MAE(Masked Autoencoders) 详解
MAE详解
- 0. 引言
- 1. 网络结构
-
- 1.1 Mask 策略
- 1.2 Encoder
- 1.3 Decoder
- 2. 关键问题解答
-
- 2.1 进行分类任务怎么来做?
- 2.2 非对称的编码器和解码器机制的介绍
- 2.3 损失函数是怎么计算的?
- 2.4 bert把mask放在编码端,为什么MAE加在解码端?
- 3. 总结
0. 引言
masked autoencoders (MAE) 是用于CV的自监督学习方法,优点是扩展性强的(scalable),方法简单。在MAE方法中会随机mask输入图片的部分patches,然后重构这些缺失的像素。MAE基于两个核心设计:(1)不对称的(asymmetric)编码解码结构,编码器仅仅对可见的patches进行编码,不对mask tokens进行任何处理,解码器将编码器的输出(latent representation)和mask tokens作为输入,重构image;(2)使用较高的mask比例(如75%)。MAE展现了很强的迁移性能,在ImageNet-1K上取得了best accuracy(87.8%),且因为方法简单,可扩展性极强(scalable)。
下图展示了MAE在ImageNet验证集上的重建结果。对于每个三元组,左边的图像是被遮挡的,中间的图像是MAE重建的,右边的图像是实际的。其中掩蔽率为80%,即在196个patch中只剩下39个对模型可见。可以看出,经过MAE还原后的图像可以大致将原始图像还原出来。
论文名称:Masked Autoencoders Are Scalable Vision Learners
论文地址:https://arxiv.org/abs/2111.06377
代码地址:https://github.com/facebookresearch/mae
1. 网络结构
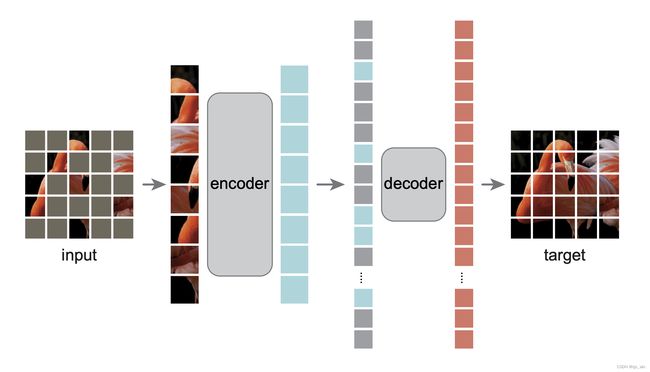
MAE 模型整体网络结构如下所示。包含一个encoder模块和一个decoder模块。
首先,输入图像被按照patch_size分割成patch集合。然后,patch集合中的一个大的随机子集被mask,没有被mask的patch会被输入encoder模型得到编码补丁。随后,编码补丁与masked token(被mask的部分,其中每个masked token都是共享的、可被学习的向量)被合并输入decoder。经decoder得到还原后的图案。
1.1 Mask 策略
首先,沿袭 ViT 的做法,将图像分成一块块(ViT 中是 16x16 大小)不重叠的 patch,然后使用服从均匀分布(uniform distribution)的采样策略对这些 patches 随机采样一部分,同时 mask 掉余下的另一部分。被 mask 掉的 patches 占所有 patches 的大部分(实验效果发现最好的比例是 75%),它们不会输入到 Encoder。
OK,策略很简单,那么这样做有什么好处呢?
首先,patch 在图像中是服从均匀分布来采样的,这样能够避免潜在的“中心归纳偏好”(也就是避免 patch 的位置大多都分布在靠近图像中心的区域);其次,采用高掩码比例(mask 掉图中大部分 patches)能够防止模型轻易地根据邻近的可见 patches 推断(原文是 extrapolation,外推,这词有点高级…)出这些掩码块;最后,这种策略还造就了稀疏的编码器输入,因为 Encoder 只处理可见的 patches,于是能够以更低的代价训练较大规模的 Encoder,因为计算量和内存占用都减少了。
虽然 mask 策略好像挺简单的,但却是至关重要的一个部分,因为其决定了预训练代理任务是否具有足够的挑战性,从而影响着 Encoder 学到的潜在特征表示 以及 Decoder 重建效果的质量。
1.2 Encoder
记住最重要的一点,Encoder 仅处理可见(un-masked)的 patches。Encoder 本身可以是 ViT 或 ResNet(其它 backbone 也 ok,就等你去实现了,大神给了你机会),至于如何将图像划分成 patch 嘛,使用 ViT 时的套路是这样的:
作者首先将图片数据 X ∈ R H × W × C X\in R^{H\times W \times C} X∈RH×W×C 按照 patch_size 进行切分并进行一维展平,得到数据 X ∈ R N × ( P 2 × C ) X\in R^{N\times (P^2\times C)} X∈RN×(P2×C) 。其中, P P P 表示 patch_size; N N N 表示图片被切分为多少块,即 N = H × W P 2 N=\frac{H\times W}{P^2} N=P2H×W 。然后,这批数据经过线性变换后与原始图像的位置编码进行合并(并在首部添加类别编码 class embedding)。
由于 un-masked patches 占所有 patches 的少数,计算消耗和空间需求都减少了,因此可以训练很大的 Encoder。
1.3 Decoder
Decoder 不仅需要处理经过 Encoder 编码的 un-masked 的 tokens,还需要处理 masked tokens。但请注意,masked token 并非由之前 mask 掉的 patch 经过 embedding 转换而来,而是可学习的。所有 masked patches 都共享的1个向量,对,仅仅就是1个!
