ddia(5)----Chapter5.Replication
CHAPTER5. Replication
Replication means keeping a copy of the same data on multiple machines that connected via a network. There are several reasons of why we want to replicate data:
- To keep data geographically close to your users and reduce latency.
- To allow the system to continue working even if some of its parts have failed and increase availability.
- To scale out the number of machines that can serve read queries and increase read throughput.
Leaders and Followers
Each node that stores a copy of the database is called a replica. Every write to the database needs to be processed by every replica. The most common solution for this is called leader-based replication (also known as active/passive or master-slave replication).
- One of the replicas is designated the leader (also known as master or primary), other replicas are followers (read replicas, slaves, secondaries or hot standbys). Clients can query either the leader or followers, but writes are only accepted by the leader.
- When the leader writes new data to its database, it also sends the new data change to all of its followers as part of a replication log or change stream.

This mode is used in relational databases, such as MySQL, Oracle Data Guard, etc. and nonrelational databases, such as MongoDB, RethinkDB. Finally, leader-based replication is also used by distributed message brokers such as Kafka and RabbitMQ.
Synchronous Versus Asynchronous Replication
An important detail of a replicated system is whether the replication happens synchronously or asynchronously.

In this example, the replication to follower 1 is synchronous: the leader waits until follower 1 has confirmed that it received the write before reporting success to the user. The replication to follow 2 is asynchronous.
As we can see, there is a substantial delay before follower 2 processes the message. There are several reasons, for example, this follower is recovering from a failure, this system is operating near maximum capacity, or there are network problems.
| synchronous | asynchronous | semi-synchronous |
|---|---|---|
| The follower is guaranteed to have an up-to-date copy of the data. But the leader must block all writes and wait until the follower responds although the follower has crashed. | The most common mode. If the leader fails and is not recoverable, any writes that have not yet been replicated to followers are lost. But the leader can continue processing writes, even if all of its followers have fallen behind. | One of the followers is synchronous and the others are asynchronous. If a synchronous follower crashes, one of the asynchronous followers is make synchronous. |
Setting Up New Followers
We should ensure the newly added follower has an accurate copy of the leader’s data.
The data is always in flux, thus simply copying data files from one node to the new node makes sense. Locking the database to make the files consistent also goes against our goal of high availability.
Take a consistent snapshot of the leader’s database, and the snapshot is associated with an exact position in the leader’s replication log. Then copy the snapshot to the new follower node. When the follower has processed the backlog of data changes since the snapshot, we say it has caught up.
Handling Node Outages
We should keep the system as a whole running despite individual node failures and to keep the impact of a node outage as small as possible.
Follower failure: Catch-up recovery
Each follower keeps a log of the data changes in its local disk, the follower can easily recover the last transaction that was processed before the fault occurred. Thus, the follower can connect to the leader and request all the data changes that occurred during the time when the follower crashed.
Leader failure: Failover
When the leader has a failure, one of the followers needs to be promoted to be the new leader. This process is called failover. An automatic failover process usually consists of the following steps:
- Determining that the leader has failed. Most systems simply use a timeout to assume whether the leader is dead.
- Choosing a new leader.
- Reconfiguring the system to use the new leader. The system needs to ensure the old leader becomes a follower and recognizes the new leader.
Failover is fraught with things that can go wrong:
- If asynchronous replication is used, the new leader may not have received all the writes from the old leader before it failed. The most common solution is for the old leader’s unreplicated writes to be discarded. This solution may cause inconsistency. For example, the database used an autoincrementing counter to assign primary keys to new rows, and the new leader reused some primary keys that were also used in a Redis store. This resulted in inconsistency between MySQL and Redis.
- In certain fault scenarios, it could happen that two nodes both believe that they are the leader. This situation is called split brain. Data is likely to be lost or corrupted.
- Longer timeout means a long time to recover the leader’s fails. A shorter timeout could be unnecessary failover failovers.
