Facenet实现人脸特征比对-深度学习学习笔记-2
前言
本文是我的学习笔记,基于人工智能领域大佬Bubbliiiing聪明的人脸识别3——Pytorch 搭建自己的Facenet人脸识别平台
原文链接:https://blog.csdn.net/weixin_44791964/article/details/108220265
记录我复现与拓展的学习过程,万分感谢大佬的开源和无私奉献。本文部分内容来自网上搜集与个人实践。如果任何信息存在错误,欢迎读者批评指正。本文仅用于学习交流,不用作任何商业用途。
Retinaface实现人脸检测与关键点定位-深度学习学习笔记-1
Facenet实现人脸特征比对-深度学习学习笔记-2
RetinaFace人脸检测模型-Gradio界面设计
FaceNet人脸识别模型-Gradio界面设计
Retinaface+FaceNet人脸识别系统-Gradio界面设计
文章目录
- 前言
- 需求分析
- 技术选取
- 数据集选取
- 什么是Facenet
- Facenet的实现思路
-
- 主干网络介绍
- 主干网络选取
- 根据初步特征继续处理
- 训练部分
-
- 训练数据集介绍
- LOSS组成
需求分析
- 人脸特征比对:人脸特征比对就是通过计算和比较人脸的特点来判断两张脸是否是同一个人。我们会将每个人脸转化为一串数字,然后比较这些数字之间的相似程度。如果数字非常接近,那么我们可以认为是同一个人;如果数字差别很大,那么可能不是同一个人。这种方法可以用于识别人脸、验证身份等场景,帮助我们更准确地辨认人的身份。
- 深度学习:深度学习是一种机器学习方法,其核心是构建和训练具有多个神经网络层的模型,以从大量数据中提取复杂的特征表示。深度学习在计算机视觉、自然语言处理等领域取得了很大的成功。
技术选取
- PyTorch:PyTorch是一个开源的深度学习框架,它提供了丰富的工具和函数来简化神经网络模型的构建和训练过程。
- Facenet是一种面向人脸识别的深度学习算法,原创论文发表于2015年CVPR,其核心思想是通过CNN网络将人脸图像映射到欧式空间中的向量表示,使得同一人不同脸的向量距离近,不同人脸的向量距离远。
数据集选取
LFW全称为Labeled Faces in the Wild,意为“非约束环境下的人脸图像数据集”。这是一个面向人脸识别研究而构建的数据库。
LFW数据集的一些关键特征:
- 包含超过13,000张面部图像,对应超过5,000个不同的人物身份。
- 图片中人脸角度、光照、表情、场景均存在变化,模拟实际应用中图像的复杂性。
- 提供的人脸图片是非约束的,即不要求正面朝摄像头等强制性要求。
- 图片来源多样,包括网络搜索引擎,新闻图片等。
- 每张人脸图片都经过了检测和校准,眼睛坐标已经标注。
- 提供定量的评测基准,可以 用来评测不同的人脸识别算法的性能。
LFW数据集包含训练、验证和测试三个子集。算法在测试集上进行评估。LFW的出现大大推动了人脸识别技术的发展。很多最先进的人脸识别算法都会在LFW数据集上测评其性能。
Facenet论文也是在LFW的标准测试集上报告了99.63%的识别准确率,超过了当时其他算法。
什么是Facenet
Facenet是谷歌在2015年发表在CVPR上的一种人脸识别算法。其基本思路是:

使用Facenet进行人脸识别的流程:
- 输入一张人脸图片
- 通过(Deep Architecture就是传统的CNN)卷积神经网络提取该图片的特征向量(Embedding)
- 对特征向量进行L2标准化
- 得到一个长度固定为128的特征向量
- 计算特征向量与存储的人脸特征向量的距离
- 判断距离是否小于阈值来识别人脸
简单来说,Facenet将人脸识别问题转化为了计算特征向量之间距离的问题。它利用了人脸在视角、表情变化下特征向量仍保持稳定这一先验知识进行训练,使得同一人脸的特征向量距离很近,不同人脸很远,从而实现了高效的人脸识别。
