一篇搞懂浏览器的工作原理(万字详解)
摘要
本文是学习极客时间上的课程,进而整理出的浏览器工作原理。
第一部分:浏览器的进程和线程
(1)进程和线程的区别?
在浏览器中,各个进程负责处理自己的事情,而不同的进程中,也有线程之间相互配合,所以在了解浏览器的工作原理之前,要明白进程和线程之间的区别。
- 线程不能单独存在,它要由进程来启动和管理
- 一个进程就是一个程序的实例
- 线程依附于进程,一个进程采用多个线程可以提高效率
- 线程之间共享进程的数据
- 当一个进程关闭之后,操作系统会回收进程所占用的内存
- 进程和进程之间相互独立
(2)单进程浏览器的缺点
在远古时期,浏览器还是单进程的。当然现在肯定不是,所谓单进程浏览器,就是整个浏览器的工作全部在一个进程里,那对于单进程浏览器,它的缺点都有什么?
- 不稳定:不管是一个页面,还是一个JS程序执行出问题,还是一个脚本或者一个插件执行出问题,就会导致整个浏览器崩溃,直接GG。
- 不流畅:所有的页面渲染都在一个进程中,如果一个渲染JS效率比较低,会导致整个渲染流程不流畅。同时单进程中渲染过于复杂,在关闭页面后浏览器不能回收所有内存,从而导致内存泄漏。
- 不安全:自定义的脚本和插件,会拿到操作系统的系统权限和安全数据
(3)多进程浏览器
既然单进程浏览器的缺点这么明显,那么是否可以考虑将负重比较大的单进程。拆分成负责不同功能模块的多进程呢?
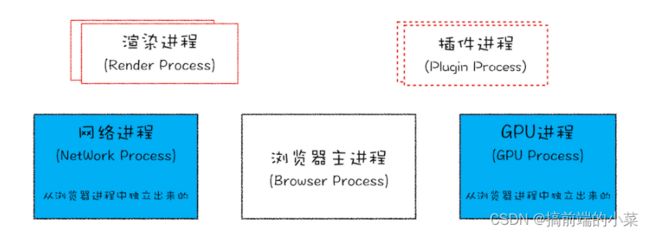
可以在上图看到,不同进程之间负责不同的内容。
不同进程的工作内容
浏览器主进程: 主要负责页面展示,用户交互,子进程管理,同时提供存储功能。
渲染进程: 每个页面都有自己的渲染进程。主要是将html,js,css转换为可以显示的网页。我们经常听到的V8引擎就是在这个进程里。
GPU进程: 主要是为了实现3D,CSS的效果
网络进程: 主要负责网络加载
插件进程: 如果有插件的话,会为插件单独开一个进程用来运行。
所以我们现在已经知道,如果有人问你
当你打开一个浏览器,浏览器会开几个进程?答案是四个,因为有可能没有插件进程。
当然你也可以打开浏览器的任务管理器自己查看当前浏览器的进程:

多进程的缺点
当然和优点比起来,缺点显得就微不足道了。
- 更高的资源占用:因为进程多了资源占用的自然就多
- 更复杂的体系结构:浏览器耦合性差,扩展性差,会导致现在的架构很难适应新的需求。
(3)常见问题
问:既然每个页面都有一个渲染进程,那为什么有时候一个页面卡死,会影响其他的页面。
答:通常来讲,一个页面只有一个渲染进程。但是如果两个页面来自一个站点(例如只是端口号不同),那么这两个页面会使用同一个渲染进程。
问:多进程是如何解决安全问题的。
答:在渲染进程和插件进程中,做了沙箱处理。他们无法在硬盘写入任何数据,也不能在敏感位置读取数据。
第二部分:从输入URL到页面展示,这中间发生了什么?
OK,这也是一道很常见的面试题。现在,我们了解了每个进程都是干什么的了。我们通过从进程的角度,来解释这一个问题。
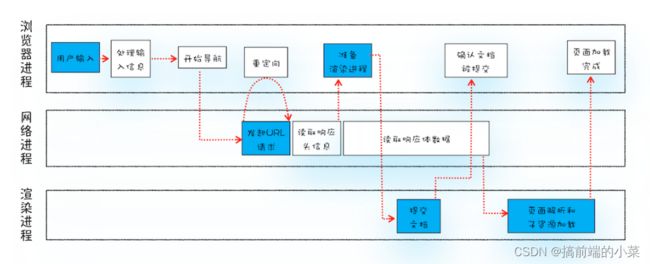
先将流程图附上,在后面的讲解可以比对着这张图来看。
浏览器进程
- 判断用户输入的关键字为搜索内容还是URL
- 如果是搜索内容,就使用浏览器默认的搜索引擎,来合成带搜索内容的URL
- 如果是请求的URL,就会将请求的URL拼接成合法的,完整的URL,通过IPC把请求的URL交给网络进程。
网络进程
- 网络进程查找本地缓存,是否命中强缓存,如果命中,直接将缓存交给浏览器进程
- 如果没有命中强缓存,通过DNS对域名解析成IP地址
- 利用IP地址,建立TCP连接,发送HTTP请求,服务器返回响应信息
- 返回信息中,如果命中协商缓存,继续从缓存里拿资源,交给浏览器进程。否则进行下一步
- 返回的状态码如果是301 或者 302,就要进行重定向,回到第一步
- 返回的状态码如果是200,那么读取响应数据,并且交给浏览器进程。
- 关闭TCP连接
如果你对HTTP的缓存比较陌生,可以先看这一篇文章来了解强缓存和协商缓存:
Http缓存 — 强缓存和协商缓存(详解)
渲染进程
- 此时渲染进程已经准备完毕,但是文档信息还在浏览器进程里面
- 浏览器进程发起提交文档的信息
- 渲染进程接受到提交文档的消息后,和网络进程建立传输管道
- 数据传输完毕后,渲染进程返回确认提交的信息给浏览器进程
- 浏览器进程接受到消息后,会更新浏览器的状态(页面的url,前进后退的历史状态),更新页面
所以下次如果有人问你这个问题,你就可以从浏览器多进程的角度来解释。
第三部分:浏览器的渲染进程
(1)构建DOM树
当渲染进程拿到了请求的资源后,html文档是不能够被浏览器所识别的。所以需要将html文档转化为能够被浏览器所识别的DOM树。
DOM树是一个具有层级关系的树形结构,上面的每一个节点就是DOM元素。
DOM树也就是document,上面暴露了很多操作节点的API,例如document.getElementById方法。我们可以在浏览器控制台输入document查看DOM树。

(2)样式计算
在这个过程,主要是计算出每个DOM节点对应的具体样式。
转换CSS结构
CSS的来源主要有以下三种:
- 通过link标签引入的外部CSS
- style标签里的CSS内容
- 元素里嵌套的CSS样式
浏览器也是无法理解CSS的样式,所以要转换成浏览器可以理解的结构,styleSheets。
可以通过document.styleSheets来查看CSSOM树的结构。

转换样式表的属性值,使其标准化
因为我们在CSS中写得属性值都是各种各样的,所以要将它转换成浏览器容易识别的标准值。

计算出DOM树中每个节点的样式
由于在CSS中,我们知道有一个非常重要的机制,就是继承。那继承来的样式,并没有在对应的DOM节点上标记,所以我们要在这一个过程,计算出每个DOM节点的样式。

(3)布局阶段
当浏览器将html和css转换成了DOM树和CSSOM树之后,还不能进行渲染页面。需要经过布局计算的过程。
创建布局树
该过程主要检查DOM树上的每个节点的样式。是否具有隐藏样式(例如display:none),如果有的话就屏蔽掉,从而构建出一颗新的布局树。
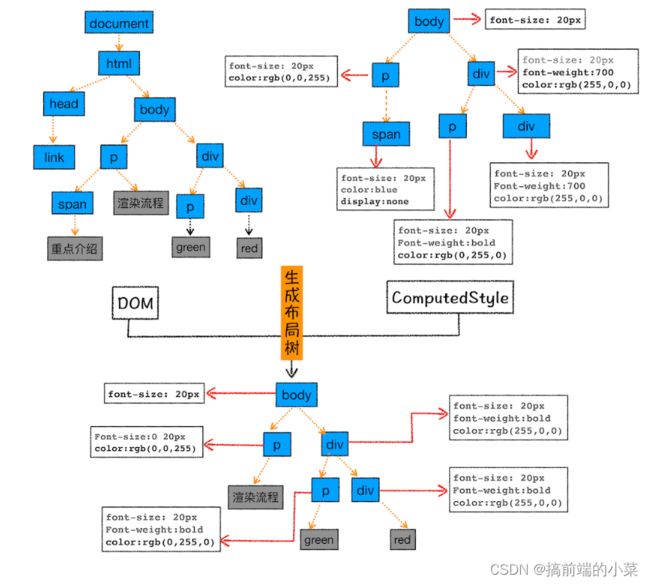
布局计算
该环节主要是计算布局树中,每个节点的坐标位置。
(4)分层阶段
有了布局树之后,还是不能渲染页面。因为没有考虑到Z轴以及3D动画的问题。所以在这一步要对布局树进行分层处理。
所谓分层处理,就是将布局树分为几个图层,每个节点在自己的图层里。
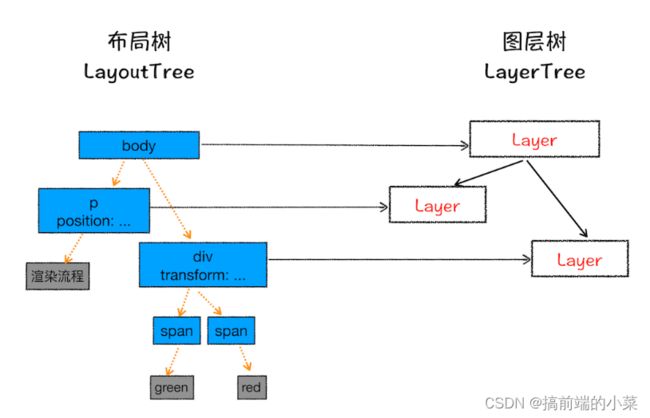
并非每个节点都具有自己的图层,只有满足以下两个条件,才会单独为节点创建自己的图层。否则就属于父节点的图层。
(1)拥有层叠上下文的元素