Implementation of Replication Logs
Statement-based replication
In the simplest case, the leader logs every write request (INSERT, UPDATE, DELETE) that it executes and sends that statement log to its followers. This approach has many disadvantages:
- Some statements, such as NOW(), RAND(), are likely to generate a different value on different replicas.
- If statements use an autoincrementing column, they must be executed in exactly the same order on each replica, or else they may have a different effect.
Although the leader can replace any nondeterministic function calls with a fixed return value when the statement is logged, there are so many edge cases so we prefer other methods.
Write-ahead log (WAL) shipping
This method seems like other other knowledge we discussed:
- In the case of a log-structured storage engine (see “SSTables and LSM-Trees”), this log is the main place for storage.
- In the case of a B-tree (see “B-Trees”), which overwrites individual disk blocks, every modification is first written to a write-ahead log so that the index can be restored to a consistent state after a crash.
Logical (row-based) log replication
An alternative is to use different log formats for replication and for the storage engine, this kind of replication log is called a logical log. A logical log for a relational database is usually a sequence of records describing writes to database tables at the granularity of a row:
- For an insert row, the log contains the new value of all columns.
- For a delete row, the log contains enough information to identify the row that was deleted, such as the primary key.
- For an update row, the log contains enough information to identify the row and the new value.
Trigger-based replication
Trigger-based replication has greater overheads than other replication methods, and is more prone to bugs and limitations than the database’s built-in replication. However, it has higher flexibility:
- It can only replicate a subset of the data.
- It can replicate from one kind of database to another.
Problems with Replication Lag
In a system that consists of mostly reads, we have an option: create many followers and distribute read requests across those followers.
If you read from an asynchronous follower, you may see different data from leader. But this inconsistency is just a temporary state, the follower will eventually catch up. This effect is called eventual consistency.
Sometimes, the delay between a write happening on the leader and the follower may be just a second, but in some cases, such as network error, this lag can be easily increased to several seconds.
Reading Your Own Writes

In this situation, we need read-after-write consistency, also known as read-your-writes consistency. There are various possible techniques to implement read-after-write consistency:
- When you read something that the user may have modified, read it from the leader.
- If things are potentially editable, read them from the leader.
- The client can remember the timestamp of its most recent write, the follower needs to ensure that it has all updates at least until that timestamp.
- If the replicas are distributed across multiple datacenters, any write request needs to be served by the datacenter that contains the leader.
Maybe your application supports access from multiple devices, such as a web browser and a mobile app. In this case, there are some new issues to consider:
- Remembering the timestamp of the user’s last update from another device becomes more difficult.
- If your replicas are distributed across different datacenters, there is no guarantee that connections from different devices will be routed to the same datacenter.
Monotonic Reads
Reading from asynchronous followers may cause the error as shown in the below figure, known as moving backward in time.

Monotonic reads guarantee eventual consistency, the user will not read older data after having previously read newer data. One way of achieving monotonic reads is to make sure that each user always makes their reads from the same replica (for example, the replica can be chosen based on the hash of the user ID).
Consistent Prefix Reads
This example violation of causality.
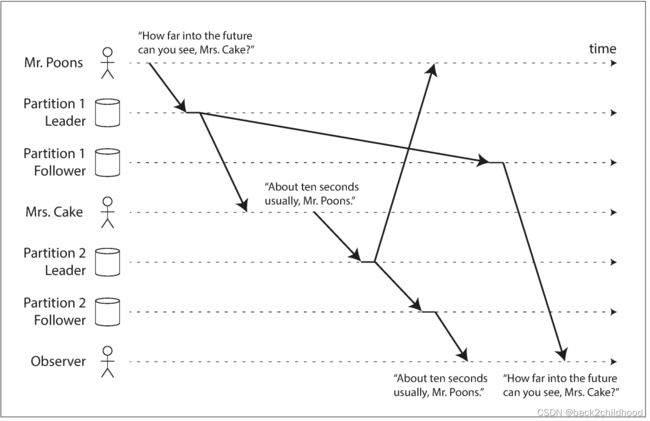
Preventing this kind of anomaly requires another type of guarantee: consistent prefix reads. This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order.
