Hive-入门学习之 hive 简介和安装 (1)
1 Hive 简介
1.1 hive 是什么
是由 Facebook 开源用于解决海量结构化日志的数据统计(海量的结构化数据的运算分析) .
是基于 hadoop 的一个数据仓库工具(服务性的软件) ,可以将结构化的数据文件映射为一张表 ,并提供类似SQL查询 .
本质是将 Hive SQL 转化成 MapReduce 程序或者 spark 程序 .
1.2 Hive架构原理
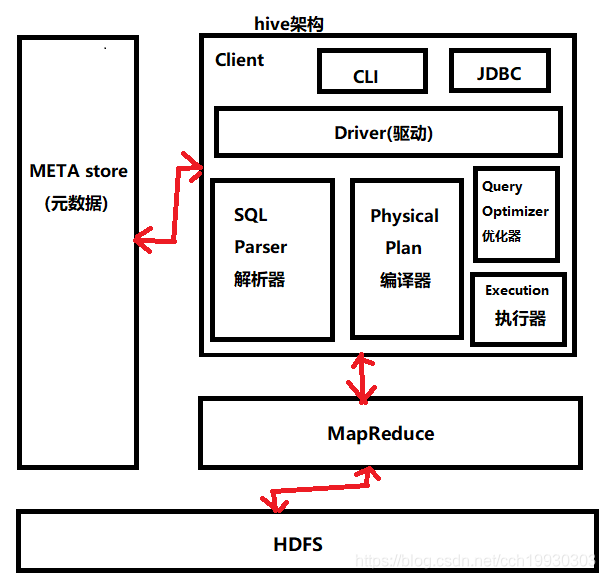
1.2.1 META store : 元数据
元数据包括 : 表名 / 表所属的数据库 (默认是 default ) / 表的拥有者(表存储的节点) / 列或分区字段 / 表的类型(是否是外部表)
表的数据所在目录等;
默认存储在自带的 derty 数据库中 ,推荐使用 MySQL 存储 Metastore
1.2.2 用户接口 : Client
CLI (hive shell) JDBC/ODBC(java 访问 hive) WEBUI(浏览器访问 hive)
1.2.3 驱动器 : Driver
(1) 解析器(SQL Parser) : 将 SQL 字符串转换成抽象语法树 AST ,这一步一般都用第三方工具库完成,
比如 antlr : 对 AST 进行语法分析 ,比如表是否存在, 字段是否存在.SQL 语义是否有误.
(2) 编译器( PhysicalPlan ) : 将 AST 编译生成逻辑执行计划.
(3) 优化器( Query Optimizer ) : 对逻辑执行计划进行优化.
(4) 执行器( Execution ) : 把逻辑执行计划转换成可以运行的物理计划 . 对于 hive 来说 ,就是 MR/Spark .
1.2.4 Hadoop
使用 HDFS 进行存储 ,yarn 资源调度 ,使用 MAPReduce 进行计算 .
1.3 基本流程/原理如下 :
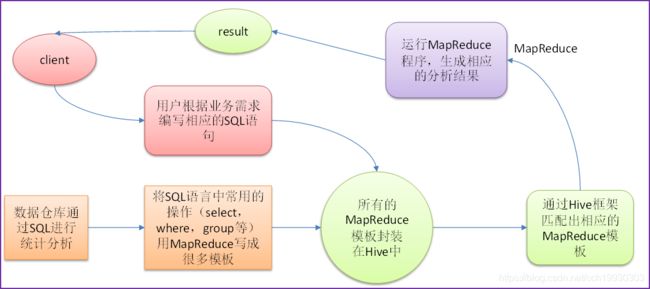
- Hive 处理的数据存储在 HDFS
- Hive 分析数据底层的实现是 MapReduce / spark (分布式运算框架)
- 执行程序一下在 Yarn 上(也可以运行在本地上, 速度回快一点)
所以使用 Hive 时,需要将 hdfs 和 yarn 开启,使其处于运行状态
1.4 Hive 和数据库比较
Hive不是数据库 ,是基于 hadoop 的一个数据仓库工具 / 数据处理工具 ,本质是将 Hive SQL 转化成 MapReduce 程序或者 spark 程序 .
Hive 和数据库除了有类似的查询语言外 ,再没其他类似之处 .
数据库可以用在 Online 的应用中 ,但是 Hive 是为数据仓库而设计的.
1.4.1 查询语言
由于 SQL (结构化查询语言)被广泛的应用在数据仓库中 ,因此专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL .
1.4.2 数据存储位置
Hive 是建立在 Hadoop 之上的 ,所有 Hive 的数据都是存储在 HDFS 中的 . 而数据库则可以将数据保存在块设备或
本地文件系统中 .