那么你会问:这样如何区分各个 masked patch 所对应的 token 呢?
别忘了,我们还有 position embedding 嘛!如同在 Encoder 中的套路一样,这里对于 masked token 也需要加入位置信息。position emebdding 是每个 masked patch 对应1个,shape 是 ( N ′ , d i m ) (N',dim) (N′,dim),其中 N ′ N' N′ 是 masked patch 的数量。但 masked token 只有1个怎么办是不是?简单粗暴——“复制”多份即可,使得每个 masked patch 都对应1个 masked token,这样就可以和 position embedding 进行相加了。
另外,Decoder 仅仅是在预训练任务为了重建图像而存在,而我们的下游任务形式多种多样,因此实际应用时很可能没 Decoder 什么事了。所以,Decoder 的设计和 Encoder 是解耦的,Decoder 可以设计得简单、轻量一些(比 Encoder 更窄、更浅。窄:对应通道数;浅:对应深度),毕竟主要学习潜在特征表示的是 Encoder。
这样,尽管 Decoder 要处理的 token 很多(全量token,而 Encoder 仅处理 un-masked 的部分),但其本身轻量,所以还是能够高效计算。再结合 Encoder 虽然本身结构重载(相对 Decoder 来说),但其处理的 token 较少,这样,整体架构就十分 efficient 了!
2. 关键问题解答
2.1 进行分类任务怎么来做?
看起来 MAE 是一个图像还原的项目,那么如何使用它来做图像分类任务呢?
虽然 MAE 整体结构是图像还原项目,但是也可以用来做图像分类。MAE 采用先预训练然后再微调的方法得到分类模型。具体操作步骤如下:
- 首先,使用
MAE模型进行训练来得到预训练好的模型。 - 然后,将
Encoder部分提取出来。 - 最后,在后面加上全连接层进行分类。
整体而言:使用预训练模型得到一个可以提取“完整”特征的Encoder模型,然后在后面加上线性层进行分类。
2.2 非对称的编码器和解码器机制的介绍
非对称是说编码器看到的和解码器看到的东西是不一样的,这里编码器只看到那些可见的块,解码器拿到编码器的输出之后,就去重构那些被遮挡住的块- 为什么使用这些非对称的架构,因为大量的块都被遮住了,这样的话编码器只用看可见的那些块,可以极大地减轻计算的开销,也可以使得内存更小一点
2.3 损失函数是怎么计算的?
MAE 预训练任务的目标是重建像素值,并且仅仅是 masked patches 的像素值,也就是仅对 mask 掉的部分计算 loss,而 loss 就是很大众的 MSE。为何仅计算 mask 部分的 loss?实验结果发现这样做模型的性能会更好,而如果对所有 patches 都计算 loss 的话会掉点。
那么模型是如何去预测 masked patches 的像素值并计算 loss 的呢?具体来说,就是:
在 Decoder 解码后的所有 tokens 中取出 masked tokens(在最开始 mask 掉 patches 的时候可以先记录下这些 masked 部分的索引),将这些 masked tokens 送入全连接层,将输出通道映射到1个 patch 的像素数量(PxPxC),也就是输出的 shape 是:(B,N’,PxPxC),其中的每个值就代表预测的像素值。最后,以之前 mask 掉的 patches 的像素值作为 target,与预测结果计算 MSE loss。
另外,作者提到使用归一化的像素值作为 target 效果更好,能够提升学到的表征的质量。这里的归一化做法是:计算每个 patch 像素值的均值与标准差,然后用均值与标准差去归一化对应的 patch 像素。
代码如下所示:
def forward_loss(self, imgs, pred, mask):
"""
imgs: [N, 3, H, W]
pred: [N, L, p*p*3]
mask: [N, L], 0 is keep, 1 is remove, mask记录了哪些patch被mask
"""
target = self.patchify(imgs)
if self.norm_pix_loss:
mean = target.mean(dim=-1, keepdim=True)
var = target.var(dim=-1, keepdim=True)
target = (target - mean) / (var + 1.e-6)**.5
loss = (pred - target) ** 2
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return loss
2.4 bert把mask放在编码端,为什么MAE加在解码端?
bert在预训练中输入到encoder的里面有mask,但是在进行下游任务微调时没有mask,这样会使预训练和下游任务的微调存在一个gap,因为输入不一致会导致最终输出效果有影响,bert为了消除这个影响会对15%的词汇有8:11的比例,只有8份是真正mask,这样就缩小了两者的gap——bert是在缩小这个差距,MAE是在试图消除这个影响——让预训练和下游任务微调保持一致。
MAE在decoder中加入了mask,是因为在下游任务只使用了encoder,所以在预训练和下游任务都不会出现mask——但是!在预训练时MAE看到的是25%patch,在下游任务看到的是100%patch,其实引入了另外一种gap。
3. 总结
MAE的算法还是非常简单的,就是利用vit来做和BERT一样的自监督学习,vit已经做了类似的事情了,但是本文在此基础之上提出了三点
- 第一点是需要盖住更多的块,使得剩下的那些块,块与块之间的冗余度没有那么高,这样整个任务就变得
复杂一点(以更少的可见模块去预测更多不可见的模块) - 第二个是使用一个transformer架构的解码器,直接还原原始的像素信息,使得整个
流程更加简单一点(算法的整体思想与模型结构是简单的) - 第三个是加上vit工作之后的各种技术,使得它的训练更加
鲁棒一点
以上三点加起来,使得MAE能够在ImageNet-1k数据集上使用自监督训练的效果超过了之前的工作。
如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。