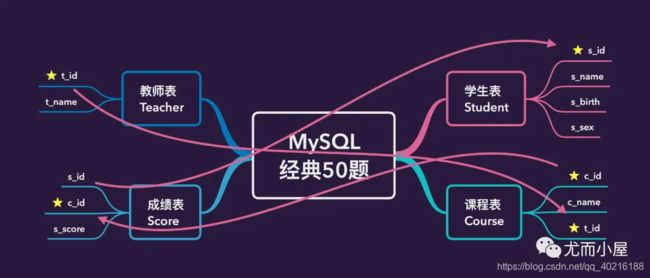
MySQL之经典50道题
MySQL之经典50道题
- 一、创建数据表并插入数据
- 二、开始解题
-
- 2.1 题目1:查询"01"课程比"02"课程成绩高的学生的信息、课程分数
- 2.2 题目2:查询平均成绩大于等于60分且总分大于200分的同学且必须考3门的学生编号和学生姓名和平均成绩
- 2.3 题目3:查询平均成绩小于60分的同学的学生编号、学生姓名、平均成绩(包括有成绩的和无成绩)
- 2.4 题目4:查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
- 2.5 题目5:查询“李”姓老师的数量
- 2.6 题目6:查询学过张三老师授课的同学信息
- 2.7 题目7:找出没有学过张三老师课程的学生
- 2.8 题目8:查询学过编号为01,并且学过编号为02课程的学生信息
- 2.9 题目9:查询学过01课程,但是没有学过02课程的学生信息
- 2.10 题目10:查询没有学完全部课程的同学的信息
- 2.11 题目11:查询至少有一门课与学号为01的同学所学相同的同学的信息
- 2.12 题目12:查询和01同学学习的课程完全相同的同学的信息
- 2.13 题目13:查询没有修过张三老师讲授的任何一门课程的学生姓名
- 2.14 题目14:查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
- 2.15 题目15:LeetCode-for-SQL的第二题:第二高的薪水
- 2.16 题目16:求出第n高的成绩(找出语文科目第2高的成绩和学号)
- 2.17 题目17:LeetCode-SQL-596-超过5名学生的课程
- 2.18 题目18:LeetCode-SQL-181-超过经理收入的员工
- 2.19 题目19:检索01课程分数小于60,按分数降序排列的学生信息
- 2.20 题目20:按平均成绩从高到低(降序)显示所有学生的所有课程的成绩以及平均成绩
- 2.21 题目21:查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率(及格:>=60),中等率(中等为:70-80),优良率(优良为:80-90),优秀率(优秀为:>=90);---比较综合,多看!
- 2.22 题目22:按照各科成绩进行排序,并且显示排名---比较综合,多看!
- 2.23 题目23:查询学生的总成绩,并进行排名---比较综合,多看!
- 2.24 题目24:LeetCode-SQL-182-查找重复的电子邮箱,从给定的表Person中找出重复的电子邮箱
- 2.25 题目25:LeetCode-SQL-595-大的国家
- 2.26 题目26:LeetCode-SQL-184-部门工资最高/N高的员工---多看
- 2.27 题目27:查询不同老师所教不同课程平均分从高到低显示
- 2.28 题目28:查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
- 2.29 题目29:统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
- 2.30 题目30:查询学生的平均成绩及名次---比较综合,多看,定义变量,实现rank函数
- 2.31 题目31:查询各科成绩前三名的记录---比较综合,多看
- 2.32 题目32:查询每门课被选修的学生数
- 2.33 题目33:查询出只有两门课程的全部学生的学号和姓名
- 2.34 题目34:查询男女生人数
- 2.35 题目35:查询名字中含有风字的学生信息
- 2.36 题目36:查询同名同性的学生名单,并统计同名人数
- 2.37 题目37:查询每门课程的平均成绩,结果按平均成绩降序排列;平均成绩相同时,按课程编号c_id升序排列
- 2.38 题目38:查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
- 2.39 题目39:查询所有学生的课程及分数(均分、总分)情况
- 2.40 题目40:查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
- 2.41 题目41:查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩---比较综合,多看!一个表自连
- 2.42 题目42:题目的要求就是找出每门课的前2名同学---多看,比较综合,解决前几名排序的问题
- 2.43 题目43:统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
- 2.44 题目44:检索至少选修两门课程的学生学号
- 2.45 题目45:查询选修了全部课程的学生信息
- 2.46 题目46:查询各学生的年龄:按照出生日期来算,当前月日 < 出生年月的月日则,年龄减1
- 2.47 题目47:查询本周过生日的学生
- 2.48 题目48:查询下周过生日的学生
- 2.49 题目49:查询本月过生的同学
- 2.50 题目50:查询下月过生的同学
一、创建数据表并插入数据
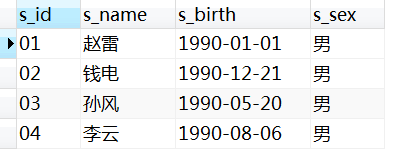
- 1、学生表
Student(s_id,s_name,s_birth,s_sex) :学生编号、姓名、年月、性别
-- 1、学生表
-- Student(s_id,s_name,s_birth,s_sex) :学生编号、姓名、年月、性别
CREATE TABLE
IF NOT EXISTS `Student` (
`s_id` VARCHAR (20),
`s_name` VARCHAR (20) NOT NULL DEFAULT '',
`s_birth` VARCHAR (20) NOT NULL DEFAULT '',
`s_sex` VARCHAR (10) NOT NULL DEFAULT '',
PRIMARY KEY (`s_id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 插入数据
INSERT INTO Student VALUES ('01', '赵雷', '1990-01-01', '男');
INSERT INTO Student VALUES ('02', '钱电', '1990-12-21', '男');
INSERT INTO Student VALUES ('03', '孙风', '1990-05-20', '男');
INSERT INTO Student VALUES ('04', '李云', '1990-08-06', '男');
INSERT INTO Student VALUES ('05', '周梅', '1991-12-01', '女');
INSERT INTO Student VALUES ('06', '吴兰', '1992-03-01', '女');
INSERT INTO Student VALUES ('07', '郑竹', '1989-07-01', '女');
INSERT INTO Student VALUES ('08', '王菊', '1990-01-20', '女');
- 2、课程表
Course(c_id,c_name,t_id) :课程编号、 课程名称、 教师编号
-- 2、课程表
-- Course(c_id,c_name,t_id) :课程编号、 课程名称、 教师编号
CREATE TABLE
IF NOT EXISTS `Course` (
`c_id` VARCHAR (20),
`c_name` VARCHAR (20) NOT NULL DEFAULT '',
`t_id` VARCHAR (20) NOT NULL,
