IEEE--AdaPool: Exponential Adaptive Pooling forInformation-Retaining Downsampling 论文翻译
 论文:IEEE Xplore Full-Text PDF:
论文:IEEE Xplore Full-Text PDF:
目录
摘要
1介绍
2相关工作
A. 手工特征池化
B. CNN中的池化
3方法学
A. 平滑近似平均池化
B. 平滑近似最大池化
C. AdaPool:自适应指数池化
D. 使用adaUnPool进行上采样
4 INTER4K视频数据集
5 主要结果
A. 实验设置
1 数据集:
2 分类训练方案:
3 目标检测细节:
B. 降采样相似性
C. 延迟和内存使用
D. 在ImageNet1K上的图像分类性能
E. 与替代池化方法的比较
F. 在MS COCO上的目标检测性能
G. 视频分类性能
H. 图像超分辨率和帧插值结果
6. 消融研究
A. β权重掩模的影响
B. InceptionV3的逐层消融
C. 池化方法与融合策略的比较
D. 与基于注意力的下采样方法的比较
E. 定性可视化
7. 结论
附录 A
A. 逆距离加权池化
B. 基于系数的方法
C. 与替代软平均方法的比较
D. β参数化替代方案的消融
E. 计算描述
致谢
摘要
池化层是卷积神经网络(CNNs)中至关重要的构建块,用于降低计算负担并增加前向卷积操作的感受野。其目标是生成下采样的图像,尽可能地保持与输入图像的相似性,在理想情况下,同时具备较高的计算和内存效率。满足这两个要求一直是一个挑战。为此,我们提出了一种自适应和指数加权的池化方法:adaPool。我们的方法学习了基于Dice-Sørensen系数的指数和指数最大值的两组池化核的区域特定融合。adaPool提高了在多个任务中的性能,包括图像和视频分类以及目标检测。adaPool的一个重要特性是其双向性。与常见的池化方法不同,学习到的权重还可用于上采样激活图。我们称这个方法为adaUnPool。我们还在图像和视频超分辨率以及帧插值任务上评估了adaUnPool。为了进行性能基准测试,我们引入了Inter4K,一个高质量、高帧率的新视频数据集。实验结果表明,adaPool在各种任务和骨干网络上都取得了更好的结果,同时引入了轻微的额外计算和内存开销。
关键词— 池化,降采样,上采样
1 介绍
池化方法将空间输入降采样到较低分辨率。它们的目标是减小后续网络操作的计算开销并增大它们的感受野。池化操作在图像和视频处理方法中至关重要,包括基于卷积神经网络(CNNs)的方法。池化的一个重要方面是它在模型内部引入了信息损失。因此,保留输入的结构方面的细节,如对比度和纹理,可能变得具有挑战性。由于池化是几乎所有流行的CNN架构的关键组件,因此必须确保这种信息损失不会影响性能。
已经提出了一系列不同属性的池化方法(参见第II节)。大多数架构使用最大池化或平均池化,这两种方法都快速且内存高效,但在保留信息方面仍有改进的空间。其他方法使用可训练的子网络。这些方法在平均池化或最大池化之上显示出了一些改进,但它们通常效率较低,而且通常不适用于所有情况,因为它们的参数需要事先确定。
在这项工作中,我们研究了如何利用基于指数加权的低计算方法来解决池化方法的缺点。我们引入了一种方法,根据激活的softmax加权和或基于Dice-Sørensen系数获得的内核区域内每个激活与平均激活之间的相似性的指数来加权内核区域。然后,我们提出了adaPool作为这两种方法的学习融合,如图1所示。AdaPool不像平均池化那样平均高频模式,也不像最大池化那样专注于这些模式。相反,adaPool在保留有信息的细节和本地图像结构之间提供了平衡。
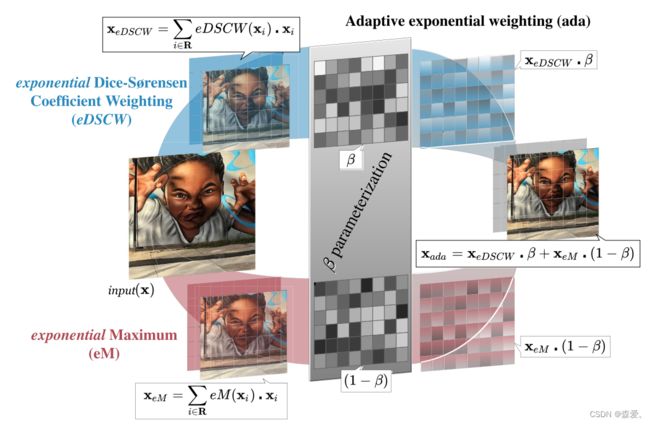
图1. AdaPool降采样。输出是两个过程的组合。第一个过程使用基于区域均值(x)的指数Dice-Sørensen系数权重(eDSCW)降采样。第二个过程使用指数最大值(eM)降采样。两个输出(xeM,xeDSCW)分别与区域权重掩模β和(1-β)相加,以产生自适应加权输出(xada)。
许多任务,包括实例分割、图像生成和超分辨率,需要对输入或信号进行上采样,这与池化的目标相反。除了LiftPool之外,池化操作不能被逆转,因为这会导致稀疏的上采样结果(例如,使用最大池化)。常见的上采样方法,如插值、转置卷积和反卷积,是对高分辨率特征的近似而不是重建。不包括先前知识是一个障碍,因为将信息编码到较低分辨率会损失局部信息。相反,我们认为引入先前的局部知识有助于上采样过程。基于与adaPool相同的公式,我们提出了adaUnPool来进行上采样。
我们展示了adaPool在保留描述性特征方面的有利效果。因此,这使得使用adaPool的模型能够始终提高分类和识别性能。AdaPool保持了较低的计算成本,并提供了一种保留先前信息的方法。我们还引入了adaUnPool并解决了超分辨率和插值任务。总之,我们做出了以下贡献:
• 我们改进了逆距离加权(IDW)[12]用于池化,并通过使用Dice-Sørensen系数(DSC)来计算相似性,利用其指数eDSC来加权核元素进行扩展。
• 我们提出了adaPool,这是一个参数化的可学习融合,由平均值和最大值的平滑近似部分组成。通过逆向的方法,我们开发了上采样过程adaUnPool。
• 我们引入了一个包含1,000个高帧率的4K视频的集合,名为Inter4K,用于评估帧超分辨率和插值算法。
• 我们在多个全局和局部任务上进行了实验,包括图像和视频分类以及目标检测。我们通过用adaPool替换原始池化层来展示一致的性能改进。我们还展示了adaUnPool在图像和视频超分辨率以及视频帧插值上的改进性能。
本文的其余部分结构如下。首先,我们讨论相关工作。然后,我 们详细介绍了我们的降采样方法eDSCPool、eMPool和adaPool,以及上采样方法adaUnPool(第III节)。我们在第IV节介绍了Inter4K,并在全局和局部图像和视频任务上进行评估(第V节)。最后,我们在第VII节中总结。
2 相关工作
A. 手工特征池化
在手工编码特征提取中,降采样被广泛应用。在词袋模型(BoW,[13])中,图像被表示为本地补丁的组合,这些补丁经过池化,然后编码为向量[14]。基于这种方法,空间金字塔匹配(SPM)[15]旨在保留空间信息。后续的研究通过线性SPM [16]扩展了这种方法,该方法在空间区域中选择最大的SIFT特征。早期的特征池化研究主要集中在最大池化上,基于生物皮层信号的最大似然行为[17]。Boureau等人[18]关于信息保留方面的最大池化和平均池化研究表明,在低特征激活设置下,最大池化产生的结果在代表性方面更具优势。
B. CNN中的池化
随着学习特征方法在各种计算机视觉任务中的普及,池化方法也已经适应了基于核的操作。在CNN中,池化主要用于创建紧凑的特征表示,以降低模型的计算需求,从而使更深层次的架构成为可能。
最近,降采样期间有关特征的保留已经变得更加重要。最初的方法包括随机池化,它使用核区域内激活的概率加权采样。其他池化方法,如混合池化,基于最大池化和平均池化的组合,可以通过概率方法或来自每种方法的部分组合来实现。Power Average(L p)[2]利用一个学习参数p来确定平均池化和最大池化的相对重要性。当p = 1时,使用总和池化,而当p → ∞时,对应于最大池化。
一些方法使用网格采样。S3Pool [4]随机采样原始特征图的行和列,以创建降采样版本。方法也可以使用学习权重,例如细节保持池化(DPP,[21])使用平均池化,同时增强高于平均值的激活。本地重要性池化(LIP,[6])利用子网络关注机制内的学习权重。图2中显示了不同池化方法执行的操作的视觉和数学概述。