(2)需要裁减的地方会被创建图层
例如内容区域大于父容器,那么多出来的内容就会被单独创建图层。
最终再经过图层绘制,栅格化操作,合成与显示。渲染进程的工作就做完了(后面这三步感兴趣的话可以自行查阅资料)
(5)重绘,重排,合成
这三个概念,也是经常出现在面试中的。那如果你已经了解了渲染进程的工作原理,你就可以从这方面来解释这个问题了。
(1)重排

(2)重绘
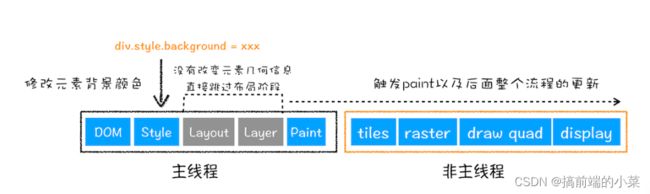
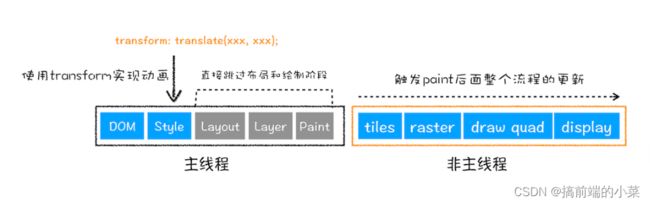
(3)合成
第四部分:JS是按顺序执行的吗?
当我们有了一段JS代码,JS是怎么执行的呢?
JS是先编译,再执行。举个例子:
showName()
var showName = function() {
console.log(2)
}
function showName() {
console.log(1)
}
showName()
看这段代码,应该输出什么呢。应该有不少人在面试中遇到过类似的问题吧。
例如上面的代码,JS要先经过编译,找到通过var,let,const,function定义的变量,将其定义好。切记,赋值操作不在这个阶段执行,上边的代码经过编译后:
var showName
function showName(){console.log(1)}
然后在执行:
showName()//输出1
showName=function(){console.log(2)}
showName()//输出2
所以会先输出1,再输出2。
第五部分:JS的调用栈
想必很多人在面试中,遇到过JS函数作用域等相关的问题吧。而这一小节,会解释JS的执行,是如何创建上下文的。
假如我有以下代码:
var a = 2
function add(b,c){
return b+c
}
function addAll(b,c){
var d = 10
result = add(b,c)
return a+result+d
}
addAll(3,6)
现在我们知道一段JS代码要先经过编译,然后再执行了。
(1)编译和执行过程
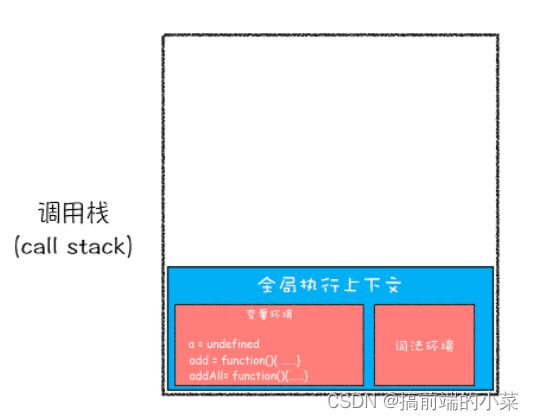
第一步:创建全局上下文,将编译后的内容压入栈底。
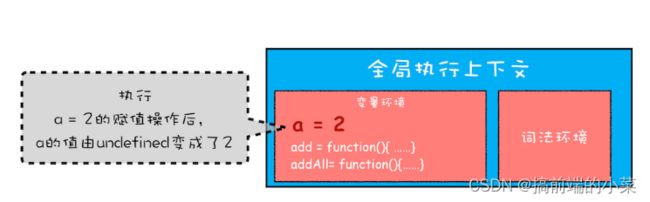
第二步:执行代码,a = 2;
第三步:调用addAll函数,编译函数里的内容,创建一个新的执行上下文,压入栈。

