oracle
文章目录
- 死锁
-
- 死锁查看
- 关闭死锁
- SQL语句
-
- 操作表
- 数据类型
-
- 一.字符类型
- 二.数值类型
- 三.日期类型
- 四.大对象类型
- 查询
-
- 分页,模糊,排序查询
- 其他查询
- 函数
- 存储过程
-
- 创建存储过程
- 函数
-
- 函数的创建和使用
- 游标
-
- 定义游标
- 打开游标
- 提取数据(提取多行)
- 关闭游标
- 例子
- 触发器
-
- 创建触发器
- 触发器的条件谓语
- 查询所有的触发器
- 禁用触发器
- 启用触发器
- 创建视图
- oracle的mybatis项目
- oracle数据类型
死锁
死锁查看
Username:死锁语句所用的数据库用户;
Lockwait:死锁的状态,如果有内容表示被死锁。
Status: 状态,active表示被死锁
Machine: 死锁语句所在的机器。
Program: 产生死锁的语句主要来自哪个应用程序。
logon_time:产生死锁的日期
第一种:
select s.username,l.object_id,l.session_id,s.serial#,s.lockwait,s.status,s.machine,s.program from v s e s s i o n s , v session s,v sessions,vlocked_object l where s.sid = l.session_id;
第二种:(查询所有)
select * from v s e s s i o n s , v session s, v sessions,vlocked_object l where s.sid = l. session_id;
第三种:
select s.username,l.session_id,s.serial#,s.lockwait
from v s e s s i o n s , v session s,v sessions,vlocked_object l
where s.lockwait is not null and s.sid=l.session_id;
第四种:(用dba用户执行以下语句,可以查看到被死锁的语句)
select sql_text from v s q l w h e r e h a s h v a l u e i n ( s e l e c t s q l h a s h v a l u e f r o m v sql where hash_value in (select sql_hash_value from v sqlwherehashvaluein(selectsqlhashvaluefromvsession where sid in
(select session_id from v$locked_object));
关闭死锁
alter system kill session ‘sid,serial#’; (其中sid=l.session_id);
SQL语句
操作表
–创建一个学生信息表
create table tbl_student (
stuid number not null primary key,
stu_name varchar2(20) not null,
age number(3) not null,
sex varchar2(1) not null
)
–创建序列
create sequence seq_tbl_student start with 1002 increment by 1;
–使用序列,dual 虚表
select seq_tbl_student.nextval from dual;
select seq_tbl_student.currval from dual;
–添加check约束
alter table tbl_student add constraint check_sex check(sex=‘男’ or sex=‘女’)
–添加唯一约束
alter table tbl_student add constraint unique_name unique(stu_name);
–添加外键约束(创建表之后)
create table tbl_class ( classid number(3),class_name varchar2(20));
–创建唯一索引
create unique index index_unique_name on tbl_index(name);
create index index_city on tbl_indexx(city);
–删除索引
drop index index_city
–在已经存在的表上添加一列
alter table tbl_student add classid number(3);
alter table tbl_class add constraint pk_tbl_class primary key (classid);
alter table tbl_student add constraint fk_class foreign key(classid) references tbl_class(classid);
–修改ORACLE字段的默认排序方式, Session级别的设置:
按拼音:alter session set nls_sort = SCHINESE_PINYIN_M;
按笔画:alter session set nls_sort = SCHINESE_STROKE_M;
按偏旁:alter session set nls_sort = NLS_SORT=SCHINESE_RADICAL_M;
–数据的导入导出
导出数据库中的数据,必须首先指定导出的目录,oracle默认没有权限操作未授权的操作系统目录。
步骤一:创建目录,存放导出的数据(必须保证硬盘上的目录提前存在)
create directory dir_sz as ‘C:\app\Administrator\oradata\orcl\dump’;