PRIMARY KEY (`c_id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 插入数据
INSERT INTO Course VALUES ('01', '语文', '02');
INSERT INTO Course VALUES ('02', '数学', '01');
INSERT INTO Course VALUES ('03', '英语', '03');
- 3、教师表
Teacher(t_id,t_name) :教师编号、教师姓名
-- 3、教师表
-- Teacher(t_id,t_name) :教师编号、教师姓名
CREATE TABLE
IF NOT EXISTS `Teacher` (
`t_id` VARCHAR (20),
`t_name` VARCHAR (20) NOT NULL DEFAULT '',
PRIMARY KEY (`t_id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 插入数据
INSERT INTO Teacher VALUES ('01', '张三');
INSERT INTO Teacher VALUES ('02', '李四');
INSERT INTO Teacher VALUES ('03', '王五');
- 4、成绩表
Score(s_id,c_id,s_score) :学生编号、课程编号、分数
-- 4、成绩表
-- Score(s_id,c_id,s_score) :学生编号、课程编号、分数
CREATE TABLE
IF NOT EXISTS `Score` (
`s_id` VARCHAR (20),
`c_id` VARCHAR (20),
`s_score` INT (3),
PRIMARY KEY (`s_id`, `c_id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 插入数据
INSERT INTO Score VALUES ('01', '01', 80);
INSERT INTO Score VALUES ('01', '02', 90);
INSERT INTO Score VALUES ('01', '03', 99);
INSERT INTO Score VALUES ('02', '01', 70);
INSERT INTO Score VALUES ('02', '02', 60);
INSERT INTO Score VALUES ('02', '03', 80);
INSERT INTO Score VALUES ('03', '01', 80);
INSERT INTO Score VALUES ('03', '02', 80);
INSERT INTO Score VALUES ('03', '03', 80);
INSERT INTO Score VALUES ('04', '01', 50);
INSERT INTO Score VALUES ('04', '02', 30);
INSERT INTO Score VALUES ('04', '03', 20);
INSERT INTO Score VALUES ('05', '01', 76);
INSERT INTO Score VALUES ('05', '02', 87);
INSERT INTO Score VALUES ('06', '01', 31);
INSERT INTO Score VALUES ('06', '03', 34);
INSERT INTO Score VALUES ('07', '02', 89);
INSERT INTO Score VALUES ('07', '03', 98);
二、开始解题
2.1 题目1:查询"01"课程比"02"课程成绩高的学生的信息、课程分数
- 需要输出Student表的全部信息和Score表中的s_score;
-- 方法一:使用join连接
SELECT
a.*,
b.s_score,
c.s_score
FROM
Student a
JOIN Score b ON a.s_id = b.s_id
AND b.c_id = '01'
JOIN Score c ON a.s_id = c.s_id
AND c.c_id = '02'
WHERE
b.s_score > c.s_score;
-- 方法二:采用where语句
SELECT
a.*,
b.s_score,
c.s_score
FROM
Student a,
Score b,
Score c
WHERE
a.s_id = b.s_id
AND a.s_id = c.s_id
AND b.c_id = '01'
AND c.c_id = '02'
AND b.s_score > c.s_score;
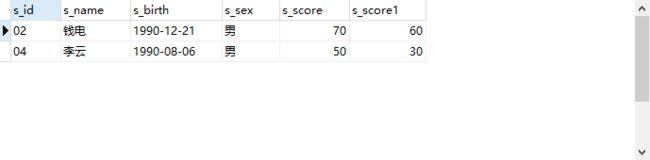
2.2 题目2:查询平均成绩大于等于60分且总分大于200分的同学且必须考3门的学生编号和学生姓名和平均成绩
SELECT
a.s_id,
a.s_name,
ROUND(AVG(b.s_score), 2) AS avg_score,
-- 求均值并保留2位小数
ROUND(SUM(b.s_score), 0) AS sum_score
-- 求和并保留0位小数
FROM
Student a
JOIN Score b ON a.s_id = b.s_id
GROUP BY
a.s_id
HAVING
avg_score >= 60
AND sum_score > 200
AND COUNT(b.s_score)=3;
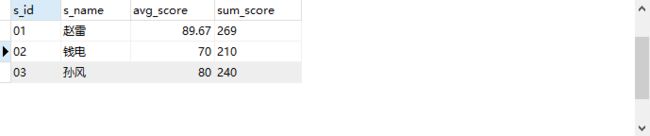
2.3 题目3:查询平均成绩小于60分的同学的学生编号、学生姓名、平均成绩(包括有成绩的和无成绩)
SELECT
a.s_id,
a.s_name,
ROUND(AVG(b.s_score), 2) AS avg_score
FROM
Student a
LEFT JOIN Score b ON a.s_id = b.s_id
GROUP BY
a.s_id
HAVING
avg_score < 60;

- 上表所示的结果中没有"王菊",因为王菊没有成绩;
- 以下代码筛选出没有成绩的同学王菊;
SELECT
a.s_id,
a.s_name,
0 AS avg_score -- 将avg_score的值置为0
FROM
Student a
WHERE
a.s_id NOT IN (
-- 学生的学号不在给给定表的学号中
SELECT DISTINCT
s_id -- 查询出全部的学号
FROM
Score
);

- 可以将上述2个表进行合并,采用union函数,但表的数据列必须一致,上下合并数据表的函数有union和union all两个,区别在于union可以对数据进行去重,而union all则不去重;
-- 方法1:采用union函数进行合并
SELECT
a.s_id,
a.s_name,
ROUND(AVG(b.s_score), 2) AS avg_score
FROM
Student a
LEFT JOIN Score b ON a.s_id = b.s_id
GROUP BY
a.s_id
HAVING
avg_score < 60
UNION
SELECT
a.s_id,
a.s_name,
0 AS avg_score
FROM
Student a
WHERE
a.s_id NOT IN (
-- 学生的学号不在给给定表的学号中
SELECT DISTINCT
s_id -- 查询出全部的学号
FROM
Score
);

- 不采用union函数,采用ifnull和null函数进行筛选计算;
-- 方法2:采用ifnull函数
SELECT
S.s_id,
S.s_name,