卷积神经网络(Convolutional Neural Network, CNN) - 一种模拟视觉神经网络结构的人工神经网络,利用卷积运算提取图像的特征信息,再通过全连接层进行分类。由卷积层和池化层堆叠构成,能够自动学习识别图像的特征。在图像识别任务上效果显著。
特征向量(Embedding) - 用卷积神经网络提取出的图像特征的向量表示,长度固定,包含了输入图像的高级语义信息。Facenet使用CNN将人脸图片映射到128维的特征向量上,这个固定长度的向量即为Embedding。
Triplet Loss - Facenet中的损失函数,目标是最小化同一人脸的特征向量距离,而最大化不同人脸的特征距离。这样可以将同一人的人脸聚集,不同人脸分割开来,利于识别。
LFW数据集 - 人脸识别领域公开的一个标准数据集,包含超过13000张面部图片,有汽人脸识别算法会在这个数据集上评测其性能。
L2标准化 - 对向量进行标准化处理,使其长度为1。这有利于不同向量之间计算距离,消除量纲影响。
阈值 - 如果两个人脸向量距离小于设定的阈值,则判断为同一人,大于阈值则判断为不同人。合理设定阈值对提高识别准确率很关键。
Facenet的实现思路
主干网络介绍
facenet的主干网络起到提取特征的作用,facenet可以用mobilenetv1或Inception-ResNetV1为主干特征提取网络,二者都起到特征提取的作用.
Keras API documentation
- MobileNetV1:
MobileNetV1是Google在2017年提出的一个轻量级卷积神经网络,用于移动和嵌入式视觉应用场景。其显著特点是使用了深度可分离卷积来构建整个网络架构。
深度可分离卷积将标准卷积分为两个更简单的部分:
- 深度可分离卷积:使用多个过滤器来Capture通道相关的信息。
- 点卷积(1x1卷积):来Capture跨通道信息。
比如,一个标准的3x3卷积会被替换为一个3x3的深度可分离卷积和一个1x1的点卷积。这种设计大大减少了参数量和计算量。
整个MobileNetV1网络由深度可分离卷积模块堆叠构成,主要有以下特点: - 网络基本结构模块是深度可分离卷积后接1x1点卷积。
- 网络中有均是3x3的深度可分离卷积,不使用任何较大卷积核。
- 1x1点卷积主要起到通道调节作用,同时整合信息。
- 后半部分引入了2种不同的模块,进一步提高效率。
- 整个网络只有4.2 million个参数,计算量只有标准CNN的1/30左右, thus非常适合移动端。
综上,MobileNetV1成功地利用深度可分离卷积来构建轻量级的CNN模型,使其可以在移动和嵌入式设备上高效运行,同时保持了良好的识别精度。
- Inception-ResNetV1:
Inception-ResNetV1是Google在2016年提出的一个卷积神经网络模型,它结合了Inception网络和残差网络(ResNet)的优点。
Inception模块的主要contribution是在同一层中使用不同大小的卷积核捕捉信息的多尺度特性。例如一个Inception模块可以同时包含1x1,3x3,5x5的卷积。
ResNet的主要contribution是引入了残差连接,解决了网络加深时的梯度消失问题。利用残差连接,模型可以顺畅训练数百个乃至上千个层。
Inception-ResNetV1模型融合了两者的设计理念:
- 在Inception模块中,同一层包含不同卷积核大小的分支路径,增加网络对多尺度信息的学习能力。
- 在Inception模块之间加入残差连接,增强信息传播和梯度反传,使得网络可以很深。
- 为了降低计算量,Inception模块中大部分使用了1x1卷积来减少通道数。
- 整个网络包含约50层的Inception-ResNet模块堆叠。加入了BatchNormalization、Dropout等正则手段。
主干网络选取
我们主要使用MobilenetV1作为主干网络,设计的一个轻量级的深层神经网络模型。它的核心思想是使用depthwise separable convolution(深度可分离卷积)来减少模型参数量和计算量。