步骤二:授权,给目录
grant read ,write on directory dir_sz to user_sz;
步骤三:导出数据
C:\Users\Administrator>expdp user_sz/tiger schemas=user_sz dumpfile=20200709.dump directory=dir_sz
数据库导入dump文件。
impdp user_sz/tiger schemas=user_sz dumpfile=20200709.dump directory=dir_sz
–清空表
truncate table tbl_index;
数据类型
一.字符类型
1.char
2.varchar2(4000字节)
二.数值类型
1.number
2.number(m,n) m表示精度,数字的总位数,n表示小数点后面的位数
三.日期类型
1.date(年,月,日,时,分,秒)
2.timestamp(秒值精确到小数点后6位)
四.大对象类型
1.clob 存储可变长度的字符数据,最多4GBshju
2.blob 二进制类型对象,图像,视频,声音等
查询
分页,模糊,排序查询
分页
select empnew.* from (select rownum r ,emp.* from emp ) empnew where empnew.r>0 and empnew.r<=5;
select t.* from (select rownum r,e.* from 表名 e where rownum<=pagesizepageno) t where r>pagesizepageno-pagesize
–查询出员工姓名中包含字母为’a’的员工的信息
select * from emp e where e.ename like ‘%A%’
–查询出员工姓名中第一个字母为’S’的员工的姓名(‘%S’ 最后一位)
select * from emp e where e.ename like ‘S%’
–查询出员工姓名中包含’A’和’F’的员工的信息
select * from s_emp e where e.ename like ‘%A%’ and e.ename like ‘%F%’;
–查询出员工姓名中倒数第三个字母为’i’的员工的信息
select * from emp e where e.ename like ‘%L__’
select * from emp e where e.ename like ‘__L%’
–查询出在31,41部门的所有员工
select * from emp e where e.deptno =10 or e.deptno =30;
select * from emp e where e.deptno in (10,30);
模糊
–查询出员工姓名中包含字母为’a’的员工的信息
select * from emp e where e.ename like ‘%A%’
–查询出员工姓名中第一个字母为’S’的员工的姓名(‘%S’ 最后一位)
select * from emp e where e.ename like ‘S%’
–查询出员工姓名中包含’A’和’F’的员工的信息
select * from s_emp e where e.ename like ‘%A%’ and e.ename like ‘%F%’;
–查询出员工姓名中倒数第三个字母为’i’的员工的信息
select * from emp e where e.ename like ‘%L__’
select * from emp e where e.ename like ‘__L%’
–查询出在31,41部门的所有员工
select * from emp e where e.deptno =10 or e.deptno =30;
select * from emp e where e.deptno in (10,30);
排序
–按照笔划排序
select * from emp order by nlssort(ename,‘NLS_SORT=SCHINESE_STROKE_M’);
–按照部首排序
select * from emp order by nlssort(ename,‘NLS_SORT=SCHINESE_RADICAL_M’);
–按照拼音排序 此为系统的默认排序方式
select * from emp order by nlssort(ename,‘NLS_SORT=SCHINESE_PINYIN_M’);
–降序
select * from emp e order by e.sal desc
–升序
select * from emp e order by e.sal asc
排序加分页
select * from (select rownum r,t.* from (select * from emp e order by e.sal desc) t where rownum<=10) where r>0
select * from (select rownum r,t.* from (select * from 表名 e order by e.排序的列desc) t where rownum<= pagesizepageno) where r> pagesizepageno-pagesize
模糊加分页
select rownum, t.*
from (select rownum r, e.*
from (select *
from emp e
where e.ename like ‘%A%’
and e.ename like ‘%L__’
and sal>=1000 and sal <= 5000) e
where rownum <= 5) t
where r > 0
排序加模糊加分页查询
select rownum, t.*
from (select rownum r, e.*
from (select *