图2. 池化变种。R表示核邻域,即一组像素。(i-ii) 平均池化和最大池化基于核区域内的平均或最大激活值。(iii) 幂均池化[1],[2]与平均池化成正比,其幂次为ρ。当ρ → ∞时,输出等于最大池化,而ρ = 1等于平均池化。(iv) 总和池化也与平均池化成正比,输出中所有核激活被求和。(v) 随机池化[3]从核区域中随机采样一个激活。(vi) 随机空间采样(S3Pool)[4]在指定的步幅下采样水平和垂直区域。(vi) 门控池化[5]基于门控掩码(ω)和S形函数使用最大-平均池化。(viii) 本地重要性池化(LIP)[6]使用可学习的子网络G增强特定特征。(ix-x) L1和L2反距离加权池化(IDW,我们的方法)根据它们到平均激活(a)的反距离来加权核区域。(xi) 指数最大池化(emPool/SoftPool,我们的方法)使用softmax核指数加权激活。(xii) 指数Dice-Sørensen系数加权池化(eDSCWPool,我们的方法)使用核激活(ai)和它们的平均值(a)的指数Dice-Sørensen系数[7],[8]作为权重。(xiii) 自适应指数池化(adaPool,我们的方法)将(xi)和(xii)结合起来,并使用可学习的权重掩码β。
文献中报告的大多数池化工作不能用于上采样。Badrinarayanan等人[11]提出了通过跟踪所选最大输入的内核位置来反转最大操作,而在上采样输出中,其他位置由零值填充。这确保了使用原始值,但输出本质上是稀疏的。最近,Zhao和Snoek [10]基于输入的四个可学习子频带提出了LiftPool。生成的输出由已发现的子频带的混合组成。他们还提出了他们方法的上采样反演(LiftUpPool)。这两种方法都基于子网络结构,限制了它们作为计算和内存高效的池化技术的可用性。
大多数先前提到的方法依赖于最大池化和平均池化的组合,或者包含子网络,这些都阻碍了低计算和高效的降采样。与组合现有方法不同,我们的工作基于自适应的指数加权方法,以提高信息的保留和更好地保留原始信号的细节。我们提出的方法adaPool受Luce的选择公理的启发。因此,我们根据它们的相关性来加权核区域,而不受相邻核向量的影响。这与平均池化和最大池化都不同。AdaPool使用两组池化核。第一组根据个别核向量与它们的均值的通道内相似性来确定它们的相关性。相似性是基于Dice-Sørensen系数计算的。第二组基于softmax加权来放大强度更大的特征激活[9]。 最后,来自两个核操作的输出被参数化地融合成一个体积。参数针对每个核位置是特定的,从而使我们的方法具有区域自适应性。
adaPool的一个关键特性是在反向传播过程中为每个核向量计算梯度。这改进了网络的连接性。此外,降采样区域不太可能表现出激活的消失趋势,正如平均池化或总和池化等等贡献方式观察到的。我们演示了adaPool如何能够自适应地捕捉细节,如图3所示,其中放大区域显示了一个特定的标志。AdaPool改善了字母和数字的清晰度和可辨认性。