ROUND(AVG(IFNULL(C.s_score, 0)), 2) AS avg_score -- ifnull 函数:第一个参数存在则取它本身,不存在取第二个值0
FROM
Student S
LEFT JOIN Score C ON S.s_id = C.s_id -- 一定要采用左连接
GROUP BY
s_id
HAVING
avg_score < 60;

-- 方法3:采用null函数
SELECT
a.s_id,
a.s_name,
ROUND(AVG(b.s_score), 2) AS avg_score
FROM
Student a
LEFT JOIN Score b ON a.s_id = b.s_id
GROUP BY
a.s_id
HAVING
avg_score < 60
OR avg_score IS NULL; -- 最后的NULL判断

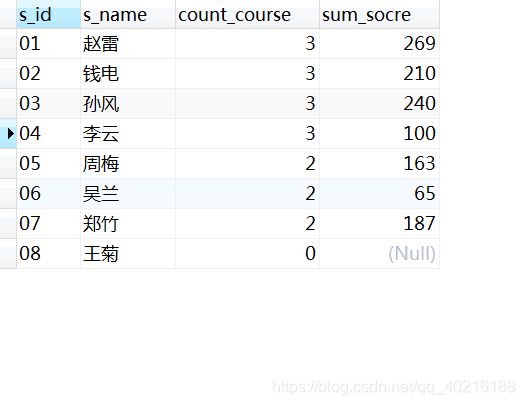
2.4 题目4:查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
SELECT
a.s_id,
a.s_name,
COUNT(b.c_id) AS count_course,
SUM(b.s_score) AS sum_socre
FROM
Student a
LEFT JOIN Score b ON a.s_id = b.s_id -- 采用left join,所以对于没有成绩的学生也可以筛选出来。
GROUP BY
a.s_id;
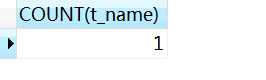
2.5 题目5:查询“李”姓老师的数量
- 采用通配符%和like关键字来解决。
SELECT
COUNT(t_name)
FROM
Teacher
WHERE
t_name LIKE '李%'; -- 以李字开头的名字
2.6 题目6:查询学过张三老师授课的同学信息
-- 方法1:通过筛选出张三的id,并匹配相应的课程id,最后将学生的成绩与课程id进行匹配,最后筛选出符合条件的学生。
SELECT
a.*
FROM
Student a
JOIN Score b ON a.s_id = b.s_id
AND b.c_id =(
SELECT
c_id
FROM
Course
WHERE
t_id =(
SELECT
t_id
FROM
Teacher
WHERE
t_name = '张三'
));
-- 方法2:通过left join进行匹配
SELECT
a.*
FROM
Student a
JOIN Score b ON a.s_id = b.s_id
JOIN Course c ON b.c_id = c.c_id
JOIN Teacher d ON c.t_id = d.t_id
WHERE d.t_name='张三';
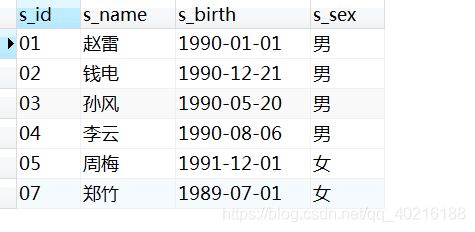
2.7 题目7:找出没有学过张三老师课程的学生
- 和上面的题目是互补的,考虑取反操作。
-- 方法1:通过筛选出张三的id,并匹配相应的课程id,然后将学生的成绩与张三老师课程id进行匹配,最后筛选不在次学生id范围内的学生信息。
SELECT
t3.*
FROM
Student t3
WHERE
t3.s_id NOT IN (
SELECT
t1.s_id
FROM
Score t1
JOIN Course t2 ON t1.c_id = t2.c_id
WHERE
t_id = (
SELECT
t_id
FROM
Teacher
WHERE
t_name = '张三'
)
);
-- 方法2:使用join
SELECT
a.*
FROM
Student a
WHERE
a.s_id NOT IN (
SELECT
s_id
FROM
Score a
JOIN Course b ON a.c_id = b.c_id
JOIN Teacher c ON b.t_id = c.t_id
WHERE
c.t_name = '张三'
);
2.8 题目8:查询学过编号为01,并且学过编号为02课程的学生信息
-- 方法1:通过自连接实现
SELECT
a.*
FROM
Student a
WHERE
a.s_id IN (
SELECT
b.s_id
FROM
Score b
JOIN Score c ON b.s_id = c.s_id
WHERE
b.c_id = '01'
AND c.c_id = '02'
);
--方法2:通过where实现
SELECT
s1.*
FROM
Student s1,
Score s2,
Score s3
WHERE
s1.s_id = s2.s_id
AND s1.s_id = s3.s_id
AND s2.c_id = 01
AND s3.c_id = 02;
2.9 题目9:查询学过01课程,但是没有学过02课程的学生信息
SELECT
s1.*
FROM
Student s1
WHERE
s1.s_id IN (
SELECT
s_id
FROM
Score
WHERE
c_id = '01'
) -- 修过01课程,要保留
AND s1.s_id NOT IN (
SELECT
s_id
FROM
Score
WHERE
c_id = '02'
);-- 哪些人修过02,需要排除

2.10 题目10:查询没有学完全部课程的同学的信息
- 解题思路:在Course表中先计算总的课程数,后对学生进行分组,筛选出每组中课程数量少于总的课程数的学生。
-- 方法1
select s.*
from Student s -- 学生表
left join Score s1 -- 成绩表
on s1.s_id = s.s_id
group by s.s_id -- 学号分组
having count(s1.c_id) < ( -- 分组后学生的课程数<3
select count(*) from Course -- 全部课程数=3
)
-- 方法2
select s.*
from Student s
where s_id not in (
select s_id
from Score s1
group by s_id
having count(*) = (select count(*) from Course)
);
2.11 题目11:查询至少有一门课与学号为01的同学所学相同的同学的信息
SELECT
b.*
FROM
student b
LEFT JOIN score c ON b.s_id = c.s_id
WHERE
c.c_id IN ( SELECT a.c_id FROM score a WHERE a.s_id = '01' )
AND b.s_id != '01' --排除01学生自己
GROUP BY
b.s_id;
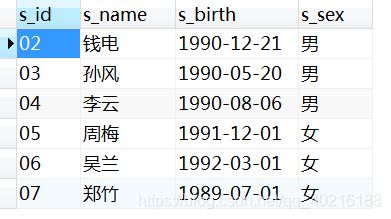
2.12 题目12:查询和01同学学习的课程完全相同的同学的信息
- 方法1:因为总课程数3,而01号同学的课程数刚好是3,所以我们只要找出在Score表中课程也修满3门的同学即可。
SELECT
b.*
FROM
student b
JOIN score c ON b.s_id = c.s_id
WHERE
b.s_id != '01'
GROUP BY
b.s_id
HAVING
COUNT( c.c_id )=(
SELECT
COUNT( c_id )
FROM
score
WHERE
s_id = '01')
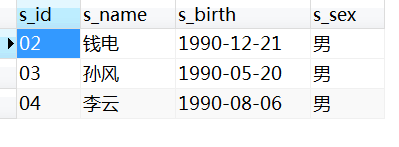
- 方法2:使用group_concat函数(分组合并,同时排序)
1)group_concat的使用方法为:
group_concat([DISTINCT] 字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
SELECT
b.s_id,
b.s_name,
b.s_sex,