from (select * from emp oe order by oe.sal desc) e
where e.ename like ‘%A%’
and sal >= 1000
and sal <= 5000) e
where rownum <= 5) t
where r > 0
其他查询
–获取当前系统时间
select sysdate from dual;
函数
1、字符串函数
字符函数接受字符参数,这些参数可以是表中的列,也可以是一个字符串表达式。
常用的字符函数:
| 函数 | 说明 | 示例 | 示例结果 |
|---|---|---|---|
| ascii(X) | 返回字符X的ASCII码 | SELECT ASCII(‘a’) FROM dual; | 97 |
| concat(X,Y) | 连接字符串X和Y | SELECT CONCAT(‘Hello’,‘world’) FROM dual; | Helloworld |
| instr(X,STR[,START][,N) | 从X中查找str,可以指定从start开始,也可以指定从n开始 | SELECT INSTR(‘Hello world’,‘or’) FROM dual; | 8 |
| length(X) | 返回X的长度 | SELECT LENGTH(‘Hello’) FROM dual; | 5 |
| lower(X) | X转换成小写 | SELECT LOWER(‘Hello’) FROM dual; | hello |
| upper(X) | X转换成大写 | SELECT UPPER(‘hello’) FROM dual; | HELLO |
| ltrim(X[,TRIM_STR]) | 把X的左边截去trim_str字符串,缺省截去空格 | SELECT LTRIM(’=Hello=’,’=’) FROM dual; | Hello= |
| rtrim(X[,TRIM_STR]) | 把X的右边截去trim_str字符串,缺省截去空格 | SELECT RTRIM(’=Hello=’,’=’) FROM dual; | =Hello |
| trim([TRIM_STR FROM]X) | 把X的两边截去trim_str字符串,缺省截去空格 | SELECT TRIM(’=‘FROM’=Hello=’) FROM dual; | Hello |
| REPLACE(X,old,new) | 在X中查找old,并替换成new | SELECT REPLACE(‘ABCDE’,‘CD’,‘AAA’)FROM dual; | ABAAAE |
| TRANSLATE(char, from, to) | 在char中把from字符逐一替换为to | SELECT TRANSLATE(‘123456789’,‘4564’,‘abcd’) FROM DUAL; | 123abc789 |
| REGEXP_REPLACE(sourceStr, patternStr[, replacedStr]) | sourceStr标识要被替换的字段名或字符串,patternStr被替换字符串所需要匹配的正则表达式,replacedStr表示要替换成的字符串。如果没有replacedStr则删除正则表达式所匹配的字符串。 | SELECT REGEXP_REPLACE(‘A9是8C7’,’[^0-9]’,‘0’) FROM dual | 090807 |
| SUBSTR(X,start[,length]) | 返回X的字串,从start处开始,截取length个字符,缺省length,默认到结尾 | SELECT SUBSTR(‘ABCDE’,2,3) FROM dual; | BCD |
| INITCAP(char) | 把每个字符串的第一个字符换成大写 | SELECT INITCAP(‘mr.ecop’) FROM dual; | Mr.Ecop |
| WM_CONCAT(列名) | 把列值以“,”分隔开,显示为字符串 | SELECT WM_CONCAT(NAME) NAME FROM TEST; | a,b,c,d,e |
2、数字函数
数字函数接受数字参数,参数可以来自表中的一列,也可以是一个数字表达式。
| 函数 | 说明 | 示例 |
|---|---|---|
| abs(X) | X的绝对值 | ABS(-3)=3 |
| acos(X) | X的反余弦 | ACOS(1)=0 |
| cos(X) | 余弦 | COS(1)=0.54030230586814 |
| ceil(X) | 大于或等于X的最小值 | CEIL(5.4)=6 |
| floor(X) | 小于或等于X的最大值 | FLOOR(5.8)=5 |
| log(X,Y) | X为底Y的对数 | LOG(2,4)=2 |
| mod(X,Y) | X除以Y的余数 | MOD(8,3)=2 |
| power(X,Y) | X的Y次幂 | POWER(2,3)=8 |
| round(X[,Y]) | X在第Y位四舍五入 | ROUND(3.456,2)=3.46 |
| sqrt(X) | X的平方根 | SQRT(4)=2 |
| trunc(X[,Y]) | X在第Y位截断 | TRUNC(3.456,2)=3.45 |
3、日期函数
1、ADD_MONTHS(d,n),在某一个日期 d 上,加上指定的月数 n,返回计算后的新日期。
例:SELECT SYSDATE,add_months(SYSDATE,5) FROM dual;
2、LAST_DAY(d),返回指定日期当月的最后一天。
3、例: SELECT SYSDATE,last_day(SYSDATE) FROM dual;
ROUND(d[,fmt]),返回一个以fmt为格式的四舍五入日期值 d是日期,fmt是格式例:
4、四舍五入日期天,月,年
SELECT SYSDATE,ROUND(SYSDATE),ROUND(SYSDATE,‘day’),ROUND(SYSDATE,‘month’),ROUND(SYSDATE,‘year’) FROM dual;