This is a particular problem in partitioned (sharded) databases because in many databases, different partitions operate independently, when a user reads from the database, they may see some older data.
One solution is to make sure that any writes that are causally related to each other are written to the same partition.
Solutions for Replication Lag
In a single-node system, transaction is a way for a database to provide stronger guarantees.
In a distributed system, transactions are too expensive in terms of performance and availability.
Multi-Leader Replication
In a single-leader system, if you can’t connect to the leader for any reason, you can’t write to the database. A natural extension of the leader-based replication model is to allow more than one node to accept write, as known to multi-leader configuration (also known as master-master or active/active replication). In this setup, each leader simultaneously acts as a follower to the other leaders.
Use Cases for Multi-Leader Replication
The benefits of multi-leader configuration rarely outweigh the added complexity, however, there are some situations in which this configuration is reasonable.
Multi-datacenter operation
In a multi-leader configuration, you can have a leader in each datacenter.

| single-leader configuration | multi-leader configuration | |
|---|---|---|
| Performance | Every write must go over the internet to the datacenter with the leader. This can add significant latency to writes. | Every write can be processed in the local datacenter and is replicated asychronously to the other datacenters. The interdatacenter network delay is hidden from users. |
| Tolerance of datacenter outages | If the datacenter with the leader fails, failover can promote a follower in another datacenter to be leader. | Each datacenter can run independently of the others, and the replication catches up when the failed data comes back online. |
| Tolerance of network problems | Sensitive to problems. | A temporary network interruption does not prevent writes being processed. |
Multi-leader configurations is often implemented with external tools, such as Tungsten Replicator for MySQL, BDR for PostgreSQL, and GoldenGate for Oracle.
Multi-leader replication has a big downside: the same data may be concurrently modified in two different datacenters, and those write conflicts must be resolved.
Multi-leader replication is often considered dangerous territory that should be avoided if possible.
Clients with offline operation
Another situation in which multi-leader replication is appropriate is if you have an application that needs to continue to work while it is disconnected from the internet.
For example, you need to be able to see your schedule on any device, regardless of whether your device currently has an internet connection. If you make any changes while you are offline, they need to be synced with a server and your other devices when the device is next online.
In this case, every device has a local database that acts as a leader (it accepts write requests), and there is an asynchronous multi-leader replication process (sync) between the replicas of your calendar on all of your devices.
From an architectural point of view, this setup is essentially the same as multi-leader replication between datacenters: each device is a “datacenter”.
Collaborative editing
Real-time collaborative editing applications allow several people to edit a document simultaneously.
If you want to guarantee that there will be no editing conflicts, the application must obtain a lock on the document before a user can edit it. However, for faster collaboration, you may want to make the unit of change very small (e.g., a single keystroke) and avoid locking.
Handling Write Conflicts
The biggest problem with multi-leader replication is that write conflicts can occur, which means that conflict resolution is required.
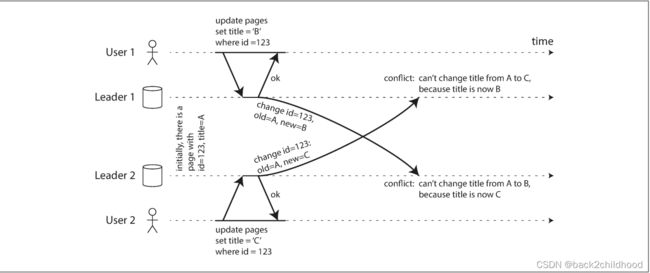
Synchronous versus asynchronous conflict detection
Although we can make the conflict detection synchronous, however, by doing so, you would lose the main advantage of multi-leader replication.
Conflict avoidance
The simplest strategy for dealing with conflicts is to avoid them: if the application can ensure that all writes for a particular record go through the same leader, then conflicts cannot occur.