图3. 使用不同池化方法保留细节的示例。常见的方法,如平均池化和最大池化,会导致扭曲的签名,细节不可辨认,如数字或字符。通过归一化局部最大值(eM)或基于相似性的指数加权(eDSCW)更好地捕捉细节。当引入这两种指数加权方法之间的自适应融合(adaPool)时,细节和表示质量进一步得到改善。
3 方法学
在本节中,我们介绍组成最终adaPool方法的两个过程(第III-A和III-B节),然后在第III-C节中介绍adaUnPool方法的反向过程。
我们首先介绍我们的池化方法的基本操作。我们将本地核区域R定义为激活图a的一部分,其大小为C×H×W,其中C通道数,高度H,宽度W。为了简化符号,我们省略了通道维度,并假设R是相对位置索引的集合,对应于k!×k的2D空间区域内的激活(即,|R| = k^2)。我们将池化输出表示为ea,并将相应的梯度表示为∇ai,在区域R内的第i个坐标位置。
A. 平滑近似平均池化
平均池化在核区域内对所有输入向量使用相等的权重。因此,合并的输出受到区域内的异常值的影响。我们认为改进区域平均值的计算,可以限制异常值在正向传递中创建池化图像以及反向传递中的梯度计算的影响。
逆距离加权(IDW)广泛应用于多元插值的加权平均方法[23],[24]。基本假设是几何上接近的观测值比几何上更远的观测值更相似。我们通过使用每个激活ai的距离,具有坐标索引i ∈ R,到R的平均激活a来将IDW扩展为池化的核加权。得到的汇总区域被表述为:
权重w(·, ·I DW)基于每个激活与平均激活之间的距离d(·, ·)的倒数:
![]()
距离函数d(·, ·)可以通过任何几何距离方法来计算。关于IDWPool的更多细节和限制将在附录VII-A中讨论。
由于距离方法在直接应用于输入区域时可能产生伪影(请参阅附录VII-A),因此使用相似性度量更适合池化的区域性质。对于广泛使用的余弦相似度,存在一个问题,即当两个向量之间的相似度为1时,即使其中一个向量是无限大,也会出现问题[25]。其他用于向量体积的点积方法,如Dice-Sørensen系数(DSC),通过考虑向量长度来克服这一限制。
鉴于公式1中的IDW方法,将分配零值距离或系数的权重为零。因此,我们的第二个扩展是使用激活向量与平均激活之间相似性的指数(e)。这在反向传播过程中使池化方法可微,因为至少会为每个位置计算最小梯度。它还减少了梯度消失问题出现的可能性。
基于相似性系数的指数介绍,我们重新构造公式1如下:
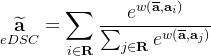
降采样的体积重要的是要在降低输入的空间分辨率的同时保留有信息的特征。创建不能完全捕获结构和特征外观的体积可能会对性能产生负面影响。如图3所示,可以看到这种细节的丧失。平均池化均匀降低激活的分辨率。相反,使用Dice-Sørensen系数的指数(eDSCWPool)可以通过根据它们与区域均值的相似性指数加权核值,从而确保分配非零权重,从而改善激活的保留。
B. 平滑近似最大池化
作为核区域内平滑近似平均的补充,我们讨论了基于平滑近似最大的降采样的公式,最近被引入为SoftPool[9]。为了清晰起见,并符合使用的术语,我们将SoftPool称为指数最大池化(eMPool)。
使用指数最大值的背后动机受到了皮质神经模拟的影响,这些模拟用于降采样手工编码的特征。该方法基于自然指数(e),它确保较大的激活将对最终输出产生更大的影响,同时还确保最低激活被分配到最小的权重值。指数最大池化(eMPool)中的权重用于基于相应激活值的非线性变换。具有较高值的激活将比具有较低值的激活更占主导地位。由于大多数池化操作是在高维特征空间上执行的,因此突出具有更大影响的激活比仅选择最大激活更加平衡。在后一种情况下,丢弃大多数激活存在丢失重要信息的风险。
eMPool的输出通过对核区域R内的所有加权激活进行求和来产生:
eMPool产生了归一化的结果,类似于eDSCWPool。结果基于一个概率分布,该分布与核区域内相邻激活的值成比例。
C. AdaPool:自适应指数池化
根据它们的属性,eDSCWPool使用核区域R内向量ai与平均激活a的相似性。然而,eMPool使用向量,其权重与它们的值成比例,具有较高值的激活被赋予更大的权重。从图3中,这两种方法都不能被认为优于另一种。然而,它们的属性可以互补地发现核区域内最具信息量的特征。基于这一观察,以及与Lee等人介绍的平均池化和最大池化融合策略[5]一致,我们使用可学习的权重掩码β来创建平滑近似平均值和平滑近似最大值的组合体积。在这里,β用于学习在每个核区域R内从两种方法中使用的比例。将β作为网络训练过程的一部分引入具有依赖于eMPool和eDSCWPool的属性组合的通用池化策略的优点。我们将该方法公式化为下采样的平滑近似平均值(ea eDSC)和平滑近似最大值(ea eM)的区域学习组合:
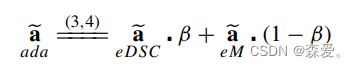
其中β∈{0,...,1}是与下采样体积ea(H'×W')相同大小的权重掩码。adaPool的可视化在图1中显示。用于反向传播的β的梯度是根据链式法则计算的:
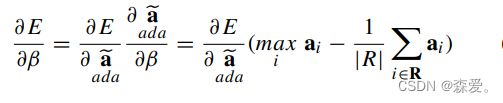
D. 使用adaUnPool进行上采样
池化将区域信息压缩为单一输出。大多数子采样方法不会在子采样和原始输入之间建立双向映射,因为大多数任务不需要这种连接。但是,语义分割[27],[28],[29],超分辨率[30],[31],[32],[33]或帧插值[34],[35],[36],[37]等任务显著受益于此。由于adaPool是可微分的并且使用了最小权重分配,因此在上采样过程中可以使用发现的权重作为先验知识。我们将这个上采样操作称为adaUnPool。
对于给定的池化体积(ea),我们使用平滑近似最大值(w(ai) eM )和平滑近似平均权重(w(a, ai) eDSCW )以及学习权重掩码β。第i个核区域(i ∈ R)的最终未池化输出(ai)计算如下:

其中IA(·)通过分配原核区域的池化体积(ea)来进行插值。该方法用于将体积从尺寸H'×W'扩展到H×W。
4 INTER4K视频数据集
我们引入了一个新的高分辨率视频数据集来评估上采样方法。Inter4K是一个包含1,000个60帧每秒(fps)的4K超高分辨率视频剪辑的集合,这些视频剪辑来自YouTube。该数据集提供了标准化的视频分辨率,包括超高清(UHD/4K)、四分之一高清(QHD/2K)、全高清(FHD/1080p)、(标准)高清(HD/720p)、四分之一全高清(qHD/520p)和九分之一全高清(nHD/360p)。每种分辨率都有不同的帧率可用,包括60、50、30、24和15 fps。根据这种标准化,可以为不同的缩放尺寸(×2、×3和×4)执行超分辨率和帧插值测试。在我们的实验中,我们使用Inter4K来处理帧上采样和插值两个任务。
与用于视频超分辨率和插值的其他数据集不同,Inter4K为所有视频提供了标准化的UHD分辨率和60 fps。该数据集分为800个用于训练的视频,100个用于验证,以及100个用于测试。视频长度为5秒(示例请参见图4),包括根据所使用的设备(例如专业的4K相机、手机)、光照条件、固定和移动相机以及动作、活动和物体的变化的不同场景。我们根据图5中呈现的六个主要类别的基本关注点,提供了Inter4K视频的摘要。类别是根据视频的主要焦点选择的。占视频90%的主要四个类别包括城市环境(例如建筑物、街道或车辆)、自然和动物、体育和人们的人类活动和行为,以及演示和抽象,包括用于视频分辨率和帧率的演示视频,或包含计算机生成的抽象形状的视频。最后两个类别在数据集中不太常见,可能是由于版权限制(音乐视频和电影)或视频稀缺(机械)。在图6中,我们展示了1,000个视频中的632个视频的位置可视化。这些位置是根据可用的地理标签、视频标题和关键字或视频中可识别地标的描述而找到的。图5和图6都展示了Inter4K在视频内容和视频拍摄地点方面的多样性。
图4. Inter4K视频帧样本。这些样本展示了高分辨率(UHD/4K)和帧之间的差异。由于快速运动和移动、复杂的光照、纹理和物体细节,这些视频对视频处理来说具有挑战性。