5、提取日期中特定部分 extract
SELECT SYSDATE “date”,
EXTRACT(YEAR FROM SYSDATE)“year”,
EXTRACT(MONTH FROM SYSDATE)“month”,
EXTRACT(DAY FROM SYSDATE)“day”,
EXTRACT(HOUR FROM SYSTIMESTAMP)“hour”,
EXTRACT(MINUTE FROM SYSTIMESTAMP)“minute”,
EXTRACT(SECOND FROM SYSTIMESTAMP)“second” from dual;
4、转换函数
1、获取当前年月日时分秒
select to_char (sysdate,‘YYYY"年"MM"月"DD"日" HH24:MI:SS’)“date” from dual;
结果:2020年09月6日 17:08:10
针对时间日期的格式化,格式化字符有:
| 参数 | 说明 | 示例 |
|---|---|---|
| Y | Y或YY或YYY 年的最后一位,两位,三位 | SELECT TO_CHAR(SYSDATE,‘YYY’) FROM dual; |
| Q | 季度,1-3月为第一季度 | SELECT TO_CHAR(SYSDATE,‘Q’) FROM dual; |
| MM | 月份数 | SELECT TO_CHAR(SYSDATE,’ MM’) FROM dual; |
| RM | 月份的罗马表示 | SELECT TO_CHAR(SYSDATE,’ RM’) FROM dual; |
| month | 用9个字符表示的月份名 | SELECT TO_CHAR(SYSDATE,‘month’) FROM dual; |
| ww | 当年第几周 | SELECT TO_CHAR(SYSDATE,‘ww’) FROM dual; |
| w | 本月第几周 | SELECT TO_CHAR(SYSDATE,‘w’) FROM dual; |
| DDD | 当年第几天,一月一日为001 ,二月一日032 | SELECT TO_CHAR(SYSDATE,‘DDD’) FROM dual; |
| DD | 当月第几天 | SELECT TO_CHAR(SYSDATE,‘DD’) FROM dual; |
| D | 星期几 | SELECT TO_CHAR(SYSDATE,‘D’) FROM dual; |
| DY | 星期几的缩写 | SELECT TO_CHAR(SYSDATE,‘DY’) FROM dual; |
| hh12 | 12小时制小时数 | SELECT TO_CHAR(SYSDATE,‘hh12’) FROM dual; |
| hh24 | 24小时制小时数 | SELECT TO_CHAR(SYSDATE,‘hh24’) FROM dual; |
| Mi | 分钟数 | SELECT TO_CHAR(SYSDATE,‘Mi’) FROM dual; |
| ss | 秒数 | SELECT TO_CHAR(SYSDATE,‘ss’) FROM dual; |
针对数字的格式化,格式化字符有:
| 参数 | 示例 | 示例 |
|---|---|---|
| 9 | 9999 | 指定位置处显示数字 |
| . | 9.9 | 指定位置返回小数点 |
| , | 99,99 | 指定位置返回一个逗号 |
| $ | $999 | 数字开头返回一个美元符号 |
| EEEE | 9.99EEEE | 科学计数法表示 |
| L | L9999 | 数字前加一个本地货币符号 |
| PR | 9999PR | 如果数字式负数则用尖括号进行表示 |
例:SELECT TO_CHAR(-123456.78,‘L9.9EEEEPR’)“date” FROM dual;
5、其它单行函数
1、nvl(X,VALUE)
如果X为空,返回value,否则返回X
例:nvl(comm,0); 把空值传换成0
2、nvl2(x,value1,value2)
如果x非空,返回value1,否则返回value2 。
例: select nvl2(comm,1000,0)sall,e.* from emp e
3、decode(x,value1,return1,value2,return2,…,valueN,returnN, returnEnd)
如果x的值等于value1,则返回return1 ,等于value2,返回return2,以此类推,returnEnd是缺省值,当X的值均不满足条件时,返回returnEnd。
4、PIVOT(列转行)
PIVOT(聚合函数 for 列名 in (定义列名和范围)),其中in(’’)中可以指定别名和子查询。
6、rank()/dense_rank over(partition by … order by …)
说明:over()在什么条件之上;
partition by 按哪个字段划分组;
order by 按哪个字段排序;
注意:
(1)使用rank()/dense_rank() 时,必须要带order by否则非法
(2)rank()/dense_rank()分级的区别:
rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
–在按部门划分的基础上,工资从高到低分级,级别RANK 从1开始依次递增
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO,E.RANK
FROM (SELECT E.ENAME,
E.JOB,
E.SAL,
E.DEPTNO,
RANK() OVER(partition BY E.DEPTNO ORDER BY E.SAL DESC) RANK
FROM EMP E) E
where E.RANK =1 ;