1.4.3 数据更新
因为 Hive 是针对数据仓库应用设计的 ,而数据仓库的内容是读多写少的 . 所以, Hive中不建议对数据的改写, 所有的数据都是在
加载的时候就确定好的 . 而数据库中的数据通常是需要经常进行修改的 ,因此可以使用 insert into..values 和 update..set .
1.4.4 索引
Hive 在加载数据的过程中不会对数据进行任何处理, 甚至不会对数据进行扫描 ,因此也没有对数据中的某些 key 建立索引.
Hive 要访问数据中满足条件的特定值时 ,需要暴力扫描整个数据 , 因此访问延迟较高 , 这决定了 Hive 不适合在线数据查询.
由于 MAPReduce 的引入 ,Hive 可以并行访问数据 ,因此即便没有索引 ,对于大数据量的访问 ,Hive 仍然可以体现出优势 .
数据库通常针对一个或多个列建立索引 ,因此对于少量的特定条件的数据的访问 ,数据库可以有很高的效率 , 较低的延迟 .
1.4.5 执行
Hive 中大多数查询的执行是通过 Hadoop 提供的 MAPReduce 来实现的 .
数据库通常有自己的执行引擎.
1.4.6 执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。
1.4.7 数据库规模
Hive 建立在集群上并可以利用 MAPREduce 进行并行计算 ,因此可以支持很大规模的数据.
数据库可以支持的数据规模较小 .
Hive 是一个数据仓库工具(服务性质软件) ,并不是一个数据库. 处理分析大量的静态的结构化数据 /报表 等 .
1.4.8 可扩展性
由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的(世界上最大的Hadoop 集群在 Yahoo!,2009年的规模在4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右。
1.5 Hive 的优缺点
1.5.1 优点
- 操作接口采用类SQL语法, 提供快速开发的能力(简单,容易上手)
- 避免了去写 MapReduce ,减少开发人员的学习成本
- Hive 的执行延迟比较高, 因此Hive 常用于数据分析, 对实时性要求不高的场合 .
- Hive的优势在于处理大数据 ,在处理小数据上没有优势,因为Hive的执行延迟比较高.
- Hive 支持用户自定义函数 ,用户可以根据自己的需求来实现自己的函数 .
Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
1.5.2 缺点
- Hive的HQL表达能力有限
- Hive的效率比较低(在集群中运算 用 47s 左右 ,如果在本地运算的话速度 3s 左右 == > 小数据运算)
2 Hive 安装前准备 : 启动 hdfs 和 yarn , mysql 环境准备
2.1 正常启动 HDFS 和 yarn
[root@linux03 ~]# start-all.sh // 一键启动 hdfs 和 yarn
2.2 启动 mysql 并登录 mysql
[root@linux03 bin]#service mysqld start
Starting mysqld: [ OK ]
[root@linux03 bin]#mysql -uroot -p1234562.3 配置mysql的开机自启动服务,开放远程连接权限
// 开启开机自启动服务
[root@linux03 bin]# service mysqld start
Starting mysqld: [ OK ]
set password for 'root'@'m01'= password('root');
// 输入mysql的账号和密码
mysql -uroot -p12345
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=1;
// 开启远程连接权限
mysql > grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
mysql > flush privileges;2.4 授权完毕后 ,测试一下是否成功 ,在 window 上用 Navicat 连接一下看是否能成功
[root@linux03 bin]# netstat -nltp | grep 3306
tcp6 0 0 :::3306 :::* LISTEN 1213/mysqld // 远程开启成功
连接成功后 ,有以下信息 ;
3 Hive 安装
3.1 上传 hive 的安装包 ,解压
[root@linux03 bin]# rz // 上传安装包
[root@linux03 bin]# tar -zxvf apache-hive-3.1.2.tar.gz // 解压安装包
3.2 /opt/apps/apache-hive-3.1.2/conf 目录下
[root@linux03 conf]# mv hive-env.sh.template hive-env.sh // 将环境配置文件改名
[root@linux03 conf]# vi hive-env.sh // 修改配置文件

3.3 修改 hive-site.xml 配置文件
javax.jdo.option.ConnectionURL
jdbc:mysql://doit03:3306/hive?createDatabaseIfNotExist=true&useSSL=false
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.metastore.warehouse.dir
/user/hive/warehouse
hive.exec.scratchdir
/user/hive/tmp
hive.querylog.location
/user/hive/log
hive.server2.thrift.port
10000
hive.server2.thrift.bind.host
0.0.0.0
hive.server2.webui.host
0.0.0.0
hive.server2.webui.port
10002
hive.server2.long.polling.timeout
5000
hive.server2.enable.doAs
true
datanucleus.autoCreateSchema
false
datanucleus.fixedDatastore
true
hive.execution.engine
mr
3.4 修改 /opt/apps/hadoop-3.2.1/etc/hadoop 目录下的 core-site.xml 文件