我们先了解一些基本概念:
-
卷积:
-
卷积是一种数学运算,用于将一个函数与另一个函数进行操作,以产生一个新的函数。在图像处理中,我们可以把卷积看作是一种滤波操作。它通过在图像上滑动一个小的窗口(称为卷积核),对窗口内的像素进行加权求和,从而得到新的像素值。
-
新像素 = 卷积核中的权重 * 窗口内像素的加权平均值
-
我们可以把卷积想象成用一个小小的滤网去过滤咖啡。
比如我们有一张5x5的图片,每一个小格子是一个像素点,用数字1到5表示它的颜色:
1 1 2 3 4
2 2 3 4 5
3 3 3 4 5
4 4 4 5 5
5 5 5 5 5
现在我们定义一个3x3的滤波器,就是一个3行3列的小矩阵:
0 1 0
1 0 1
0 1 0
我们把这个滤波器放在图片上,让它从左到右、从上到下滑动,每次停在一个位置。
当它停在最上面最左边时,会覆盖图片中的:
1 1 2
2 2 3
3 3 3
对应元素相乘就是:
(1 x 0) (1 x 1) (2 x 0)
(2 x 1) (2 x 0) (3 x 1)
(3 x 0) (3 x 1) (3 x 0)
然后我们把滤波器中的数字与覆盖的图片中对应的数字分别相乘,再把 9 个乘积加起来,就可以得到一个新的数字,比如这里是18。
18就会成为输出图片中对应位置的新的像素值。
我们让滤波器继续在图片上滑动,每次输出一个乘积求和的结果,最终就可以得到一个新的图片,它保留了原图片在这个滤波器下的特征。
如果我们改变滤波器的数字的安排组合,就可以得到不同的特征。
这个过程,就像我们用不同的滤网去过滤咖啡,不同的滤网会提取咖啡中的不同成分。
所以卷积核其实就是一个提取图像特征的滤波器,经过卷积操作,可以得到代表不同特征的图像。这一技术在图像处理和机器学习中很重要,比如可以用来进行图像识别等任务。
-
-
卷积层:
- 卷积层就像是神经网络中的一个特殊工人,负责从输入数据中提取有用的信息。它可以看作是一个滑动窗口,不停地在输入数据上移动。每次移动,它会与当前窗口内的数据进行一种特殊的计算,这个计算方式就叫做卷积。通过卷积,卷积层可以捕捉到输入数据中的不同特征,比如边缘、纹理等。卷积层可以有多个窗口,每个窗口可以提取不同的特征。卷积层的输出结果就是一组特征图,它们包含了输入数据中不同特征的信息。
-
卷积核:
- 卷积核就像是卷积层的工具箱,它是卷积层中的一个小矩阵。每个卷积核都有一组权重参数,这些参数决定了卷积核如何与输入数据进行计算。卷积核的大小和形状是由设计者事先确定的。
- 通过与输入数据进行卷积操作,卷积核可以突出输入数据中的不同特征。卷积核的参数是可以学习的,通过神经网络的训练过程,它们会自动调整以提取最有用的特征。
-
卷积层和卷积核之间的关系:卷积层包含了多个卷积核。每个卷积核可以提取不同的特征。卷积层通过并行地使用多个卷积核,可以同时提取多个特征。每个卷积核在卷积层中滑动并与输入数据进行卷积操作,生成对应的特征图。这些特征图可以被传递给神经网络的下一层进行进一步的处理和分析。
-
总结起来
- 卷积是一种数学运算,用于将一个函数与另一个函数进行操作,以产生一个新的函数。在图像处理和深度学习中,卷积是指将一个卷积核与输入数据进行操作,以生成输出特征图。
- 卷积层是神经网络中的一种基本层级结构,用于处理图像、语音和其他类型的数据。它由多个卷积核组成,每个卷积核都会对输入数据进行卷积操作,并生成一个对应的输出特征图。卷积层在神经网络中起到了提取特征的重要作用。
- 卷积核是卷积层中的一个小矩阵,它的大小和形状由设计者事先确定。每个卷积核都包含一组权重参数,这些参数在训练过程中会被优化。每个卷积核通过与输入数据进行卷积操作,可以提取出不同的特征。卷积核实际上是神经网络中的一种学习到的参数,它的作用是通过与输入数据进行卷积操作,从输入数据中提取出有用的特征。每个卷积核可以捕捉到不同的特征,比如边缘、纹理、形状等。卷积层中的每个卷积核都可以学习到不同的特征,从而帮助神经网络理解和处理复杂的数据。