7、min()/max() over(partition by …)
注:这里没有排序条件,若加上order by 排序条件,
MAX() OVER(PARTITION BY … ORDER BY … DESC) 排序规则只能为desc,否则不起作用,将查询到目前为止排序值最高字段的对应值
MIN() OVER(PARTITION BY … ORDER BY … ASC ) 排序规则只能为asc,否则不起作用,将查询到目前为止排序值最低的字段的对应值,
8、lead()/lag() over(partition by … order by …)
取前面/后面第n行记录
说明:
lead(列名,n,m): 当前记录后面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录后面第一行的记录<列名>的值,没有则默认值为null。
lag(列名,n,m): 当前记录前面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录前面第一行的记录<列名>的值,没有则默认值为null。
示例:查询个人工资与比自己高一位、第一位的工资的差额
9、FIRST_VALUE/LAST_VALUE() OVER(PARTITION BY …) 取首尾记录
代码演示:
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO,E.ROW_NUM
FROM (SELECT E.ENAME,
E.JOB,
E.SAL,
E.DEPTNO,
ROW_NUMBER() OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) ROW_NUM
FROM EMP E) E
WHERE E.ROW_NUM > 3;
10、ROW_NUMBER() OVER(PARTITION BY… ORDER BY …) 排序
代码演示:
SELECT E.ENAME, E.JOB, E.SAL, E.DEPTNO,E.ROW_NUM
FROM (SELECT E.ENAME,
E.JOB,
E.SAL,
E.DEPTNO,
ROW_NUMBER() OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) ROW_NUM
FROM EMP E) E
WHERE E.ROW_NUM > 3;
11、sum/avg/count() over(partition by …)
代码演示:
SELECT E.ENAME,
E.JOB,
E.SAL,
E.DEPTNO,
SUM(E.SAL) OVER(PARTITION BY E.DEPTNO) SUM_SAL, --统计某组中的总计值
AVG(E.SAL) OVER(PARTITION BY E.DEPTNO) AVG_SAL, --统计某组中的平均值
COUNT(E.SAL) OVER(PARTITION BY E.DEPTNO) COUNT_SAL --按某列分组,并统计该组中记录数量
FROM EMP E;
SELECT A.DEPT_ID,
A.SALE_DATE,
A.GOODS_TYPE,
A.SALE_CNT,
SUM(A.SALE_CNT) OVER(PARTITION BY A.DEPT_ID) DEPT_TOTAL, --部门销售总和
SUM(A.SALE_CNT) OVER() CMP_TOTAL, --公司销售总额
AVG(A.SALE_CNT) OVER(PARTITION BY A.DEPT_ID) DEPT_AVG, --部门销售均值
AVG(A.SALE_CNT) OVER() CMP_AVG --公司销售均值
FROM LEARN_FUN_KEEP A;
12、rows/range between … preceding and … following 上下范围内求值
说明:unbounded:不受控制的,无限的
preceding:在…之前
following:在…之后
rows between … preceding and … following
代码演示:
13、NULLS FIRST/LAST 将空值字段记录放到最前或最后显示
代码演示:
SELECT E.ENAME,
E.JOB,
E.SAL,
E.DEPTNO,
RANK() OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL NULLS LAST)
FROM EMP E;
SELECT EMPNO,
ENAME,
DEPTNO,
SAL,
–注意ROWS BETWEEN unbounded preceding AND current row 是指第一行至当前行的汇总
SUM(SAL) OVER(PARTITION BY DEPTNO
ORDER BY ENAME
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) max_sal
FROM SCOTT.EMP;
14、NTILE(n) 获取部分数据
代码演示:
SELECT E.ENAME,
E.JOB,
E.SAL,
E.DEPTNO,
NTILE(3) OVER(ORDER BY E.SAL DESC NULLS LAST) ALL_CMP, --若只取前三分之一,all_cmp=1即可,若只取中间三分之一,all_cmp=2即可
NTILE(3) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC NULLS LAST) ALL_DEPT --每个部门的分成三部分
FROM EMP E
函数练习:
–1案例,显示所有员工的姓名的第一个字母
select ename,substr(ename,1,1) from emp ;
–2假设一个月为30天,找出所有员工的日薪,不计小数
select trunc(sal/30) from emp
