据的消防监控平台界面展示:



四、部分代码设计
- 项目实战-代码参考:
class Scheduler(object):
def __init__(self, mongodb_server, mongodb_port, mongodb_db, persist, queue_key, queue_order):
self.mongodb_server = mongodb_server
self.mongodb_port = mongodb_port
self.mongodb_db = mongodb_db
self.queue_key = queue_key
self.persist = persist
self.queue_order = queue_order
def __len__(self):
return self.client.size()
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
mongodb_server = settings.get('MONGODB_QUEUE_SERVER', 'localhost')
mongodb_port = settings.get('MONGODB_QUEUE_PORT', 27017)
mongodb_db = settings.get('MONGODB_QUEUE_DB', 'scrapy')
persist = settings.get('MONGODB_QUEUE_PERSIST', True)
queue_key = settings.get('MONGODB_QUEUE_NAME', None)
queue_type = settings.get('MONGODB_QUEUE_TYPE', 'FIFO')
if queue_type not in ('FIFO', 'LIFO'):
raise Error('MONGODB_QUEUE_TYPE must be FIFO (default) or LIFO')
if queue_type == 'LIFO':
queue_order = -1
else:
queue_order = 1
return cls(mongodb_server, mongodb_port, mongodb_db, persist, queue_key, queue_order)
def open(self, spider):
self.spider = spider
if self.queue_key is None:
self.queue_key = "%s_queue"%spider.name
connection = pymongo.Connection(self.mongodb_server, self.mongodb_port)
self.db = connection[self.mongodb_db]
self.collection = self.db[self.queue_key]
# notice if there are requests already in the queue
size = self.collection.count()
if size > 0:
spider.log("Resuming crawl (%d requests scheduled)" % size)
def close(self, reason):
if not self.persist:
self.collection.drop()
def enqueue_request(self, request):
data = request_to_dict(request, self.spider)
self.collection.insert({
'data': data,
'created': datetime.datetime.utcnow()
})
def next_request(self):
entry = self.collection.find_and_modify(sort={"$natural":self.queue_order}, remove=True)
if entry:
request = request_from_dict(entry['data'], self.spider)
return request
return None
def has_pending_requests(self):
return self.collection.count() > 0
class DoubanPipeline(object):
def __init__(self):
self.server = settings['MONGODB_SERVER']
self.port = settings['MONGODB_PORT']
self.db = settings['MONGODB_DB']
self.col = settings['MONGODB_COLLECTION']
connection = pymongo.Connection(self.server, self.port)
db = connection[self.db]
self.collection = db[self.col]
def process_item(self, item, spider):
self.collection.insert(dict(item))
log.msg('Item written to MongoDB database %s/%s' % (self.db, self.col),level=log.DEBUG, spider=spider)
return item
五、论文参考
- 计算机毕业设计选题推荐-基于大数据的消防监控平台系统-论文参考:

六、系统视频
基于大数据的消防监控平台系统-项目视频:
大数据毕业设计选题推荐-消防监控平台-Hadoop
结语
大数据毕业设计选题推荐-消防监控平台-Hadoop-Spark-Hive
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:私信我
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目