- 卷积是一种数学运算,卷积层是神经网络中的一种基本层级结构,而卷积核是卷积层中用于对输入数据进行卷积操作的小矩阵。它们共同作用于神经网络中,帮助网络理解和处理复杂的数据。
-
特征图(featuremap)
- 是指卷积操作的输出结果。在卷积层中,每个卷积核都会生成一个特征图,它包含了从输入数据中提取的特征信息。特征图可以传递给神经网络的下一层进行进一步的处理和分析
-
通道:
- 通道对应着特征图的深度维度,每一通道都是一张2D特征图。
- 例如,RGB图像有3个通道,那么它可以看作是由3张2D特征图堆叠起来的。而在模型中,不同的通道可以检测图像的不同属性,卷积层输出的通道数由输出通道数决定。
-
步长:
- 步长用来控制卷积核在输入特征图上滑动的步进,它决定着输出特征图相对于输入特征图的缩小程度。
- 步长越大,输出特征图相对输入特征图的缩小程度越大,特征的提取会更加粗糙。步长为2时,输出特征图的大小会减半。
-
深度可分离卷积(depthwise separable convolution)
- 深度可分离卷积是一种卷积操作的变种。它将卷积操作分为两个步骤:深度卷积和融合操作。
- 深度卷积是指使用一个小的卷积核(比如3×3)分别遍历输入数据的每个通道,得到多个特征图谱。
- 融合操作是指使用一个1×1大小的卷积核将这些特征图谱融合在一起,生成最终的输出特征图。通过这种方式,深度可分离卷积可以减少模型的参数量,提高计算效率。
假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
应用深度可分离卷积,用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱,所需参数为16×3×3+16×32×1×1=656个。
可以看出来depthwise separable convolution可以减少模型的参数。
-
通俗来说
- 我们可以把一张图片看成是多层薄薄的玻璃板叠在一起。每层玻璃板显示图片的一个特定特征,比如颜色、边缘等。这些玻璃板就可以看成是图片的通道。我们做一个比喻:
输入图片 -> 多层玻璃板
图片通道 -> 每层玻璃板
普通卷积核 -> 小刷子
- 我们可以把一张图片看成是多层薄薄的玻璃板叠在一起。每层玻璃板显示图片的一个特定特征,比如颜色、边缘等。这些玻璃板就可以看成是图片的通道。我们做一个比喻:
-
普通的卷积操作中,我们的输入图片有 16 个通道(可以看成 16 层玻璃板),我们希望卷积层输出 32 个通道(特征图)。
- 普通的卷积操作每个输出通道需要一个对应的卷积核来生成, 所以需要准备 32 个卷积核,即 32 个小刷子
- 就像用32个小刷子来刷这张图片。 每个小刷子要刷过输入图片的全部 16 个层,才能输出 32 个通道,捕捉所有特征,得到对应的输出,参数数量非常大,需要16×32×3×3=4608个。
-
而深度可分离卷积则是分两步刷:
- 第一步,用16个刷子分别刷每一层玻璃板,每个刷子只刷一层输入通道。
- 第一步参数量为:输入通道数*刷子大小 = 16×3×3
- 第二步,再用32个刷子只刷第一步刷过的结果,32个小刷子作用在第一步产生的16个结果通道上,不会再操作原始的16个输入通道。
- 第二步参数量:第一步输出通道数输出通道数刷子大小 = 16×3×3+16×32×1×1=656个。
-
这样参数数量只需要16×3×3+16×32×1×1=656个。大约减少到原来的1/7。
所以深度可分离卷积通过分解步骤,显著减少了参数量。这使得模型更加轻量化,也降低了计算量。
希望这个通俗的刷玻璃板比喻可以让你更直观地理解卷积通道和深度可分离卷积的工作原理。
如下这张图就是depthwise separable convolution的结构
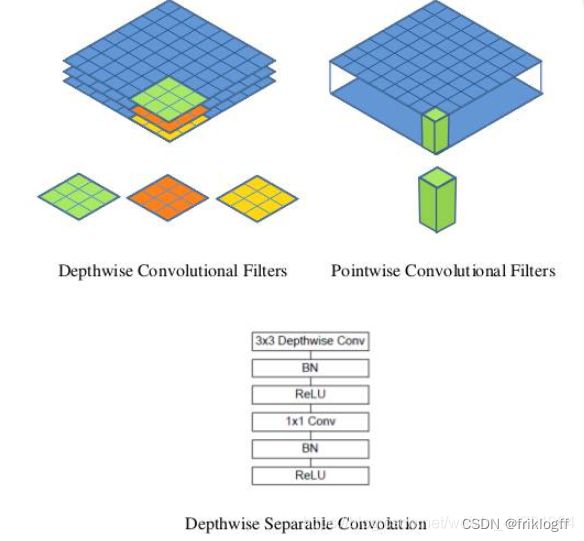