–3找到2月份受雇的员工
select * from emp where to_char(hiredate,‘mm’)=‘02’ ;
–4分组统计各部门下工资>500的员工的平均工资
select avg(sal),deptno from emp where sal>500 group by deptno ;
–5统计各部门下平均工资大于500的部门
select avg(sal),deptno from emp group by deptno having avg(sal)>500;
select * from (select avg(sal) avgsal ,deptno from emp group by deptno) tt where tt.avgsal>500;
–6算出部门30中得到最多奖金的员工奖金
select max(comm) from emp where deptno=30
–7算出每个职位的员工数和最低工资
select job,count(empno),min(sal) from emp group by job;
–8列出员工表中每个部门的员工数,和部门编号
select deptno, count(empno) from emp group by deptno
–9得到工资大于自己部门平均工资的员工信息
select *
from emp e, (select avg(sal) avgsal, deptno from emp group by deptno) tt
where e.deptno = tt.deptno
and e.sal > tt.avgsal
–使用连接查询
select *
from emp e
right join (select avg(sal) avgsal, deptno from emp group by deptno) tt
on e.deptno = tt.deptno
– where e.sal > tt.avgsal
–(+)在哪里,那么对端就是主表
select * from emp e,dept d where e.deptno(+)=d.deptno
–10分组统计每个部门下,每种职位的平均奖金(也要算没奖金的人)和总工资(包括奖金)
select deptno,
job,
avg(nvl(comm, 0)) avgcomm,
sum(sal + nvl(comm, 0)) totalsal
from emp
group by deptno, job
order by deptno
–11列出员工表中每个部门的员工数(员工数必须大于3),和部门名称
select tt., dept.dname
from (select deptno, count(empno)
from emp
group by deptno
having count(empno) > 3) tt
inner join dept
on tt.deptno = dept.deptno;
–12找出工资比jones多的员工
select * from emp where sal >(select sal from emp where ename =upper(‘jones’))
–13列出所有员工的姓名和其上级的姓名
select tt., e.ename
from (select ename, mgr from emp) tt
left join emp e
on tt.mgr = e.empno;
–14以职位分组,找出平均工资最高的两种职位
select *
from (select avg(sal), job from emp group by job order by avg(sal) desc) tt
where rownum <= 2
存储过程
创建存储过程
调用存储过程
第一种:call proc_del_same();
第二种:exec proc_del_same; (在命令中使用)
第三种:begin
proc_del_same;
end;
创建存储过程
–无参存储过程 删除重复行
create or replace procedure proc_del_same
is
begin
delete from tb_test aaa
where aaa.rowid not in (select max(rowid)
from tb_test bbb
where aaa.a = bbb.a
and aaa.b = bbb.b);
end;
–带入参的存储过程
–输入员工编号,返回工资
create or replace procedure proc_get_sal(v_empno in emp.empno%type) is
v_sal emp.sal%type;
begin
select sal into v_sal from emp where empno = v_empno;
dbms_output.put_line(‘你查询的员工的工资:’ || v_sal);
exception
when NO_DATA_FOUND then
dbms_output.put_line(‘你查询的员工不存在’);
end;
–带返回值和带入参的存储过程
–输入员工编号,返回员工工资
create or replace procedure proc_return_sal(v_empno in emp.empno%type,
v_sal out emp.sal%type) is
begin
select sal into v_sal from emp where empno = v_empno;
dbms_output.put_line(‘你查询的员工的工资:’ || v_sal);
exception
when NO_DATA_FOUND then
dbms_output.put_line(‘你查询的员工不存在’);
end;
—一个参数,两种作用
create or replace procedure proc_in_out_sal(v_param in out number) is