GROUP_CONCAT( c.c_id ORDER BY c.c_id ) AS concat_course
FROM
student b
JOIN score c ON b.s_id = c.s_id
GROUP BY
b.s_id
HAVING
GROUP_CONCAT( c.c_id ORDER BY c.c_id )=(
SELECT
GROUP_CONCAT( c_id ORDER BY c_id )
FROM
score
WHERE
s_id = '01'
);
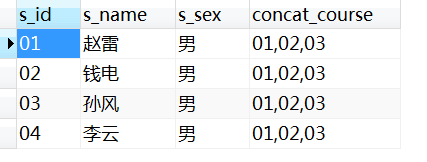
2.13 题目13:查询没有修过张三老师讲授的任何一门课程的学生姓名
-- 方法1
SELECT
*
FROM
student
WHERE
s_id NOT IN (
SELECT DISTINCT
t1.s_id
FROM
score t1
JOIN course t2 ON t1.c_id = t2.c_id
WHERE
t2.t_id = (
SELECT
t_id
FROM
teacher
WHERE
t_name = '张三'
)
)
-- 方法2
SELECT
* -- 4、学号取反找到学生信息
FROM
Student
WHERE
s_id NOT IN (
SELECT DISTINCT
(s_id) -- 3、课程号找到对应的学号
FROM
Score
WHERE
c_id = (
SELECT
c_id -- 2、教师编号找到对应的课程号
FROM
Course
WHERE
t_id = (
SELECT
t_id -- 1、姓名找到教师编号
FROM
Teacher
WHERE
t_name = '张三'
)
)
);
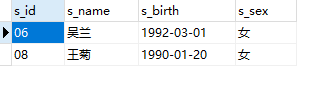
2.14 题目14:查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
SELECT
s.s_id,
s.s_name,
t.avg_score
FROM
Student s
JOIN (
SELECT
s_id,
ROUND(AVG(s_score)) avg_score --求均值再取整
FROM
Score
WHERE
s_score < 60
GROUP BY
s_id
HAVING
COUNT(s_score) >= 2
) t ON s.s_id = t.s_id
2.15 题目15:LeetCode-for-SQL的第二题:第二高的薪水
编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
±—±-------+
| Id | Salary |
±—±-------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
±—±-------+
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
±--------------------+
| SecondHighestSalary |
±--------------------+
| 200 |
±--------------------+
- 方法1:嵌套
-- 第二高的薪水,除去最高薪水之后,在剩下的薪水中找最高的
select
max(Salary) as SecondHighestSalary -- 2、排除原数据中最高薪水之后,剩下的最大值就是第二高
from Employee
where Salary < (select max(Salary) from Employee); -- 1、这个select是找到原始数据中的最高薪水
缺点:当求第二高薪水的时候,只需要嵌套一层;如果求的是第3高,那么需要将第一高、第二高的同时排除,需要排除两次
-- 嵌套方法:找出第三高的薪水
select
max(Salary) as ThirdHighestSalary -- 3、确定第3高
from Employee
where Salary < (
select
max(Salary) as SecondHighestSalary -- 2、找到第二高
from Employee
where Salary < (select max(Salary) from Employee); -- 1、找到第一高
);
- 方法1:使用 limit 关键字来实现翻页处理
1)使用limit m,n的形式:m 表示从第 m 行数据之后,不包含第 m 行,之后的 n 行数据

1)使用limit m offset n形式:表示查询结果跳过 n 条数据,读取前 m 条数据
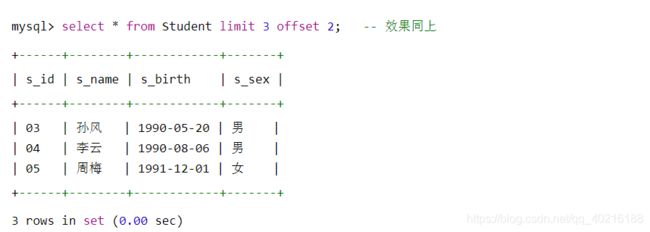
select
distinct Salary -- 去重
from Employee
order by Salary desc -- 薪水降序
limit 1 offset 1 -- 从第1行数据之后显示一行:除去最高的薪水之后再显示一行,也就是第二高的薪水
如果原数据中只存在一个最高值,也就说不存在第二高薪水的时候,需要显示为null,我们对上面的结果使用ifnull函数来实现
select ifnull((select distinct Salary -- 如果不存在则赋值为null
from Employee
order by Salary desc
limit 1 offset 1), null) as SecondHighestSalary
- IFNULL() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为 NULL 则返回第一个参数的值。
2.16 题目16:求出第n高的成绩(找出语文科目第2高的成绩和学号)
SELECT DISTINCT
s.s_score -- 分数去重
FROM
Score s
LEFT JOIN Course c ON s.c_id = c.c_id
WHERE
c.c_name = '语文' -- 指定科目
ORDER BY
s.s_score DESC -- 降序
LIMIT 1 OFFSET 1;-- limit和offset实现翻页功能

2.17 题目17:LeetCode-SQL-596-超过5名学生的课程
有一个 courses 表 ,有 student (学生) 和 class (课程)。请列出所有超过或等于5名学生的课。例如,表:
±--------±-----------+
| student | class |
±--------±-----------+
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
±--------±-----------+
最终的结果输出为:
±--------+
| class |
±--------+
| Math |
±--------+
在最下面有个提示:学生在每个课中不应被重复计算。即如果A同学重修了Math课程,则不应该被计算在内。
-- 方法1
select
class
from courses
group by class
having count(distinct student) >=5; -- distinct去重关键
-- 方法2
select
class
from(
select
distinct *
from courses) t -- 临时表
group by class
having count(class) >= 5;
本题中最大的陷阱就是有重修课程的同学,但是给出的数据中没有展现出来,所以上面的方法中都会出现去重的操作
2.18 题目18:LeetCode-SQL-181-超过经理收入的员工
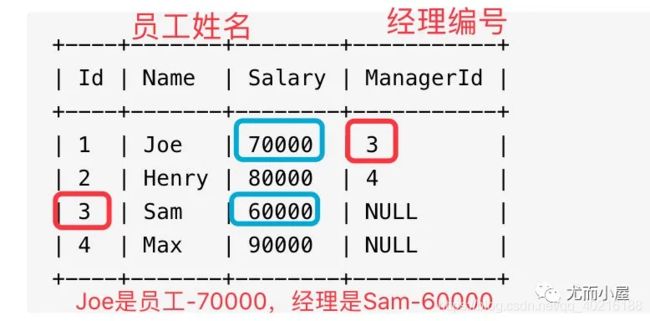
Employee 表包含所有员工,他们的经理也属于员工。每个员工都有一个 Id,此外还有一列对应员工的经理的 Id。