第四步:执行addAll函数里的代码,d=10;
第五步:调用add函数,继续编译add函数里的内容,创建一个上下文,压入栈。

第六步:执行add函数的代码,执行完后add执行上下文从栈中弹出。

第七步:返回结果给到addAll执行上下文,执行return语句。addAll上下文中代码执行完,弹出。

然后整个JS代码就执行完了,结束。
(2)常见问题
问:如何在浏览器中查看调用栈?
可以在右侧的call back中查看。也可以通过console.trace()方法查看。
问: 栈溢出是什么?
如果调用栈中的函数执行上下文过多,达到了临界值,那么就会报栈溢出的错误。可以自己写代码尝试浏览器的临界值是多少。
第六部分:let和var的区别
这个问题肯定是手到擒来了对吧,什么变量提升,不能重复定义巴拉巴拉。。
但是我们也可以从执行上下文中,来解释二者的区别。
在上面的流程图中,你会发现有一个词法环境,是没有用到过的。而它是专门针对let和const定义的变量,出现的。
例如我现在又这段代码:
function foo(){
var a = 1
let b = 2
{
let b = 3
var c = 4
let d = 5
console.log(a)
console.log(b)
}
console.log(b)
console.log(c)
console.log(d)
}
foo()
只有foo一个函数,那么这段代码经过编译后应该是:

通过var定义的变量,我们放在变量环境,通过let定义的变量,我们放在词法环境。OK,编译完成后,执行代码。
a = 1; b = 2;
执行块级作用域,继续编译:

在变量环境里加入了一个c,词法环境里加入了一个b和d。并且在词法环境中维护一个栈结构。
执行块级作用域里面的代码:

只不过上述流程是为了方便了解的。真正的块级作用域是不会被编译的,编译的过程只会存在第一次执行,所以编译时变量环境和词法环境最顶层数据已经确定了。
当执行到块级作用域时,块级作用域中,通过let和const声明的变量会被追加到词法作用域中,当这个块执行结束后,追加到词法作用域的内容会被销毁掉。
第七部分:作用域和作用域链
先来看一段代码:
function bar() {
console.log(myName)
}
function foo() {
var myName = "极客邦"
bar()
}
var myName = "极客时间"
foo()
请做出回答,这段代码的执行结果是什么。现在我们通过作用域来对它进行解释。
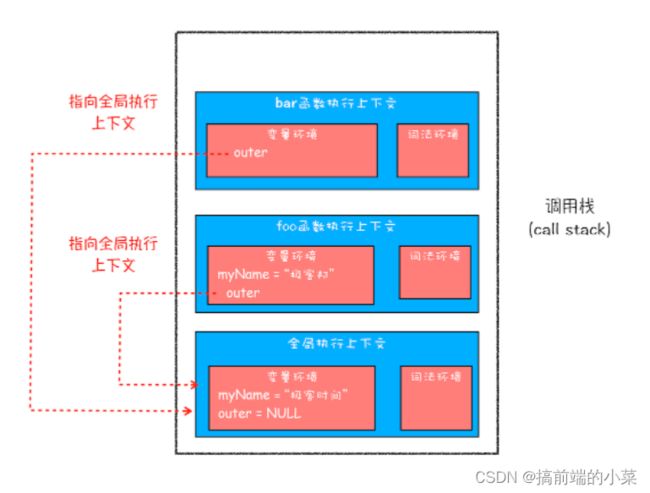
现在我们可以很清晰的写出整个执行栈了:

当在bar的执行上下文中,找不到myName的变量时。它要沿着作用域链进行查找。
而作用域链是在代码定义的时候就已经确定了的,并不是在编译时确定的。
每一个执行上下文都有一个auto指针,指向作用域链上的上一个上下文:
而作用域链,是由词法作用域来决定的。词法作用域是一个静态作用域,由代码位置来确定:

闭包的情况
来看一段代码:
function foo() {
var myName = "极客时间"
let test1 = 1
const test2 = 2
var innerBar = {
getName:function(){
console.log(test1)
return myName
},
setName:function(newName){
myName = newName
}
}
return innerBar
}
var bar = foo()
bar.setName("极客邦")
bar.getName()
console.log(bar.getName())
在看后面的内容前,可以先试着写出打印结果。
现在我们一步步来分析,整个过程。
(1)首先是创建全局执行上下文,并且创建foo函数的执行上下文:
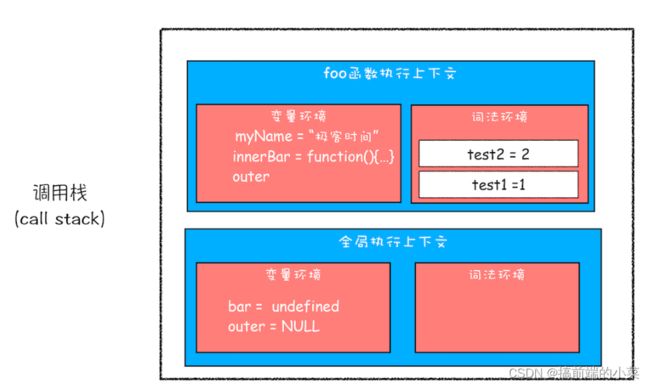
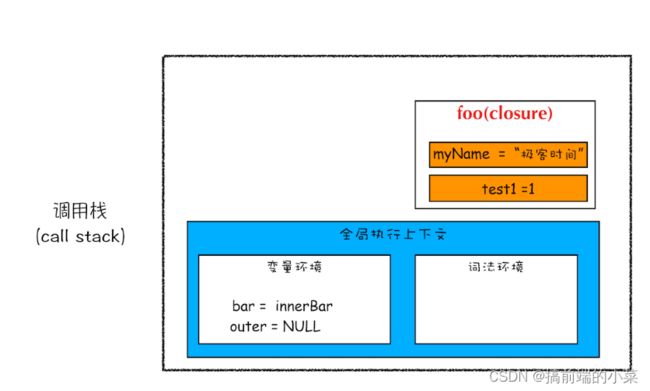
(2)编译结束后,执行foo函数,将innerBar赋值给bar。等foo函数执行完后,会从调用栈中弹出,但是因为innerBar中访问了foo函数中的变量。
所以即便foo函数弹出了,但是getName和setName依旧可以访问myName和test1。
所以我们来给闭包一个专属的定义:
在 JavaScript 中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。比如外部函数是 foo,那么这些变量的集合就称为 foo 函数的闭包。
第八部分:垃圾回收机制
又是一个面试中比较常见的问题:
首先,我们知道,在JS中,变量的内存是保存在调用栈中。而对象的内存是保存在堆内存中。
如果你不了解堆内存和栈内存,可以先看一下相关文章。
例如我又这样一段代码:
function foo(){
var a = 1
var b = {name:"极客邦"}
function showName(){
var c = 2
var d = {name:"极客时间"}
}
showName()
}
foo()
调用栈和堆内存的空间状态如图所示:
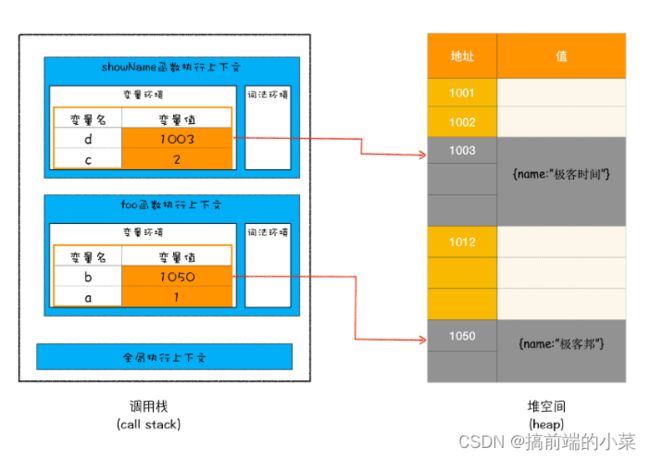
当showName函数执行完后,栈中的上下文会一个个弹出,但是堆内存的数据还没有清理。所以我们说的垃圾回收机制,主要针对的是堆内存中的数据。
(1)代际假说
代际假说有两个特点:
- 大部分对象在内存中存在的时间都很短
- 不死的对象会活很久
基于这个特点,V8将内存分为了两种。新生代内存和老生代内存。针对于这两部分,V8用不同的机制去实现垃圾回收。
- 副垃圾回收器:负责回收新生代的内存
- 主垃圾回收器:负责回收老生代的内存
(2)副垃圾回收器
在新生代内存中,主要使用Scavenge算法来处理。所谓Scavenge算法,就是将新生代的内存分为两部分,一部分是对象区域,一部分是空闲区域。
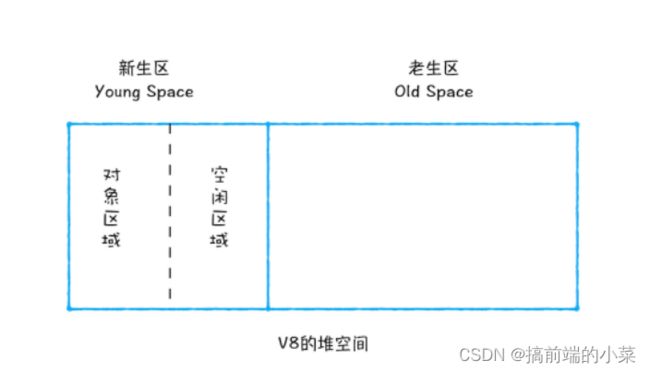
每次新加入对象后,都会在对象区域添加。等对象区域满了,就要执行一次垃圾回收操作。
将对象区域中的所有内存打上标记,标记完成后,会将存活的对象复制到空闲区域,同时还会把这些对象有序的排列起来,所以复制的过程,也是对内存整理的过程。
然后对象区域和空闲区域进行互换,等新的对象区域又满了,再次执行垃圾回收操作。
注意:V8还有一个策略是,经过两次垃圾回收,依然存活在对象区域的话,会被移动到老生区域中。
(3)主垃圾回收器
主垃圾回收器,主要是通过标记-清除的方式进行垃圾回收。
标记阶段
通过遍历调用栈,如果有对内存的引用,就会标记为活动对象,如果没有就会标记为垃圾数据。
清除阶段
将垃圾数据的内存进行清除