图5. Inter4K类别比例。这些类别是基于视频的广泛概念进行选择的。

图6. 各大洲的Inter4K视频分布情况。深色表示视频数量较多。
5 主要结果
我们首先评估不同池化方法引起的下采样的信息损失。我们使用标准相似性度量比较下采样后的图像和原始图像(第V-B节)。此外,我们还检查了每种池化方法的计算开销(第V-C节)。 然后,我们测试了在ImageNet1K上使用广泛使用的CNN架构时,将网络的原始池化层替换为eMPool、eDSCWPool和adaPool的性能(第V-D节)。我们还提供了不同池化方法之间的比较(第V-E节)。 我们在MS COCO上使用RetinaNet和Mask R-CNN进行对象检测的结果(第V-F节),使用了多个骨干网络。此外,我们还在时空数据上进行实验,重点关注视频中的动作识别(第V-G节)。 最后,我们呈现了图像超分辨率、帧插值以及它们的组合的结果(第V-H节)。
A. 实验设置
1 数据集:
对于我们基于图像的实验,我们使用七个不同的数据集,用于定量评估下采样图像质量、图像分类、目标检测和图像超分辨率。用于图像质量和相似性评估,我们使用高分辨率的DIV2K、Urban100、Manga109和Flicker2K数据集。用于图像分类的数据集是ImageNet1K,用于图像目标检测的数据集是MS COCO。用于图像超分辨率的数据集包括Urban100、Manga109和B100。对于基于视频的实验,我们使用六个数据集。用于动作识别的数据集包括大规模的HACS和Kinetics-700,以及较小的UCF-101数据集。用于帧插值的数据集包括Vimeo90K和Middlebury视频处理数据集,以及我们新引入的Inter4K数据集,它也用于帧插值和超分辨率的联合任务。
2 分类训练方案:
对于图像分类,我们使用大小为294×294的随机空间区域裁剪,然后调整大小为224×224。我们的实验中初始学习率设置为0.1,使用SGD优化器。我们总共训练100个时代,每40个时代进行一次学习率递减。在更多的时代中,没有观察到进一步的改进。批量大小设置为256。 对于视频动作识别测试,我们使用多网格训练方案,帧尺寸在4-16之间,帧裁剪在每个周期中在90-256之间。平均视频输入尺寸为8×160×160,批量大小在64到2048之间。每个批次的大小在每一步中与输入尺寸相等,以优化内存使用。我们在视频动作识别实验中使用与基于图像的实验相同的学习率、优化器、学习率计划和最大时代数。
3 目标检测细节:
我们首先对图像进行重新缩放,以确保最小边的大小至少为800像素。如果经过重新缩放后,最大边大于1024像素,我们将整个图像调整大小,使最大边变为1024像素。我们的重新缩放和调整大小保持了图像的纵横比。我们使用图像分类任务的预训练网络作为骨干网络。学习率设置为1e−5,使用带有0.9动量的SGD优化器。
B. 降采样相似性
在第一组测试中,我们评估了使用我们提出的方法进行降采样时的信息损失。比较主要关注原始输入和降采样输出之间的相似性。我们使用三种常用的池化核尺寸(k = {2, 3, 5})。我们使用三种标准化的评估指标[58],[59]:
结构相似性指数度量(SSIM)以亮度、对比度和结构项方面的两幅图像之间的差异来计算。较大的SSIM值对应于较大的结构相似性。
峰值信噪比(PSNR)是对生成图像的压缩质量的量化。PSNR考虑了两幅图像通道的均方误差(MSE)的倒数。较高的PSNR值表示两幅图像之间通道间距离较小。
学习的感知图像块相似性(LPIPS)是两幅图像中图像块之间的相似性测量。LPIPS比较了通过深度学习骨干提取的两幅图像的特征之间的距离。较低的LPIPS值对应于图像之间的更高相似性。
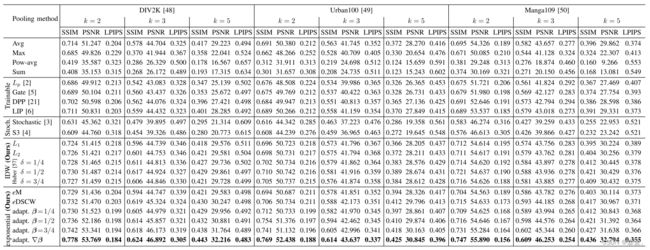
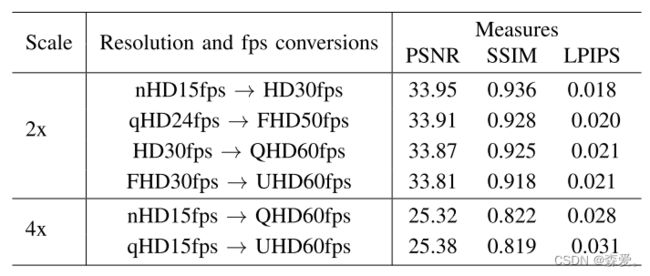
在表I和表II中,我们提供了在不同的核尺寸下,DIV2K [48]、Urban100 [49]、Manga109 [50]和Flicker2K [48]数据集中所有图像上平均的SSIM、PSNR和LPIPS值。基于IDW的距离方法优于不可训练和随机方法。随机方法的随机策略似乎不允许完全捕捉细节。此外,将指数权重引入我们的基于IDW的方法明显改进了性能。在不同的核尺寸和数据集上,eMPool和eDSCWPool表现出色,展示了指数逼近方法对图像降采样的益处。最后,将这两种指数方法组合成adaPool并学习融合参数β时,一贯实现了最佳综合性能。
表格I 高分辨率数据集上的定量结果。每个设置的最佳结果以粗体标出。
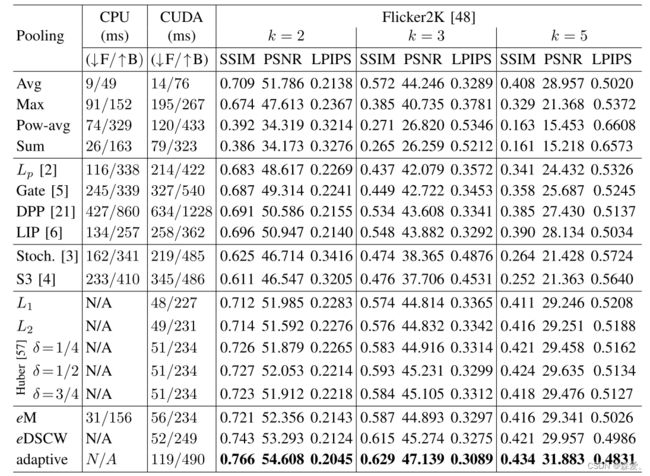
表格II 延迟和像素相似度。前向和后向传递的延迟在CPU和GPU上平均计算在ImageNet1K的所有图像上。像素相似度报告在Flicker2K。最佳结果以粗体显示。
C. 延迟和内存使用
从内存和延迟的角度来看,池化操作通常在文献中被忽略,因为单个操作的延迟时间和内存消耗很小。然而,鉴于可能有限的可用资源,以及事实上,这些操作在每个时期执行数千次,我们建议对运行时间和内存使用进行评估。慢或内存密集型的操作可能会对性能产生不利影响,并可能成为潜在的计算瓶颈。 表II中报告了基于CPU和GPU(CUDA)上每个操作的前向(↓ F)和后向(↑ B)传递的计算开销。我们观察到,尽管与平均、最大、幂平均或求和池化等方法相比,我们的实现在CUDA上实现了合理的推断时间,尽管需要额外的计算。
D. 在ImageNet1K上的图像分类性能
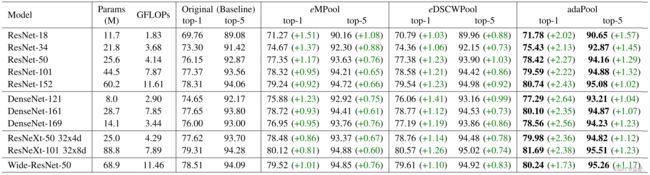
我们测试了使用指数权重方法在降采样期间更好地保留信息是否会提高图像分类准确性的假设。基于平均池化和最大池化以及adaPool之间的结果(表I和表II),我们将ResNet [60]、DenseNet [61]、ResNeXt [62]和wideResNet [63]网络中的原始池化层替换为我们的指数池化方法,并测试它们在ImageNet1K上的性能。结果见表III。在表IV中,我们总结了四次运行的结果,以确保公平比较。最高的准确率用“(best)”标记。
表格III ImageNet1K [51]上原始网络和将其池层替换为eMPool,eDSCWPool和adaPool的对照网络的Top-1和Top-5准确性的成对比较。所有网络都是从零开始训练的。最佳结果以粗体显示。有关参数和FLOP的更多详细信息请参见附录VII-E。
表格IV ImageNet1K [51]上原始网络和那些使用eMPool,eDSCWPool和adaPool的网络在多次运行中的Top-1准确性。我们为每种网络和池类型的组合进行了四次运行。最佳运行以(BEST)标识。最佳整体结果以粗体显示。