±—±------±-------±----------+
| Id | Name | Salary | ManagerId |
±—±------±-------±----------+
| 1 | Joe | 70000 | 3 |
| 2 | Henry | 80000 | 4 |
| 3 | Sam | 60000 | NULL |
| 4 | Max | 90000 | NULL |
±—±------±-------±----------+
给定 Employee 表,编写一个 SQL 查询,该查询可以获取收入超过他们经理的员工的姓名。在上面的表格中,Joe 是唯一一个收入超过他的经理的员工。
±---------+
| Employee |
±---------+
| Joe |
±---------+
题目利用如下的图形解释:Joe是员工,工资是70000,经理是编号3,也就是Sam,但是Sam工资只有60000
-- 方法1:自连接
select
e1.Name as Employee
from Employee e1 -- 表的自连接
left join Employee e2
on e1.ManagerId = e2.Id -- 连接条件
where e1.Salary > e2.Salary
-- 方法2:where条件过滤
select
a.Name as Employee
from Employee as a,Employee as b -
where a.ManagerId = b.Id
and a.Salary > b.Salary;
2.19 题目19:检索01课程分数小于60,按分数降序排列的学生信息
SELECT
t1.s_id
,t1.s_name
,t1.s_birth
,t1.s_sex
,t2.s_score
FROM
student t1
JOIN score t2 ON t1.s_id = t2.s_id
WHERE
t2.c_id = 01
AND t2.s_score < 60
ORDER BY t2.s_score DESC;
2.20 题目20:按平均成绩从高到低(降序)显示所有学生的所有课程的成绩以及平均成绩
-- 方法1
SELECT
t1.s_id,
t1.c_id,
t1.s_score,
t2.avg_score
FROM
score t1
JOIN ( -- 创建临时表,并进行连接
SELECT
s_id,
ROUND(AVG(s_score), 2) avg_score
FROM
score
GROUP BY
s_id
) t2 ON t1.s_id = t2.s_id
ORDER BY
4 DESC; -- 按照select中的第4列进行降序排列
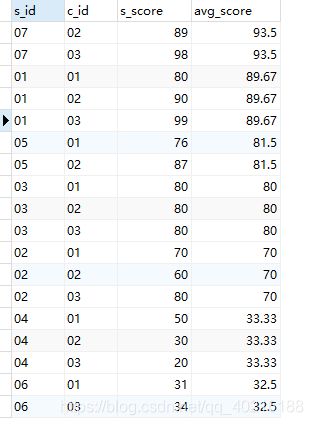
为何采用聚合函数MAX:
-- 方法2:采用case when then end语句
SELECT
s.s_id,
MAX(CASE s.c_id WHEN '01' THEN s.s_score END) 语文,
MAX(CASE s.c_id WHEN '02' THEN s.s_score END) 数学,
MAX(CASE s.c_id WHEN '03' THEN s.s_score END) 英语,
ROUND(AVG(s.s_score), 2) avg_score
FROM
score s
GROUP BY
s.s_id
ORDER BY
5 DESC;
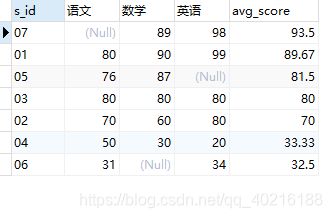
- 注意的点:对于下面的例子而言
select
s.s_id
,max(case s.c_id when '01' then s.s_score end) 语文
,max(case s.c_id when '02' then s.s_score end) 数学
,max(case s.c_id when '03' then s.s_score end) 英语
,avg(s.s_score)
,b.s_name -- 没有出现在group by子句中,导致报错
from score s
join Student b
on s.s_id = b.s_id
group by s.s_id
order by 5 desc;
- 严格模式的报错:
ERROR 1055 (42000): Expression #6 of SELECT list is not in GROUP BY clause and contains nonaggregated column ‘test.b.s_name’ which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by - 原因在于:MySQL语句模式为only_full_group_by,即对于在SELECT中的列,除了采用聚合函数的列以外,其他的列必须出现在GROUP BY中,否则认为SQL语句是不合法的。
- 上述的MySQL语句应修改为:
select
s.s_id
,max(case s.c_id when '01' then s.s_score end) 语文 -- 由于有些数据是空值,所以必须采用聚合函数,才能将真实值取出
,max(case s.c_id when '02' then s.s_score end) 数学
,max(case s.c_id when '03' then s.s_score end) 英语
,avg(s.s_score)
,b.s_name -- 没有出现在group by子句中,导致报错
from score s
join Student b
on s.s_id = b.s_id
group by s.s_id, b.s_name
order by 5 desc;
2.21 题目21:查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率(及格:>=60),中等率(中等为:70-80),优良率(优良为:80-90),优秀率(优秀为:>=90);—比较综合,多看!
- 一道比较综合的题目
SELECT
t1.c_id,
t2.c_name
,MAX(t1.s_score) max_score
,MIN(t1.s_score) min_score
,ROUND(AVG(t1.s_score),2) avg_score
,ROUND(100*(SUM(CASE WHEN t1.s_score>=60 THEN 1 ELSE 0 END)/sum(CASE WHEN t1.s_score THEN 1 ELSE 0 END)),2) AS '及格率'
,ROUND(100*(SUM(CASE WHEN t1.s_score>=70 AND t1.s_score<=80 THEN 1 ELSE 0 END)/sum(CASE WHEN t1.s_score THEN 1 ELSE 0 END)),2) AS '中等率'
,ROUND(100*(SUM(CASE WHEN t1.s_score>=80 AND t1.s_score<=90 THEN 1 ELSE 0 END)/sum(CASE WHEN t1.s_score THEN 1 ELSE 0 END)),2) AS '优良率'
,ROUND(100*(SUM(CASE WHEN t1.s_score>=90 THEN 1 ELSE 0 END)/sum(CASE WHEN t1.s_score THEN 1 ELSE 0 END)),2) AS '优秀率'
FROM
score t1
JOIN course t2 ON t1.c_id = t2.c_id
GROUP BY
t1.c_id,
t2.c_name;

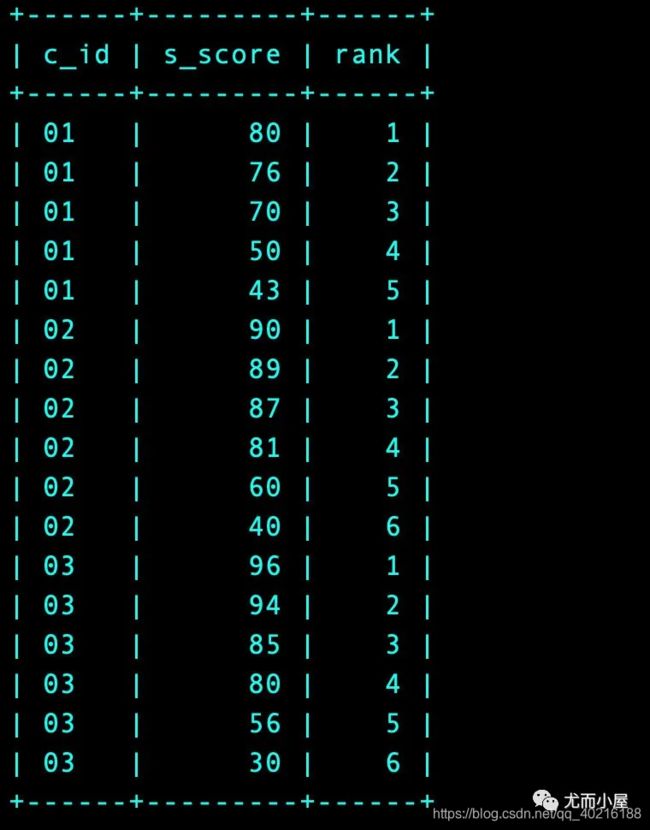
2.22 题目22:按照各科成绩进行排序,并且显示排名—比较综合,多看!