在建立模型的时候,可以将卷积group设置成in_filters层实现深度可分离卷积,然后再利用1x1卷积调整channels数。
通俗地理解就是3x3的卷积核厚度只有一层,然后在输入张量上一层一层地滑动,每一次卷积完生成一个输出通道,当卷积完成后,在利用1x1的卷积调整厚度。
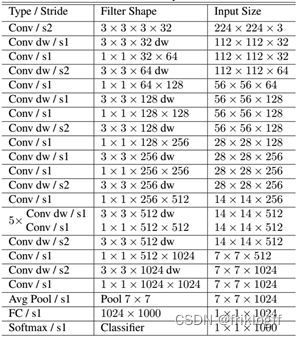
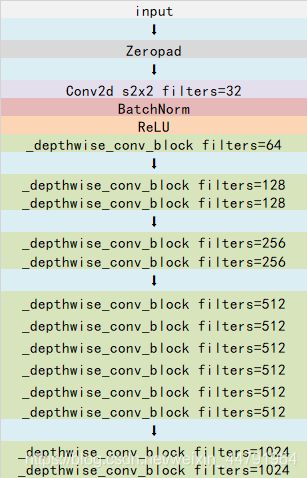
如下就是MobileNet的结构,其中Conv dw就是分层卷积,在其之后都会接一个1x1的卷积进行通道处理,
# nets/mobilenet.py
import torch.nn as nn
def conv_bn(inp, oup, stride=1):
'''
卷积块,组合卷积层、BN层、激活函数
参数:
inp:输入通道数
oup:输出通道数
stride:卷积层步长
返回:Sequential块
'''
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
# 3x3卷积,输入通道inp,输出通道oup,调整通道数
nn.BatchNorm2d(oup),
# BN层,针对oup通道标准化
nn.ReLU6()
# ReLU6激活函数
)
def conv_dw(inp, oup, stride=1):
'''
深度可分离卷积块
参数:
inp:输入通道数
oup:输出通道数
stride:步长
返回:Sequential块
'''
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
# 3x3深度可分离卷积,分组数等于inp,即split通道,通道不变
nn.BatchNorm2d(inp),
nn.ReLU6(),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
# 1x1点卷积,调整通道数为oup
nn.BatchNorm2d(oup),
nn.ReLU6(),
)
class MobileNetV1(nn.Module):
def __init__(self):
super(MobileNetV1, self).__init__()
self.stage1 = nn.Sequential(
# 160x160x3 -> 80x80x32
conv_bn(3, 32, 2),
# 第1层卷积,步长2,图像尺寸减半
# 80x80x32 -> 80x80x64
conv_dw(32, 64, 1),
# 80x80x64 -> 40x40x128
conv_dw(64, 128, 2), # 步长2,尺寸减半
conv_dw(128, 128, 1),
# 40x40x128 -> 20x20x256
conv_dw(128, 256, 2), # 步长2,尺寸减半
conv_dw(256, 256, 1),
)
self.stage2 = nn.Sequential(
# 20x20x256 -> 10x10x512
conv_dw(256, 512, 2), # 步长2,尺寸减半
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
)
self.stage3 = nn.Sequential(
# 10x10x512 -> 5x5x1024
conv_dw(512, 1024, 2), # 步长2,尺寸减半
conv_dw(1024, 1024, 1),
)
self.avg = nn.AdaptiveAvgPool2d((1, 1)) # 1x1全局池化
self.fc = nn.Linear(1024, 1000) # 分类全连接层,1000类
def forward(self, x):
x = self.stage1(x)
# stage1模块
x = self.stage2(x)