However, sometimes you might want to change the designated leader for a record—perhaps because one datacenter has failed and you need to reroute traffic to another datacenter, or perhaps because a user has moved to a different location and is now closer to a different datacenter.
Converging toward a consistent state
The database must solve the write conflict problem in a convergent way, which means that all replicas must arrive at the same final value when changes have been replicated.
There are various ways of achieving convergent conflict resolution:
- Give each write a unique ID (e.g., a timestamp, a long random number, a UUID, or a hash of the key and value), pick the write with the highest ID as the winner, and throw away the other writes. If a timestamp is used, this technique is known as last write wins (LWW).
- Give each replica a unique ID, and let writes that originated at a highernumbered replica always take precedence over writes that originated at a lowernumbered replica. This approach also implies data loss.
Custom conflict resolution logic
As the most appropriate way of resolving a conflict may depend on the application.
That code may be executed on write or on read:
- On write:
As soon as the database system detects a conflict in the log of replicated changes, it calls the conflict handler. - On read:
When the application receives multiple versions of the data, it may prompt the user or automatically resolve the conflict and write the result back to the database.
What is a conflict?
Some kinds of conflict are obvious.
Other kinds of conflict are subtle. For example, if a meeting room booking system allows a room to be booked by two different leaders.
Multi-Leader Replication Topologies
A replication topology describes the communication paths along which writes are propagated from one node to another.

In circular and star topology, a write may need to pass through one node several times before it reaches all replicas. In order to prevent infinite replication loops, nodes are given a unique identifier, and each write is tagged with the identifier of all nodes it has passed through in the replication log.
In circular and star topology, if a node fails, it can interrupt the flow of replication messages between other nodes.
In all-to-all topology, some network links may be faster than others, with the result that some replication messages may "overtake " others, as illustrated in the image below.
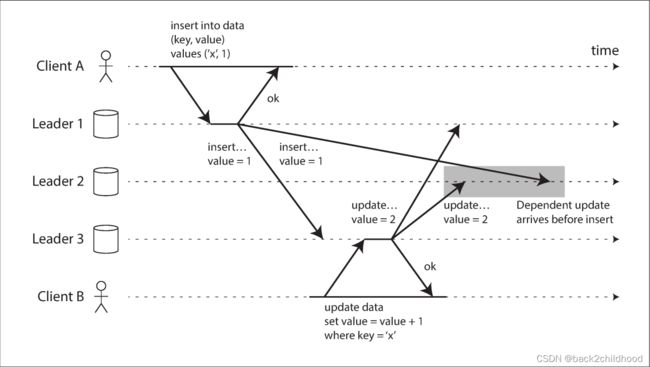
This problem is similar to the one we saw in “Consistent Prefix Reads”, but simply attaching a timestamp to every write is not sufficient, because clocks cannot be trusted to be sufficiently in sync to correctly order these events at leader 2.
To order these events correctly, a technique called version vectors can be used.
Leaderless Replication
In some leaderless implementations, the client directly sends its writes to several replicas, while in others, a coordinator node does this on behalf of the client. However, unlike a leader database, that coordinator does not enforce a particular ordering of writes.
Writing to the Database When a Node Is Down
In leaderless replication, failover doesn’t exist. In the below image, there are two out of three replicas to accept the write, we believe this write is a success.
When clients read from the database, they should read from several nodes in parallel, they will use the version number to determine which value is newer.
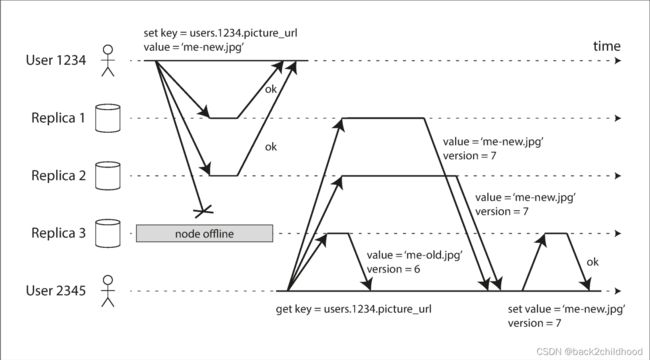
Read repair and anti-entropy
After an unavailable node comes back online, how does it catch up on the writes that it missed?
