两款html解析库html2struct及majestic12介绍
原文:http://www.codeproject.com/Articles/752625/html-struct-Class-Library
Watcher项目中的majestic12:https://websecuritytool.codeplex.com/SourceControl/latest#Watcher/Majestic12/DynaString.cs
html2struct is intended as an aid when data-mining from external HTML sources.
下面是一些关于Watcher的简介:
Watcher is a runtime passive-analysis tool for HTTP-based Web applications.
Watcher is built as a plugin for the Fiddler HTTP debugging proxy available at www.fiddlertool.com.我想对于fiddler我们应该很是熟悉了,web开发人员必备利器
- Download html2struct.zip - 4.8 KB
Introduction
html2struct is intended as an aid when data-mining from external HTML sources.
It's makes it easy to extract data from HTML files based on tag-structure with attributes without being reliant on other content that may change and cause the extraction to fail.
It parses HTML code into a simple tree-like structure of objects and provides a little tool-set to extract data from it. It is a light-weight parser that does not rely on resource hungry external stuff like browsers or DOM objects. It just creates a simple tree made of htmlTag objects.
It does NOT generate HTML, run scripts or fetch any external references.
It makes no attempts to enforce HTML document standards and does not care about conforming to them like having to have or
tags. This makes it easy to parse any segments of HTML code into a structure which as far as I know differs this solution from other HTML/XML parsers I've seen so far.I theory it should parse other Markup Languages as well, like XHTML, XML, SGML and other variants. Currently this is mostly untested territory but I've tried it on a few RSS sources where it parses XML just fine and in time I hope to make this parser capable of handling all Markup Languages similar to HTML.
Background
I have been developing a search engine that specializes in mini-ads/classifieds, collects them from different sources and allows people to search them. I like to call it a kind of localized mini-Google and today I index up to 2.000 advertisements from 20 different sources each day. This project requires a lot of data-mining from different HTML pages represented in distinct ways to extract a uniform data material which people can then search.
I'm a big fan of regular expressions and had been using them to isolate the data from those HTML sources until now, but after struggling with it for months while fine-tuning ridiculously complex expressions I came to the conclusion that it was too hard to define a "correct" expression for ever changing data sources.
I have repeatedly found my search engine to mine data incorrectly after someone makes a minor changes to their HTML code and these changes can be notoriously hard to debug. These changes would include adding or removing HTML Tags, adding/removing/swapping the order of attributes in an element, even adding a single space somewhere could easily cause a problem. As much as I tried to anticipate those changes I found it impossible and the expressions seized to match repeatedly.
This problem called for a different approach. I wanted to be able to parse HTML code regardless of its casing, order of elements/attributes, white-spaces or compliance to specific HTML standards.
After a bit of searching I decided to make my own parser since all the existing solutions I found seemed to include a full-blown browser or a DOM object generator to do the parsing and tended to reject the HTML code as a whole if it did not comply to some particular standards or had errors in it.
Finally I decided to share this in the open source community. This is the first time I do this in official manner which I have been wanting to do for a long time. I hope you'll find this class useful and certainly hope I'm not reinventing the wheel 8)
Definition
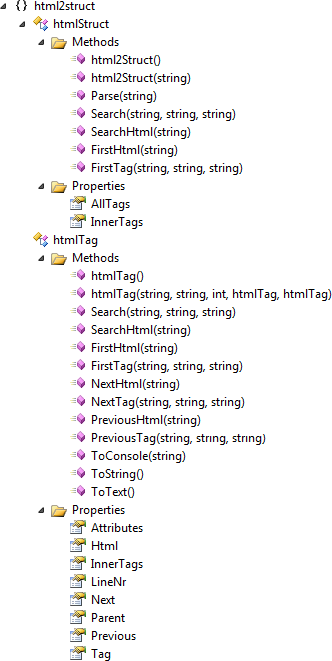
This library consists of 2 classes, the main class called htmlStruct and htmlTag which represents the tag structure. As the Class View demonstrates the structure is quite simple.
A word on attributes: The htmlStruct class has only 2 attributes
AllTags- holds all parsed elements in a HTML documentInnerTags- represents the tree-structure and tends to hold top-level elements such as and. It is the list intended for navigating down the HTML tree.
htmlTag is the class intended to be extracted from and has a few attributes for navigation and data extraction.
Tagholds the name of the current tag of course.Attributesprovides a Dictionary type access to attributes, such as 'src' and 'href', defined with the current tag.Htmlholds the HTML source used to create the tag. In case ofit holds the text. LineNrhas the line position in the HTML source where the tag was parsed for debugging purposes.InnerTagsholds the tags that were found within the opening/closing of the current tag, which then can have their inner tags, etc.Next,PreviousandParentare intended for navigation from a current tag that has been isolated with a search function.
A word on functions: As a rule of thumb, functions in the htmlStruct class operate on AllTags and search the whole document, functions in htmlTag operate recursively on InnerTags and do not search outside the scope of the current tag.
Parse()- Takes a HTML document as string, populates the attributes and generates the tree structure.Search()- Returns a list of tags that match all given search expressions based on tag name, attribute or value.SearchHtml()- Returns list of tags that match a regular expression from theirHtmlattribute.FirstTag()- Returns the first tag that matches all search criterias based on tag name, attribute or value.FirstHtml()- Returns the first tag that matches a regular expression from itsHtmlattribute.NextTag()- Returns the next subsequent tag that matches all given search expressions regardless of whether it is an inner tag or not.NextHtml()- Returns the next subsequent tag that matches a regular expression from itsHtmlattribute regardless of whether it is an inner tag or not.PreviousTag()- Returns the previous antecedent tag that matches all given search expressions regardless of whether it is an inner tag or not.PreviousHtml()- Returns the previous antecedent tag that matches HTML expression regardless of whether it is an inner tag or not.ToText()- Extracts text from current tag and its inner tags. If it runs into
ortags they get treated as newlines.
A word on search criterias: All Search(), FirstTag() and PreviousTag() functions accept the same search parameters, name of tag, attribute and value. Also they take a case-insensitive regular expression as search string. They will then do a search returning tags where all given expressions are true. If name of tag is given it will return tags with names that match. If attribute is given it return tags with attribute names that match. If value is given it will return tags with any attributes having values that match. If both attribute and value is given it will return tags with attribute names that match having a value that match (hmm, getting kinky...).
A word on