# stage2模块
x = self.stage3(x)
# stage3模块
x = self.avg(x)
# 平均池化
x = x.view(-1, 1024)
# 平铺,用于全连接层输入
x = self.fc(x)
# 全连接层
return x
代码实现了MobileNetV1模型的定义和前向传播过程。
这段代码的主要功能是将输入图像通过多个阶段的深度可分离卷积块逐渐降低为更小的特征图尺寸,然后通过全局平均池化层进行空间降维,最后使用全连接层进行分类预测。这样的设计使得模型能够有效地提取图像特征,并在保持较小模型尺寸的同时实现准确的分类结果。
根据初步特征继续处理
利用主干特征提取网络我们可以获得一个特征层,它的shape为(batch_size, h, w, channels),我们可以将其取全局平均池化,方便后续的处理(batch_size, channels)。
我们可以
- 利用backbone网络从输入图像中提取初步特征。
- 通过全连接层Bottleneck将初步特征降维到128维。
- 对128维特征进行L2标准化处理,获得规范化的特征向量。
- 最后在训练模式下,在特征向量基础上构建分类器。
class Facenet(nn.Module):
def __init__(self, backbone="mobilenet", dropout_keep_prob=0.5, embedding_size=128, num_classes=None, mode="train"):
super(Facenet, self).__init__()
# 根据选择的backbone网络初始化模型
if backbone == "mobilenet":
self.backbone = mobilenet()
flat_shape = 1024
elif backbone == "inception_resnetv1":
self.backbone = inception_resnet()
flat_shape = 1792
else:
raise ValueError('Unsupported backbone - `{}`, Use mobilenet, inception_resnetv1.'.format(backbone))
# 自适应平均池化层,将特征图转换为大小为1x1的全局特征
self.avg = nn.AdaptiveAvgPool2d((1,1))
# Dropout层,用于随机丢弃特征向量中的部分元素以减少过拟合风险
self.Dropout = nn.Dropout(1 - dropout_keep_prob)
# Bottleneck线性层,将特征映射到长度为embedding_size的特征空间
self.Bottleneck = nn.Linear(flat_shape, embedding_size,bias=False)
# BatchNorm1d层,对特征向量进行归一化处理
self.last_bn = nn.BatchNorm1d(embedding_size, eps=0.001, momentum=0.1, affine=True)
# 在训练模式下创建分类器线性层,用于具体的人脸分类任务
if mode == "train":
self.classifier = nn.Linear(embedding_size, num_classes)
def forward(self, x):
# 数据在backbone网络中前向传播得到特征图
x = self.backbone(x)
# 自适应平均池化将特征图转换为大小为1x1的全局特征
x = self.avg(x)
# 将特征图展平成一维向量
x = x.view(x.size(0), -1)
# Dropout层对特征向量进行随机丢弃以减少过拟合风险
x = self.Dropout(x)
# Bottleneck线性层将特征映射到长度为embedding_size的特征空间
x = self.Bottleneck(x)
