机器学习---决策树算法梳理
决策树算法梳理
- 任务3 - 决策树算法梳理
-
- 1、信息论基础(熵 联合熵 条件熵 信息增益 基尼不纯度)
- 2.决策树的不同分类算法(ID3算法、C4.5、CART分类树)的原理及应用场景
- 3、回归树原理
- 4、决策树防止过拟合手段
- 5、模型评估
- 6、sklearn参数详解,Python绘制决策树
任务3 - 决策树算法梳理
1、信息论基础(熵 联合熵 条件熵 信息增益 基尼不纯度)
(1)熵: 表示随机变量不确定性的度量。

(2)联合熵 :一组变量之间不确定性的衡量手段。
两个变量:
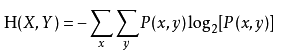
多个变量:

(3)条件熵 :表示在已知随机变量X的条件下随机变量Y的不确定性。

(4)信息增益 :表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
(5)基尼不纯度:是指将来自集合中的某种结果随机应用在集合中,某一数据项的预期误差率。在进行决策树编程的时候,可以作为衡量系统混乱程度的标准。
2.决策树的不同分类算法(ID3算法、C4.5、CART分类树)的原理及应用场景
1、ID3算法:主要针对属性选择问题。


2、C4.5算法

3、CART分类树(分类与回归树)
由两部分组成:
(1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;
(2)决策树剪枝:用验证数据集对已生成的数进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。


3、回归树原理
参考大神:
https://blog.csdn.net/aaa_aaa1sdf/article/details/81588382
4、决策树防止过拟合手段
对决策树进行剪枝来简化学到的决策树。决策树的剪枝,往往从已生成的树上剪掉一些叶结点或叶结点以上的子树,并将其父结点或根结点作为新的叶结点,从而简化生成的决策树。
剪枝算法如下:

5、模型评估
1、随机二次抽样
2、交叉验证
3、自助法
参考学习:https://www.cnblogs.com/fushengweixie/p/8039991.html
6、sklearn参数详解,Python绘制决策树
1、sklearn参数详解
参考自链接:
https://mp.weixin.qq.com/s?__biz=MzI2MjE3OTA1MA%3D%3D&idx=1&mid=2247484903&scene=45&sn=e3c3af7b600854c65df01cf93d8a21f4
https://www.jianshu.com/p/d1d17499365c
criterion:特征选择的标准,有信息增益和基尼系数两种,使用信息增益的是ID3和C4.5算法(使用信息增益比),使用基尼系数的CART算法,默认是gini系数。
splitter:特征切分点选择标准,决策树是递归地选择最优切分点,spliter是用来指明在哪个集合上来递归,有“best”和“random”两种参数可以选择,best表示在所有特征上递归,适用于数据集较小的时候,random表示随机选择一部分特征进行递归,适用于数据集较大的时候。
max_depth:决策树最大深度,决策树模型先对所有数据集进行切分,再在子数据集上继续循环这个切分过程,max_depth可以理解成用来限制这个循环次数。
min_samples_split:子数据集再切分需要的最小样本量,默认是2,如果子数据样本量小于2时,则不再进行下一步切分。如果数据量较小,使用默认值就可,如果数据量较大,为降低计算量,应该把这个值增大,即限制子数据集的切分次数。
min_samples_leaf:叶节点(子数据集)最小样本数,如果子数据集中的样本数小于这个值,那么该叶节点和其兄弟节点都会被剪枝(去掉),该值默认为1。
min_weight_fraction_leaf:在叶节点处的所有输入样本权重总和的最小加权分数,如果不输入则表示所有的叶节点的权重是一致的。
max_features:特征切分时考虑的最大特征数量,默认是对所有特征进行切分,也可以传入int类型的值,表示具体的特征个数;也可以是浮点数,则表示特征个数的百分比;还可以是sqrt,表示总特征数的平方根;也可以是log2,表示总特征数的log个特征。
random_state:随机种子的设置,与LR中参数一致。
max_leaf_nodes:最大叶节点个数,即数据集切分成子数据集的最大个数。
min_impurity_decrease:切分点不纯度最小减少程度,如果某个结点的不纯度减少小于这个值,那么该切分点就会被移除。
min_impurity_split:切分点最小不纯度,用来限制数据集的继续切分(决策树的生成),如果某个节点的不纯度(可以理解为分类错误率)小于这个阈值,那么该点的数据将不再进行切分。
class_weight:权重设置,主要是用于处理不平衡样本,与LR模型中的参数一致,可以自定义类别权重,也可以直接使用balanced参数值进行不平衡样本处理。
presort:是否进行预排序,默认是False,所谓预排序就是提前对特征进行排序,我们知道,决策树分割数据集的依据是,优先按照信息增益/基尼系数大的特征来进行分割的,涉及的大小就需要比较,如果不进行预排序,则会在每次分割的时候需要重新把所有特征进行计算比较一次,如果进行了预排序以后,则每次分割的时候,只需要拿排名靠前的特征就可以了。
2、python实现参考:
http://www.4u4v.net/hui-gui-shu-di-yuan-li-ji-qi-python-shi-xian.html
https://www.cnblogs.com/qwj-sysu/p/5974421.html