总体而言,将CNN的池化层替换为adaPool可以提高准确率。以下是关于各种CNN体系结构的更详细讨论:
-
ResNet [60]:当将ResNet模型的池化层替换为adaPool时,我们报告了top-1准确率平均提高2.19%,top-5准确率平均提高1.33%。使用eMPool和eDSCWPool替换的模型也观察到准确率的提高,分别为平均+1.17%和+1.15%的top-1准确率。ResNet体系结构仅在第一个卷积层之后包含一个池化操作。仅替换一个池化层就能实现准确性的提高,这表明adaPool对图像分类的益处。在表格IV中,我们没有观察到ResNet-18、ResNet-34和ResNet-50网络多次运行中的准确性显著差异。平均而言,使用adaPool替代原始ResNet-18可在多次运行中提高+2.01%的准确性,ResNet-34和ResNet-50分别提高+2.24%和+2.38%。
-
DenseNet [61]:DenseNet包括五个池化层。我们的替换涉及第一个卷积层之后的最大池化层和在密集块之间的四个平均池化层。使用adaPool替换各层后,top-1准确率平均提高2.35–2.64%。对于eMPool和eDSCWPool的替换,准确率提高较小,分别为+(0.93–1.23)%和+(1.12–1.41)%。
-
ResNeXt [62]:我们使用adaPool替换时,平均提高了2.37%的top-1准确率和1.17%的top-5准确率。对于eDSCWPool的替换,top-1和top-5准确率的平均提高分别为1.20%和0.76%。对于eMPool的替换,这些改进分别为0.83%和0.64%。
-
Wide-Resnet-50 [62]:在Wide-ResNet-50上,当我们将原始池化层替换为adaPool时,我们观察到最佳的top-1准确率为80.24%,准确率提高了1.73%。eMPool和eDSCWPool的替换也提高了性能,分别为+1.01%和+1.10%。
我们在表格V中提供了六种不同模型下不同池化方法的定量比较。我们系统性地替换了原始模型(基准模型)的池化层。对于LIP,我们考虑了与其他实验一致的替代方案,以及与文献[6]中的LIP-ResNet和LIP-DenseNet体系结构一致的多次替代方案。非自适应的eMPool和eDSCWPool仍然优于随机方法,而获得的准确率与可学习的方法相似。在测试的各种体系结构中,adaPool优于其他可学习和随机的池化方法。在InceptionV1上观察到最大的整体边际,其性能改进范围在1.61–2.78%,在DenseNet121上为0.65–2.64%。
E. 与替代池化方法的比较
我们在表格V中提供了关于六个不同模型的不同池化方法的数量化比较。我们系统性地替换了原始模型(基准模型)的池化层。对于LIP,我们考虑了插入替代方案,与我们其他实验一致,以及根据论文[6]中的LIP-ResNet和LIP-DenseNet架构进行了多次替代。非自适应的eMPool和eDSCWPool仍然胜过随机方法,同时其准确性与可学习方法相似。在经过测试的各种架构中,adaPool优于其他可学习和随机池化方法。最大的整体改进幅度出现在InceptionV1上,改进幅度在1.61%到2.78%之间,以及在DenseNet121上为0.65%到2.64%。
表格V 不同池化方法的池化层替换Top-1准确性。实验在ImageNet1K上进行。每个网络中的最佳结果都以粗体显示。

F. 在MS COCO上的目标检测性能
为了探讨我们提出的指数加权池化方法在捕捉相关的局部信息方面的优点,我们在表VI中呈现了在MS COCO上的目标检测结果。我们使用了RetinaNet和Mask-RCNN,它们分别采用了不同的骨干网络。我们选择了这两个模型,因为它们非常受欢迎。 总体而言,我们观察到eMPool和eDSCWPool都具有平均精度(AP)的提高,分别为1.00%和0.86%。adaPool的性能相较于原始模型提高了2.40%。AP50和AP75也显示了类似的趋势,表明adaPool不仅有助于依赖于一般特征的任务,如分类,还提高了依赖于局部特征的任务,比如目标检测的性能。
表格VI 使用原始骨干网络和使用我们的指数池化层替换池化层的相同网络的MS COCO测试-开发集上的目标检测边界框AP结果。所有模型都是在ImageNet1K上进行预训练的。最佳结果以粗体显示。