# BatchNorm1d层对特征向量进行归一化处理
x = self.last_bn(x)
# L2标准化使特征向量具有单位长度
x = F.normalize(x, p=2, dim=1)
return x
def forward_feature(self, x):
# 数据在backbone网络中前向传播得到特征图
x = self.backbone(x)
# 自适应平均池化将特征图转换为大小为1x1的全局特征
x = self.avg(x)
# 将特征图展平成一维向量
x = x.view(x.size(0), -1)
# Dropout层对特征向量进行随机丢弃以减少过拟合风险
x = self.Dropout(x)
# Bottleneck线性层将特征映射到长度为embedding_size的特征空间
x = self.Bottleneck(x)
# BatchNorm1d层对特征向量进行归一化处理,并返回未标准化前的结果
before_normalize = self.last_bn(x)
# L2标准化使特征向量具有单位长度
x = F.normalize(before_normalize, p=2, dim=1)
return before_normalize, x
def forward_classifier(self, x):
# 输入特征向量经过分类器线性层进行分类预测
x = self.classifier(x)
return x
这段代码承接了nets/mobilenet.py的输出,并对其进行处理。
- 首先根据初步特征图提取长度为128的特征向量
-
输入数据经过backbone网络(如MobileNetV1或Inception-ResNetv1)进行特征提取。这些backbone网络被设计用于从输入图像中学习有意义的高级特征表示。
-
经过backbone网络后,得到一个包含空间信息的特征图。接下来,应用自适应平均池化层(avg)将特征图转换为大小为1x1的全局特征。
-
将全局特征展平成一维向量,以便进一步处理。然后,通过Dropout层对特征向量进行随机丢弃,以减少过拟合风险。
-
特征向量通过Bottleneck线性层(Bottleneck)映射到长度为128的特征空间。这个线性层可以看作是一个嵌入层,它将高维特征映射到低维度的特征向量。
-
最后,特征向量通过BatchNorm1d层(last_bn)进行归一化处理。BatchNorm1d层对特征向量的每个元素进行标准化,使其具有零均值和单位方差,从而增加模型的稳定性和泛化能力。
通过根据初步特征图提取长度为128的特征向量,我们可以获得更具有判别能力和泛化能力的人脸特征表示。这种特征表示在人脸识别、验证和分类等任务中具有重要意义,并且可以应用于各种实际场景中。
- 然后应用L2标准化处理该特征向量。
- forward_feature(self, x)方法接收从第一段代码中得到的特征图作为输入,并通过平均池化、展平和线性层将其转换为长度为128的特征向量。
- 在生成特征向量之前,使用Dropout层对特征进行随机丢弃以减少过拟合风险。
生成的特征向量通过Bottleneck层映射到长度为128的空间,并通过last_bn层进行归一化处理。 - 最后,应用L2标准化(通过调用F.normalize函数)对特征向量进行标准化。
L2标准化是一种常见的数据预处理技术,也被称为单位范数或欧几里得归一化。它的目的是将特征向量的每个元素除以该向量的L2范数,使得特征向量的模长变为1。
总而言之,应用L2标准化处理特征向量的目的是消除尺度差异、提高相似度度量以及减少冗余信息。这样做有助于改善模型的性能和鲁棒性,并为后续的人脸识别任务提供更加一致和可靠的特征表示。
- 此外,在训练模式下,还可以使用分类器进行具体的人脸分类,用于辅助Triplet Loss的收敛。
-