begin
select sal into v_param from emp where empno = v_param;
dbms_output.put_line(‘你查询的员工的工资:’ || v_param);
exception
when NO_DATA_FOUND then
dbms_output.put_line(‘你查询的员工不存在’);
end;
–存储过程的参数传递
create or replace procedure proc_add_dept(v_deptno dept.deptno%type,
v_dname dept.dname%type,
v_loc dept.loc%type) as
begin
insert into dept values (v_deptno, v_dname, v_loc);
commit;
end;
select * from dept;
函数
函数的创建和使用
–通过输入员工编号获得员工所在的部门名称
create or replace function func_get_dname(v_empno number) return varchar2 as
v_dname dept.dname%type;
begin
select d.dname
into v_dname
from emp e
inner join dept d
on e.deptno = d.deptno
where e.empno = v_empno;
return v_dname;
end;
–删除函数
drop function func_get_dname;
游标
declare
v_dept dept%rowtype;
–定义一个变量,封装多行数据,table类型
type dept_table is table of dept%rowtype;
v_dept_rows dept_table;
定义游标
cursor cursor_dept is select * from dept;
begin
打开游标
open cursor_dept;
提取数据(提取多行)
fetch cursor_dept bulk collect into v_dept_rows;
–loop
–fetch cursor_dept into v_dept;
–exit when cursor_dept%notfound;
–dbms_output.put_line(‘部门编号:’||v_dept.deptno||‘部门名称:’||v_dept.dname||‘地址:’||v_dept.loc);
–end loop;
关闭游标
close cursor_dept;
例子
–通过for循环显示v_dept_rows
for i in v_dept_rows.first…v_dept_rows.last loop
dbms_output.put_line(‘部门编号:’||v_dept_rows(i).deptno||‘部门名称:’||v_dept_rows(i).dname||‘地址:’||v_dept_rows(i).loc);
end loop;
end;
declare
–定义游标
cursor cursor_dept(v_loc varchar2) is select deptno,dname from dept where loc=v_loc;
v_dept cursor_dept%rowtype;
begin
–打开游标
open cursor_dept(‘北京’);
–提取数据(提取多行)
–fetch cursor_dept bulk collect into v_dept_rows;
loop
fetch cursor_dept into v_dept;
exit when cursor_dept%notfound;
dbms_output.put_line(‘部门编号:’||v_dept.deptno||‘部门名称:’||v_dept.dname);
end loop;
–关闭游标
close cursor_dept;
end;
–游标for循环方式
declare
–定义游标
cursor cursor_dept is select * from dept;
begin
–提取数据(提取多行)
for xxx in cursor_dept loop
dbms_output.put_line(‘部门编号:’||xxx.deptno||‘部门名称:’||xxx.dname||‘地址:’||xxx.loc);
end loop;
end;
–将游标的定义省略
begin
–提取数据(提取多行)
for xxx in (select * from dept) loop
dbms_output.put_line(‘部门编号:’||xxx.deptno||‘部门名称:’||xxx.dname||‘地址:’||xxx.loc);
end loop;
end;
触发器
创建触发器
–删除dept中的数据时,触发一个新事件,将删除的数据保存到dept的备份表中
–创建备份表tbl_dept_bak(1=1,数据一起备份)(1=2,只有类型,没有数据)
create table tbl_dept_bak as select * from dept where 1=2;
create or replace trigger trigger_dept after delete on dept for each row
declare
begin
insert into tbl_dept_bak values(:old.deptno,:old.dname,:old.loc);
end;
select * from dept;
select * from tbl_dept_bak;
delete from dept where deptno=88;
触发器的条件谓语
create or replace trigger trigger_operation_dept
before