G. 视频分类性能
我们通过关注视频中的动作识别任务来评估我们的池化操作符在时空数据上的性能。在视频理解领域,准确的时空特征分类和表示是一个重要挑战。 大多数时空网络是基于将2D卷积扩展到3D以包含时间维度。输入使用帧的堆叠。类似地,我们方法的唯一修改是在核区域R中包含时间维度。 在我们的测试中,我们首先使用作者的实现从头开始在HACS上训练模型。然后,这些模型用于初始化Kinetics-700和UCF-101测试的权重。SlowFast(SF)[69]和ir-CSN-101 [67]是使用不同初始化权重的两个模型,ir-CSN-101是在IG65M上预训练的,而SF是在ImageNet上预训练的。在表VII中,我们报告了三个时空CNN模型的性能,其中池化层被adaPool替换。我们观察到MTNetL与adaPool在HACS和Kinetics-700上表现出最先进的性能,分别达到了87.83%和64.67%的top-1准确度。这相较于原始池化层的同一网络提高了1.21%和1.36%。这也伴随着可忽略的额外GFLOPs(+0.2)。在UCF-101上,我们展示了MTNetL和SRTG r3d-101与adaPool相比,优于原始模型和其他性能卓越的模型。SRTG r3d-101在HACS上的top-1性能提高了2.71%,在Kinetics-700上提高了1.47%。这些结果进一步证明,仅通过adaPool替换池化操作符,可以一致地实现性能的适度但重要的提升。即使在UCF-101上性能几乎饱和,使用adaPool也使MTNetL的性能提高了1.22%。
表格VII HACS、K-700和UCF-101的动作识别TOP-1和TOP-5准确性。模型在HACS上进行训练,然后在K-700和UCF-101上进行微调,除了IR-CSN-101和SF R3D-50(详见正文)。N/A表示没有提供训练好的模型。最佳结果以粗体显示。

H. 图像超分辨率和帧插值结果
为了评估在adaUnPool中重复使用学习到的adaPool权重的好处,我们进行了图像超分辨率、视频帧插值以及它们的组合实验。对于每个任务,我们将池化层替换为adaPool,将双线性插值替换为adaUnPool。我们在图VIII中展示了有关图像超分辨率的比较。使用ada(Un)Pool替换下采样和上采样层的RCAN [73]和HAN+ [75]在性能上表现出色。我们观察到,在2×和4×图像上采样的两种情况下,我们转换后的网络不仅优于它们的原始实现,还优于其他方法。
表格VIII 2×和4×图像超分辨率。最佳和次佳结果以粗体和下划线显示。

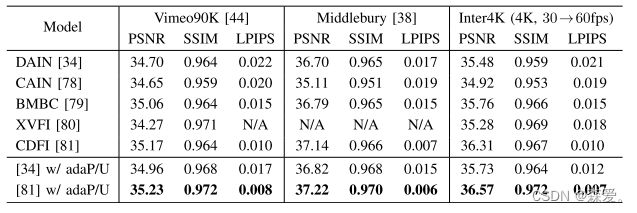
我们在表IX中展示了将所有池化和插值层替换为ada(Un)Pool进行帧插值的优点。两个转换后的网络,DAIN [34]和CDFI [81],在经过测试的数据集上产生了改进的结果。CDFI与adaPool和adaUnPool结合在Vimeo90K、Middlebury以及我们的Inter4K上均取得了最先进的结果,将30到60 fps的4K视频插值。 我们还在Inter4K上执行了帧超分辨率和插值的组合任务的性能基准测试,使用CDFI+ada(Un)Pool。我们的研究结果在表X中报告。总体而言,我们观察到在高分辨率、高帧率转换方面性能略有下降。
表格IX VIMEO90K,MIDDLEBURY和INTER4K的定性帧插值结果。N/A表示原始作品未提供结果。 最佳结果以粗体显示。
表格X 在INTER4K上使用CDFI进行帧插值和超分辨率。第二列中指示了原始和处理后视频的分辨率和FPS。 最佳结果以粗体显示。
6 消融研究
在本节中,我们研究了adaPool不同设计选择的影响。首先,我们考虑将β权重掩模设置为可训练参数或常数值的效果(第VI-A部分)。此外,我们提供了对InceptionV3 [82]的池化层替换的结果(第VI-B部分),评估了融合和池化方法替换的性能(第VI-C部分),并与转换为下采样的基于注意力的方法进行了比较(第VI-D部分)。最后,我们呈现了网络显著性和特征嵌入空间的定性可视化,对比了原始模型和adaPool替代模型(第VI-E部分)。除非另有说明,实验设置遵循第V-A部分所描述的设置。
A. β权重掩模的影响
为了研究不同估算的最大值和平均值组合对我们提出的 adaPool 方法的影响,我们在ImageNet1K上提供了表XI中的结果,使用了几个常数 β 值,并研究了当将 β 转换为可训练权重掩码时的性能提升。
表格XI β值对IMAGENET1K图像分类的影响。较大的β值对应于更强的eDSCWPOOL,而较小的β值更看重eMPOOL。最佳结果以粗体显示,次优结果以下划线显示。
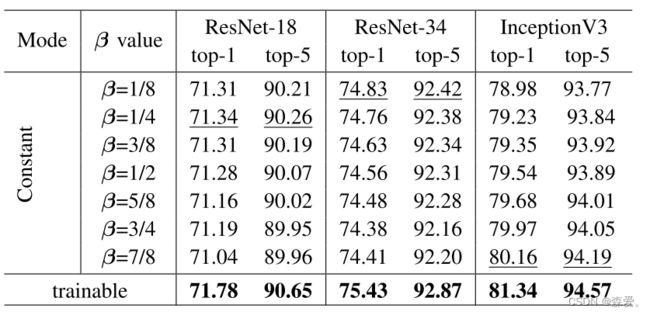
总体而言,可训练设置在所有三个测试网络上提供了最佳性能。可训练权重掩模相对于表现最佳的固定值的性能提升在复杂架构中更为明显。在ResNet-18中,top-1的差异为0.44%,而在InceptionV3中为1.18%。我们在附录VII-D中提供了更多基于参数的消融研究。
B. InceptionV3的逐层消融
为了了解adaPool在不同网络深度上的影响,我们在InceptionV3架构的不同池化层上进行了分层的消融。这个选择主要基于Inception块的结构,其中包括池化操作。这允许对池化运算的变化进行每个块的评估。
从表格 XII 中总结的结果来看,我们可以预期,每替换一个原始的池化操作为 adaPool,平均 top-1 精度将提高 0.56%。尽管性能提升是有规律的,但在替换初始卷积层后的第一个池化操作 (pool1) 和最后的 Inception 块 (mixed7b-d) 上观察到最大的改进,精度分别提高了 0.89% 和 0.80%。因此,我们证明 adaPool 通过其自适应加权提高了准确性,无论网络深度和通道数量如何。
表格 XII 在ImageNet1K上对InceptionV3进行渐进层替代。列号表示替代的池化层的数量,用 ✓ 标记。最佳结果以粗体显示。