- Read repair
When a client makes a read from several nodes in parallel, it can detect any stale response. - Anti-entropy process
Use a background process to look for differences in the data between replicas and copy any missing data from one replica to another.
Quorums for reading and writing
If there are n replicas, every write must be confirmed by w nodes to be considered successful, and we must query at least r nodes for each read. (In our example, n = 3, w = 2, r = 2.) As long as w + r > n, we expect to get an up-to-date value when reading, because at least one of the r nodes we’re reading from must be up to date. Reads and writes that obey these r and w values are called quorum reads and writes. You can think of r and w as the minimum number of votes required for the read or write to be valid.
A common choice is to make n an odd number and to set w = r = (n + 1) / 2.
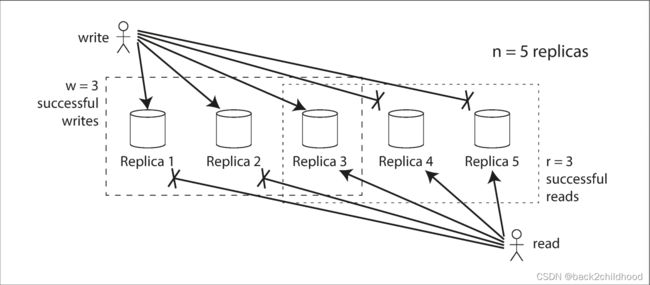
Limitation of Quorum Consistency
Even with w + r > n, there are likely to be edge cases where stale values are returned.
- If a sloppy quorum is used, maybe there will be no different nodes between the w nodes and the r nodes.
- If two writes occur concurrently, it is not clear which one happened first.
- If a write happens concurrently with a read, it’s undetermined whether the read returns the old or the new value.
- If a node carrying a new value fails and restores from a replica carrying an old value, may the number of replicas storing the new value fall below w.
Monitoring staleness
Although our application can tolerate stale reads, we still need to investigate the cause. For leaderless replication, there is no fixed order in which writes are applied which makes monitoring more difficult.
Sloppy Quorums and Hinted Handoff
Databases with appropriately configured quorums can tolerate the failure of individual nodes without the need for failover. This makes databases with leaderless replication have high availability and low latency.
If some nodes are disconnected, we have to face a trade-off:
- sloppy quorum: we accept writes anyway and write them to some nodes that are reachable.
- hinted handoff:
Multi-datacenter operation
Detecting Concurrent Writes
In order to become eventually consistent, the replicas should converge toward the same value. If you want to avoid losing data, you should know a lot about the internals of your database’s conflict handling.
Last write wins (discarding concurrent writes)
Even though the writes don’t have a natural ordering, we can force an arbitrary order on them. For example, we can attach a timestamp to each write, pick the biggest timestamp as the most “recent” and discard others, this resolution algorithm is called LWW.
If there are several concurrent writes to the same key, LWW may cost durability. If losing data is unacceptable, LWW is a poor choice for conflict resolution.
The only safe way to use LWW is to ensure that a key is only written once and thereafter treated as immutable.
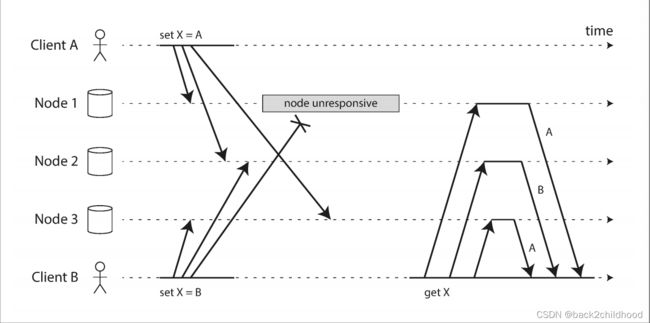
The “happens-before” relationship and concurrency
Whenever you have two operations A and B, there are three possibilities: either A happened before B, or B happened before A, or A and B are concurrent. We should decide whether two operations are concurrent or one operation causally dependent on another.