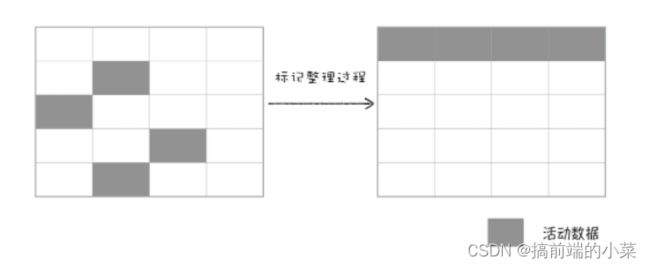
不过对一个区域进行标记清除算法之后,会产生大量的不连续的碎片。由于不连续会导致大对象不能分配到连续的内存,于是产生了另一种算法,标记-整理。
标记的方式还是一样,只不过是将所有存活的对象,同时向一段移动。移动完后,会将所有边界外的数据清除。
全停顿
由于JS是在主线程上执行,一旦执行垃圾回收算法,那么主线程的JS就要停止,等垃圾回收完再继续执行,这种情况叫全停顿。
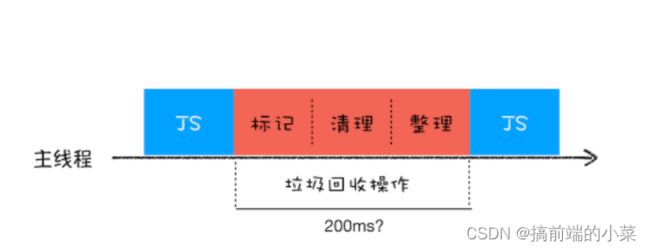
为了降低老生代垃圾回收而造成的卡顿,V8引擎将标记的过程分为一个个子过程,同时让垃圾回收的操作和JS交替运行,直到标记阶段结束,我们把这个算法称为增量-标记。
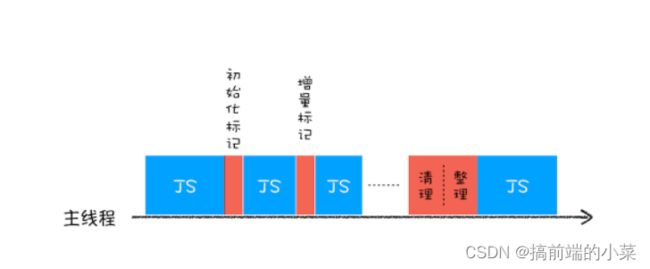
第九部分:事件循环
事件循环也是在面试中比较常见的问题了。
而JS的事件循环,是通过浏览器的消息队来实现的:
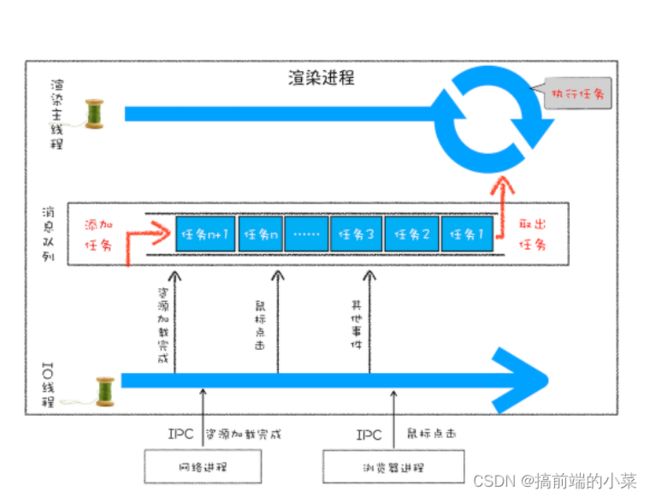
- 渲染进程:用来解析JS代码
- 消息队列:用来存放宏任务列表
- IO线程:用来和其他线程进行通信
每个宏任务都有一个微任务队列,用来存放微任务。当宏任务里的代码全部执行完毕后, 才会执行微任务队列里面的微任务。
现在我用一段代码来描述:
console.log(123)
setTimeout(() => {
console.log('time');
new Promise((resolve,reject) =>{resolve()}).then(() => {
console.log(123);
})
}, 0);
new Promise((resolve,reject) =>{resolve()}).then(() => {
console.log(123);
})
console.log(789);
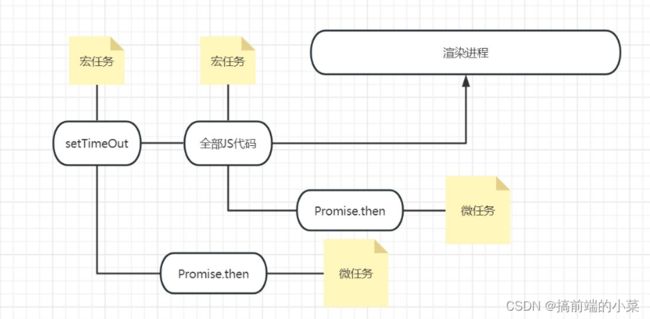
- 执行代码,给JS整体代码创建宏任务H1。
- 执行宏任务H1,打印123
- 碰到setTimeout,创建宏任务H2,继续执行代码
- 碰到Promise.then,在宏任务H1中创建微任务队列W1,并将Promise.then放在队列里
- 继续执行代码,输出789
- 宏任务H1代码执行完了,开始执行微任务队列W1里的代码,输出123
- 宏任务H1里的微任务队列执行完,开始执行宏任务H2
- 输出time,碰到Promise.then,给宏任务H2添加微任务队列W2
- 执行W2里的代码,输出123
OK,这样这段代码的事件循环就描述清楚了。
第十部分:await和async
上面说了事件循环,但是我们知道,在JS中,异步相关的还有await和async。