C. 池化方法与融合策略的比较
我们提供了与[5]中提出的其他池化方法和融合策略的比较。混合池化融合策略对应于使用单个参数来融合所使用的池化方法。这可以被视为自适应池化的特例,其中 |β| = 1。门控融合方法使用一个学习参数来选择所使用的两种池化方法之一。除了我们的 eDSCW+eM 组合,我们还测试了平均池化/最大池化的融合策略。
我们的比较结果如表 XIII 所示。平滑近似平均值和最大值的组合在不同的平均值或基于最大值的组合上表现良好。我们还观察到通过自适应融合使用参数掩模有助于提高性能。
表格 XIII 基于不同的池化和池化组合方法在ImageNet1K上多次运行的TOP-1准确率。

D. 与基于注意力的下采样方法的比较
最近引入的基于注意力的方法已经在一系列高级视觉任务中显示出了很大的潜力。因此,我们还研究了三种不同的基于注意力的方法的可用性,通过将它们用于下采样进行了调整。我们测试了通道级的 Squeeze-and-Excitation(SE)[83] 注意力模块,局部应用的卷积块注意力模块(CBAM)[84],以及使用全局注意力对输入的空间缩减 KQV 线性投影进行多尺度自注意力模块(MSA)[85]。这些测试模块在注意力模块之后(SE、CBAM)或之前(MSA)进行池化。
从表 XIV 中呈现的结果来看,我们观察到,我们提出的 adaPool 比任何基于注意力的方法要高效得多,仅需要额外的 +1.5 MFLOPs 和 4.2K 参数。与基于 SE 和 CBAM 的池化方法相比,adaPool 表现出色,但与基于 MSA 的平均值或 SoftPool 相比,性能略有下降。需要注意的是,adaPool 与基于 MSA 的池化方法之间的性能与计算复杂性的权衡是巨大的,MSA 需要的 FLOPs 比 adaPool 多 1,600 倍。对于 DenseNet-121,使用基于 MSA 的池化方法的计算负担占模型使用的总 FLOP 数的 30%。
表格 XIV 在ImageNet1K上,将adaPool与密集连接网络(DenseNet-121)的基于注意力的下采样方法进行比较,同时考虑SE [83],CBAM [84]和MSA [85]。最佳结果以粗体显示。

E. 定性可视化
为了更好地理解 adaPool 对特征提取过程的影响,我们使用 GradCAM [86] 计算显著性图,以可视化原始网络和 adaPool 替代网络的显著区域,如图 8 所示。我们使用表 III 中的固定 ResNet-50 模型,并从 ImageNet 类别“海盗船”、“网球”、“卡丁车”、“海狮”、“敞篷车”和“划艇”中抽样示例。
图 8. 显著性图。我们比较了两个ResNet-50模型的视觉显著性地图,一个使用原始的最大池化,另一个使用提出的adaPool。示例来自ImageNet1K的验证集。对于每个图像,我们展示了真实的标签。
对于像“卡丁车”和“海狮”这样的情况,其中类的多个对象出现在图像中,基于 adaPool 的网络生成更好地适应其区域的显著性图。由于更好地保留了输入的细节,模型更关注包含类的更多描述性特征的区域,例如“海盗船”示例中的帆或“网球”示例中的球拍和网球。
另外,在图 7 中,我们提供了原始网络和 adaPool 替代的 InceptionV3 特征嵌入的 t-SNE [87] 可视化。我们按照 [9] 中的相同方法进行,使用 PCA 将维度降低到 50 个通道。总体上,类似示例的特征嵌入在启用 adaPool 的网络上显示出更接近的映射。例如,“甜椒”类别的特征嵌入在 adaPool 启用的网络上更清晰地区分了不同椒类的颜色,以及图像中多个或单个椒类的区别。
a. 类别 "火烈鸟" b. 类别 "原声吉他" c. 类别 "甜椒"
图 7. InceptionV3 的 t-SNE 特征嵌入,带有(底部)和不带(顶部)adaPool。使用的ImageNet1K类别包括“火烈鸟”、“原声吉他”和“甜椒”。
7 结论
本文中,我们提出了 adaPool,这是一种基于自适应指数权重的用于保留信息特征的池化方法。它是一种区域自适应方法,使用指数最大值 eMPool 和指数平均值 eDSCWPool 的参数化融合。adaPool 的权重可以用于反向池化操作(adaUnPool),以实现上采样。
我们在图像和视频分类、图像相似度、目标检测、图像和帧超分辨率任务以及帧插值任务上测试了我们的方法。实验一致表明,当面临各种挑战时,如捕捉全局和局部信息,或考虑2D图像数据和3D视频数据时,我们提出的方法具有显著的优势。在所有下游任务中,使用各种网络骨干和实验设置,adaPool 在性能上系统地优于其他任何方法,同时计算延迟和内存使用保持适度。基于这些广泛的实验,我们认为adaPool是目前流行的池化算子的一个良好替代品。
附录 A
在本附录中,我们提供了对逆距离加权(IDW)池化的更多细节(第VII-A节),我们使用Dice-Sørensen系数(DSC)的动机(第VII-B节),与其他软平均方法的比较(第VII-C节)以及我们实现的计算复杂性描述(第VII-E节)。
A. 逆距离加权池化
为了分配权重值,IDW依赖于区域内的测量观测距离。权重过程的可视化表示如图9所示。为了克服均匀加权区域平均的局限性,我们将IDW适应到池化中,我们称之为IDWPool。我们在第V节中使用了均值和个体激活之间的欧几里德距离(L2)。在以下各节中,我们还提供了备选距离函数的结果。与均匀加权平均相比,IDWPool生成了具有更高权重的归一化结果,这些权重是几何上靠近均值的特征激活向量。这也适用于梯度的计算,并减少了离群值的影响,基于特征激活的相关性提供了更好的代表性更新率。在这个方面,IDWPool的工作方式不同于在其中输出激活没有规范化的平均所有激活的常见方法。
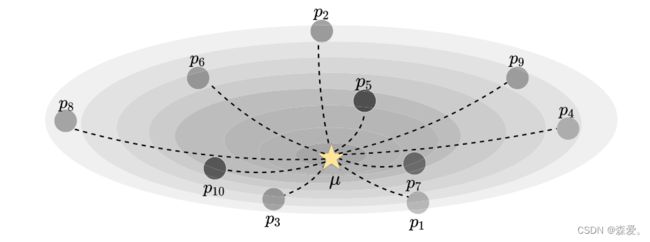
图 9. 逆距离加权。给定特征空间中的多个点 {p1, . . . , pn} 以及它们的均值 (µ),它们的权重等于它们的距离的倒数除以它们的总和。
尽管IDWPool可以改善均匀加权平均,但我们认为基于距离的加权平均在多维空间上是次优的。朴素IDWPool实现的主要缺点之一是特征激活向量和区域均值之间的L1或L2距离是基于每个通道对的均值、总和或最大值计算的。由于成对距离也是无界的,因此计算得到的距离也是无界的。此外,计算的距离对通道对异常值敏感。这在图10中的逆距离加权方法的像素伪影中可见。使用距离方法时,在某些通道中计算得到的距离可能明显大于其他通道。这会导致权重接近零(w(ac, aj,c) I DW → 0)的问题。