- MySQL进行排序、排名方式
select * from (select
t1.c_id,
t1.s_score,
(select count(distinct t2.s_score)
from Score t2
where t2.s_score>=t1.s_score and t2.c_id='01') rank
from Score t1 where t1.c_id='01'
order by t1.s_score desc) t1
union
select * from (select
t1.c_id
,t1.s_score
,(select count(distinct t2.s_score)
from Score t2
where t2.s_score>=t1.s_score and t2.c_id='02') rank
from Score t1 where t1.c_id='02'
order by t1.s_score desc) t2
union
select * from (select
t1.c_id,
t1.s_score,
(select count(distinct t2.s_score) from Score t2 where t2.s_score>=t1.s_score and t2.c_id='03') rank
from Score t1 where t1.c_id='03'
order by t1.s_score desc) t3
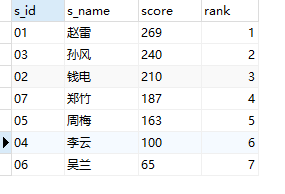
2.23 题目23:查询学生的总成绩,并进行排名—比较综合,多看!
select
t1.s_id ,t1.s_name, t1.score
,(select count(t2.score)
from(select s.s_id, s.s_name, sum(sc.s_score) score
from Student s
join Score sc
on s.s_id = sc.s_id
group by s.s_id
order by 3 desc)t2 -- t2和t1相同
where t2.score >= t1.score) as rank
from(
select s.s_id ,s.s_name ,sum(sc.s_score) score
from Student s
join Score sc
on s.s_id = sc.s_id
group by s.s_id
order by 3 desc)t1 -- t1
order by 3 desc;
2.24 题目24:LeetCode-SQL-182-查找重复的电子邮箱,从给定的表Person中找出重复的电子邮箱

-- 方法1
select
Email
from Person
group by Email
having count(Email) > 1; -- 过滤条件
-- 方法2
select
distinct (p1.Email) -- 去重统计邮箱
from Person p1
join Person p2 on p1.Email = p2.Email and p1.Id != p2.Id; -- 指定连接条件
2.25 题目25:LeetCode-SQL-595-大的国家
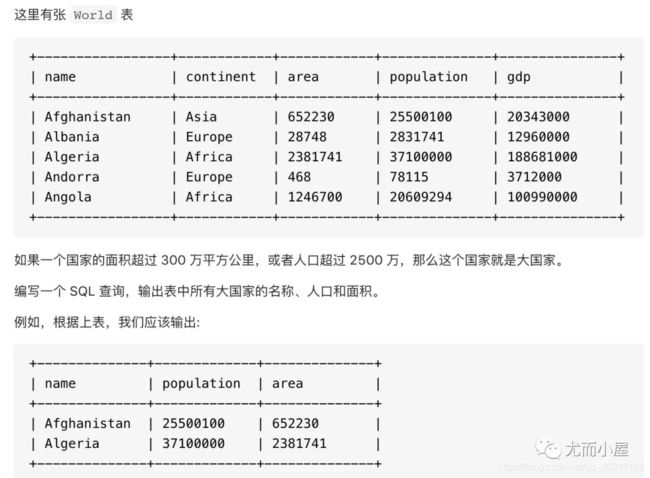
select
name
,population
,area
from World
where area > 3000000
or population > 25000000;
2.26 题目26:LeetCode-SQL-184-部门工资最高/N高的员工—多看
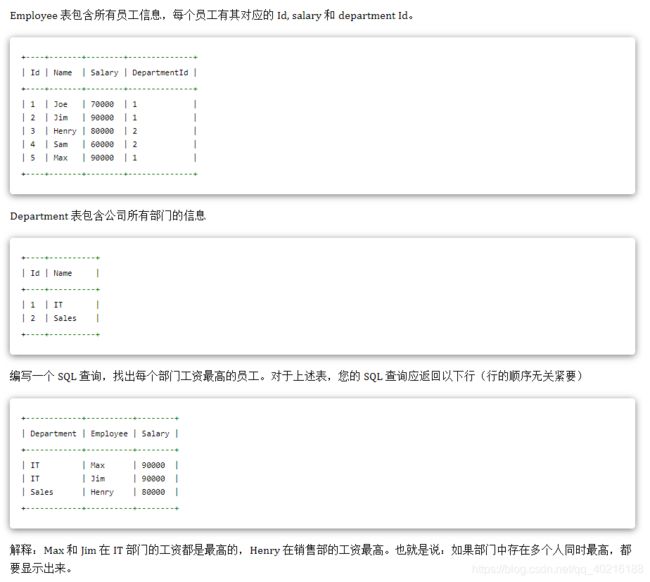
-- 方法1
SELECT
Department.name AS 'Department',
Employee.name AS 'Employee',
Salary
FROM Employee
INNER JOIN Department ON Employee.DepartmentId = Department.Id
WHERE (Employee.DepartmentId , Salary) IN ( -- 两个字段同时使用
SELECT
DepartmentId, -- 部门分组找出部门号和薪水的最大值
MAX(Salary)
FROM Employee
GROUP BY DepartmentId
)
-- 方法2:
select
d.Name Department
,e.Name Employee
,e.Salary Salary
from Employee e , Department d
where e.DepartmentId = d.Id -- 在同一个部门中进行比计较
and e.Salary >= (select max(Salary) from Employee where DepartmentId=d.Id); -- 找出每个部门的最高值;如果大于等于这个最高值,肯定是最高的
- 寻找排名第一或者第三的员工
- 窗口排名函数只有在hive和MySQL 8.X才有
SELECT S.NAME, S.EMPLOYEE, S.SALARY
FROM (SELECT
d.Name,
e.Name Employee,
e.Salary,
dense_rank() OVER(PARTITION BY e.DepartmentId ORDER BY e.Salary DESC) number -- 根据部门分区,薪水排序
FROM Employee e
LEFT JOIN Department d
ON e.DepartmentId = d.Id) S
WHERE S.number = 1 or S.number =3; -- 排名第一或者第三
2.27 题目27:查询不同老师所教不同课程平均分从高到低显示
SELECT
t2.t_name,
t2.c_name,
ROUND(AVG(t1.s_score), 2) AS avg_score
FROM
score t1
JOIN (
SELECT
a.t_name,
b.c_id,
b.c_name
FROM
teacher AS a,
course AS b
WHERE
a.t_id = b.t_id
) t2 ON t1.c_id = t2.c_id
GROUP BY t2.t_name, t2.c_name
ORDER BY ROUND(AVG(t1.s_score), 2) DESC;
- 注意:
1)上题中,最好将在select语句中除聚合函数外的列全部放到group by语句后;
2)上题中,由于select语句比order by语句先执行,所以在order by后必须使用ORDER BY ROUND(AVG(t1.s_score), 2) DESC,而不能采用别名avg_score;
2.28 题目28:查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
- 该题目采用union函数进行合并,但合并的数据必须包含相同的列;
SELECT
s.s_id,
s.s_name,
t.c_name,
t.s_score
FROM
Student s
JOIN (
-- union连接
(
SELECT
s.s_id,
s.s_score,
c.c_name
FROM
Score s
JOIN Course c ON s.c_id = c.c_id
WHERE
c.c_name = '语文'
ORDER BY
s.s_score DESC
LIMIT 1,2 -- 从第1行数据之后取2行,即取第2,3行数据
)
UNION
(
SELECT
s.s_id,
s.s_score,
c.c_name
FROM
Score s
JOIN Course c ON s.c_id = c.c_id