在解释await和async之前,我们先来说一下Generator和协程的概念。
看下面的代码:
如果你不了解Generator,可以先看一下相关的概念。
function* genDemo() {
console.log("开始执行第一段")
yield 'generator 2'
console.log("开始执行第二段")
yield 'generator 2'
console.log("开始执行第三段")
yield 'generator 2'
console.log("执行结束")
return 'generator 2'
}
console.log('main 0')
let gen = genDemo()
console.log(gen.next().value)
console.log('main 1')
console.log(gen.next().value)
console.log('main 2')
console.log(gen.next().value)
console.log('main 3')
console.log(gen.next().value)
console.log('main 4')
在渲染进程中,有一个主线程用来执行代码,消息队列用来存放宏任务,IO线程用来处理接受外部的事件。
协程的概念就是,在主线程中开辟另一条路来执行。
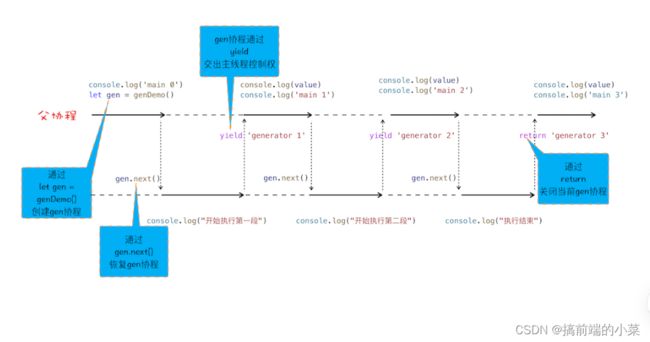
而上面的代码执行起来就是:
- let gen = genDemo(): 开辟一个协程
- gen.next():将执行的主动权交给gen协程
- yield:将执行的主动权还给主线程
- rerturn:关闭协程
OK。如果了解了Generator,那我们就来看一下await是什么情况:
async function foo() {
console.log(1)
let a = await 100
console.log(a)
console.log(2)
}
console.log(0)
foo()
console.log(3)
对于这段代码来说:
- 执行foo函数,开辟foo协程
- 执行到await 100,此时await会创建一个promise对象
- 将promise对象交给主线程,主线程通过Promise.then()来监听foo协程的变化,其实就是创建了一个微任务队列,用来存放foo协程里面剩下的内容。
- 执行主线程的代码,执行完后,执行微任务队列里面的内容
第十一部分:JS是如何影响DOM树的构建
(1)DOM树是如何构建的
- 网络进程收到响应,判断content-type是否为text/html,如果是
- 创建一个渲染进程,和网络进程建立管道
- 网络进程将请求的内容,通过管道输送给渲染进程
在渲染进程中,有一个HTML解析器,是专门用来解析文档的,解析的过程如下:

通过分词器将字节流转换为Token
Token分为Tag Token(对应的是div,span等) 和Text Token(对应的是文本节点)。
Tag Token又分为StartTag(对应的是标签开头)和EndTag(对应的是标签末尾)。

计算节点的父子关系
将HTML转为对应的Token之后,就要摸清Token和Token之间的关系了。
在HTML解析器中,维护了一个Token栈结构,这个栈主要是为了计算节点与节点之间的对应父子关系。第一阶段生成的Token会按顺序压入栈中。
- 如果压入栈中的是StateTag,HTML解析器就会为该Token创建一个DOM节点,将该节点插入到DOM树中。而该节点的父节点,就是该Token相邻的Token对应的DOM节点。
- 如果是TextToken,就不会将该Token压入栈中,而是直接生成一个文本节点插入到DOM树中,对应的父节点就是栈顶元素。
- 如果压入的是EndTag,那么就会查看栈顶元素是否为StartTag,如果是,就将栈顶元素弹出,表示该Token已经解析完毕。
(2)JS是如何影响DOM生成的
我们拿代码来举例子:
JS脚本
<html>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang'
</script>
<div>test</div>
</body>
</html>
对于这段代码,当HTML解析器碰到script标签之后,HTML解析器会暂停工作。因为JS的执行可能会影响DOM。所以要等JS执行完之后,再进行解析。
动态引入
<html>
<body>
<div>1</div>
<script type="text/javascript" src='foo.js'></script>
<div>test</div>
</body>
</html>
通过src方式的引入,HTML解析器依旧会暂停工作,不过在执行JS代码之前,要先对JS的文件进行下载,而JS的下载是非常耗时的。
所以谷歌浏览器在这方面做了优化,叫做预解析操作。渲染进程会分析HTML中的JS和CSS文件,然后提前去下载它们。
所以如果不是修改DOM操作的JS脚本,可以通过defer属性或者async属性来让脚本异步执行。
二者的区别在于:
- async脚本在加载完毕后立即执行,而defer脚本会在DOMContentLoaded事件之前执行
- defer标记的脚本需要按顺序执行,async是加载完就执行
(3)CSS阻塞
<html>
<head>
<style src='theme.css'></style>
</head>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang' //需要DOM
div1.style.color = 'red' //需要CSSOM
</script>
<div>test</div>
</body>
</html>
正常来讲,页面的渲染,应该是先构建DOM树,在进行样式计算。
但是如果我们在JS中修改了DOM的样式,这个时候就要先解析对应节点的CSS样式,如果是外部引入,那么就要先下载。
所以:
CSS不会阻塞DOM的生成,但是会阻塞JS的执行,从而影响DOM树的构建
OK,课程后面还有一些内容,写不动了,不写了,就写到这里吧。