图 10. 平均距离/相似性加权方法的示例。基于IDW [12]的距离核权重,使用不同的逆距离函数。基于(e)PCEW、(e)cosW和(e)DSCW的相似性核权重。
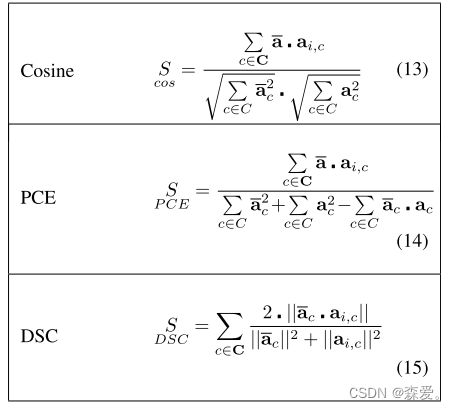
B. 基于系数的方法
我们考虑了其他基于相似性的方法来找到两个矢量体的相关性[90]。除了余弦相似度外,Kumar和Hassebrook峰-相关能量(PCE)[91]也可以应用于矢量体(如表XVI所示)。我们在图10中展示了基于不同相似性方法的池化质量差异。考虑到余弦相似度的前述不足,我们使用DSC而不是PCE主要是因为PCE的非单调性和值分布[91]。
表格 XVI 用于向量的相似性函数。所有方法都可以直接应用于多维向量体积。
C. 与替代软平均方法的比较
为了评估不同距离和相似性度量对图像分类性能的平均逼近池化的影响,我们使用ResNet-18作为骨干网络。我们将原始的ResNet-18与最大池化设置为基线。表XVII中的结果显示了IDW池化中不同距离之间的微小差异。基于Huber的池化在L1、L2和Chebyshev距离加权的范围内,表现出轻微的top-1准确性改进,为+(0.10–0.19)%。使用Gower方法观察到轻微的性能降低。这可能是因为Gower使用L1距离除以通道数(公式12)而产生较小的权重值。
表格 XVII 在ResNet-18上使用基于距离和相似性的池化替代方法进行ImageNet1K分类。基于距离的方法以IDW标示,而基于相似性的方法以SIM标示。最佳结果以粗体显示。
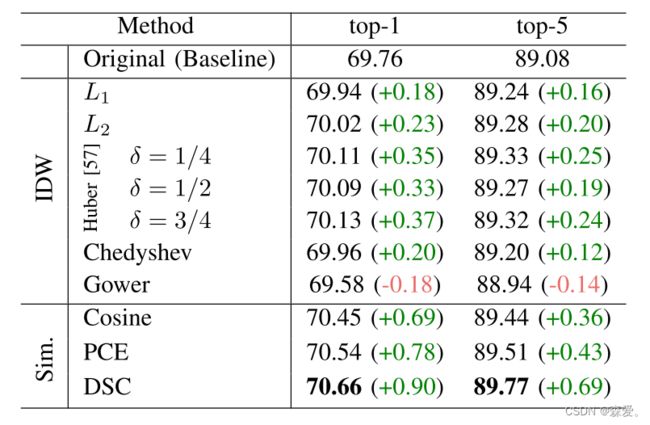
与距离方法相比,相似性度量在基线模型上显示出更大的增加。这可以归因于每个输入体的稀疏性。考虑到卷积核的相对较小尺寸(k×k)和它们所在的高维空间,点与其均值之间的距离较大[92]。Dice-Sørensen系数在top-1和top-5准确性方面最有效,分别为70.66%和89.77%。在表III中,通过DSC的指数观察到eDSCWPool的增加,分别为70.79%的top-1和90.16%的top-5准确性。
D. β参数化替代方案的消融
由于adaPool引入了额外的参数,因此我们评估观察到的性能增益是否确实是由于改进的信息保留还是仅仅是因为引入了更多的参数。我们使用三种不同的β大小:在每个位置上共享的单个|β| = 1参数,我们提出的在每个位置上具有独立参数的掩码|β| = H ′×W′,以及通道级掩码|β| = H ′×W′×C,用于位置和通道参数。我们在表XVIII中提供了ResNet-50和DenseNet-161的结果。
表格 XVIII 在ImageNet1K上,对ResNet-50和DenseNet-121的adaPool β 参数化替代方法。最佳结果和设置以粗体显示。

我们观察到,我们提出的基于掩码的β与在两个模型中大部分参数化的通道级β之间存在差异,在ResNet-50中为1.01%,在DenseNet-121中为1.28%。这些结果表明,性能的提升并不仅仅取决于引入额外的参数。
与其他非通道级参数化方法相比,通道级β的性能较差。这表明池化方法更适用于具有更大通道和特征依赖性的数据。与大多数模型使用的参数相比,我们提出的方法只引入了少量额外的参数,在ResNets上为+3.1K,在DenseNets上为+4.2K(请参阅表XIX)。
表格 XIX 在不同架构族中包含adaPool时的参数和FLOPS开销。

我们得出结论,观察到的性能改进与adaPool的设计密切相关,而不仅仅是由于额外的参数。
E. 计算描述
我们的实现是在CUDA上进行的,因此可以在GPU上本地运行,提供了接近平均和最大池化等本地方法的推断时间。由于指数最大和平均池化方法都具有并行化能力,因此运行时间接近于平均池化,分别具有O(2)和O(3)的计算复杂度,因为操作可以在卷积核区域矩阵上并行执行。相比之下,最大池化的计算复杂度为O(n),因为要按顺序考虑区域内的每个输入以发现最大值。
由于CUDA的内存减少通过分块的数据划分,eMPool和eDSCWPool与平均和最大池化不相上下。此外,两者都可以通过融合乘法-加法(FMA)来实现,这会显著提高CUDA启用设备上的性能[93]。
致谢
作者们要感谢荷兰科学研究组织(NWO)的支持。