WHERE
c.c_name = '数学'
ORDER BY
s.s_score DESC
LIMIT 1, 2)
UNION
(
SELECT
s.s_id,
s.s_score,
c.c_name
FROM
Score s
JOIN Course c ON s.c_id = c.c_id
WHERE
c.c_name = '英语'
ORDER BY
s.s_score DESC
LIMIT 1, 2)
) t -- 临时表t
ON s.s_id = t.s_id
GROUP BY
t.c_name,
s.s_id,
s.s_name,
t.s_score
- 注意:每一个子查询,即括号中的部分,不需要将查询结果组成的表重命名,否则会报错。
2.29 题目29:统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
SELECT
s.c_id,
c.c_name,
sum( CASE WHEN s_score > 85 AND s_score <= 100 THEN 1 ELSE 0 END ) AS '85-100',
round( 100 * ( sum( CASE WHEN s_score > 85 AND s_score <= 100 THEN 1 ELSE 0 END ) / count(*)), 2 ) '[85,100]占比',
sum( CASE WHEN s_score > 70 AND s_score <= 85 THEN 1 ELSE 0 END ) AS '70-85',
round( 100 * ( sum( CASE WHEN s_score > 70 AND s_score <= 85 THEN 1 ELSE 0 END ) / count(*)), 2 ) '[70,85]占比',
sum( CASE WHEN s_score > 60 AND s_score <= 70 THEN 1 ELSE 0 END ) AS '60-70',
round( 100 * ( sum( CASE WHEN s_score > 60 AND s_score <= 70 THEN 1 ELSE 0 END ) / count(*)), 2 ) '[60,70]占比',
sum( CASE WHEN s_score >= 0 AND s_score <= 60 THEN 1 ELSE 0 END ) AS '0-60',
round( 100 * ( sum( CASE WHEN s_score > 0 AND s_score <= 60 THEN 1 ELSE 0 END ) / count(*)), 2 ) '[0,60]占比'
FROM
Score s
LEFT JOIN Course c ON s.c_id = c.c_id
GROUP BY
s.c_id,
c.c_name;-- 分课程统计总数和占比

- 注意:本题目是将case when then end函数和聚合函数一起使用。
2.30 题目30:查询学生的平均成绩及名次—比较综合,多看,定义变量,实现rank函数
- 自定义变量实现rank排序
select
a.s_id -- 学号
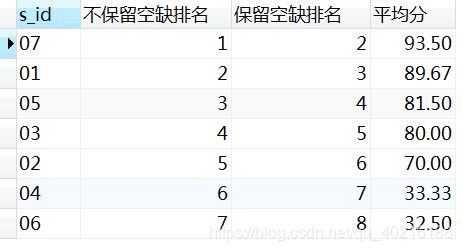
,@i:=@i+1 as '不保留空缺排名' -- 直接i的自加,顺序一直变大,声明变量需加@
,@k:=(case when @avg_score=a.avg_s then @k else @i+1 end) as '保留空缺排名' -- 只有在前后二次排序值不同时才会使顺序号加1
,@avg_score:=avg_s as '平均分' -- 表a中的值
from (select
s_id
,round(avg(s_score), 2) as avg_s
from Score
group by s_id
order by 2 desc)a -- 表a:平均成绩的排序和学号
,(select @avg_score:=0, @i:=0, @k:=0)b -- 表b:进行变量初始化,固定写法。
- 另一种实现排序的方式
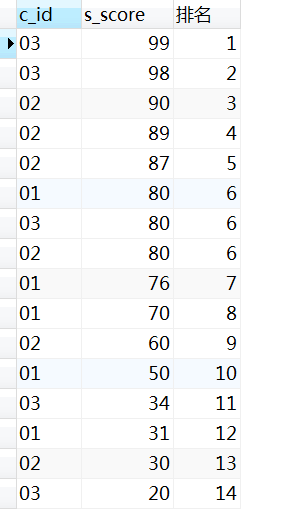
select
t1.c_id,
t1.s_score-- 成绩
,(select count(distinct t2.s_score) -- 排名从1开始
from Score t2
where t2.s_score >= t1.s_score) 排名 -- 在t2分数大的情况下,统计t2的去重个数
from Score t1
group by t1.c_id, t1.s_score
order by t1.s_score desc; -- 分数降序排列
2.31 题目31:查询各科成绩前三名的记录—比较综合,多看
- 采用union可以实现,即将各科分别筛选出来再进行union合并,但是当科目特别多时,会比价耗时,所以采用自连接的方式进行筛选。
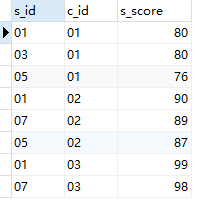
select
a.s_id
,a.c_id
,a.s_score -- a表的成绩
from Score a
join Score b
on a.c_id = b.c_id
and a.s_score <= b.s_score -- 判断a的分数小于等于b的分数,要带上等号
group by 1,2,3
having count(b.s_id) <= 3 -- b中的个数至少有3个,应对分数相同的情形
order by 2, 3 desc; -- 课程(2)的升序,成绩(3)的降序
2.32 题目32:查询每门课被选修的学生数
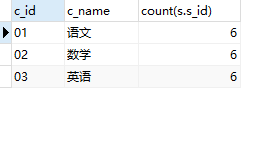
select
c.c_id
,c.c_name
,count(s.s_id)
from Course c
join Score s
on c.c_id = s.c_id
group by 1,2;
2.33 题目33:查询出只有两门课程的全部学生的学号和姓名
SELECT
t1.s_id
,t1.s_name
FROM
student t1
JOIN score t2 ON t1.s_id=t2.s_id
GROUP BY 1,2
HAVING COUNT(t2.s_score)=2;
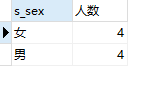
2.34 题目34:查询男女生人数
select
s_sex
,count(s_sex) as `人数`
from Student
group by s_sex;
2.35 题目35:查询名字中含有风字的学生信息
-- 模糊匹配:在两边都加上了%,考虑的是姓或者名字含有风
select * from Student where s_name like "%风%";
![]()
2.36 题目36:查询同名同性的学生名单,并统计同名人数
select
a.s_name
,a.s_sex
,count(*)
from Student a -- 同一个表的自连接
join Student b
on a.s_id != b.s_id -- 连接的时候不能是同一个人:学号保证,每个人的学号是唯一的,其他字段都可能重复
and a.s_sex = b.s_sex -- 性别相同
and a.s_name = b.s_name -- 名字相同
group by 1,2;
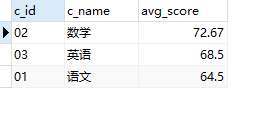
2.37 题目37:查询每门课程的平均成绩,结果按平均成绩降序排列;平均成绩相同时,按课程编号c_id升序排列
select
c.c_id
,c.c_name
,round(avg(sc.s_score),2) avg_score
from Score sc
