CBAM:Convolutional Block Attention Module
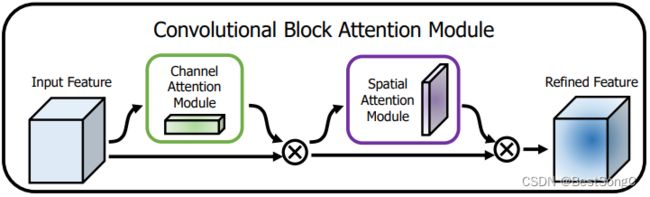
CBAM(Convolutional Block Attention Module)是一种深度学习领域的注意力机制,旨在增强卷积神经网络对图像特征的建模和表示能力。CBAM引入了通道和空间两种不同的注意力机制,使模型能够动态调整特征图的权重,以适应不同的任务和场景。

参考论文:https://arxiv.org/pdf/1807.06521.pdf
背景
深度学习中的卷积神经网络在图像分类、目标检测、图像分割等计算机视觉任务中取得了显著的成功。然而,随着网络结构的不断深化和任务复杂性的增加,传统的CNN模型在一些情况下仍然难以捕捉到图像中的关键特征。这可能是因为传统CNN在处理图像特征时对不同通道和空间位置的信息处理是均等的,忽略了不同通道和空间位置之间的差异性。CBAM的诞生正是为了应对这一挑战。
结构
CBAM模块由两部分组成,分别是通道注意力和空间注意力。以下是CBAM模块的主要组成部分:
(1)通道注意力(Channel Attention)
通道注意力机制用于自适应地调整不同通道的特征响应,以提高对不同特征的敏感性。通道注意力包括以下步骤:
平均池化:对每个通道的特征图进行全局平均池化,得到每个通道上的全局特征。
全连接层:将全局特征映射到一个新的特征空间。这个全连接层负责学习每个通道的权重,以确定其在最终的特征响应中的贡献。
预处理:在使用全连接层输出之前,对其进行一些适当的处理,如使用激活函数。这有助于限制权重的范围并增加模型的非线性表示能力。
广播与相乘:最后通过将通道特定的权重应用到原始的特征图上,获得了自适应调整后的特征响应。这个过程涉及将学习到的通道权重广播到每个空间位置,然后将它们应用到对应的通道特征上。
(2)空间注意力(Spatial Attention)
空间注意力机制用于自适应地调整不同空间位置的特征响应,以提高对不同位置的敏感性。空间注意力包括以下步骤:
最大池化:首先对每个通道的特征图进行全局最大池化,得到每个通道上的最大响应值。
全连接层:将全局最大响应值映射到一个新的特征空间。这个全连接层负责学习每个空间位置的权重,以确定其在最终的特征响应中的贡献。
预处理:与通道注意力类似,空间注意力中的全连接层输出也经过适当的处理,如激活函数。
广播与相乘:最后通过将空间位置特定的权重应用到原始的特征图上,获得了自适应调整后的特征响应。这个过程涉及将学习到的空间位置权重广播到每个通道特征上,然后将它们应用到对应的空间位置上。
通道注意力和空间注意力分别关注了不同方面的特征响应,通道注意力关注通道之间的关系,而空间注意力关注空间位置的关系。通道注意力通过学习每个通道的权重,使模型能够自适应地调整通道特征的重要性,增强对不同特征的建模能力。空间注意力通过学习每个空间位置的权重,使模型能够自适应地调整空间位置特征的重要性,增强对不同位置的建模能力。通过将通道注意力和空间注意力相乘,得到最终的自适应特征响应,这样模型可以在通道和空间维度上更好地捕捉和表示图像特征。
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class ChannelAttentionModule(nn.Module):
def __init__(self, c1, reduction=16):
super(ChannelAttentionModule, self).__init__()
mid_channel = c1 // reduction
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Linear(in_features=c1, out_features=mid_channel),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(in_features=mid_channel, out_features=c1)
)
self.act = nn.Sigmoid()
# self.act=nn.SiLU()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0), -1)).unsqueeze(2).unsqueeze(3)
maxout = self.shared_MLP(self.max_pool(x).view(x.size(0), -1)).unsqueeze(2).unsqueeze(3)
return self.act(avgout + maxout)
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.act = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.act(self.conv2d(out))
return out
class CBAM(nn.Module):
def __init__(self, c1, c2):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(c1)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
在YOLOv5模型中配置模块:
# Parameters
nc:3 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
#- [5,6, 7,9, 12,10] # P2/4
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [c=3,64*0.5=32,3]
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, CBAM, [1024]], #9
[-1, 1, SPPF, [1024,5]], #10
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, CBAM, [256]], #19
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 22 (P4/16-medium) [256, 256, 1, False]
[-1, 1, CBAM, [512]],
[-1, 1, Conv, [512, 3, 2]], #[256, 256, 3, 2]
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large) [512, 512, 1, False]
[-1, 1, CBAM, [1024]],
[[19, 23, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
在配置文件中,Backbone和Head中均包含CBAM模块,在训练时加入CBAM训练更稳定,因此一般推荐在Backbone中SPPF前面添加以及在输出预测层前添加
应用领域
CBAM注意力模块已经在多个计算机视觉任务中取得了显著的成功,以下是一些主要应用领域:
- 图像分类:CBAM模块可以嵌入到CNN架构中,用于提高图像分类任务的性能。通过自适应特征调整,模型可以更好地捕获图像中不同通道和位置的特征。
- 目标检测:在目标检测任务中,CBAM模块可以应用于改进目标检测器的性能。通过引入通道和空间的自适应调整,CBAM可以增强目标检测器对不同目标尺寸和位置的敏感性,提高检测的准确性。
- 图像分割:在图像分割任务中,CBAM模块有助于提高分割模型对图像不同区域的关注度。这可以导致更准确的分割结果,尤其在复杂的场景中。
- 迁移学习:CBAM模块的自适应特征调整性质使其非常适合迁移学习。预训练的模型可以通过微调以适应不同的任务,而CBAM模块有助于提高模型性能,无需从头开始训练。
延伸方向
- 轻量化:目前CBAM模块在一些轻量级模型或嵌入式设备上的应用仍然有挑战,因为它引入了额外的计算和参数。未来的研究可以关注如何设计更轻量级的CBAM变体,以适应资源受限的环境。
- 多尺度和多模态:CBAM模块的设计主要针对单一尺度的图像,未来可以考虑如何扩展CBAM以处理多尺度和多模态数据。这将使CBAM更适用于更广泛的应用领域。
- 结合其他注意力机制:CBAM是通道和空间注意力的组合,未来的研究可以探索如何将CBAM与其他类型的注意力机制结合,以进一步提高模型的性能。
- 可解释性:CBAM的内部机制相对复杂,如何提高模型的可解释性仍然是一个重要的研究方向。理解CBAM如何决定通道和空间的权重以及如何将其应用于特征响应的过程将有助于更好地理解模型的决策。
总结
CBAM作为一种强大的注意力模块,为卷积神经网络的性能提升和特征建模提供了重要的工具。随着未来研究的不断发展,CBAM模块将继续在计算机视觉和其他领域中发挥关键作用,为解决复杂的模式识别和数据建模问题提供更好的解决方案。同时,CBAM的核心思想也将激发更多关于注意力机制和特征调整的研究,推动深度学习领域的发展。欢迎大家关注本博主的微信公众号 BestSongC,后续更多的资源如模型改进、可视化界面等都会在此发布。