insert or update or delete
on dept for each row
begin
if to_char(sysdate,‘dat’) in (‘星期一’,‘星期五’)
then
case
when inserting then
raise_application_error(-20000,‘周1和周5不能进行录入操作’);
when deleting then
raise_application_error(-20000,‘周1和周5不能进行删除操作’);
when updating then
raise_application_error(-20000,‘周1和周5不能进行修改操作’);
end case;
end if;
end;
select * from dept
insert into dept values(60,‘财务部1’,‘深圳’);
delete from dept where deptno = 50
–如果修改的是部门编号为30的员工工资,则工资不能降低,奖金不能降,不能开除
create or replace trigger trigger_emp_update
before update of sal,comm or delete on emp for each row
begin
if :old.deptno=30 then
case when :new.sal<:old.sal
then
raise_application_error(-20000,‘工资不能降’);
when :new.comm<:old.comm
then
raise_application_error(-20000,‘奖金不能降’);
when deleting then
raise_application_error(-20000,‘不能开除’);
else
dbms_output.put_line(‘操作成功!’);
end case;
end if;
end;
update emp set comm=200 where empno=7499;
delete from emp where empno=7499;
查询所有的触发器
select trigger_name from user_triggers;
select * from user_triggers;
禁用触发器
alter trigger trigger_operation_dept disable;
–禁用某个表上的所有触发器
ALTER TABLE 你的表 DISABLE TRIGGER all
–禁用所有表上的所有触发器
exec sp_msforeachtable ‘ALTER TABLE ? DISABLE TRIGGER all’
启用触发器
alter trigger trigger_operation_dept enable;
–启用某个表上的所有触发器
ALTER TABLE 你的表enable TRIGGER all
–启用所有表上的所有触发器
exec sp_msforeachtable ‘ALTER TABLE ? enable TRIGGERall’
创建视图
–(虚拟表)cmd 打入 grant dba to scott 获取权限
create or replace view view_total
as
select (sal+nvl(comm,0)) total,empno,ename from emp;
–创建替代触发器
create or replace trigger trigger_view_total
instead of update on view_total for each row
declare
begin
update emp set comm=(comm+1000) where empno=:old.empno;
end;
oracle的mybatis项目
创建Mapper.xml文件(头部在mybatis官方文档)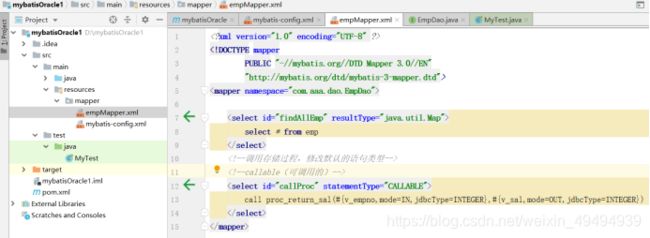
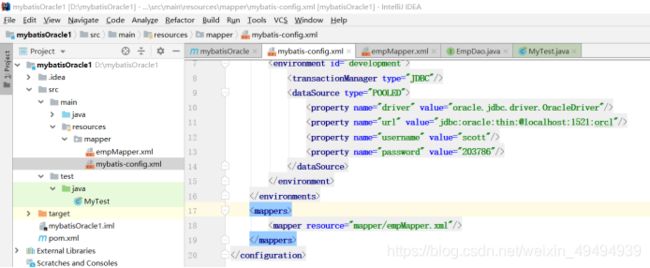
创建mybatis-conflg.xml文件(头部在mybatis官方文档)
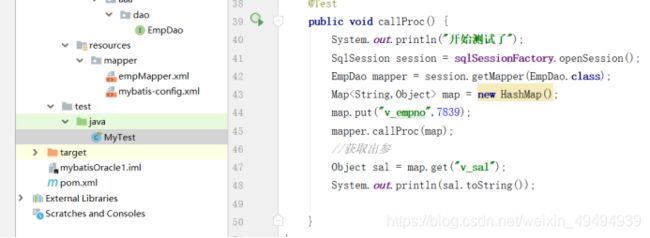
 测试函数:
测试函数:


oracle数据类型
| oracle类型 | java类型 |
|---|---|
| JDBC Type | Java Type |
| CHAR | String |
| VARCHAR | String |
| LONGVARCHAR | String |
| NUMERIC | java.math.BigDecimal |
| DECIMAL | java.math.BigDecimal |
| BIT | boolean |
| BOOLEAN | boolean |
| TINYINT | byte |
| SMALLINT | short |
| INTEGER | int |
| BIGINT | long |
| REAL | float |
| FLOAT | double |
| DOUBLE | double |
| BINARY | byte[] |
| VARBINARY | byte[] |
| LONGVARBINARY | byte[] |
| DATE | java.sql.Date |
| TIME | java.sql.Time |
| TIMESTAMP | java.sql.Timestamp |
| CLOB | Clob |
| BLOB | Blob |
| ARRAY | Array |
| DISTINCT | mapping of underlying type |
| STRUCT | Struct |
| REF | Ref |
| DATALINK | java.net.URL[color=red][/color] |