pandas笔记:读写excel
1 读excel
read_excel函数能够读取的格式包含:xls, xlsx, xlsm, xlsb, odf, ods 和 odt 文件扩展名。
支持读取单一sheet或几个sheet。
1.0 使用的数据


1.1 主要使用方法
pandas.read_excel(
io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=None,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
decimal='.',
comment=None,
skipfooter=0,
convert_float=None,
mangle_dupe_cols=True,
storage_options=None
)1.2 主要参数
1.2.1 io
文件路径
import pandas as pd
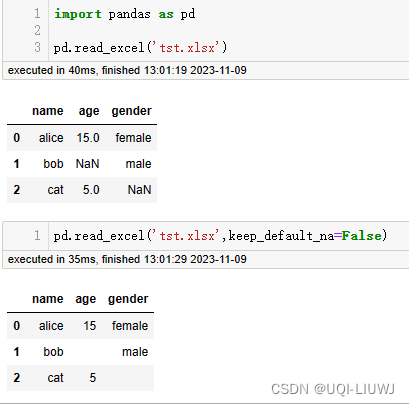
pd.read_excel('tst.xlsx')

1.2.2 sheet_name
- sheet表名,支持 str, int, list, or None
- 默认是0,索引号从0开始,表示第一个sheet
| sheet_name类型 | 输出结果 |
| 数字 | 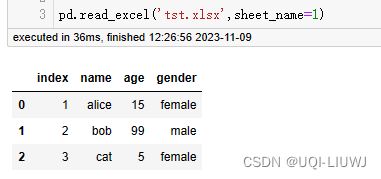 |
| 字符串 | 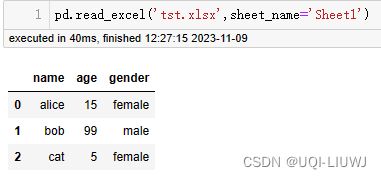 |
| 列表 |
|

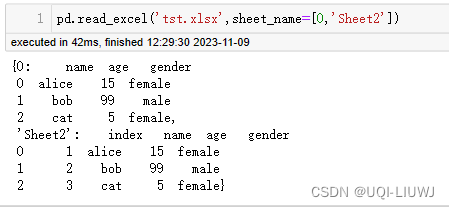
1.2.3 header
- 表示用第几行作为表头,支持 int, list of int;
- 默认是0,第一行的数据当做表头。
- header=None表示不使用数据源中的表头


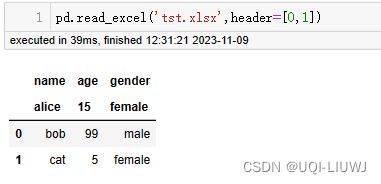
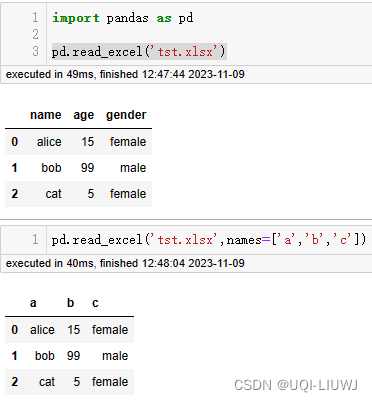
1.2.4 names
自定义表头的名称,此时需要传递数组参数
1.2.5 index_col
- 指定哪些列属性为行索引列,支持 int, list of int, 默认是None
- 也就是索引为0,1,2,3等自然数的列用作DataFrame的行标签。
- 如果传入的是列表形式,则行索引会是多层索引

1.2.6 usecols
待解析的列,支持 int, str, list-like, or callable ,默认是 None,表示解析全部的列。

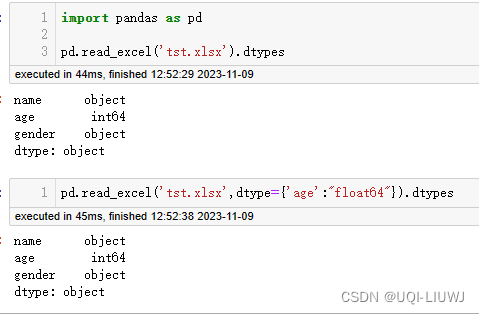
1.2.7 dtype
指定列属性的字段类型。
eg:{‘a’: np.float64, ‘b’: np.int32};默认为None,也就是不改变数据类型
1.2.8 converters
对指定列进行指定函数的处理,传入参数为列名与函数组成的字典

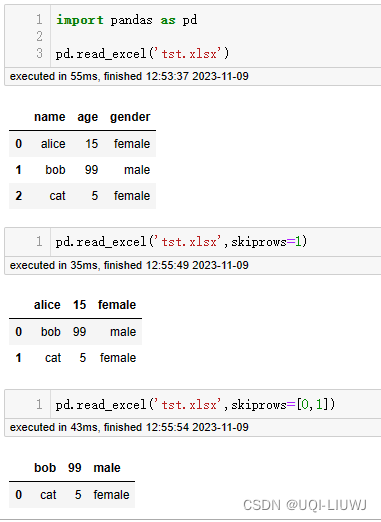
1.2.9 skiprows
跳过指定的行

1.2.10 nrows
指定读取的行数

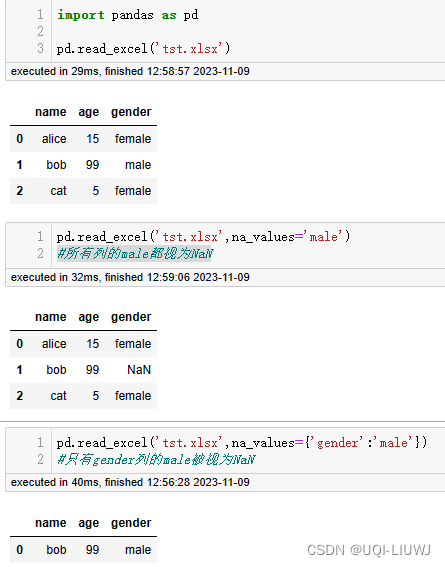
1.2.11 na_values
指定列的某些特定值为NaN
1.2.12 keep_default_na
是否导入空值,默认是导入,识别为NaN
2 写excel
和写csv很类似
import pandas as pd
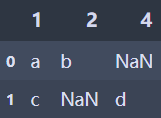
data=[{1:'a',2:'b'},
{1:'c',4:'d'}]
f1=pd.DataFrame(data)
f1.to_excel('t.xlsx',sheet_name='1')
2.1 index=False——不把索引列也存入
import pandas as pd
data=[{1:'a',2:'b'},
{1:'c',4:'d'}]
f1=pd.DataFrame(data)
f1.to_excel('t.xlsx',sheet_name='1',index=None)