在训练模式下,Facenet模型中的分类器(classifier)可以用于具体的人脸分类任务,并且对辅助Triplet Loss的收敛起到重要作用。以下是详细介绍:
-
初始化方法(init):当mode参数为"train"时,在初始化过程中创建了一个额外的线性层(classifier)用于人脸分类。
-
参数num_classes表示分类任务中的类别数量。
前向传播方法(forward_classifier):该方法仅对特征向量进行分类预测。 -
输入特征向量经过分类器线性层进行分类预测。
输出结果是每个类别的得分或概率。
总结起来,在训练模式下使用分类器进行具体的人脸分类,既可以辅助Triplet Loss的收敛,提高模型的人脸特征表达能力,也可以为人脸分类任务提供准确的预测结果。这有助于改善模型的性能和鲁棒性,并且使其适用于各种实际应用场景。
训练部分
训练数据集介绍
CASIA-WebFace是一个用于人脸识别研究的大规模数据集。该数据集由中国科学院自动化研究所(CASIA)创建,并于2014年发布。
CASIA-WebFace数据集包含了来自互联网上的10,575个身份的494,414张人脸图像。这些图像涵盖了不同种族、性别和年龄段的人脸,具有较高的多样性。
每个身份在数据集中都有至少一张正面人脸图像,而某些身份可能会有多张图像。这使得CASIA-WebFace成为一个适合进行人脸识别算法研究和评估的丰富资源。
CASIA-WebFace数据集的图像分辨率较高,通常为250x250像素。此外,数据集还提供了标注信息,包括每个图像对应的身份标签。
由于CASIA-WebFace数据集的规模和多样性,它已经成为许多人脸识别算法研究的基准数据集之一。研究人员可以使用该数据集来开发和测试人脸检测、人脸对齐、特征提取和人脸识别等相关技术。
需要注意的是,CASIA-WebFace数据集仅供非商业目的使用,需要遵守相关的数据使用规定和法律法规。
总之,CASIA-WebFace是一个用于人脸识别研究的大规模数据集,包含了来自互联网上的10,575个身份的494,414张人脸图像。该数据集具有高分辨率、多样性和标注信息,适合进行人脸识别算法的开发和评估
LOSS组成
facenet使用Triplet Loss作为loss。
Triplet Loss的输入是一个三元组
a:anchor,基准图片获得的128维人脸特征向量
p:positive,与基准图片属于同一张人脸的图片获得的128维人脸特征向量
n:negative,与基准图片不属于同一张人脸的图片获得的128维人脸特征向量
我们可以将anchor和positive求欧几里得距离,并使其尽量小。
我们可以将anchor和negative求欧几里得距离,并使其尽量大。
当我们使用Facenet进行人脸识别时,我们希望模型能够学会将同一个人的不同照片特征聚集在一起,并且将不同人的特征分开。为了实现这个目标,我们使用了Triplet Loss作为损失函数。
Triplet Loss的思想是比较三张图片之间的相似性:
基准图片(anchor)、同一个人的另一张图片(positive)和不同人的图片(negative)。
我们希望基准图片与同一个人的图片之间的距离尽量小,而与不同人的图片之间的距离尽量大。
通过计算欧几里得距离来衡量图片之间的距离,然后使用公式L=max(d(a,p)−d(a,n)+margin,0)来计算损失值。
其中,d(a,p)表示基准图片与同一个人的图片之间的距离,d(a,n)表示基准图片与不同人的图片之间的距离,margin是一个常数。
我们希望让同一个人的不同状态下的特征更加接近,而不同人的特征则更加远离。通过优化这个损失函数,我们可以使模型更好地理解人脸特征,从而提高人脸识别的准确性。
但是仅使用Triplet Loss可能导致模型难以收敛,所以我们还结合了Cross-Entropy Loss来辅助训练。Cross-Entropy Loss用于人脸分类任务,帮助模型更好地区分不同的人脸。
通过综合使用这两种损失函数,可以提高模型在人脸识别中的性能和稳定性。