join Course c
on sc.c_id = c.c_id
group by 1,2
order by 3 desc, c.c_id; -- 指定字段和排序方法
2.38 题目38:查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
select
sc.s_id
,s.s_name
,round(avg(sc.s_score),2) avg_score
from Score sc
join Student s
on sc.s_id = s.s_id
group by sc.s_id,s.s_name
having avg_score >= 85;
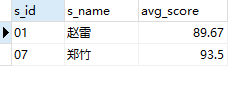
2.39 题目39:查询所有学生的课程及分数(均分、总分)情况
select
s.s_id
,s.s_name
,sum(case c.c_name when '语文' then sc.s_score else 0 end) as '语文' -- 语文分数
,sum(case c.c_name when '数学' then sc.s_score else 0 end) as '数学'
,sum(case c.c_name when '英语' then sc.s_score else 0 end) as '英语'
,round(avg(sc.s_score),2) as '平均分' -- 每个人的平均分
,sum(sc.s_score) as '总分' -- 每个人的总分
from Student s
left join Score sc
on s.s_id = sc.s_id
left join Course c
on sc.c_id = c.c_id
group by s.s_id, s.s_name; -- 学号和姓名的分组
2.40 题目40:查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
SELECT
t1.s_id,
t1.s_name,
t1.s_sex,
t1.s_birth,
t3.c_name,
t3.c_id,
MAX(t2.s_score)
FROM
student t1
JOIN score t2 ON t1.s_id = t2.s_id
JOIN course t3 ON t2.c_id = t3.c_id
JOIN teacher t4 ON t3.t_id = t4.t_id
WHERE
t4.t_name = '张三';

2.41 题目41:查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩—比较综合,多看!一个表自连
- 3个字段同时在一个表中,所以我们可以通过一个表Score的自连接来实现查出。
select
a.s_id
,a.c_id
,a.s_score
from Score a
join Score b
on a.c_id != b.c_id
and a.s_score = b.s_score
and a.s_id != b.s_id
group by 1,2,3;
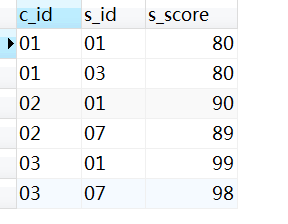
2.42 题目42:题目的要求就是找出每门课的前2名同学—多看,比较综合,解决前几名排序的问题
- 解决前几名排序的问题,特别好的方法!
SELECT
a.c_id,
a.s_id,
a.s_score
FROM
Score a
WHERE
( SELECT count( 1 ) -- count(1)类似count(*):统计表b中分数大的数量
FROM Score b WHERE b.c_id = a.c_id -- 课程相同
AND b.s_score >= a.s_score ) <= 2 -- 前2名
ORDER BY
a.c_id;
2.43 题目43:统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
SELECT
c_id,
COUNT( s_id ) num
FROM
score
GROUP BY
c_id
HAVING
COUNT( s_id ) > 5
ORDER BY
COUNT( s_id ) DESC, c_id;
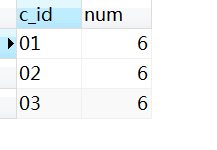
2.44 题目44:检索至少选修两门课程的学生学号
SELECT
s_id,
count(*) num
FROM
Score
GROUP BY
s_id
HAVING
count(*) >= 2;
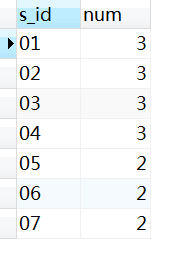
2.45 题目45:查询选修了全部课程的学生信息
select * -- 3、s_id对应的学生信息
from Student
where s_id in(select s_id -- 2、最大课程数对应的s_id
from Score
group by s_id
having count(*)=(select count(*) from Course) -- 1、全部课程数
)
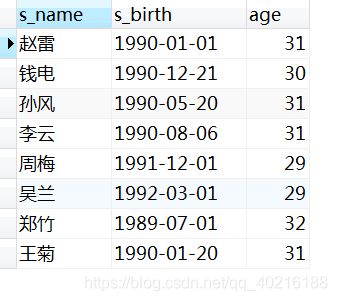
2.46 题目46:查询各学生的年龄:按照出生日期来算,当前月日 < 出生年月的月日则,年龄减1
select
s_name
,s_birth
,date_format(now(), '%Y') - date_format(s_birth, '%Y') - (case when date_format(now(), '%m%d') < date_format(s_birth, '%m%d') then 1 else 0 end) as age -- 当前日期大,说明已经过生了,年龄正常;反之说明今年还没有到年龄-1
from Student;
2.47 题目47:查询本周过生日的学生
select * from Student where week(date_format(now(),'%Y%m%d')) = week(s_birth); -- 方式1
select * from student where yearweek(s_birth) = yearweek(date_format(now(),'%Y%m%d')); -- 方式2

2.48 题目48:查询下周过生日的学生
select * from Student where week(date_format(now(),'%Y%m%d')) + 1= week(s_birth);
- 边界问题
如果现在刚好的是今年的最后一个周,那么下周就是明年的第一个周,我们如何解决这个问题呢??改进后的脚本:
select * from Student
where mod(week(now()), 52) + 1 = week(s_birth);
当现在刚好是第52周,那么mod函数的结果是0,则说明出生的月份刚好是明年的第一周
2.49 题目49:查询本月过生的同学
select * from Student where month(date_format(now(), '%Y%m%d')) = month(s_birth);

2.50 题目50:查询下月过生的同学
select * from Student
where month(date_format(now(), '%Y%m%d')) + 1= month(s_birth);
- 边界问题
假设现在是12月份,那么下个月就是明年的1月份,我们如何解决???将上面的代码进行改进:
select * from Student
where mod(month(now()),12) + 1 = month(s_birth);
- 如果现在是12月份,则mod函数的结果是0,说明生日刚好是1月份