[root@linux03 hadoop]# vi core-site.xml // 进入编辑模式 ,添加以下内容 ,保存退出
在
dfs.permissions.enabled
false
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
3.5 拷贝一个 mysql 的 jdbc 驱动 jar 包到 hive 的 lib 目录下
[root@linux03 lib]# rz // 将一下 jar 包导入到 hive 的 lib 目录下
mysql-connector-java-5.1.39.jar
3.6 重启 hadoop
[root@linux03 lib]# stop-all.sh
[root@linux03 lib]# start-all.sh
3.7 将 hive/lib/guava-19.0-jre.jar删除 ,将hadoop/share/hadoop/commons/lib/guava-27.0-jre.jar 复制到hive的lib下
3.8 初始化 hive 的元数据库 , /opt/apps/apache-hive-3.1.2/bin 目录下操作
hive --service metastore & //启动元数据服务 ,对接 spark ,在 spark 启动时 ,如果元数据服务不开启的话 ,spark 启动后会修改 hived VERSION(mysql 数据库中的version表里面的版本号) ==> 不使用/开启 spark 时 ,不启动这个服务没有关系 .
./schematool -initSchema -dbType mysql // 在mysql 中多一个 hive 数据库 ,记录元数据信息
3.9 在 linux 系统中配置 hive 的环境变量 ,配置以后 ,hive 可以在任意目录下启动
[root@linux03 lib]# vi /etc/profile
export HIVE_HOME=/opt/apps/apache-hive-3.1.2 // 添加 HIVE_HOME ,输入hive 安装包的绝对路径
在 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin 后面添加:$HIVE_HOME/bin
Esc ==> :wq! (保存退出)
[root@linux03 lib]# source /etc/profile
[root@linux03 lib]#reboot // 重启虚拟机 ,然后将 hdfs 和 yarn 启动
输入 hive 直接连接 mysql,进入 hive 交互窗口 ,查询的结果没有框 ,数据展示的时候影响观感
[root@linux03 lib]# hive
hive> show databases; // 查看数据库情况
4 HiveJDBC访问
开启 Hiveserver2 服务 ,通过 beeline 连接 mysql ,查询出的结果有框 ,展示数据的时候方便观看
4.1 开启 hive2 的服务 (quit hive的客户端模式)
[root@linux03 bin]# hiveserver2 & // 启动 hiveserver2 服务 (& 代表在后台运行)
SLF4J: Class path contains multiple SLF4J bindings.
.........
2020-09-01 04:07:16,448 WARN [main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
Hive Session ID = b192abe0-f053-47d5-9a61-31f48399ab5a
Hive Session ID = 5e2ba8b7-0f00-4835-9558-34efac6b27ad
Hive Session ID = 9630c11f-81a5-4986-876e-94c965400eef// 可以Ctrl +C退出( hiveserver2 在后台运行 ) ,并克隆一个机器,在克隆的机器上进行其他的操作
4.2 查看 10000 10002 端口启动情况
[root@linux03 bin]# netstat -nltp | grep 10000 // 查看10000端口启动情况
tcp6 0 0 :::10000 :::* LISTEN 3433/java //可以使用 shell 客户端 JDBC 远程连接[root@doit03 lib]# netstat -nltp | grep 10002 // 查看10002端口启动情况
tcp6 0 0 :::10002 :::* LISTEN 3308/java //可以使用 shell 客户端 JDBC 远程连接
[root@linux03 bin]# jps // 查看进程
2672 NodeManager
2532 ResourceManager
2021 NameNode
3111 QuorumPeerMain
2168 DataNode
3433 RunJar // hive
4.3 启动 beeline ,进入到 hive 交互窗口 (可以克隆一个 linux03 机器操作以下数据 )
[root@linux03 bin]# beeline
.........
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.2 by Apache Hive
beeline> !connect jdbc:hive2://linux03:10000 // 连接 hiveserver2
Connecting to jdbc:hive2://linux03:10000
Enter username for jdbc:hive2://linux03:10000: root // 连接数据库账号 , 然后 enter
Enter password for jdbc:hive2://linux03:10000: // 直接 enter 确定 ,不用输密码
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://linux03:10000> show databases; //还可以进行其他操作 ,use database;show tables;select.............
+----------------+
| database_name |
+----------------+
| db_xiaoqq |
| default |
| linux03 |
+----------------+3 rows selected (1.712 seconds)