Capturing the happens-before relationship

Operations 1 and 2 are concurrent, so the server stores the data separately and gives them a different version number. When the client wants to update the value, they should send a request with the version number they recently received.
In this example, the clients are never fully up to date with the data on the server, since there is another operation going on concurrently. But old versions of the value do get overwritten eventually, and no data is lost.
The dataflow is illustrated graphically in the below image. The arrows indicate which operation happened before the other operation.

The algorithm works as follows:
- The server maintains a version number for every key, increments the version number every time that the key is written.
- When a client reads a key, the server returns all values that have not been written and the latest version number.
- When a client writes a key, it must include the version number from the prior read, and it must merge together all values that it received in the prior read.
- When the server receives a write with a particular version number, it can overwrite all values with that version number or below.
Merging concurrently written values
This algorithm ensures that no data is silently dropped, but it requires that the clients do some extra work. If several operations happen concurrently, we call these concurrent values siblings.
Merging sibling values is essentially the same problem as conflict resolution in multileader replication. In the previous example, the two final siblings are [milk, flour, eggs, bacon] and [eggs, milk, ham]; note that milk and eggs appear in both.
If clients not only just add things, but remove things from their carts, then taking the union of siblings may not yield the right result: if you merge two sibling carts and an item has been removed in only one of them, then the removed item will reappear in the union of the siblings. To solve this problem, an item should leave a marker with a version number when it is deleted. This deletion marker is called a tombstone.
Version Vectors
In the previous example, we only use a single replica, in the following we will discuss how the algorithm changes when there are multiple replicas.
We need to use a version number per replica as well as per key. Each replica increments its own version number when processing a write, and also keeps track of the version numbers it has seen from each of the other replicas.
The collection of version numbers from all the replicas is called a version vector. Version vectors are sent from the database replicas to clients when values are read, and need to be sent back to the database when a value is subsequently written. The version vector allows the database to distinguish between overwrites and concurrent writes.
Summary
Replication can serve several purposes:
- High availability: Although one machine goes down, the system can still run.
- Disconnected operation: Although the network is interrupted, the application can still work.
- Latency: Placing data geographically close to users.
- Scalability: Users can read on replicas, so this approach has a higher volume of reads.
We discussed three main approaches to replication:
- Single-leader replication: Only the leader can accept writes, but all replication can handle reads (might read stale data).
- Multi-leader replication: Clients send writes to one of several leader nodes. The leaders send data change events to each other and all follower nodes.
- Leaderless replication: Clients send each write to several nodes, and read from several nodes in parallel in order to detect and correct nodes with stale data.
Single-leader replication is fairly easy to understand and there is no conflict resolution to worry about. Multi-leader and leaderless replication can be more robust in the presence of faulty nodes, network interruptions, and latency spikes—at the cost of being harder to reason about and providing only very weak consistency guarantees.
Replication has two ways to update data:
- Asynchronous: Fast, but may lose the data when you promote an asynchronously updated follower to be the new leader.
- Synchronous:
We discussed a few consistency models that are helpful for deciding how an application should behave under replication lag:
- Read-after-write consistency: Users should always see that they submitted themselves.
- Monotonic reads: After users have seen the data at one point in time, they shouldn’t later see the data from some earlier point in time.
- Consistent prefix reads: Users should see the data in a state that makes causal sense.
Finally, we discussed the consistency issues in multi-leader and leaderless replication approaches (because they allow multiple writes to happen concurrently). We examined an algorithm that a database might use to determine whether one operation happened before another, or whether they happened concurrently. We also touched on methods for resolving conflicts by merging together concurrent updates.